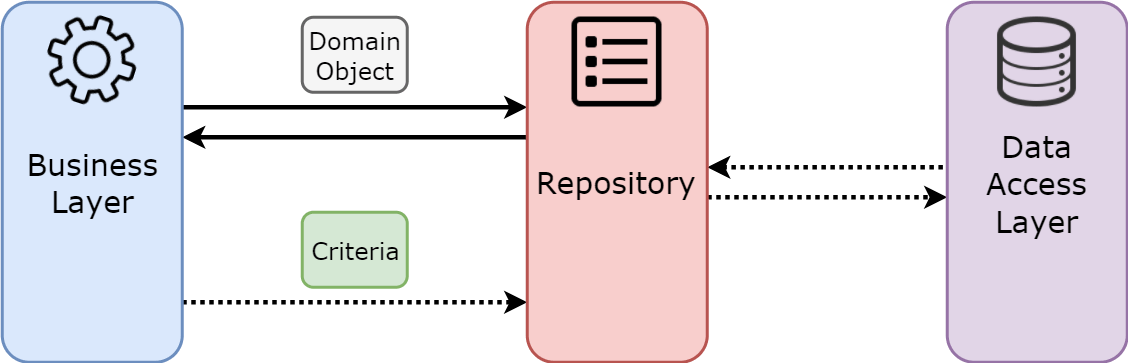
A Repository mediates between the domain and data mapping layers, acting like an in-memory domain object collection. Client objects construct query specifications declaratively and submit them to Repository for satisfaction.
Entity Framework provides us with the actual implementation of the Repository patterns: DbSet<T> and UnitOfWork: DbContext. I often see colleagues using in projects their own implementation of repositories on top of the ones existing in Entity Framework.
Most often, one of two approaches is used:
- Generic Repository as an attempt to disregard a particular ORM.
- Repository as a set of queries to a selected database table (DAO pattern).
Each of these approaches has its own downsides.
Generic Repository
When discussing the architecture of a new project, we often hear the question: “What if we want to switch to another ORM?” And the answer to it is usually the following: “Let’s make Generic Repository that will encapsulate the interaction with a particular technology for accessing data.”
And thus we have a new abstraction layer that translates the well-known, well-designed, and documented API of a beloved ORM into our custom, “on-the-knee” API without documentation.
A typical repository interface looks like this:
public interface IRepository<T>
{
T Get(int id);
void Add(T entity);
void Remove(T entity);
IEnumerable<T> GetAll();
// + some specific things like
IEnumerable<T> Filter(ICriteria<T> criteria);
void Load(T entity, Expression<Func<T, TProperty>> property);
}
So now you can easily switch to another ORM if you suddenly need it.
Not really! What if, when implementing our miracle repository, we used the unique features of a particular ORM? When migrating to a new ORM, we’ll have to invent workarounds in the business logic layer to somehow emulate what the previous ORM provided out of the box.
It turns out that in order to ensure a smooth migration, we must write the implementation of our repository for all popular libraries in advance.
Thus, to write Generic Repository, you need:
- Get thoughts together.
- Design the interface.
- Write an implementation for the ORM selected for the project.
- Write an implementation for alternative ORMs.
- Remove all the unique features of each library from the interface.
- Explain to teammates why they cannot now use the unique features of their favorite ORM.
- Maintain implementations for different ORMs in an up-to-date state. After all, frameworks are also evolving!
- Explain to a manager why you are spending time on this instead of performing immediate tasks.
Fortunately, there are people who have already done this for us. And if you really need to be independent of ORM, you can use one of the ready implementations. For example, the one from the ASP.NET Boilerplate project. In addition to Repository, there are many interesting things in it.
But it’s better to leave it as it is. IDbSet<T> already contains the entire set of CRUD operations and lots of other things (including asynchronous operations) due to the inheritance from IQueryable<T>.
Repository as a Set of Queries
Often people mistakenly call the implementation of another pattern – the Data Access Object – a repository. Or both of these patterns are implemented by the same class. Then there are methods: GetByLogin(), GetByName(), etc. in addition to CRUD operations.
While the project is “green”, everything is fine. Requests are based on the corresponding files. The code is structured. But, as the project grows, new features are added, so as new queries. The repositories swell and turn into unsupported monsters.
Then the queries appear that join several tables and return Data Transfer Object, and not the domain object. And the question arises: into which repository should such queries be pushed? All this happens because SRP is violated when grouping queries by database tables, and not by the features of business logic.
In addition to this, DAO methods also have other disadvantages:
-
They are difficult to test.
Although EF Core tried to solve this problem using in-memory DbContext.
-
They do not support reuse and composition.
For example, if you have a DAO interface:
public interface IPostsRepository
{
IEnumerable<Post> FilterByDate(DateTime date);
IEnumerable<Post> FilterByTag(string tag);
IEnumerable<Post> FilterByDateAndTag(DateTime date, string tag);
}
We cannot use two previous methods to implement FilterByDateAndTag().
So what should we do?
Use the Query Builder and Specification patterns.
.NET provides the actual implementation of the Query Builder pattern: IQueryable<T> and a set of LINQ extension methods.
Let’s analyze the queries in our project. In accordance with the Pareto law, 80% of queries will be:
-
either searching an entity by id: context.Entities.Find(id),
-
either filtration by a single field:
context.Entities.Where (e => e.Property == value).
Out of the remaining 20%, a substantial portion will be unique for each individual business case. Such queries can be left inside business logic services.
Only during the refactoring process, repetitive portions of queries should be taken out into the extension methods to IQueryable<T>. And the recurring conditions – into the specification.
Specification
The specification represents the rules of business logic in the form of a Boolean predicate that receives the domain entity at the input. Thus, the specifications support the composition with the help of Boolean operators.
Fowler and Evans define the specification as:
public interface ISpecification<T>
{
bool IsSatisfiedBy(T entity);
}
But such specifications can not be used with IQueryable<T>.
In LINQ to Entities, Expression<Func<T, bool>> is used as specifications. But such expressions cannot be combined with Boolean operators and used in LINQ to Objects.
Let’s try to combine both approaches. Let’s add the ToExpression() method:
public interface ISpecification<T>
{
bool IsSatisfiedBy(T entity);
Expression<Func<T, bool>> ToExpression();
}
And the Specification<T> base class:
public class Specification<T> : ISpecification<T>
{
private Func<T, bool> _function;
private Func<T, bool> Function => _function
?? (_function = Predicate.Compile());
protected Expression<Func<T, bool>> Predicate;
protected Specification() { }
public Specification(Expression<Func<T, bool>> predicate)
{
Predicate = predicate;
}
public bool IsSatisfiedBy(T entity)
{
return Function.Invoke(entity);
}
public Expression<Func<T, bool>> ToExpression()
{
return Predicate;
}
}
Now we need to override the Boolean operators &&, ||, and !. To do this, we have to do rather strange things. According to C# Language Specification [7.11.2], if you override the operators: true, false, & and |, then & will be called instead of &&, and | will be called instead of ||.
[expand title =”Specification.cs”]
public static implicit operator Func<T, bool>(Specification<T> spec)
{
return spec.Function;
}
public static implicit operator Expression<Func<T, bool>>(Specification<T> spec)
{
return spec.Predicate;
}
public static bool operator true(Specification<T> spec)
{
return false;
}
public static bool operator false(Specification<T> spec)
{
return false;
}
public static Specification<T> operator !(Specification<T> spec)
{
return new Specification<T>(
Expression.Lambda<Func<T, bool>>(
Expression.Not(spec.Predicate.Body),
spec.Predicate.Parameters));
}
public static Specification<T> operator &(Specification<T> left, Specification<T> right)
{
var leftExpr = left.Predicate;
var rightExpr = right.Predicate;
var leftParam = leftExpr.Parameters[0];
var rightParam = rightExpr.Parameters[0];
return new Specification<T>(
Expression.Lambda<Func<T, bool>>(
Expression.AndAlso(
leftExpr.Body,
new ParameterReplacer(rightParam, leftParam).Visit(rightExpr.Body)),
leftParam));
}
public static Specification<T> operator |(Specification<T> left, Specification<T> right)
{
var leftExpr = left.Predicate;
var rightExpr = right.Predicate;
var leftParam = leftExpr.Parameters[0];
var rightParam = rightExpr.Parameters[0];
return new Specification<T>(
Expression.Lambda<Func<T, bool>>(
Expression.OrElse(
leftExpr.Body,
new ParameterReplacer(rightParam, leftParam).Visit(rightExpr.Body)),
leftParam));
}
[/expand]
We also need to replace the argument of one of the expressions with ExpressionVisitor:
[expand title =”ParameterReplacer.cs”]
public static implicit operator Func<T, bool>(Specification<T> spec)
{
return spec.Function;
}
public static implicit operator Expression<Func<T, bool>>(Specification<T> spec)
{
return spec.Predicate;
}
public static bool operator true(Specification<T> spec)
{
return false;
}
public static bool operator false(Specification<T> spec)
{
return false;
}
public static Specification<T> operator !(Specification<T> spec)
{
return new Specification<T>(
Expression.Lambda<Func<T, bool>>(
Expression.Not(spec.Predicate.Body),
spec.Predicate.Parameters));
}
public static Specification<T> operator &(Specification<T> left, Specification<T> right)
{
var leftExpr = left.Predicate;
var rightExpr = right.Predicate;
var leftParam = leftExpr.Parameters[0];
var rightParam = rightExpr.Parameters[0];
return new Specification<T>(
Expression.Lambda<Func<T, bool>>(
Expression.AndAlso(
leftExpr.Body,
new ParameterReplacer(rightParam, leftParam).Visit(rightExpr.Body)),
leftParam));
}
public static Specification<T> operator |(Specification<T> left, Specification<T> right)
{
var leftExpr = left.Predicate;
var rightExpr = right.Predicate;
var leftParam = leftExpr.Parameters[0];
var rightParam = rightExpr.Parameters[0];
return new Specification<T>(
Expression.Lambda<Func<T, bool>>(
Expression.OrElse(
leftExpr.Body,
new ParameterReplacer(rightParam, leftParam).Visit(rightExpr.Body)),
leftParam));
}
[/expand]
And convert the Specification<T> to Expression for use within other expressions:
[expand title=”SpecificationExpander.cs”]
public class SpecificationExpander : ExpressionVisitor
{
protected override Expression VisitUnary(UnaryExpression node)
{
if (node.NodeType == ExpressionType.Convert)
{
MethodInfo method = node.Method;
if (method != null && method.Name == "op_Implicit")
{
Type declaringType = method.DeclaringType;
if (declaringType.GetTypeInfo().IsGenericType
&& declaringType.GetGenericTypeDefinition() == typeof(Specification<>))
{
const string name = nameof(Specification<object>.ToExpression);
MethodInfo toExpression = declaringType.GetMethod(name);
return ExpandSpecification(node.Operand, toExpression);
}
}
}
return base.VisitUnary(node);
}
protected override Expression VisitMethodCall(MethodCallExpression node)
{
MethodInfo method = node.Method;
if (method.Name == nameof(ISpecification<object>.ToExpression))
{
Type declaringType = method.DeclaringType;
Type[] interfaces = declaringType.GetTypeInfo().GetInterfaces();
if (interfaces.Any(i => i.GetTypeInfo().IsGenericType
&& i.GetGenericTypeDefinition() == typeof(ISpecification<>)))
{
return ExpandSpecification(node.Object, method);
}
}
return base.VisitMethodCall(node);
}
private Expression ExpandSpecification(Expression instance, MethodInfo toExpression)
{
return Visit((Expression)GetValue(Expression.Call(instance, toExpression)));
}
// http://stackoverflow.com/a/2616980/1402923
private static object GetValue(Expression expression)
{
var objectMember = Expression.Convert(expression, typeof(object));
var getterLambda = Expression.Lambda<Func<object>>(objectMember);
return getterLambda.Compile().Invoke();
}
}
[/expand]
Now we can
– test our specifications:
public class UserIsActiveSpec : Specification<User>
{
public UserIsActiveSpec()
{
Predicate = u => u.IsActive;
}
}
var spec = new UserIsActiveSpec();
var user = new User { IsActive = true };
Assert.IsTrue(spec.IsSatisfiedBy(user));
– combine our specifications:
public class UserByLoginSpec : Specification<User>
{
public UserByLoginSpec(string login)
{
Predicate = u => u.Login == login;
}
}
public class UserCombinedSpec : Specification<User>
{
public UserCombinedSpec(string login)
: base(new UserIsActive() && new UserByLogin(login))
{
}
}
– use them in LINQ to Entities:
var spec = new UserByLoginSpec("admin");
context.Users.Where(spec.ToExpression());
// or even like this (due to implicit conversion в Expression)
context.Uses.Where(new UserByLoginSpec("admin") || new UserByLoginSpec("user"));
If you do not like the magic with operators, you can use the actual implementation of the Specification from ASP.NET Boilerplate. Or use PredicateBuilder from LinqKit.
Extension Methods to IQueryable
The extension methods to Iqueryable<T> can be an alternative to the specifications. For example:
public static IQueryable<Post> FilterByAuthor(
this IQueryable<Post> posts, int authorId)
{
return posts.Where(p => p.AuthorId = authorId);
}
public static IQueryable<Comment> FilterTodayComments(
this IQueryable<Comment> comments)
{
DateTime today = DateTime.Now.Date;
return comments.Where(c => c.CreationTime > today)
}
Comment[] comments = context.Posts
.FilterByAuthor(authorId) // it's OK
.SelectMany(p => p.Comments
.AsQueryable()
.FilterTodayComments()) // will throw Exception
.ToArray();
The problem here is that if the first extension method works as expected, then Exception will be thrown for the second. Because it is called inside the Expression Tree passed to SelectMany(), and LINQ to Entities cannot handle this.
We will try to change the situation for better. For this we need:
-
ExpressionVisitor, which will expand our extension methods.
-
A decorator for IQueryable<T>, which will be called by our ExpressionVisitor.
-
The AsExpandable() extension method that will wrap IQueryable<T> in the decorator.
-
The [Expandable] attribute, with which we will mark the extension methods for expansion. After all, Where() or Select() are extension methods as well, and you do not need to expand them.
[AttributeUsage(AttributeTargets.Method, AllowMultiple = false)]
public class ExpandableAttribute : Attribute { }
[expand title=”QueryableExtensions.cs”]
public static IQueryable<T> AsExpandable<T>(this IQueryable<T> queryable)
{
return queryable.AsVisitable(new ExtensionExpander());
}
public static IQueryable<T> AsVisitable<T>(
this IQueryable<T> queryable, params ExpressionVisitor[] visitors)
{
return queryable as VisitableQuery<T>
?? VisitableQueryFactory<T>.Create(queryable, visitors);
}
[/expand]
Now we need to implement the IQueryable<T> and IQueryProvider interfaces:
public interface IQueryable<T>
{
IEnumerator GetEnumerator(); // from IEnumerable
IEnumerator<T> GetEnumerator(); // from IEnumerable<T>
Type ElementType { get; } // from IQueryable
Expression Expression { get; } // from IQueryable
IQueryProvider Provider { get; } // from IQueryable
}
[expand title=”VisitableQuery.cs”]
internal class VisitableQuery<T> : IQueryable<T>, IOrderedQueryable<T>, IOrderedQueryable
{
readonly ExpressionVisitor[] _visitors;
readonly IQueryable<T> _queryable;
readonly VisitableQueryProvider<T> _provider;
internal ExpressionVisitor[] Visitors => _visitors;
internal IQueryable<T> InnerQuery => _queryable;
public VisitableQuery(IQueryable<T> queryable, params ExpressionVisitor[] visitors)
{
_queryable = queryable;
_visitors = visitors;
_provider = new VisitableQueryProvider<T>(this);
}
Expression IQueryable.Expression => _queryable.Expression;
Type IQueryable.ElementType => typeof(T);
IQueryProvider IQueryable.Provider => _provider;
public IEnumerator<T> GetEnumerator()
{
return _queryable.GetEnumerator();
}
IEnumerator IEnumerable.GetEnumerator()
{
return _queryable.GetEnumerator();
}
}
[/expand]
public interface IQueryProvider
{
IQueryable CreateQuery(Expression expression);
IQueryable<TElement> CreateQuery<TElement>(Expression expression);
object Execute(Expression expression);
TResult Execute<TResult>(Expression expression);
}
[expand title=”VisitableQueryProvider.cs”]
internal class VisitableQueryProvider<T> : IQueryProvider
{
readonly VisitableQuery<T> _query;
public VisitableQueryProvider(VisitableQuery<T> query)
{
_query = query;
}
IQueryable<TElement> IQueryProvider.CreateQuery<TElement>(Expression expression)
{
expression = _query.Visitors.Visit(expression);
return _query.InnerQuery.Provider
.CreateQuery<TElement>(expression)
.AsVisitable(_query.Visitors);
}
IQueryable IQueryProvider.CreateQuery(Expression expression)
{
expression = _query.Visitors.Visit(expression);
return _query.InnerQuery.Provider.CreateQuery(expression);
}
TResult IQueryProvider.Execute<TResult>(Expression expression)
{
expression = _query.Visitors.Visit(expression);
return _query.InnerQuery.Provider.Execute<TResult>(expression);
}
object IQueryProvider.Execute(Expression expression)
{
expression = _query.Visitors.Visit(expression);
return _query.InnerQuery.Provider.Execute(expression);
}
}
[/expand]
[expand title=”VisitorExtensions.cs”]
internal static class VisitorExtensions
{
public static Expression Visit(this ExpressionVisitor[] visitors, Expression node)
{
if (visitors != null)
{
foreach (var visitor in visitors)
{
node = visitor.Visit(node);
}
}
return node;
}
}
[/expand]
There is one small feature. To support asynchronous operations, such as ToListAsync(), EntityFramework, and EF Core, additional interfaces should be defined: IDbAsyncEnumerable<T> and IAsyncEnumerable<T>. Therefore, it is better to use the actual implementation. It is based on ExpandableQuery of LinqKit but allows to use any ExpressionVisitor.
And, finally, the ExpressionVisitor as such:
[expand title=”ExtensionExpander.cs”]
public class ExtensionExpander : ExpressionVisitor
{
protected override Expression VisitMethodCall(MethodCallExpression node)
{
MethodInfo method = node.Method;
if (method.IsDefined(typeof(ExtensionAttribute), true)
&& method.IsDefined(typeof(ExpandableAttribute), true))
{
ParameterInfo[] methodParams = method.GetParameters();
Type queryableType = methodParams.First().ParameterType;
Type entityType = queryableType.GetGenericArguments().Single();
object inputQueryable = MakeEnumerableQuery(entityType);
object[] arguments = new object[methodParams.Length];
arguments[0] = inputQueryable;
var argumentReplacements = new List<KeyValuePair<string, Expression>>();
for (int i = 1; i < methodParams.Length; i++)
{
try
{
arguments[i] = GetValue(node.Arguments[i]);
}
catch (InvalidOperationException)
{
ParameterInfo paramInfo = methodParams[i];
Type paramType = paramInfo.GetType();
arguments[i] = paramType.GetTypeInfo().IsValueType
? Activator.CreateInstance(paramType) : null;
argumentReplacements.Add(
new KeyValuePair<string, Expression>(paramInfo.Name, node.Arguments[i]));
}
}
object outputQueryable = method.Invoke(null, arguments);
Expression expression = ((IQueryable)outputQueryable).Expression;
Expression realQueryable = node.Arguments[0];
if (!typeof(IQueryable).IsAssignableFrom(realQueryable.Type))
{
MethodInfo asQueryable = _asQueryable.MakeGenericMethod(entityType);
realQueryable = Expression.Call(asQueryable, realQueryable);
}
expression = new ExtensionRebinder(
inputQueryable, realQueryable, argumentReplacements).Visit(expression);
return Visit(expression);
}
return base.VisitMethodCall(node);
}
private static object MakeEnumerableQuery(Type entityType)
{
return _queryableEmpty.MakeGenericMethod(entityType).Invoke(null, null);
}
private static readonly MethodInfo _asQueryable = typeof(Queryable)
.GetMethods(BindingFlags.Static | BindingFlags.Public)
.First(m => m.Name == nameof(Queryable.AsQueryable) && m.IsGenericMethod);
private static readonly MethodInfo _queryableEmpty = (typeof(ExtensionExpander))
.GetMethod(nameof(QueryableEmpty), BindingFlags.Static | BindingFlags.NonPublic);
private static IQueryable<T> QueryableEmpty<T>()
{
return Enumerable.Empty<T>().AsQueryable();
}
// http://stackoverflow.com/a/2616980/1402923
private static object GetValue(Expression expression)
{
var objectMember = Expression.Convert(expression, typeof(object));
var getterLambda = Expression.Lambda<Func<object>>(objectMember);
return getterLambda.Compile().Invoke();
}
}
[/expand]
[expand title=”ExtensionRebinder.cs”]
internal class ExtensionRebinder : ExpressionVisitor
{
readonly object _originalQueryable;
readonly Expression _replacementQueryable;
readonly List<KeyValuePair<string, Expression>> _argumentReplacements;
public ExtensionRebinder(
object originalQueryable, Expression replacementQueryable,
List<KeyValuePair<string, Expression>> argumentReplacements)
{
_originalQueryable = originalQueryable;
_replacementQueryable = replacementQueryable;
_argumentReplacements = argumentReplacements;
}
protected override Expression VisitConstant(ConstantExpression node)
{
return node.Value == _originalQueryable ? _replacementQueryable : node;
}
protected override Expression VisitMember(MemberExpression node)
{
if (node.NodeType == ExpressionType.MemberAccess
&& node.Expression.NodeType == ExpressionType.Constant
&& node.Expression.Type.GetTypeInfo().IsDefined(typeof(CompilerGeneratedAttribute)))
{
string argumentName = node.Member.Name;
Expression replacement = _argumentReplacements
.Where(p => p.Key == argumentName)
.Select(p => p.Value)
.FirstOrDefault();
if (replacement != null)
{
return replacement;
}
}
return base.VisitMember(node);
}
}
[/expand]
Now we can
– use the extension methods inside Expression Tree:
[Expandable]
public static IQueryable<Post> FilterByAuthor(
this IEnumerable<Post> posts, int authorId)
{
return posts.AsQueryable().Where(p => p.AuthorId = authorId);
}
[Expandable]
public static IQueryable<Comment> FilterTodayComments(
this IEnumerable<Comment> comments)
{
DateTime today = DateTime.Now.Date;
return comments.AsQueryable().Where(c => c.CreationTime > today)
}
Comment[] comments = context.Posts
.AsExpandable()
.FilterByAuthor(authorId) // it's OK
.SelectMany(p => p.Comments
.FilterTodayComments()) // it's OK too
.ToArray();
TL; DR
Dear colleagues, do not try to abstract yourself from the chosen framework! As a rule, the framework already provides a sufficient level of abstraction. Otherwise, why is it needed?
The full code for extensions is available on GitHub: EntityFramework.CommonTools, and in NuGet:
PM> Install-Package EntityFramework.CommonTools PM> Install-Package EntityFrameworkCore.CommonTools
Benchmarks in my project:
[expand title=”DatabaseQueryBenchmark.cs”]
public class DatabaseQueryBenchmark
{
readonly DbConnection _connection = Context.CreateConnection();
[Benchmark(Baseline = true)]
public object RawQuery()
{
using (var context = new Context(_connection))
{
DateTime today = DateTime.Now.Date;
return context.Users
.Where(u => u.Posts.Any(p => p.Date > today))
.FirstOrDefault();
}
}
[Benchmark]
public object ExpandableQuery()
{
using (var context = new Context(_connection))
{
return context.Users
.AsExpandable()
.Where(u => u.Posts.FilterToday().Any())
.ToList();
}
}
readonly Random _random = new Random();
[Benchmark]
public object NotCachedQuery()
{
using (var context = new Context(_connection))
{
int[] postIds = new[] { _random.Next(), _random.Next() };
return context.Users
.Where(u => u.Posts.Any(p => postIds.Contains(p.Id)))
.ToList();
}
}
}
[/expand]
[expand title=”The approximate results”]
Method | Median | StdDev | Scaled | Scaled-SD |
---------------- |-------------- |----------- |------- |---------- |
RawQuery | 555.6202 μs | 15.1837 μs | 1.00 | 0.00 |
ExpandableQuery | 644.6258 μs | 3.7793 μs | 1.15 | 0.03 | <<<
NotCachedQuery | 2,277.7138 μs | 10.9754 μs | 4.06 | 0.10 |
[/expand]
It seems that everything is cached as it should. The compilation time of the query increases by 15-30%.
Source references:
- https://martinfowler.com/eaaCatalog/repository.html
- https://softwareengineering.stackexchange.com/questions/180851/why-shouldnt-i-use-the-repository-pattern-with-entity-framework
- http://enterprisecraftsmanship.com/2016/02/08/specification-pattern-c-implementation
- https://aspnetboilerplate.com/Pages/Documents/Repositories
- https://aspnetboilerplate.com/Pages/Documents/Specifications
- http://www.albahari.com/nutshell/linqkit.aspx
- https://msdn.microsoft.com/en-us/library/aa691312(v=vs.71).aspx







good read, however it all looks a lot of ceremony (which I guess we cannot avoid). have you ever witnessed underlying database engine switch in projects? heard it many times, done also abstractions in repositories back in time, but never ever had real example when we needed to switch databases..
And then, if you want to stop using Entity Framework because some mapping problems that NHibernate doesn’t have, or because of a specific aspect of an inherited database that you can’t do with an ORM, you need to provide all the functionality of IQueryable.
Wouldn’t it be simpler just make a method in the interface called FindByFields that gets a data structure and make that combination of queries in the implementation? What if Entity Framework shows a poor performance and I want to call a stored procedure instead?
The specification pattern is for business logic, not to expose database aspects to the business.
I do want to get collections as the result of the repository, not IQueryable because I want the unit of work to be completely closed and disposed when the repository returns, not to have potential state problems with the result of the methods.
The caller should not be aware of that.