Transaction logs are a vital and important component of database architecture. In this article, we’ll discuss SQL Server transaction logs, importance, and their role in the database migration.
Introduction
Let’s talk about different options for taking SQL Server backups. SQL Server supports three different types of Backups.
1. Full
2. Differential
3. Transaction-log
Before jumping into transaction-log concepts, let’s discuss other basic backup types in SQL Server.
A full backup is a copy of everything. As the name implies, it will back up everything. It will back up all of the data, every object of the database such as a file, file-group, table, etc: – A full backup is a base for any other type of backups.
A differential backup will back up data that has changed since the last full backup.
The third option is a Transaction-Log Backup, which will log all the statements that we issue to the database in the transaction log. The transaction log is a mechanism known as “WAL” (Write-Ahead-Logging). It writes every piece of information out to the transaction log first and then to the database. In other words, the process does not typically update the database directly. This is the only full available option with Full recovery model of the database. In other recovery models, data is either partial or there isn’t enough data in the log. For example, the log record when recording the start of a new transaction (the LOP_BEGIN_XACT log record) will contain the time the transaction started, and the LOP_COMMIT_XACT (or LOP_ABORT_XACT) log records will record the time the transaction was committed (or aborted).
To find internals of online Transaction Log, you can query sys.fn_dblog function.
The system function sys.fn_dblog accepts two parameters, first, begin LSN and end LSN of the transaction. By default, it is set to NULL. If it is set to NULL, it will return all log records from the transaction log file.
USE WideWorldImporters GO SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], [Log Record Fixed Length], [Log Record Length] [Transaction SID], [SPID], [Begin Time], * FROM fn_dblog(null,null)

As we all know, the transactions are stored in binary format and it’s not in a readable format. In order to read the offline transaction log file, you can use fn_dump_dblog.
Let us query the transaction log file to see who has dropped object using the fn_dump_dblog.
SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], SUSER_SNAME ([Transaction SID]) AS DBUser
FROM fn_dump_dblog (
NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn',
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT)
WHERE
Context IN ('LCX_NULL') AND Operation IN ('LOP_BEGIN_XACT')
AND [Transaction Name] LIKE '%DROP%'
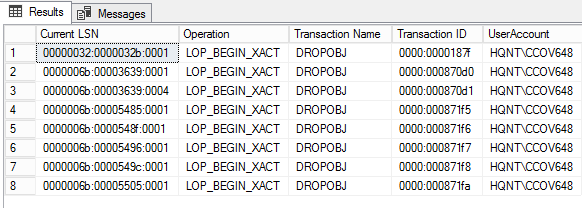
We will use fn_dblog() function to read the active portion of the transaction log for finding activity that is performed on the data . Once the transaction log is cleared, you have to query the data from a log file using fn_dump_dblog().
This function provides the same rowset as fn_dblog(), but has some interesting functionality that makes it useful is some troubleshooting and recovery scenarios. Specifically, it can read not only transaction log of the current database, but also transaction log backups on either disk or tape.
To get the list of the objects that are dropped using transaction file, run the following query. Initially, the data is dumped to temp table. In some cases, the execution of fun_dump_dblog() takes a little longer to execute. So, it’s better to capture the data in the temp table.
To get an object ID from the Lock Information column, run the following query.
SELECT * INTO TEMP FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction ID] in( SELECT DISTINCT [Transaction ID] FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction Name] LIKE '%DROP%') and [Lock Information] like '%ACQUIRE_LOCK_SCH_M OBJECT%'
To get an object ID from the Lock Information column, run the following query.
SELECT DISTINCT [Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4,
Substring([Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4) objectid
from temp
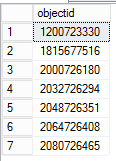
The object_id can be found by manipulating the Lock Information column value. In order to find object name for the corresponding object id, restore the database from the backup right before the table got dropped. After the restore, you can query the system view to get the object name.
USE AdventureWorks2016; GO SELECT name, object_id from sys.objects WHERE object_id = '1815677516';
Now, let us see the different forms of the same transaction details using sys.dn_dblog, sys.fn_full_dblog. The system function fn_full_dblog works only with SQL Server 2017.
Query to fetch the top 10 transactions using fn_dblog.
SELECT TOP 10 * FROM sys.fn_dblog(null,null)

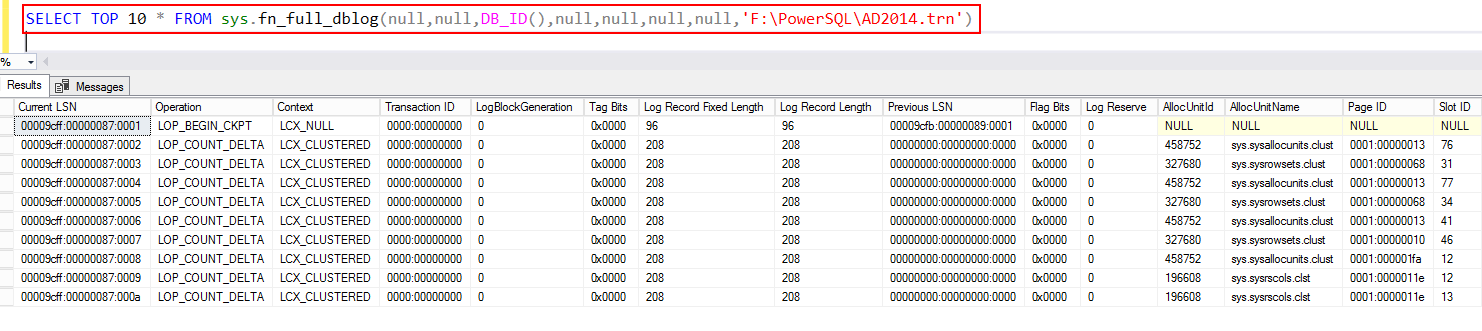
From SQL Server 2017 onwards, you can use fn_full dblog.
SELECT TOP 10 * FROM sys.fn_full_dblog(null,null,DB_ID(),null,null,null,null,NULL)

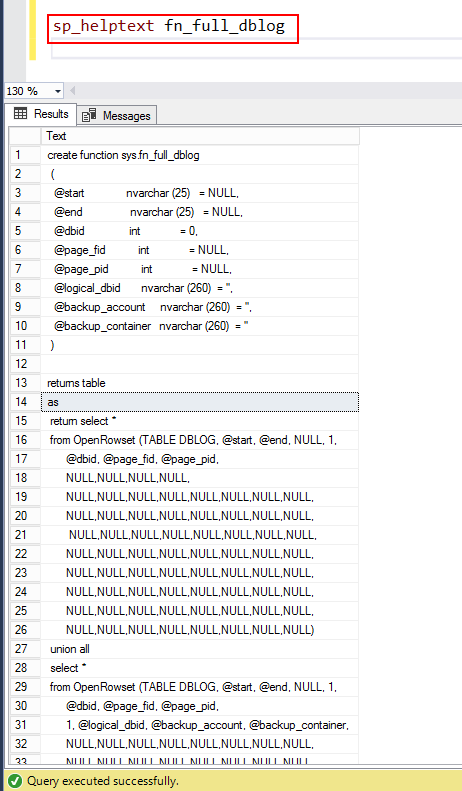
You can further delve into the system function using the sp_helptext fn_full_dblog.
Next, query the backup file using the system function using fn_full_dblog. Again, this is applicable only from SQL Server 2017 onwards.
Point-in-time restore
Let’s assume that you’ve the list of the entire log backup, and then when youe intend to restore the logs, you have the possibility to perform a point-in-time restoration of the data. So, in the process of log restore, you don’t necessarily need to restore all of the data, you may restore it right up to, before or after any individual transaction. So, if database crashes at a specific time, and we have both full backup and log backups, we should be able to first restore the full backup and then restore the log backup, and in the process, restore the last log until a certain time, and that would leave the database in the exact state it was in before this problem occurred.
Log backups are pretty common VLDB (Very Large Database) and most critical databases. It is always recommended to test the restore process. Whenever you do database backups, it is advised to think about the restore process well, and you should always test the restore process more often.
It is always good to alleviate the testing the restore process from time to time, so just make sure the process goes through the backups normally.
Scenarios
Lets us talk about a scenario, when you need to restore a very large database and we all know it normally can take several hours, and that’s something everyone should be aware of. If you’re planning for database migration with zero data loss and smaller outage windows, that could still be a pretty big problem. So you make sure to rely on Transaction log backup to speed up the process.
Let us consider another scenario where you’re performing a side-by-side database migration between two different versions of SQL Server; you’re involved in migrating the database to the same software version on the target and that includes transfer of operating system, database, application, and network etc:-; migrating the database from one piece of hardware to another; changing both software and hardware. The process of database migration is always the challenge where the data loss is always possible and it’s subjected to the environment.
Best practices of Database migration
Let us discuss the standard practices of database migration management.
Migration must be done in a transactional way to avoid inconsistencies in the data. The usual steps of the migration process are conventionally the following:
- Stop the application service—this is where downtime starts
- Initiate log backup, it depends on your requirements
- Put the database in recovery mode so that no further changes to the database are made
- Move the log file(s)
- Restore the database Transaction log file(s)—provided, you’ve already restored the database full backup on target and leave the database in restoring state.
- Clone the logins and fix the orphan users
- Create Jobs
- Install the application
- Configure network – Change DNS entries
- Re-configure application settings
- Start application service
- Test the application
Getting started
In this article, we’ll discuss how to handle Very large OLTP database migration. We will discuss strategies to use SQL server techniques and 3rd party tools for data safety along with zero or minimal disruption to the production system availability. During the process, there is always a chance to lose the data. Do you think the seamless handling of transactions is a good strategy? If “yes”, what are your favorite options?
Let us deep-dive into the available options:
- Backup and Restore
- Log shipping
- Database mirroring
- 3rd party tools
Backup and Restore
The Backup-and-Restore database technique is the most viable option for any database migration. If it’s planned and tested properly, we will avoid many unforeseen migration errors. We all know that the backup is an online process, it is easy to initiate Transaction log backup in a timely manner to narrow down the number of transaction to be supplied to the new database. During the migration window, we can limit the users from accessing the database and initiate one last log backup and transfer it to the destination. In this way, the downtime can be shortened significantly.
Log shipping
We all understand the importance of the log files in the database world. Log shipping technique offers a good disaster recovery solution and supports limited read-only access to secondary databases, during the interval between restore jobs. It’s essentially a concept of backing up the transaction log and is replayed on a full backup on one more secondary database. These secondary databases are duplicate copies of the primary database and continually restore the transaction log backups to their own copy, in order to keep it in sync with the primary database. As the secondary database is on separate hardware, in case of failure of primary for any reason, the fully backed up copy of the system is immediately available for use and network traffic can simply be rerouted to the secondary server, without any users knowing that a fault has occurred. Log shipping provides an easy and effective way to manage migration to a greater extent in most of the cases.
Mirroring
Database Mirroring is also an option for database migration provided both source and target are of same versions and editions. Essentially, mirroring creates two duplicate copies of a database on two hardware instances. Transactions would occur on both databases simultaneously. You have the ability to take a production database offline, switching over to the mirrored version of that database, and allow users to continue accessing the data as if nothing had happened. In terms of implementing it, we deal with a principal server, a mirror server, and a witness. But it’s going to be a deprecated feature and it will be removed from future versions of SQL Server.
Summary
In this article, we discussed the types of backups, Transaction log backup in detail, data migration standards, process, and strategy, learned to use SQL techniques for effective handling of data migration steps.
The transaction log writing mechanism WAL ensures that transactions are always written to the log file first. In this way, SQL Server guarantees the effects of all committed transactions will ultimately be written in the data files(to disk), and that any data modifications on disk that originate from incomplete transactions will be ROLLBACK and not reflected in the data files.
In most of the cases, the delay in data synchronization is unforeseen and data loss is permanent. More often than not, it all depends on the size of the database and available infrastructure. As a recommended practice, it is better to run migrations manually than as part of the deployment to keep things segregated so that output can be more predictable.
Personally, I would prefer Log shipping for various reasons: You can take a full backup of the data from the old server well in advance, get it over to the new server, restore it, and then apply the residual transactions (t-log backup) from the point right up to the moment of cutover. The process is actually quite simple.
Database migration is not difficult if it is done the right way. I hope this post helps you run the database migrations in a smoother fashion.
Tags: sql server, transaction log Last modified: September 22, 2021





