In this article, we will discuss typical errors that newbie developers may face with while designing T-SQL code. In addition, we will have a look at the best practices and some useful tips that may help you when working with SQL Server, as well as workarounds to improve performance.
Contents:
1. Data Types
2. *
3. Alias
4. Column order
5. NOT IN vs NULL
6. Date format
7. Date filter
8. Сalculation
9. Convert implicit
10. LIKE & Suppressed index
11. Unicode vs ANSI
12. COLLATE
13. BINARY COLLATE
14. Code style
15. [var]char
16. Data length
17. ISNULL vs COALESCE
18. Math
19. UNION vs UNION ALL
20. Re-read
21. SubQuery
22. CASE WHEN
23. Scalar func
24. VIEWs
25. CURSORs
26. STRING_CONCAT
27. SQL Injection
Data Types
The main issue we face when working with SQL Server is an incorrect choice of data types.
Assume we have two identical tables:
DECLARE @Employees1 TABLE (
EmployeeID BIGINT PRIMARY KEY
, IsMale VARCHAR(3)
, BirthDate VARCHAR(20)
)
INSERT INTO @Employees1
VALUES (123, 'YES', '2012-09-01')
DECLARE @Employees2 TABLE (
EmployeeID INT PRIMARY KEY
, IsMale BIT
, BirthDate DATE
)
INSERT INTO @Employees2
VALUES (123, 1, '2012-09-01')
Let’s execute a query to check what the difference is:
DECLARE @BirthDate DATE = '2012-09-01' SELECT * FROM @Employees1 WHERE BirthDate = @BirthDate SELECT * FROM @Employees2 WHERE BirthDate = @BirthDate
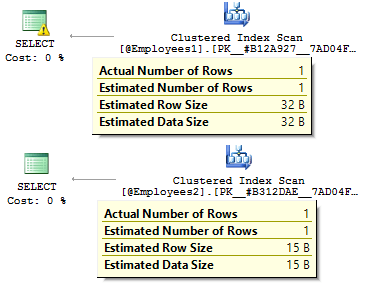
In the first case, the data types are more redundant than it might be. Why should we store a bit value as the YES/NO row? Why should we store a date as a row? Why should we use BIGINT for employees in the table, rather than INT?
It leads to the following drawbacks:
- Tables may take much space on the disk;
- We need to read more pages and put more data in BufferPoolto handle data.
- Poor performance.
*
I have faced the situation when developers retrieve all the data from a table, and then on the client-side, use DataReader to select required fields only. I do not recommend using this approach:
USE AdventureWorks2014
GO
SET STATISTICS TIME, IO ON
SELECT *
FROM Person.Person
SELECT BusinessEntityID
, FirstName
, MiddleName
, LastName
FROM Person.Person
SET STATISTICS TIME, IO OFF
There will be a significant difference in the query execution time. In addition, the covering index may reduce a number of logical reads.
Table 'Person'. Scan count 1, logical reads 3819, physical reads 3, ... SQL Server Execution Times: CPU time = 31 ms, elapsed time = 1235 ms. Table 'Person'. Scan count 1, logical reads 109, physical reads 1, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 227 ms.
Alias
Let’s create a table:
USE AdventureWorks2014
GO
IF OBJECT_ID('Sales.UserCurrency') IS NOT NULL
DROP TABLE Sales.UserCurrency
GO
CREATE TABLE Sales.UserCurrency (
CurrencyCode NCHAR(3) PRIMARY KEY
)
INSERT INTO Sales.UserCurrency
VALUES ('USD')
Assume we have a query that returns the amount of identical rows in both tables:
SELECT COUNT_BIG(*)
FROM Sales.Currency
WHERE CurrencyCode IN (
SELECT CurrencyCode
FROM Sales.UserCurrency
)
Everything will be working as expected, until someone renames a column in the Sales.UserCurrency table:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
Next, we will execute a query and see that we get all the rows in the Sales.Currency table, instead of 1 row. When building an execution plan, on the binding stage, SQL Server would check the columns of Sales.UserCurrency, it will not find CurrencyCode there and decides that this column belongs to the Sales.Currency table. After that, an optimizer will drop the CurrencyCode = CurrencyCode condition.
Thus, I recommend using aliases:
SELECT COUNT_BIG(*)
FROM Sales.Currency c
WHERE c.CurrencyCode IN (
SELECT u.CurrencyCode
FROM Sales.UserCurrency u
)
Column order
Assume we have a table:
IF OBJECT_ID('dbo.DatePeriod') IS NOT NULL
DROP TABLE dbo.DatePeriod
GO
CREATE TABLE dbo.DatePeriod (
StartDate DATE
, EndDate DATE
)
We always insert data there based on the information about the column order.
INSERT INTO dbo.DatePeriod SELECT '2015-01-01', '2015-01-31'
Assume someone changes the order of columns:
CREATE TABLE dbo.DatePeriod (
EndDate DATE
, StartDate DATE
)
Data will be inserted in a different order. In this case, it is a good idea to explicitly specify columns in the INSERT statement:
INSERT INTO dbo.DatePeriod (StartDate, EndDate) SELECT '2015-01-01', '2015-01-31'
Here is another example:
SELECT TOP(1) * FROM dbo.DatePeriod ORDER BY 2 DESC
On what column are we going to order data? It will depend on the column order in a table. In case one changes the order we get wrong results.
NOT IN vs NULL
Let’s talk about the NOT IN statement.
For example, you need to write a couple of queries: return the records from the first table, which do not exist in the second table and visa verse. Usually, junior developers use IN and NOT IN:
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1)) INSERT INTO @t1 VALUES (1), (2) DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2)) INSERT INTO @t2 VALUES (1) SELECT * FROM @t1 WHERE t1 NOT IN (SELECT t2 FROM @t2) SELECT * FROM @t1 WHERE t1 IN (SELECT t2 FROM @t2)
The first query returned 2, the second one – 1. Further, we will add another value in the second table – NULL:
INSERT INTO @t2 VALUES (1), (NULL)
When executing the query with NOT IN, we will not get any results. Why IN works and NOT In not? The reason is that SQL Server uses TRUE, FALSE, and UNKNOWN logic when comparing data.
When executing a query, SQL Server interprets the IN condition in the following manner:
a IN (1, NULL) == a=1 OR a=NULL
NOT IN:
a NOT IN (1, NULL) == a<>1 AND a<>NULL
When comparing any value with NULL, SQL Server returns UNKNOWN. Either 1=NULL or NULL=NULL – both result in UNKNOWN. As far as we have AND in the expression, both sides return UNKNOWN.
I would like to point out that this case is not rare. For example, you mark a column as NOT NULL. After a while, another developer decides to permit NULLs for that column. This may lead to the situation, when a client report stops working once any NULL-value is inserted in the table.
In this case, I would recommend excluding NULL values:
SELECT *
FROM @t1
WHERE t1 NOT IN (
SELECT t2
FROM @t2
WHERE t2 IS NOT NULL
)
In addition, it is possible to use EXCEPT:
SELECT * FROM @t1 EXCEPT SELECT * FROM @t2
Alternatively, you may use NOT EXISTS:
SELECT *
FROM @t1
WHERE NOT EXISTS(
SELECT 1
FROM @t2
WHERE t1 = t2
)
Which option is more preferable? The latter option with NOT EXISTS seems to be the most productive as it generates the more optimal predicate pushdown operator to access data from the second table.
Actually, the NULL values may return an unexpected result.
Consider it on this particular example:
USE AdventureWorks2014 GO SELECT COUNT_BIG(*) FROM Production.Product SELECT COUNT_BIG(*) FROM Production.Product WHERE Color = 'Grey' SELECT COUNT_BIG(*) FROM Production.Product WHERE Color <> 'Grey'
As you can see, you have not got the expected result for the reason that NULL values have separate comparison operators:
SELECT COUNT_BIG(*) FROM Production.Product WHERE Color IS NULL SELECT COUNT_BIG(*) FROM Production.Product WHERE Color IS NOT NULL
Here is another example with CHECK constraints:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
CREATE TABLE #temp (
Color VARCHAR(15) --NULL
, CONSTRAINT CK CHECK (Color IN ('Black', 'White'))
)
We create a table with a permission to insert only white and black colors:
INSERT INTO #temp VALUES ('Black')
(1 row(s) affected)
Everything works as expected.
INSERT INTO #temp VALUES ('Red')
The INSERT statement conflicted with the CHECK constraint...
The statement has been terminated.
Now, let’s add NULL:
INSERT INTO #temp VALUES (NULL) (1 row(s) affected)
Why the CHECK constraint passed the NULL value? Well, the reason is that there is enough the NOT FALSE condition to make a record. The workaround is to explicitly define a column as NOT NULL or use NULL in the constraint.
Date format
Very often, you may have difficulties with data types.
For example, you need to get the current date. To do this, you can use the GETDATE function:
SELECT GETDATE()
Then just copy the returned result in a required query, and delete the time:
SELECT * FROM sys.objects WHERE create_date < '2016-11-14'
Is that correct?
The date is specified by a string constant:
SET LANGUAGE English
SET DATEFORMAT DMY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4
All values have a one-valued interpretation:
----------- ----------- ----------- ----------- 2016-12-05 2016-05-12 2016-05-12 2016-12-05
It will not cause any issues until the query with this business logic is executed on another server where settings may differ:
SET DATEFORMAT MDY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4
Though, these options may lead to an incorrect interpretation of the date:
----------- ----------- ----------- ----------- 2016-05-12 2016-12-05 2016-12-05 2016-12-05
Furthermore, this code may lead both to a visible and latent bug.
Consider the following example. We need to insert data to a test table. On a test server everything works perfect:
DECLARE @t TABLE (a DATETIME)
INSERT INTO @t VALUES ('05/13/2016')
Still, on a client side this query will have issues as our server settings differ:
DECLARE @t TABLE (a DATETIME)
SET DATEFORMAT DMY
INSERT INTO @t VALUES ('05/13/2016')
Msg 242, Level 16, State 3, Line 28 The conversion of a varchar data type to a datetime data type resulted in an out-of-range value.
Thus, what format should we use to declare date constants? To answer this question, execute this query:
SET DATEFORMAT YMD
SET LANGUAGE English
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4
GO
SET LANGUAGE Deutsch
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4
The interpretation of constants may differ depending on the installed language:
----------- ----------- ----------- -----------
2016-01-12 2016-01-12 2016-01-12 2016-01-12
----------- ----------- ----------- -----------
2016-12-01 2016-12-01 2016-01-12 2016-01-12
Thus, it is better to use the last two options. Also, I would like to add that to explicitly specify the date is not a good idea:
SET LANGUAGE French DECLARE @d DATETIME = '12-jan-2016' Msg 241, Level 16, State 1, Line 29 Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.
Therefore, if you want constants with the dates to be interpreted correctly, then you need to specify them in the following format YYYYMMDD.
In addition, I would like to draw your attention to the behavior of some data types:
SET LANGUAGE English
SET DATEFORMAT YMD
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2
GO
SET LANGUAGE Deutsch
SET DATEFORMAT DMY
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2
Unlike DATETIME, the DATE type is interpreted correctly with various settings on a server:
---------- ---------- 2016-01-12 2016-01-12 ---------- ---------- 2016-01-12 2016-12-01
Date filter
To move on, we will consider how to filter data effectively. Let’s start from them DATETIME/DATE:
USE AdventureWorks2014 GO UPDATE TOP(1) dbo.DatabaseLog SET PostTime = '20140716 12:12:12'
Now, we will try to find out how many rows the query returns for a specified day:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime = '20140716'
The query will return 0. When building an execution plan, SQL server is trying to cast a string constant to the data type of the column which we need to filter out:
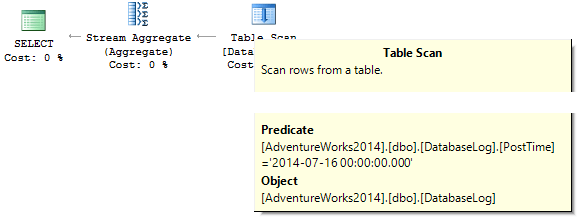
Create an index:
CREATE NONCLUSTERED INDEX IX_PostTime ON dbo.DatabaseLog (PostTime)
There are correct and incorrect options to output data. For example, you need to delete the time column:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CONVERT(CHAR(8), PostTime, 112) = '20140716' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CAST(PostTime AS DATE) = '20140716'
Or we need to specify a range:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140716' AND PostTime < '20140717'
Taking into account optimization, I can say that these two queries are the most correct ones. The point is that all conversion and calculations of index columns that are being filtered out may decrease performance drastically and raise time of logic readings:
Table 'DatabaseLog'. Scan count 1, logical reads 7, ... Table 'DatabaseLog'. Scan count 1, logical reads 2, ...
The PostTime field had not been included in the index before, and we could not see any efficiency in using this correct approach in filtering. Another thing is when we need to output data for a month:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE DATEPART(YEAR, PostTime) = 2014
AND DATEPART(MONTH, PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE YEAR(PostTime) = 2014
AND MONTH(PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE EOMONTH(PostTime) = '20140731'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140701' AND PostTime < '20140801'
Again, the latter option is more preferable:
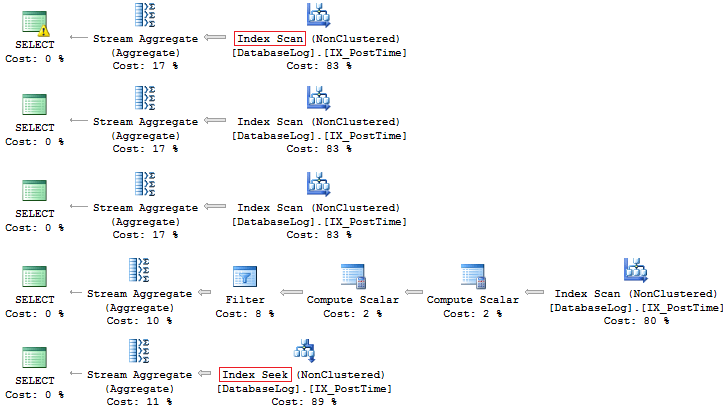
In addition, you can always create an index based on a calculated field:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL
ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDay
GO
ALTER TABLE dbo.DatabaseLog
ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTED
GO
CREATE INDEX IX_MonthLastDay ON dbo.DatabaseLog (MonthLastDay)
In comparison with the previous query, the difference in logical readings may be significant (if large tables are in question):
SET STATISTICS IO ON SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140701' AND PostTime < '20140801' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE MonthLastDay = '20140731' SET STATISTICS IO OFF Table 'DatabaseLog'. Scan count 1, logical reads 7, ... Table 'DatabaseLog'. Scan count 1, logical reads 3, ...
Calculation
As it has been already discussed, any calculations on index columns decrease performance and raise time of logic reads:
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID * 2 = 10000 SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID = 2500 * 2 SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID = 5000 Table 'Person'. Scan count 1, logical reads 67, ... Table 'Person'. Scan count 0, logical reads 3, ...
If we look at the execution plans, then in the first one, SQL Server executes IndexScan:
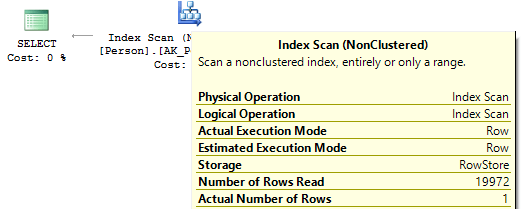
Then, when there are no calculations on the index columns, we will see IndexSeek:
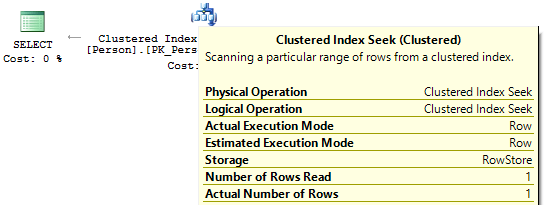
Convert implicit
Let’s have a look at these two queries that filter by the same value:
USE AdventureWorks2014 GO SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = 30845 SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = '30845'
The execution plans provide the following information:
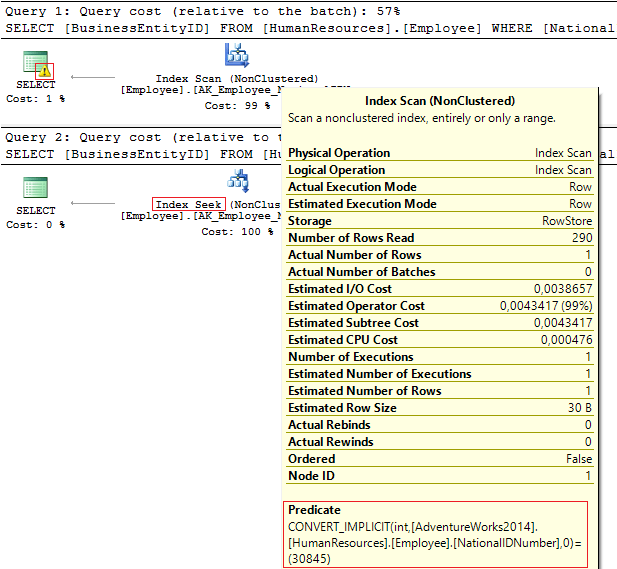
- Warning and IndexScan on the first plan
- IndexSeek – on the second one.
Table 'Employee'. Scan count 1, logical reads 4, ... Table 'Employee'. Scan count 0, logical reads 2, ...
The NationalIDNumber column has the NVARCHAR(15) data type. The constant we use to filter data out is set as INT which leads us to an implicit data type conversion. In its turn, it may decrease performance. You can monitor it when someone modifies the data type in the column, however, the queries are not changed.
It is important to understand that an implicit data type conversion may lead to errors at runtime. For example, before the PostalCode field was numeric, it turned out that a postal code could contain letters. Thus, the data type was updated. Still, if we insert an alphabetic postal code, then the old query will no longer work:
SELECT AddressID FROM Person.[Address] WHERE PostalCode = 92700 SELECT AddressID FROM Person.[Address] WHERE PostalCode = '92700' Msg 245, Level 16, State 1, Line 16 Conversion failed when converting the nvarchar value 'K4B 1S2' to data type int.
Another example is when you need to use EntityFramework on the project, which by default interprets all row fields as Unicode:
SELECT CustomerID, AccountNumber FROM Sales.Customer WHERE AccountNumber = N'AW00000009' SELECT CustomerID, AccountNumber FROM Sales.Customer WHERE AccountNumber = 'AW00000009'
Therefore, incorrect queries are generated:
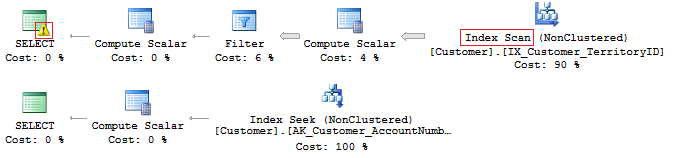
To solve this issue, make sure that data types match.
LIKE & Suppressed index
In fact, having a covering index does not mean that you will use it effectively.
Let’s check it on this particular example. Assume we need to output all the rows that start with…
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT AddressLine1 FROM Person.[Address] WHERE SUBSTRING(AddressLine1, 1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE LEFT(AddressLine1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE CAST(AddressLine1 AS CHAR(3)) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '100%'
We will get the following logic readings and execution plans:
Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 4, ...
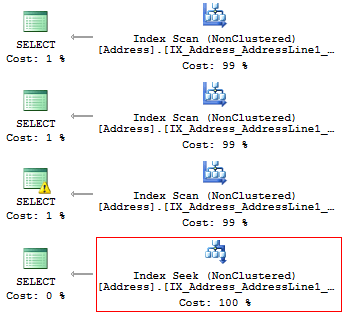
Thus, if there is an index, it should not contain any calculations or conversion of types, functions, etc.
But what do you do if you need to find the occurrence of a substring in a string?
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'v
We will come back to this question later.
Unicode vs ANSI
It is important to remember that there are the UNICODE and ANSI strings. The UNICODE type includes NVARCHAR/NCHAR (2 bytes to one symbol). To store ANSI strings, it is possible to use VARCHAR/CHAR (1 byte to 1 symbol). There is also TEXT/NTEXT, but I do not recommend using them as they may decrease performance.
If you specify a Unicode constant in a query, then it is necessary to precede it with the N symbol. To check it, execute the following query:
SELECT '文本 ANSI'
, N'文本 UNICODE'
------- ------------
?? ANSI 文本 UNICODE
If N does not precede the constant, then SQL Server will try to find a suitable symbol in the ANSI coding. If it fails to find, then it will show a question mark.
COLLATE
Very often, when being interviewed to the position Middle/Senior DB Developer, an interviewer often asks the following question: Will this query return the data?
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @b
It depends. Firstly, the N symbol does not precede a string constant, thus, it will be interpreted as ANSI. Secondly, a lot depends on the current COLLATE value, which is a set of rules, when selecting and comparing string data.
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CI_AS
GO
USE test
GO
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @b
This COLLATE statement will return question marks as their symbols are equal:
---- ---- ? ?
If we change the COLLATE statement for another statement:
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_AS
In this case, the query will return nothing, as Cyrillic characters will be interpreted correctly.
Therefore, if a string constant takes up UNICODE, then it is necessary to set N preceding a string constant. Still, I would not recommend setting it everywhere for the reasons we have discussed above.
Another question to be asked on the interview refers to rows comparison.
Consider the following example:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a = @b, 'TRUE', 'FALSE')
Are these rows equal? To check this, we need to explicitly specify COLLATE:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a COLLATE Latin1_General_CS_AS = @b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
As there are the case-sensitive (CS) and case-insensitive (CI) COLLATEs when comparing and selecting rows, we cannot say for sure if they are equal. In addition, there are various COLLATEs both on a test server and a client side.
There is a case when COLLATEs of a target base and tempdb do not match.
Create a database with COLLATE:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Albanian_100_CS_AS
GO
USE test
GO
CREATE TABLE t (c CHAR(1))
INSERT INTO t VALUES ('a')
GO
IF OBJECT_ID('tempdb.dbo.#t1') IS NOT NULL
DROP TABLE #t1
IF OBJECT_ID('tempdb.dbo.#t2') IS NOT NULL
DROP TABLE #t2
IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL
DROP TABLE #t3
GO
CREATE TABLE #t1 (c CHAR(1))
INSERT INTO #t1 VALUES ('a')
CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)
INSERT INTO #t2 VALUES ('a')
SELECT c = CAST('a' AS CHAR(1))
INTO #t3
DECLARE @t TABLE (c VARCHAR(100))
INSERT INTO @t VALUES ('a')
SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation')
UNION ALL
SELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')
UNION ALL
SELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM t
UNION ALL
SELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t1
UNION ALL
SELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t2
UNION ALL
SELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3
UNION ALL
SELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @t
When creating a table, it inherits COLLATE from a database. The only difference for the first temporary table, for which we determine a structure explicitly without COLLATE, is that it inherits COLLATE from the tempdb database.
------ -------------------------- tempdb Cyrillic_General_CI_AS test Albanian_100_CS_AS t Albanian_100_CS_AS #t1 Cyrillic_General_CI_AS #t2 Albanian_100_CS_AS #t3 Albanian_100_CS_AS @t Albanian_100_CS_AS
I will describe the case when COLLATEs do not match on the particular example with #t1.
For example, data is not filtered out correctly, as COLLATE may not take into account a case:
SELECT * FROM #t1 WHERE c = 'A'
Alternatively, we may have a conflict to connect tables with different COLLATEs:
SELECT * FROM #t1 JOIN t ON [#t1].c = t.c
Everything seems to be working perfect on a test server, whereas on a client server we get an error:
Msg 468, Level 16, State 9, Line 93 Cannot resolve the collation conflict between "Albanian_100_CS_AS" and "Cyrillic_General_CI_AS" in the equal to operation.
To work around it, we have to set hacks everywhere:
SELECT * FROM #t1 JOIN t ON [#t1].c = t.c COLLATE database_default
BINARY COLLATE
Now, we will find out how to use COLLATE for your benefit.
Consider the example with the occurrence of a substring in a string:
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'
It is possible to optimize this query and reduce its execution time.
At first, we need to generate a large table:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CS_AS
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test', SIZE = 64MB)
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test_log', SIZE = 64MB)
GO
USE test
GO
CREATE TABLE t (
ansi VARCHAR(100) NOT NULL
, unicod NVARCHAR(100) NOT NULL
)
GO
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E8(N) AS (SELECT 1 FROM E4 a, E4 b)
INSERT INTO t
SELECT v, v
FROM (
SELECT TOP(50000) v = REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '')
FROM E8
) t
Create calculated columns with binary COLLATEs and indexes:
ALTER TABLE t
ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2
ALTER TABLE t
ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2
CREATE NONCLUSTERED INDEX ansi ON t (ansi)
CREATE NONCLUSTERED INDEX unicod ON t (unicod)
CREATE NONCLUSTERED INDEX ansi_bin ON t (ansi_bin)
CREATE NONCLUSTERED INDEX unicod_bin ON t (unicod_bin)
Execute the filtration process:
SET STATISTICS TIME, IO ON SELECT COUNT_BIG(*) FROM t WHERE ansi LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE unicod LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SELECT COUNT_BIG(*) FROM t WHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SET STATISTICS TIME, IO OFF
As you can see, this query returns the following result:
SQL Server Execution Times: CPU time = 350 ms, elapsed time = 354 ms. SQL Server Execution Times: CPU time = 335 ms, elapsed time = 355 ms. SQL Server Execution Times: CPU time = 16 ms, elapsed time = 18 ms. SQL Server Execution Times: CPU time = 17 ms, elapsed time = 18 ms.
The point is that filter based on the binary comparison takes less time. Thus, if you need to filter occurrence of strings frequently and quickly, then it is possible to store data with COLLATE ending with BIN. Though, it should be noted that all binary COLLATEs are case sensitive.
Code style
A style of coding is strictly individual. Still, this code should be simply maintained by other developers and match certain rules.
Create a separate database and a table inside:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_CI_AS
GO
USE test
GO
CREATE TABLE dbo.Employee (EmployeeID INT PRIMARY KEY)
Then, write the query:
select employeeid from employee
Now, change COLLATE to any case-sensitive one:
ALTER DATABASE test COLLATE Latin1_General_CS_AI
Then, try to execute the query again:
Msg 208, Level 16, State 1, Line 19 Invalid object name 'employee'.
An optimizer uses rules for the current COLLATE at the binding step when it checks for tables, columns and other objects as well as it compares each object of the syntax tree with a real object of a system catalog.
If you want to generate queries manually, then you need to always use the correct case in object names.
As for variables, COLLATEs are inherited from the master database. Thus, you need to use the correct case to work with them as well:
SELECT DATABASEPROPERTYEX('master', 'collation')
DECLARE @EmpID INT = 1
SELECT @empid
In this case, you will not get an error:
----------------------- Cyrillic_General_CI_AS ----------- 1
Still, a case error may appear on another server:
-------------------------- Latin1_General_CS_AS Msg 137, Level 15, State 2, Line 4 Must declare the scalar variable "@empid".
[var]char
As you know, there are fixed (CHAR, NCHAR) and variable (VARCHAR, NVARCHAR) data types:
DECLARE @a CHAR(20) = 'text'
, @b VARCHAR(20) = 'text'
SELECT LEN(@a)
, LEN(@b)
, DATALENGTH(@a)
, DATALENGTH(@b)
, '"' + @a + '"'
, '"' + @b + '"'
SELECT [a = b] = IIF(@a = @b, 'TRUE', 'FALSE')
, [b = a] = IIF(@b = @a, 'TRUE', 'FALSE')
, [a LIKE b] = IIF(@a LIKE @b, 'TRUE', 'FALSE')
, [b LIKE a] = IIF(@b LIKE @a, 'TRUE', 'FALSE')
If a row has a fixed length, say 20 symbols, but you have written only 4 symbols, then SQL Server will add 16 blanks on the right by default:
--- --- ---- ---- ---------------------- ---------------------- 4 4 20 4 "text " "text"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a = b b = a a LIKE b b LIKE a ----- ----- -------- -------- TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1 WHERE 'a ' LIKE 'a' SELECT 1 WHERE 'a' LIKE 'a ' -- !!! SELECT 1 WHERE 'a' LIKE 'a' SELECT 1 WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL
, @b VARCHAR(10) = '0.1'
, @c SQL_VARIANT
SELECT @a = @b
, @c = @a
SELECT @a
, @c
, SQL_VARIANT_PROPERTY(@c,'BaseType')
, SQL_VARIANT_PROPERTY(@c,'Precision')
, SQL_VARIANT_PROPERTY(@c,'Scale')
As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- ----- 0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ---- 40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions: ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) = NULL SELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL') DECLARE @i INT = NULL SELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ---- N NULL ---- ---- 7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3 SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
----------- 0 ----------- 0.333333
Also, let’s consider this particular example:
SELECT COUNT(*)
, COUNT(1)
, COUNT(val)
, COUNT(DISTINCT val)
, SUM(val)
, SUM(DISTINCT val)
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val)
SELECT AVG(val)
, SUM(val) / COUNT(val)
, AVG(val * 1.)
, AVG(CAST(val AS FLOAT))
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val)
This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id] FROM sys.system_objects UNION SELECT [object_id] FROM sys.objects SELECT [object_id] FROM sys.system_objects UNION ALL SELECT [object_id] FROM sys.objects
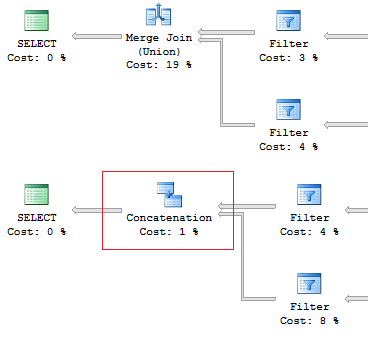
Also, I would like to point out the difference of these operators: the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)
SET @AddressLine = '4775 Kentucky Dr.'
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
OR AddressLine2 = @AddressLine
As we have OR in the statement, we will receive IndexScan:
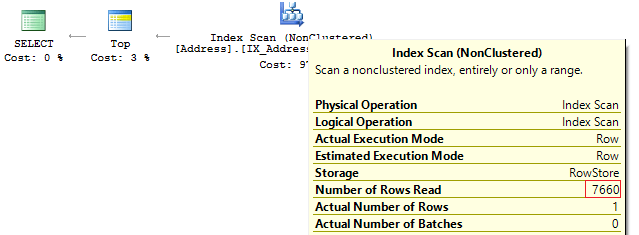
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressID
FROM (
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
UNION ALL
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine2 = @AddressLine
) t
When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
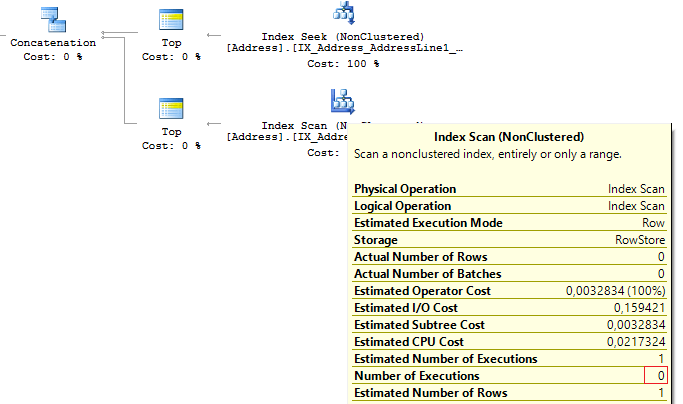
Table 'Worktable'. Scan count 0, logical reads 0, ... Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT e.BusinessEntityID
, (
SELECT p.LastName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
, (
SELECT p.FirstName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
FROM HumanResources.Employee e
SELECT e.BusinessEntityID
, p.LastName
, p.FirstName
FROM HumanResources.Employee e
JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ... Table 'Employee'. Scan count 1, logical reads 2, ... Table 'Person'. Scan count 0, logical reads 888, ... Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT p.BusinessEntityID
, (
SELECT s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
)
FROM Person.Person p
However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6 Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID
, (
SELECT TOP(1) s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
ORDER BY s.QuotaDate DESC
)
FROM Person.Person p
SELECT p.BusinessEntityID
, t.SalesQuota
FROM Person.Person p
OUTER APPLY (
SELECT TOP(1) s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
ORDER BY s.QuotaDate DESC
) t
When executing these queries, we will get the same issue – multiple IndexSeek operators:
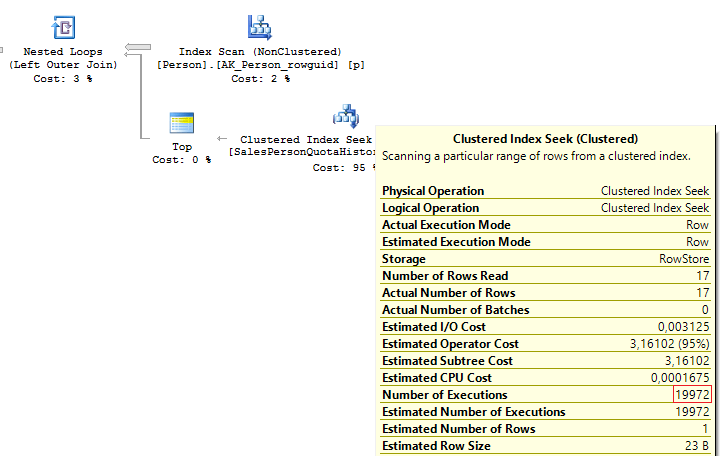
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ... Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID
, t.SalesQuota
FROM Person.Person p
LEFT JOIN (
SELECT s.BusinessEntityID
, s.SalesQuota
, RowNum = ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC)
FROM Sales.SalesPersonQuotaHistory s
) t ON p.BusinessEntityID = t.BusinessEntityID
AND t.RowNum = 1
We get the following result:
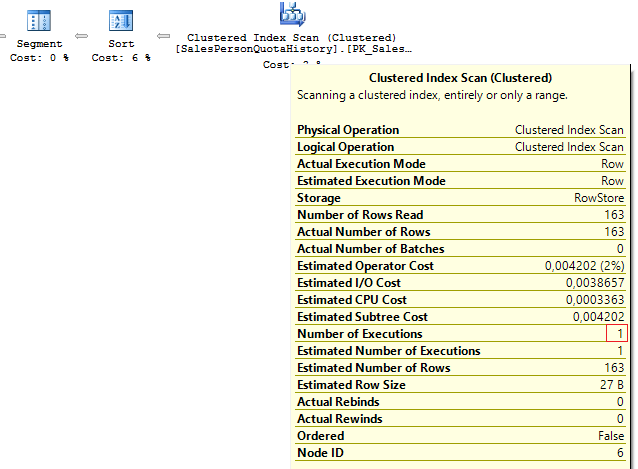
Table 'Person'. Scan count 1, logical reads 67, ... Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014
GO
SELECT BusinessEntityID
, Gender
, Gender =
CASE Gender
WHEN 'M' THEN 'Male'
WHEN 'F' THEN 'Female'
ELSE 'Unknown'
END
FROM HumanResources.Employee
SQL Server will decompose the statement to the following:
SELECT BusinessEntityID
, Gender
, Gender =
CASE
WHEN Gender = 'M' THEN 'Male'
WHEN Gender = 'F' THEN 'Female'
ELSE 'Unknown'
END
FROM HumanResources.Employee
Thus, this will lead to the main issue: each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL
DROP FUNCTION dbo.GetMailUrl
GO
CREATE FUNCTION dbo.GetMailUrl
(
@Email NVARCHAR(50)
)
RETURNS NVARCHAR(50)
AS BEGIN
RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))
END
Then, configure SQL Profiler to build SQL events: StmtStarting / SP:StmtCompleted (if you want to do this with XEvents: sp_statement_starting / sp_statement_completed).
Execute the query:
SELECT TOP(10) EmailAddressID
, EmailAddress
, CASE dbo.GetMailUrl(EmailAddress)
--WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM Person.EmailAddress
The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID
, EmailAddress
, CASE dbo.GetMailUrl(EmailAddress)
WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM Person.EmailAddress
In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID
, EmailAddress
, CASE MailUrl
WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM (
SELECT TOP(10) EmailAddressID
, EmailAddress
, MailUrl = dbo.GetMailUrl(EmailAddress)
FROM Person.EmailAddress
) t
In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT
CASE
WHEN Gender = 'M' THEN 'Male'
WHEN Gender = 'M' THEN '...'
WHEN Gender = 'M' THEN '......'
WHEN Gender = 'F' THEN 'Female'
WHEN Gender = 'F' THEN '...'
ELSE 'Unknown'
END
FROM HumanResources.Employee
Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT = 1
SELECT
CASE WHEN @i = 1
THEN 1
ELSE 1/0
END
GO
DECLARE @i INT = 1
SELECT
CASE WHEN @i = 1
THEN 1
ELSE MIN(1/0)
END
Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014
GO
UPDATE TOP(1) Person.[Address]
SET AddressLine2 = AddressLine1
GO
IF OBJECT_ID('dbo.isEqual') IS NOT NULL
DROP FUNCTION dbo.isEqual
GO
CREATE FUNCTION dbo.isEqual
(
@val1 NVARCHAR(100),
@val2 NVARCHAR(100)
)
RETURNS BIT
AS BEGIN
RETURN
CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 = @val2
THEN 1
ELSE 0
END
END
The queries return the identical data:
SET STATISTICS TIME ON
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE dbo.IsEqual(AddressLine1, AddressLine2) = 1
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL)
OR AddressLine1 = AddressLine2
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE AddressLine1 = ISNULL(AddressLine2, '')
SET STATISTICS TIME OFF
However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times: CPU time = 63 ms, elapsed time = 57 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL
DROP FUNCTION dbo.GetPI
GO
CREATE FUNCTION dbo.GetPI ()
RETURNS FLOAT
WITH SCHEMABINDING
AS BEGIN
RETURN PI()
END
GO
SELECT dbo.GetPI()
FROM Sales.Currency
In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL
DROP TABLE dbo.tbl
GO
CREATE TABLE dbo.tbl (a INT, b INT)
GO
INSERT INTO dbo.tbl VALUES (0, 1)
GO
IF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL
DROP VIEW dbo.vw_tbl
GO
CREATE VIEW dbo.vw_tbl
AS
SELECT * FROM dbo.tbl
GO
SELECT * FROM dbo.vw_tbl
As you can see, we get the correct result:
a b ----------- ----------- 0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl
ADD c INT NOT NULL DEFAULT 2
GO
SELECT * FROM dbo.vw_tbl
We receive the same result:
a b ----------- ----------- 0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname = N'dbo.vw_tbl' GO SELECT * FROM dbo.vw_tbl
Result:
a b c ----------- ----------- ----------- 0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployee
AS
SELECT e.BusinessEntityID
, p.Title
, p.FirstName
, p.MiddleName
, p.LastName
, p.Suffix
, e.JobTitle
, pp.PhoneNumber
, pnt.[Name] AS PhoneNumberType
, ea.EmailAddress
, p.EmailPromotion
, a.AddressLine1
, a.AddressLine2
, a.City
, sp.[Name] AS StateProvinceName
, a.PostalCode
, cr.[Name] AS CountryRegionName
, p.AdditionalContactInfo
FROM HumanResources.Employee e
JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID
JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID = e.BusinessEntityID
JOIN Person.[Address] a ON a.AddressID = bea.AddressID
JOIN Person.StateProvince sp ON sp.StateProvinceID = a.StateProvinceID
JOIN Person.CountryRegion cr ON cr.CountryRegionCode = sp.CountryRegionCode
LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID = p.BusinessEntityID
LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID = pnt.PhoneNumberTypeID
LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID = ea.BusinessEntityID
What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID
, FirstName
, LastName
FROM HumanResources.vEmployee
SELECT p.BusinessEntityID
, p.FirstName
, p.LastName
FROM Person.Person p
WHERE p.BusinessEntityID IN (
SELECT e.BusinessEntityID
FROM HumanResources.Employee e
)
Look at the execution plan in the case of using a view:
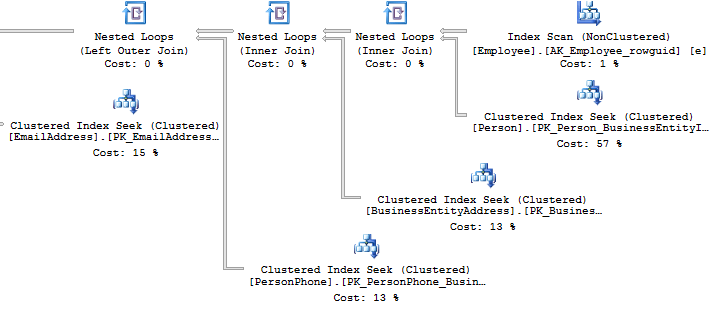
Table 'EmailAddress'. Scan count 290, logical reads 640, ... Table 'PersonPhone'. Scan count 290, logical reads 636, ... Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ... Table 'Person'. Scan count 0, logical reads 897, ... Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:

Table 'Person'. Scan count 0, logical reads 897, ... Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INT
DECLARE cur CURSOR FOR
SELECT BusinessEntityID
FROM HumanResources.Employee
OPEN cur
FETCH NEXT FROM cur INTO @BusinessEntityID
WHILE @@FETCH_STATUS = 0 BEGIN
UPDATE HumanResources.Employee
SET VacationHours = 0
WHERE BusinessEntityID = @BusinessEntityID
FETCH NEXT FROM cur INTO @BusinessEntityID
END
CLOSE cur
DEALLOCATE cur
Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.Employee SET VacationHours = 0 WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL
DROP TABLE #t
GO
CREATE TABLE #t (i CHAR(1))
INSERT INTO #t
VALUES ('1'), ('2'), ('3')
Then, assign values to the variable:
DECLARE @txt VARCHAR(50) = '' SELECT @txt += i FROM #t SELECT @txt -------- 123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) = '' SELECT @txt += i FROM #t ORDER BY LEN(i) SELECT @txt -------- 3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] = i
FROM #t
FOR XML PATH('')
--------
123
It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF((
SELECT ', ' + c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
------------------------ ------------------------------------
ScrapReason ScrapReasonID, Name, ModifiedDate
Shift ShiftID, Name, StartTime, EndTime
In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
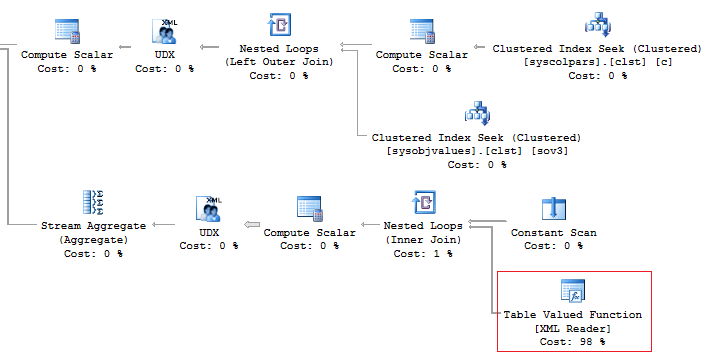
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF((
SELECT ', ' + c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name
, STUFF((
SELECT ', ' + c.name
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH('')), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
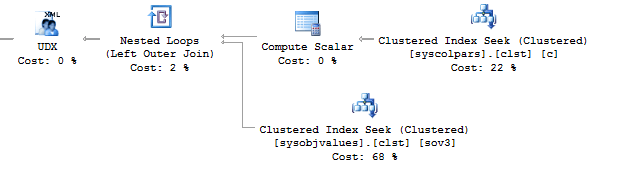
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name
, STUFF((
SELECT ', ' + CHAR(13) + c.name
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH('')), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’….
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX) SET @param = 1 DECLARE @SQL NVARCHAR(MAX) SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = ' + @param PRINT @SQL EXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1
If we add any additional value to the property,
SET @param = '1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn = new SqlConnection())
{
conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true";
conn.Open();
SqlCommand command = new SqlCommand(
string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id = {0}", value), conn);
using (SqlDataReader reader = command.ExecuteReader())
{
while (reader.Read()) {}
}
}
When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)
SET @param = '1; select ''hack'''
DECLARE @SQL NVARCHAR(MAX)
SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id'
PRINT @SQL
EXEC sys.sp_executesql @SQL
, N'@schema_id INT'
, @schema_id = @param
It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn = new SqlConnection())
{
conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true";
conn.Open();
SqlCommand command = new SqlCommand(
"SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id", conn);
command.Parameters.Add(new SqlParameter("schema_id", value));
...
}
Summary
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.
Tags: query performance, sql constraints, sql server, t-sql, tips and tricks Last modified: September 23, 2021





