One of the available algorithms to join two tables together in SQL Server is Nested Loops. The nested loops join uses one join input as the outer input table and one as the inner input table. The outer loop iterates the outer input table row by row. The inner loop, executed for each outer row, searches for matching rows in the inner input table.
This is called a naive nested loops join.
If you have an index on join conditions in the inner input table, then it is not necessary to perform an inner loop for each row of the outer table. Instead, you can pass the value from the external table as a search argument, and connect all the returned rows of the inner table to the rows from the outer table.
The search by the inner table is a random access. The SQL Server, starting from version 2005, has the batch sort optimization (do not confuse with the Sort operator in Batch Mode for Columnstore indexes). The purpose of the optimization is to order search keys from the external table before getting data from the internal one. Thus, a random access will be sequential.
The execution plan does not display the batch sort operation as a separate operator. Instead, you can see the Optimized=true property in the Nested Loops operator. If it were possible to see batch sort as a separate operator in the plan, it would look like the following:
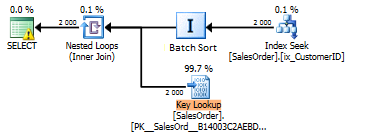
In this pseudo-plan, we read data from the non-clustered ix_CustomerID index in the order of this CustomerID index key. Then, we need to perform Key Lookup in the clustered index, as ix_CustomerID is not a covering index. Key Lookup is a clustered index key search operation – a random access. To make it sequential, SQL Server may execute batch sort by the clustered index key.
To learn more about batch sort, please refer to my article Batch Sort and Nested Loops.
This optimization provides a great boost with a sufficient number of rows. You can read more about its test results in the blog OPTIMIZED Nested Loops Joins, created by Craig Freedman, an optimizer developer.
However, if the actual number of rows is less than the expected one, then CPU additional costs to build this sort may hide its benefits, increase CPU consumption and reduce its performance.
Consider this particular example:
use tempdb;
go
-- create a test table (SalesOrderID - clustered PK)
create table dbo.SalesOrder(SalesOrderID int identity primary key, CustomerID int not null, SomeData char(200) not null);
go
-- add test data
with n as (select top(1000000) rn = row_number() over(order by (select null)) from sys.all_columns c1,sys.all_columns c2)
insert dbo.SalesOrder(CustomerID, SomeData) select rn%500000, str(rn,100) from n;
-- create a clustered index
create index ix_c on dbo.Salesorder(CustomerID);
go
-- the batch sort optimization is enabled by default (Nested Loops: Optimized = true)
select * from dbo.SalesOrder with(index(ix_c)) where CustomerID < 1000;
-- disable it with the DISABLE_OPTIMIZED_NESTED_LOOP hint (Nested Loops: Optimized = false)
select * from dbo.SalesOrder with(index(ix_c)) where CustomerID < 1000 option(use hint('DISABLE_OPTIMIZED_NESTED_LOOP'));
go
The returned result:
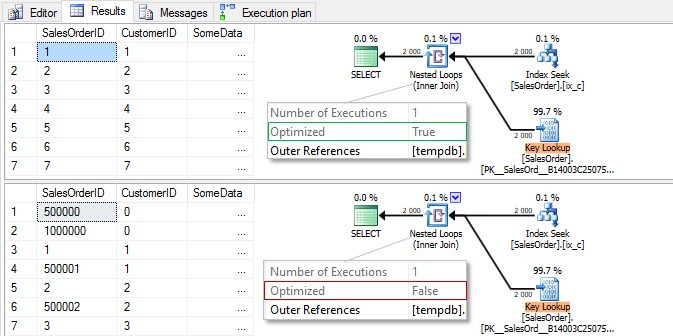
I would like to draw your attention to the different order of rows in the output. The server returns rows in the order it process them as we have not explicitly specified ORDER BY. In the first case, we gradually read from the ix_c index. However, to optimize random readings from the clustered index, we filter rows by the clustered SalesOrderID index key. In the second case, there is no sort, as well as reads are done in the CustomerID key order of the nonclustered index ix_c.
Difference from the 2340 trace flag
Despite the fact that the documentation specifies the 2340 trace flag as an equivalent of the DISABLE_OPTIMIZED_NESTED_LOOP hint, it is not actually true.

Consider the following example where I will use the UPDATE STATISTICS … WITH PAGECOUNT undocumented command to deceive the optimizer by saying that the table takes more pages than it actually has. Then, have a look at these queries:
- Without any hints (I have added MAXDOP to keep a simple plan);
- With the DISABLE_OPTIMIZED_NESTED_LOOP hint;
- With the 2340 trace flag.
-- create a huge table
update statistics dbo.SalesOrder with pagecount = 100000;
go
set showplan_xml on;
go
-- 1. without hints
select * from dbo.SalesOrder with(index(ix_c)) where CustomerID < 1000000 option(maxdop 1);
-- 2. hint
select * from dbo.SalesOrder with(index(ix_c)) where CustomerID < 1000000 option(use hint('DISABLE_OPTIMIZED_NESTED_LOOP'), maxdop 1);
-- 3. trace flag
select * from dbo.SalesOrder with(index(ix_c)) where CustomerID < 1000000 option(querytraceon 2340, maxdop 1);
go
set showplan_xml off;
go
As a result, we have the following plans:
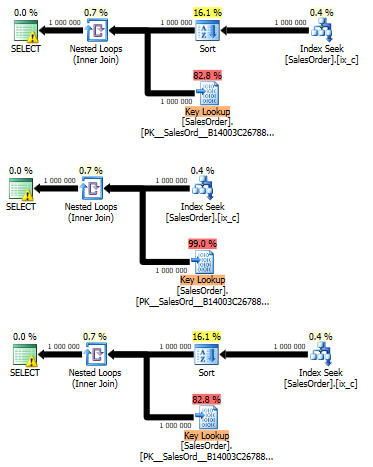
Nested Loops has the Optimized = false property in all three plans. The fact is that by increasing the table width, we also increase the data access cost. When the cost is high enough, SQL Server may use the explicit Sort operator, rather than the implicit batch sort operator. We can see this in the first query plan.
In the second query, we used the DISABLE_OPTIMIZED_NESTED_LOOP hint that turns off the implicit batch sort. However, it removes an explicit sorting by a separate operator.
In the third plan, we can see that despite adding the 2340 trace flag, the sort operator exists.
Thus, the difference of the hint from the flag is as follows: a hint disables the optimization by transforming a random access into a serial one depending on the fact whether the server implements it with the implicit batch sort or with the separate Sort operator.
P.S. Plans may depend on the equipment. Thus, if you fail to run these queries, try to increase or decrease the SomeData char(200) column size in the dbo.SalesOrder table description.
The article was translated by Codingsight team with the permission of the author.
Tags: query performance, sql server 2016, t-sql queries Last modified: September 23, 2021