FILESTREAM has been introduced by Microsoft in 2008. The purpose was to store and manage unstructured files more effectively. Before FILESTREAM was introduced, the following approaches were used to store the data in SQL server:
- Unstructured files can be stored in the VARBINARY or IMAGE column of a SQL Server table. This approach is effective to maintain transactional consistency and reduces the file management complexity, but when the client application reads data from the SQL table, it uses SQL memory which leads to poor performance.
- Instead of storing the entire file in the SQL table, store the physical location of the unstructured file in SQL Table. This approach gives huge performance improvement, but it does not ensure the transactional consistency moreover file management was difficult too.
The FILESTREAM feature is very effective because it allows storing BLOB files in the NT file system and maintains the transactional consistency. When a client application reads data from the FILESTREAM container, instead of using the memory of the SQL Server buffer, it uses Nthe T system cache which improves the performance.
FILESTREAM is not a datatype. It’s an attribute which can be assigned to the VARBINARY(MAX) column. When the VARBINARY(MAX) column is assigned to the FILESTREAM attribute, it is called a FILESTREAM column. Data stored in the FILESTREAM column will be stored in the NT system as a disk file, and pointer of the file is stored in the table. The VARBINARY(max) column with the FILESTREAM attribute assigned does not have a limit of storing 2 GB in the table. Hence, we can store huge files as well.
In this article, I am going to demonstrate as follows:
- How to enable FILESTREAM feature.
- How to create and configure FILESTREAM filegroups and FILESTREAM data container.
- How to store and access data from the FILESTREAM enabled tables.
Demo:
In this demo, I am going to use:
- Database Server: SQL Server 2017
- Software: SQL Server Management Studio
- Database: FileStream_Demo
Configure FILESTREAM Access in SQL Server Database
To configure FileStream in SQL Server, make the following changes to SQL Server.
- Enable the FILESTREAM feature from SQL Server Configuration Manager.
- Enable teh FILESTREAM access level on SQL Server instance.
- Create a FILESTREAM filegroup and a FileStream container to store BLOB data.
Enable FILESTREAM Feature
To enable FileStream on any database, firstly enable the FileStream feature on the SQL Server instance. To do that, open SQL Server configuration manager, right-click SQL Instance, select Properties, as shown in the following image:
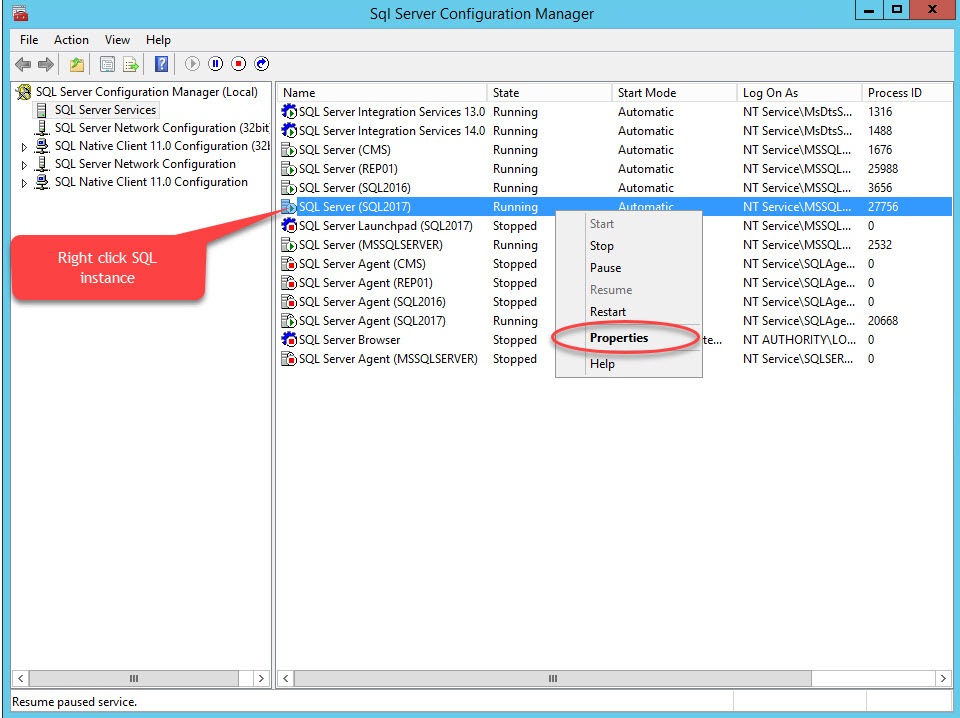
A dialog box to configure server properties opens. Switch to the FILESTREAM tab. Select Enable FILESTREAM for T-SQL access. Select Enable FILESTREAM for I/O access and then select Allow remote client access to FILESTREAM data. In the Windows share name text box, provide a name of the directory to store the files. See the following image:
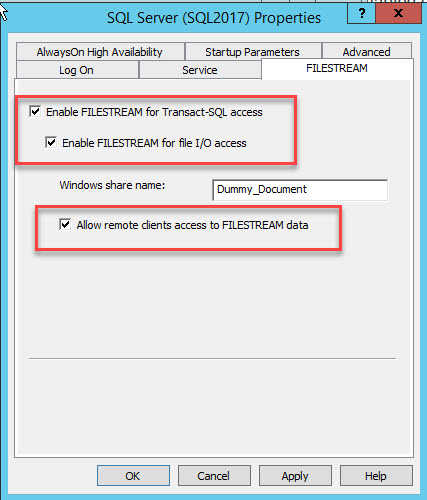
Click OK and restart the SQL service.
Enable FILESTREAM Access Level on SQL Server Instance
Once the FILESTREAM feature is enabled, change the FILESTREAM access level. To change the FileStream access level, execute the following query:
EXEC sp_configure filestream_access_level, 2 RECONFIGURE
In the above query, the parameters below are valid values:
0 means the FILESTREAM support for SQL instance is disabled.
1 means the FILESTREAM support for T-SQL is enabled.
2 means the FILESTREAM support for T-SQL and Win32 streaming access is enabled.
You can change the FILESTREAM access level using SQL Server Management Studio. To do that, right-click an SQL Server connection >> select Properties >> In the server properties dialog box, select FileStream Access Level from the drop-down box, and select Full Access Enabled, as shown in the following image:
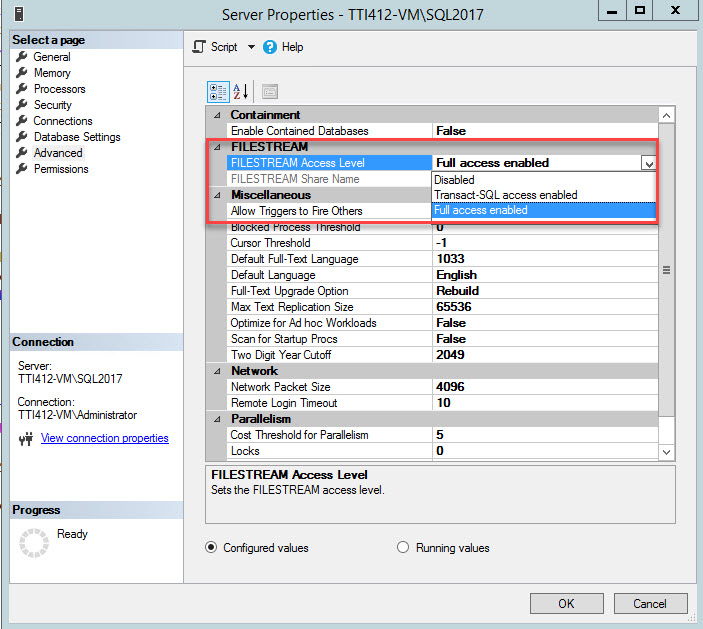
Once the parameter is changed, restart SQL Server services.
Add FILESTREAM Filegroup and Data Files
Once FILESTREAM is enabled, add the FILESTREAM filegroup and FILESTREAM container.
To do that, right-click the FileStream-Demo database >> select Properties >> In a left pane of the Database Properties dialog box, select Filegroups >> In the FILESTREAM grid, click the Add Filegroup button >> Name the filegroup as Dummy Document. See the following image:
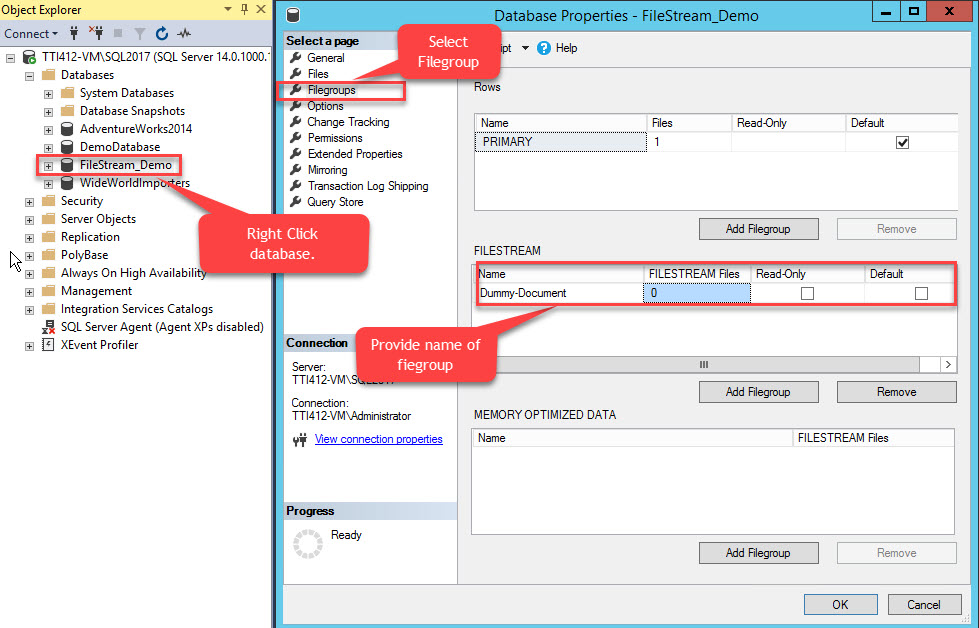
Once the filegroup is created, in the Database Properties dialog box, select files and click the Add button. The Database files grid enables. In the Logical Name column, provide the name, – Dummy-Document. Select FILESTREAM Data in the File Type drop-down box. Select Dummy-Document in the Filegroup column. In the Path column, provide the directory location where files will be stored (E:\Dummy-Documents). See the following image:
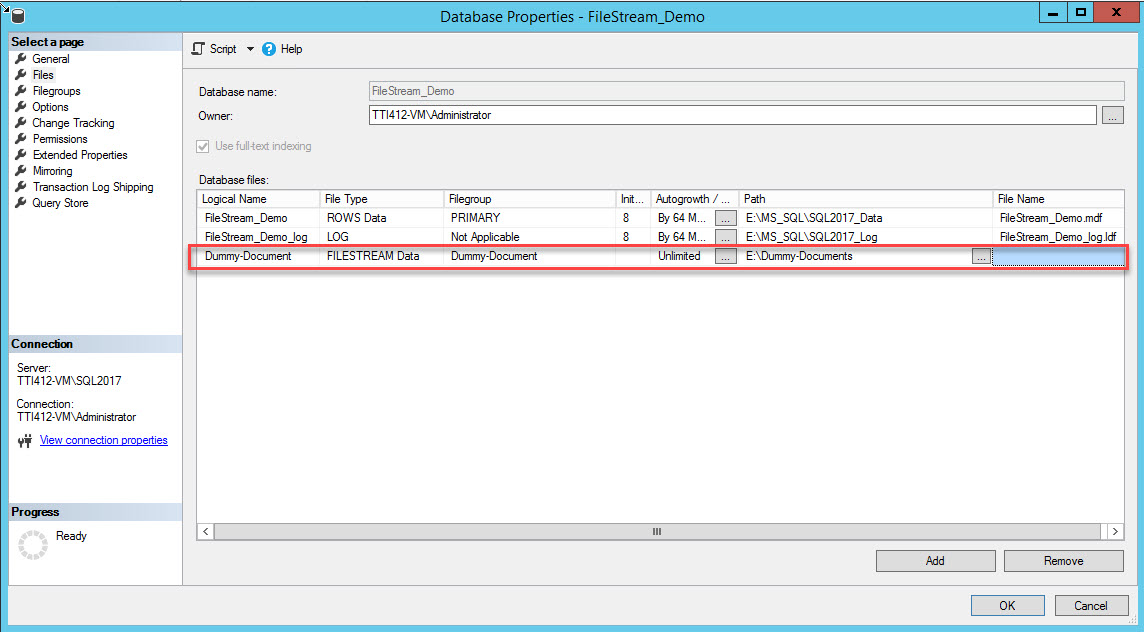
Alternatively, you can add the FILESTREAM filegroup and containers by executing the following T-SQL Query:
USE [master] GO ALTER DATABASE [FileStream_Demo] ADD FILEGROUP [Dummy-Documents] CONTAINS FILESTREAM GO ALTER DATABASE [FileStream_Demo] ADD FILE ( NAME = N'Dummy-Documents', FILENAME = N'E:\Dummy-Documents' ) TO FILEGROUP [Dummy-Documents] GO
To verify that the FileStream container has been created, open Windows Explorer and navigate to the “E:\Dummy-Document” directory.
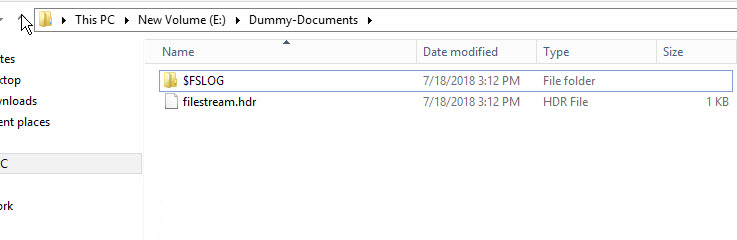
As shown in the above image, the $FSLOG directory and the filestream.hdr file have been created. $FSLOG is like SQL server T-Log, and filestream.hdr contains metadata of FILESTREAM. Make sure that you do not change or edit those files.
Store Files in SQL table
In this demo, we will create a table to store various files from the computer. The table has the following columns:
- The “RootDirectory” column to store file location.
- The “Filename” column to store the name of the file.
- The “FileAttribute” column to store File attribute (Raw/Directory.
- The “FileCreateDate” column to store file creation time.
- The “FileSize” column to store the Size of the file.
- The “FileStreamCol” column to store the content of the file in the binary format.
Create a SQL Table with a FILESTREAM column
Once FILESTREAM configures, create an SQL table with the FILESTREAM columns to store various files in the SQL server table. As I mentioned above, FILESTREAM is not a datatype. It’s an attribute that we add to the varbinary(max) column in the FILESTREAM-enabled table. When you create a FILESTREAM-enabled table, make sure that you add a UNIQUEIDENTIFIER column that has the ROWGUIDCOL and UNIQUE attributes.
Execute the following script to create a FILESTREAM-enabled table:
Use [FileStream_Demo]
go
Create Table [DummyDocuments]
(
ID uniqueidentifier ROWGUIDCOL unique NOT NULL,
RootDirectory varchar(max),
FileName varchar(max),
FileAttribute varchar(150),
FileCreateDate datetime,
FileSize numeric(10,5),
FileStreamCol varbinary (max) FILESTREAM
)
Insert Data in Table
I have the WorldWide_Importors.xls document stored in the computer at the “E:\Documents” location. Use OPENROWSET(Bulk) to load its content from disk to the VARBINARY(max) variable. Then store the variable to the FileStreamCol (VARBINARY(max)) column of the DummyDocument table. To do that, run the following script:
Use [FileStream-Demo]
Go
DECLARE @Document AS VARBINARY(MAX)
-- Load the image data
SELECT @Document = CAST(bulkcolumn AS VARBINARY(MAX))
FROM OPENROWSET(
BULK
'E:\Documents\WorldWide_Importors.xls',
SINGLE_BLOB ) AS Doc
-- Insert the data to the table
INSERT INTO [DummyDocuments] (ID, RootDirectory,FileName, FileAttribute, FileCreateDate,FileSize,FileStreamCol)
SELECT NEWID(), 'E:\Documents','WorldWide_Importors.xls','Raw',getdate(),10, @Document
Access FILESTREAM Data
The FILESTREAM data can be accessed by using T-SQL and Managed API. When the FILESTREAM column accessed using T-SQL query, it uses SQL memory to read the content of the data file and send the data to the client application. When the FILESTREAM column is accessed using Win32 Managed API, it does not use SQL Server memory. It uses the streaming capability of the NT file system which gives performance benefits.
Access FILESTREAM Data Using T-SQL
As I mentioned at the beginning of the article, FILESTREAM is an attribute assigned to a table column that has varbinary(max) data type, therefore, it can be accessed like any other column of the table. To retrieve FILESTREAM data along with all information of the table, execute below query
Use [FileStream-Demo] go select RootDirectory,FileName,FileAttribute,FileCreateDate,FileSize,FileStreamCol from DummyDocuments
Below is the output of the query:

As shown in the above image, the “WorldWide_Importors.xls” document has been converted into a BLOB that is stored in the “FileStreamCol” column.
Access FILESTREAM Data Using Managed API
Although accessing FILESTREAM using Win32 API gives a performance and other benefits, but it has different and difficult syntaxes than T-SQL syntaxes which makes it difficult to access data. Firstly, to locate the file on FILESTREAM data store, we must identify the logical path to identify the file in the FILESTREAM data store uniquely. We can do it by using the Pathname() method of FILESTREAM column. It is case sensitive.
After retrieving the path of File, to access, we must obtain transaction context by using the Begin Transaction method. Once transaction context has been obtained, we can access it using the SQLFileStream class.
The code below obtains the local path to the WorldWide_Importors.xls document in the FILESTREAM data store.
SELECT
RootDirectory,
FileName,
FileAttribute,
FileCreateDate,
FileSize,
FileStreamCol.PathName() AS FilePath
FROM DummyDocuments
Query output:

Delete Files From FILESTREAM Container
Deleting files is straightforward. You need to run the delete query to remove the file from the FILESTREAM enabled SQL table. Even though the record has been deleted from tables, the file will be available in the FILSTREAM data store physically. It will be deleted by Garbage Collector. Garbage Collector process executes when the checkpoint event occurs. By giving an explicit checkpoint, you can delete it immediately after deleting from the table.
Query to delete Files from SQL Table:
Use [FileStream_Demo] go delete from DummyDocuments where ID='0D640ABC-8CF1-41E0-9FA8-28171047129F'
Summary
In this article, I have covered:
- Introduction of FILESTREAM and what are the benefits.
- How to enable FILESTREAM feature on SQL server instance.
- Create and Configure the FILESTREAM data store and Filegroups.
- Perform Insert and Delete Files from FILESTREAM data store.
In future articles, I am going to explain:
- How to backup and restore FILESTREAM enabled database.
- Setting up replication and table portioning in FILESTREAM tables.
Stay Tuned!
Tags: filestream, sql server Last modified: September 22, 2021





