What are unique key constraints?
A unique constraint is a rule that restricts column entries to unique. In other words, this type of constraints prevents inserting duplicates into a column. A unique constraint is one of the instruments to enforce data integrity in an SQL Server database. Since a table can have only one primary key, you can use a unique constraint to enforce the uniqueness of a column or a combination of columns that do not constitute a primary key.
Creating a unique constraint on a column automatically creates a unique index. This way SQL Server implements the integrity requirement of the unique constraint. Therefore, when attempting to insert a duplicate value into a column, on which a unique constraint is defined, the Database Engine will detect the unique constraint violation and issue a corresponding error. As a result, the row with the duplicate values will not be added to a table.
Creating a unique constraint
The following sample query creates the Students table and a unique constraint on the Login column so that there are no students with the same login.
CREATE TABLE Students ( Login CHAR NOT NULL ,CONSTRAINT AK_Student_Login UNIQUE (Login) ); GO
If the Students table already exists, then you may use the following sample query to create the unique constraint.
ALTER TABLE Students ADD CONSTRAINT AK_Student_Login UNIQUE (Login); GO
Note that when you add a unique constraint to an existing table, the Database Engine verifies whether the column to which the constraint is added includes duplicated values. If there are such values, the constraint will not be added returning an error.
Now, to verify that the unique constraint has been actually added, execute the following statements:
EXEC sp_helpindex Students EXEC sp_helpconstraint Students
Here is the constraint we’ve created:
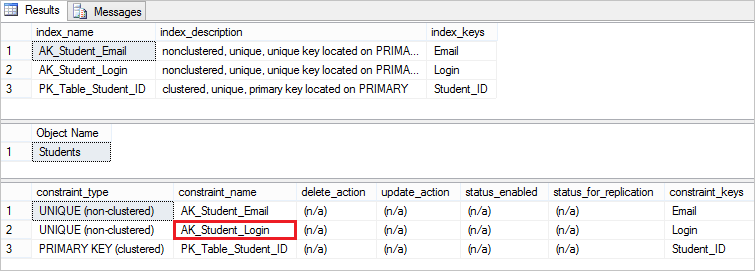
Creating a unique constraint in SQL Server Management Studio
Let’s say we need to define a unique constraint on the Login column it the Students table.
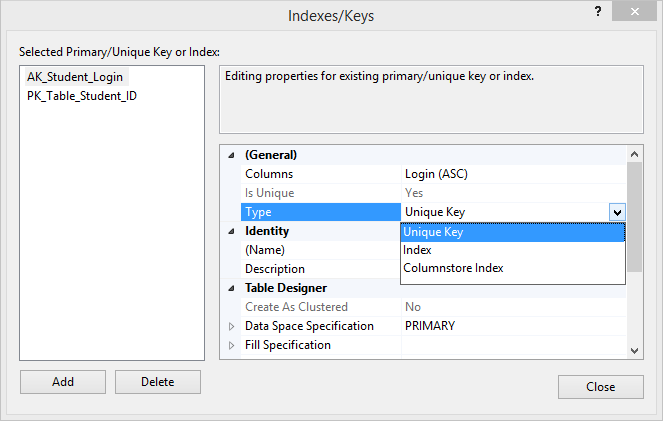
1. In the Object Explorer, right-click the Students table and click Design.
2. Right-click the Table Designer and choose Indexes/Keys…
3. In the Indexes/Keys window, click Add.
4. Under the General section, click Columns and then click the ellipsis button. In the Index Columns window, select the column(s) which you want to include in the unique constraint.
5. Under the General section, click Type and select Unique Key from the drop-down list.
6. Under the Identity section, specify the name of the constraint (in our case, AK_Student_Login) and click Close to save the newly created constraint.
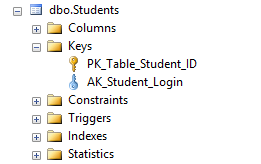
Now, if you go to the Students table in Object Explorer and click the Indexes folder, you will see that the table contains a primary key and a unique constraint AK_Student_Login.
How are unique constraints different from primary keys?
Similar to a unique constraint, a primary key is also used to enforce data integrity in a table. But the primary purpose of a primary key is to uniquely identify each record in a table and implement proper relationships between tables in a database. A primary key is required in 99% of tables to allow proper access to table rows. There can be only one primary key per table defined on one or more than one columns.
Unique constraints are specifically used to prevent duplicate values from being inserted into a column. There may be several columns with unique constraints or there may be no unique constraints defined on a table at all. They are not mandatory for a table as opposed to primary keys.
Let’s say, we have the Students table containing personal information about each student at a university. The table includes the StudentID column which is a primary key and stores a unique ID of each specific student. This primary key column is used to uniquely identify each student at a university.
At the same time, the Students table has such columns as Email, Social Security Number, and Login and each of these columns must store unique values. Since there is already one primary key in the table, we will use unique constraints instead to impose uniqueness to these columns. Thus, a table can have many unique constraints and only one primary key.
Another thing that differs a unique constraint from a primary key is that the primary key doesn’t allow any NULL values in a column, whereas a column with a unique constraint can include a NULL value but only one since SQL Server interprets two NULL values as the same values.
Suppose a unique constraint is created on the Email column of the Students table. Let’s try to insert two rows both with NULLs in the Email fields:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (1, 'John White', 19, NULL, 123-45-6789, 'John555') GO
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (2, 'James Marvin', 21, NULL, 987-65-4321, 'Marvin_J17') GO
We get the following error message:

Well, this is a predictable behavior, because duplicate values, even if they are NULLs, are not allowed by the unique constraint.
Unique constraint vs Unique index
Though both the unique constraint and unique index are two completely different unrelated database entities, they have the same goal and the same impact on SQL Server performance. They both ensure data uniqueness in a column.
However, in contrast to the unique index, you cannot specify the IGNORE_DUP_KEY, DROP_EXISTING, PAD_INDEX , and STATISTICS_NORECOMPUTE options for the unique constraint in the ALTER TABLE statements.
When you create a unique constraint on a column, SQL Server automatically creates a unique index on the column, this is just how this feature is implemented in SQL Server.
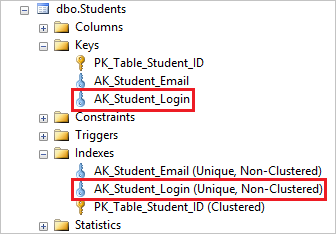
In order to delete the unique index, you need to first drop the corresponding unique constraint and this will automatically delete the underlying unique index.
The following statement will drop the AK_Student_Login constraint:
ALTER TABLE Students DROP CONSTRAINT AK_Student_Login; GO
You can see that dropping the AK_Student_Login unique constraint deletes its corresponding index.
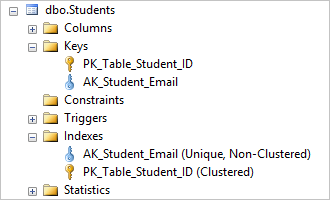
That was easy, now you can insert identical values into the Login column.
Disabling Unique Constraint
There is an option that disables a unique constraint. The following query is supposed to disable all the table constraints:
ALTER TABLE Students NOCHECK CONSTRAINT ALL GO
Having executed the query, let’s now try to insert a duplicating record:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (3, 'John White', 19, NULL, 123-45-6789, 'John555') GO
What we get is the unique constraint violation message:

Thus, it appears that the ALTER TABLE <table name> NOCHECK CONSTRAINT ALL GO does not work for unique constraints in SQL Server.
However, remember that there is a unique index under the hood of each unique constraint, and we should be able to disable a unique index. In our case, the AK_Student_Email unique constraint has created the corresponding AK_Student_Email unique index on the Email column. Let’s use the following query to disable the AK_Student_Email unique index first.
ALTER INDEX AK_Student_Email ON Students DISABLE;
The query has completed successfully, so now let’s insert two records with duplicate Email fields into the Students table.
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (3, 'John White', 19, '[email protected]', 123-45-6789, 'John555') GO
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (4, 'James Marvin', 21, '[email protected]', 987-65-4321, 'Marvin_J17') GO
It works! The records have been inserted in the table! Now we know how to get around this “disablement” issue with a unique constraint.
To enable the index, use the following query:
ALTER INDEX AK_Student_Email ON Students REBUILD;
Conclusion
Unique key constraints allow DBAs and SQL developers to enforce and preserve data uniqueness in table columns, as well as apply certain business requirements for data integrity. Basically, there is no substantial difference in behavior between a unique constraint and a unique index, except the fact that the unique constraint cannot be directly disabled and certain index creation options are not available for unique constraints in the ALTER TABLE statement.
Hope this article was interesting. You can ask questions, leave comments and suggestions concerning this article.
See also: CHECK Constraints in SQL Server
Tags: sql constraints, sql server Last modified: September 23, 2021





