When adding or modifying a large number of records (10³ and more), the Entity Framework performance is far from perfect. The reasons are architectural peculiarities of the framework, and non-optimality of the generated SQL. Leaping ahead, I can reveal that saving data through a bypass of the context significantly minimizes the execution time.
Contents
- Insert/Update with the standard means of Entity Framework
- In search of solution for the problem
- Integration of Entity Framework and SqlBulkCopy
- Advanced insert with MERGE
- Performance comparison
- Conclusion
Insert/Update with the Standard Means of Entity Framework
Let’s start with Insert. A standard way of adding new records to a DB is adding them to the context with the subsequent saving:
context.Orders.Add(order);
context.SaveChanges();
Each call of the Add method leads to an ‘expensive’ (in terms of execution) call of the DetectChanges internal algorithm. This algorithm scans all entities in the context, compares the current value of each property with a source value that is stored in the context, and updates links between entities, etc. Until the release of EF6, disabling DetectChanges for the time of adding entities to the content was the most popular way to improve performance:
context.Orders.Add(order));
context.Configuration.AutoDetectChangesEnabled = true;
context.SaveChanges();
Also, it is not recommended to store dozens of thousands of objects in the context, as well as to save data in blocks with saving context and creating a new context for each N objects, as it is shown here. Finally, the optimized AddRange method has been introduced in EF 6. The method improves performance up to the level of the Add+AutoDetectChangesEnabled binding:
context.Orders.AddRange(orders);
context.SaveChanges();
Unfortunately, the methods listed above do not solve the core problem, that is: during saving data into DB, a separate INSERT query is being generated for each new record!
INSERT [dbo].[Order]([Date], [Number], [Text]) VALUES (@0, @1, NULL)
The situation with Update is the same. The following code:
var orders = context.Orders.ToList();
//.. writing new data
context.SaveChanges();
leads to execution of a separate SQL query for each modified object:
UPDATE [dbo].[Order]
SET [Text] = @0
WHERE ([Id] = @1)
In the most simple cases, EntityFramework.Extended can help:
//update all tasks with status of 1 to status of 2
context.Tasks.Update(
t => t.StatusId == 1,
t2 => new Task { StatusId = 2 });
This code is executed through a bypass of the context and generates 1 SQL query. Obviously, this solution is not universal and serves only for the recording the same value into all target rows.
In Search of Solution for the Problem
Since I hate reinventing the wheel, I started searching for the best practices of the bulk insert with EF. It seemed to be a typical task, but I failed to find a suitable solution ‘out of the box’. At the same time, SQL Server offers a range of quick insert techniques, such as the bcp utility and the SqlBulkCopy class. I will further consider the latter class in detail.
System.Data.SqlClient.SqlBulkCopy is an ADO.NET class for witting large volumes of data into SQL Server tables. It can use DataRow[], DataTable, or implementation of IdataReader as a data source.
It can:
- send data to the server block-by-block with support for transactions;
- execute column mapping from DataTable against the DB table;
- ignore constraints, foreign keys during insert (optional).
Cons:
- insert atomicity (optional);
- failure to continue work after exception;
- weak error processing options.
Let’s go back to our problem – absence of the SqlBulkCopy and EF integration. There is no conventional approach to solving this task, but there are several projects, such as:
It turned out practically not working. When I was studying Issues, I stumbled upon a discussion with Julie Lerman who described a problem similar to mine that remained unanswered.
Alive project, active community. No support for Database First, but developers promise to implement it.
Integration of Entity Framework and SqlBulkCopy
Let’s try to do everything on our own. In the most simple case, the data insert from the object collection with SqlBulkCopy looks in the following way:
//entities - entity collection EntityFramework
using (IDataReader reader = entities.GetDataReader())
using (SqlConnection connection = new SqlConnection(connectionString))
using (SqlBulkCopy bcp = new SqlBulkCopy(connection))
{
connection.Open();
bcp.DestinationTableName = "[Order]";
bcp.ColumnMappings.Add("Date", "Date");
bcp.ColumnMappings.Add("Number", "Number");
bcp.ColumnMappings.Add("Text", "Text");
bcp.WriteToServer(reader);
}
The task to implement IdataReader on the basis of the object collection is rather trivial, so I put here a link and switch to the ways of error handling during insert with SqlBulkCopy. By default, data insert is handled in its own transaction. When exception occurs, SqlException is thrown and rollback takes place. That is, data in DB will not be written at all, and ‘native’ error notifications of this class are far from being informative. For example, SqlException.AdditionalInformation can contain the following:
The given value of type String from the data source cannot be converted to type nvarchar of the specified target column.
or:
SqlDateTime overflow. Must be between 1/1/1753 12:00:00 AM and 12/31/9999 11:59:59 PM.
Unfortunately, SqlBulkCopy does not provide information allowing to detect a row/entity that caused the error. There in one more con – during my attempt to insert a row duplicate by the primary key, SqlBulkCopy throws exception and stops working without an option to process the situation and continue execution.
Mapping
In the case of the correctly generated instances and DB, the type correspondence checks and table filed length checks (like here) become obsolete. Instead, let’s look into column mapping handled with the SqlBulkCopy.ColumnMappings property.
If the data source and the destination table have the same number of columns, and the ordinal position of each source column within the data source matches the ordinal position of the corresponding destination column, the P:System.Data.SqlClient.SqlBulkCopy.ColumnMappings collection is unnecessary. However, if the column counts differ, or the ordinal positions are not consistent, you must use ColumnMappings to make sure that data is copied into the correct columns.
In 99% of cases, you will need to explicitly set ColumnMappings for EF (because of navigation properties and any additional properties.). The navigation properties can be eliminated with Reflection:
var columns = typeof(Order).GetProperties()
.Where(property =>
property.PropertyType.IsValueType
|| property.PropertyType.Name.ToLower() == "string")
.Select(property => property.Name)
.ToList();
Such code is good for the POCO class without additional properties. Otherwise, we have to switch to ‘manual control’. Getting the table schema is simple as well:
private static List GetColumns(SqlConnection connection)
{
string[] restrictions = { null, null, "", null };
var columns = connection.GetSchema("Columns", restrictions)
.AsEnumerable()
.Select(s => s.Field("Column_Name"))
.ToList();
return columns;
}
It allows us to map source class and target table manually.
Usage of the SqlBulkCopy.BatchSize Propety and SqlBulkCopyOptions Class
SqlBulkCopy.BatchSize:
[table id=9 /]
qlBulkCopyOptions — enumeration:
[table id=10 /]
Optionally, we can enable the check for triggers and limitations on the DB side (disabled by default). When BatchSize and UseInternalTransaction are specified, data is sent to the server by blocks in separate transactions. Therefore, all successful blocks will be being saved to DB until the first erratic block.
Advanced Insert with MERGE
SqlBulkCopy can only add records to a table, and does not provide any functionality for modification of existing records. Nevertheless, we can speed up execution of the Update operations! How? – We can insert data into an empty table, and then synchronize tables with help of the MERGE statement, that was initially introduced in SQL Server 2008:
MERGE (Transact-SQL)
Performs insert, update, or delete operations on a target table based on the results of a join with a source table. For example, you can synchronize two tables by inserting, updating, or deleting rows in one table based on differences found in the other table.
With MERGE, we can easily implement various duplicate processing logic: updating data in the target table, or ignoring (even deleting) identical records. Therefore, we can save data from the EF object collection into DB, according to the following algorithm:
- Creation/deletion of a temporary table that is fully identical to the source table.
- Inserting data with SqlBulkCopy into the temporary table.
- Using MERGE to add records from temporary table to the target table.
Let’s consider steps 1 and 3 in detail.
Temporary table
We need to create a table in DB that would repeat schema of a table for data insert. Creating copies manually is the worst option, since the further comparison and synchronization of table schemas will fall on your shoulders. More reliable option is to copy schema programmatically right before the insert. For example with help of SQL Server Management Objects (SMO):
Server server = new Server();
//SQL auth
server.ConnectionContext.LoginSecure = false;
server.ConnectionContext.Login = "login";
server.ConnectionContext.Password = "password";
server.ConnectionContext.ServerInstance = "server";
Database database = server.Databases["database name"];
Table table = database.Tables["Order"];
ScriptingOptions options = new ScriptingOptions();
options.Default = true;
options.DriAll = true;
StringCollection script = table.Script(options);
It’s worth paying attention to the ScriptingOptions class containing several dozens of parameters for a profound setup of the generated SQL. We will deploy the resulting StringCollection in String. Unfortunately, I haven’t found a better solution than replacing name of the source table with name of the temporary table, like String.Replace(«Order», «Order_TEMP»). I will be grateful for suggesting a better solution for creating a table copy within a single DB. Let’s execute the scrip in any convenient way. Table copy has been created!
Nuances of SMO usage in .NET 4+
Note, that call of Database.ExecuteNonQuery in .NET 4+, throws an exception, like:
Mixed mode assembly is built against version ‘v2.0.50727’ of the runtime and cannot be loaded in the 4.0 runtime without additional configuration information.
The reason is that a great SMO library exists only for .NET 2 Runtime. Fortunately, there is a workaround:
...
The
other option is to use Database.ExecuteWithResults.
Copying data from temporary table to target table
The only thing left is to execute the MERGE statement that compares contents of the temporary and target tables and performs update or insert (if required). For instance, for the [Order] table, the code may look in the following way:
MERGE INTO [Order] AS [Target] USING [Order_TEMP] AS [Source] ON Target.Id = Source.Id WHEN MATCHED THEN UPDATE SET Target.Date = Source.Date, Target.Number = Source.Number, Target.Text = Source.Text WHEN NOT MATCHED THEN INSERT (Date, Number, Text) VALUES (Source.Date, Source.Number, Source.Text);
This SQL query compares records from the [Order_TEMP] temporary table with the records of the [Order] target table, and executes Update, if a record with identical value in the Id field is found, or Insert, if such record was not found. Let’s execute the code in any convenient way, and that’s it! Don’t forget to clean/delete temporary table.
Performance Comparison
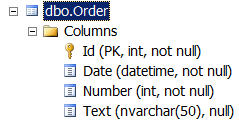
Execution environment: Visual Studio 2013, Entity Framework 6.1.1. (Database First), SQL Server 2012. The [Order] table was used for testing (the table schema was provided above). Execution time for approaches to saving data to DB described in this article has been measured. The results are provided below (time is specified in seconds):
Insert
[table id=11 /]
Wow! If we use the Add method for adding to the context and SaveChanges for saving, the saving of 100000 records to DB will take almost 2 hours! Meanwhile, SqlBulkCopy copes with the same task for less than a second!
Update
[table id=12 /]
Again, SqlBulkCopy is a hands-down leader. The source code of the test application is available at GitHub.
Conclusion
When working with the context, containing large number of objects (10³ and more), refusal of the Entity Framework infrastructure (adding to context + saving the context) and switch to SqlBulkCopy for adding records to DB can improve performance in dozens, and even hundreds of times. However, IMO, ubiquitous usage of the EF+SqlBulkCopy binding is an obvious signal that there is something wrong with the architecture of your application. The approach described in this article should be considered as a simple mean for improving performance in bottlenecks of the already written systems, if changing architecture/technology is for some reason is challenging. Any developer who uses Entity Framework must know strong and weak points of this tool. Good luck!
References:
EntityFramework: Add, AddRange
Secrets of DetectChanges
Performance Considerations for Entity Framework 4, 5, and 6
Entity Framework Performance
Entity Framework and slow bulk INSERTs
SqlBulkCopy
Using SqlBulkCopy To Perform Efficient Bulk SQL Operations
SqlBulkCopy+data reader
Creating a Generic List DataReader for SqlBulkCopy
SqlBulkCopy for Generic List
SqlBulkCopy+ MERGE
C# Bulk Upsert to SQL Server Tutorial




Have you you tried this library:
https://github.com/borisdj/EFCore.BulkExtensions
If you are worried about name conflict for orders_temp, you could use a GUID instead. newguid() is the function.
Hi there. Thanks for the nice write-up. Could you expand a little bit on how to make SqlBulkCopy operations and still remain in the same transaction associated with the current EF `DbContext`? I’ve checked other bulk libraries, and they all work with their own transaction, so they modify DB whether you later call `dbContext.SaveChanges()` or not. Is there a way to pass transaction “scope” from context to SqlBulkCopy, and to not commit bulk operations until final `SaveChanges()`? Thanks!
Hi. SqlBulkCopy use its own internal transaction by default and it also can use an external SqlTransaction (examples are here) as well as EF6. Thus, it is possible to share the same transaction for both EF and SqlBulkCopy operations. However, the recommended EF6 transaction pattern is to use TransactionScope. I would try to avoid the transaction sharing if possible due to complexity reasons.