SQL Server Transactional Replication is one of the most common Replication techniques used to copy or distribute data across multiple destinations.
In the previous articles, we discussed SQL Server Replication, how it internally works, and how to configure Replication via the Replication Wizard or T-SQL approach. Now, we focus on SQL Replication issues and troubleshooting them correctly.
SQL Replication Issues
The majority of customers who use SQL Server Transactional Replication mainly focus on achieving near-real-time data available in the Subscriber database instances. Hence, the DBA who manages the Replication should be aware of various possible SQL Replication-related issues that might arise. Also, the DBA must be able to solve these issues within a short time.
We can categorize all SQL Replication issues into the below categories (based upon my experience):
Configuration Issues
- Maximum Text Replication Size
- SQL Server Agent Service not set to start Automatic mode
- Unmonitored Replication instances get into an uninitialized Subscriptions state
- Known issues within SQL Server
Permission Issues
- SQL Server Agent Job Permission issues
- Snapshot Agent job credential can’t access Snapshot Folder path
- Log Reader Agent job credential can’t connect to Publisher/distribution database
- Distribution Agent job credential can’t connect to distribution/Subscriber database
Connectivity Issues
- Publisher server was not found or was not accessible
- Distribution server was not found or was not accessible
- Subscriber server was not found or was not accessible
Data Integrity Issues
- Primary Key or Unique Key violation errors
- Row Not Found errors
- Foreign Key or other constraint violation errors
Performance Issues
- Long-running Active Transactions in Publisher database
- Bulk INSERT/UPDATE/DELETE operations on Articles
- Huge data changes within a single Transaction
- Blockings in the distribution database
Corruptions related issues
- Publisher database corruptions
- Publisher Transactional Log file corruptions
- Distribution database corruptions
- Subscriber database corruptions
DEMO Environment Preparation
Before diving into details about the SQL Replication issues, we need to prepare our environment for the demo. As discussed in my previous articles, any data changes happening on the Subscriber database in Transactional Replication won’t be visible directly to the Publisher database. Thus, we are going to make certain modifications directly in the Subscriber database for learning purposes.
Please take extreme caution and don’t modify anything in the Production databases. It will impact the Data integrity of the Subscriber databases. I’ll take the backup scripts for every change performed and will use those scripts to fix the SQL Replication issues.
Change 1 – Inserting Records into the Person.ContactType Table
Before inserting records into the Person.ContacType table, let’s have a look at that table structure, a few default constraints, and extended properties redacted in the script below:
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
I’ve chosen this table since it has fewer columns. It is more convenient for test purposes. Now, let’s check what we’ve got about its structure:
- ContactTypeId is defined as an IDENTITY COLUMN – it will autogenerate the Primary key values and NOT FOR REPLICATION.
- NOT FOR REPLICATION is a special property that can be used upon various Object types like Tables, Constraints like Foreign Key Constraints, Check Constraints, Triggers, and Identity columns on either Publisher or Subscriber while using any of the Replication methodologies only. It lets the DBA plan or implement Replication to ensure that certain functionalities behave differently in Publisher/Subscriber while using Replication.
- In our case, we instruct SQL Server to use the IDENTITY values generated only on the Publisher database. The IDENTITY property should not be used upon the Person.ContactType table in the Subscriber database. Similarly, we can modify the Constraints or Triggers to make them behave differently while Replication is configured using this option.
- 2 other NOT NULL columns are available in the table.
- The table has a primary key defined on ContactTypeId. Just to recall, the Primary key is a mandatory requirement for Replication. Without it on a table, we would not be able to replicate a table article.
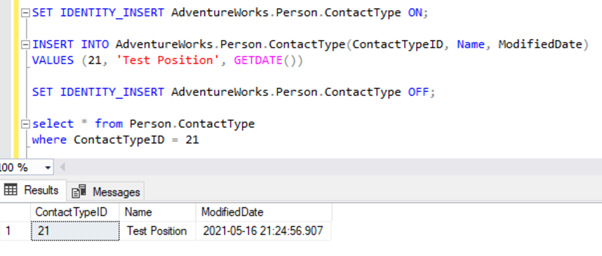
Now, let’s INSERT a sample record to Person.ContactType table in the AdventureWorks_REPL database:
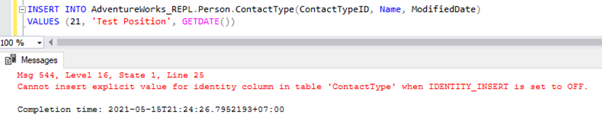
The direct INSERT on the table will fail on the Subscriber database because the Identity Property is disabled only for Replication by the NOT FOR REPLICATION option. Whenever we perform the INSERT operation manually, we still need to use the SET IDENTITY_INSERT option like this:
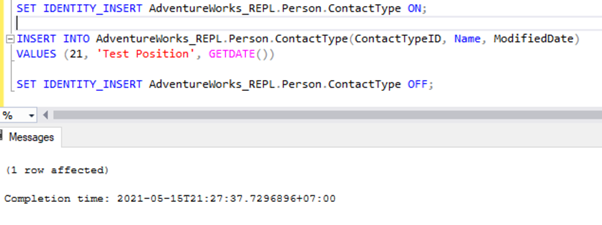
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
After adding the SET IDENTITY_INSERT option, we can INSERT record successfully into the Person.ContactType table.
Executing the SELECT on the table shows the newly inserted record:
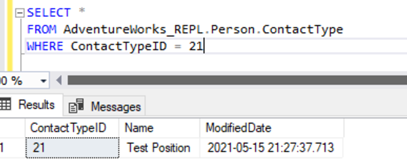
We have added a new record only to the Subscriber database which is not available in the Publisher database on the Person.ContactType table.
Executing a SELECT on the same table of the Publisher database doesn’t show any records. Thus, any changes done on the Subscriber database aren’t replicated to the Publisher database.
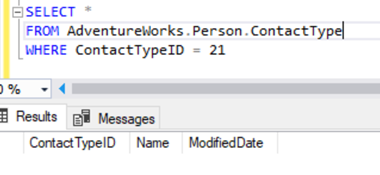
Change 2 – Deleting 2 Records from the Person.ContactType Table
We stick to our familiar Person.ContactType table. Before deleting records from the Subscriber database, we must verify if those records do exist across both Publisher and Subscriber. See below:
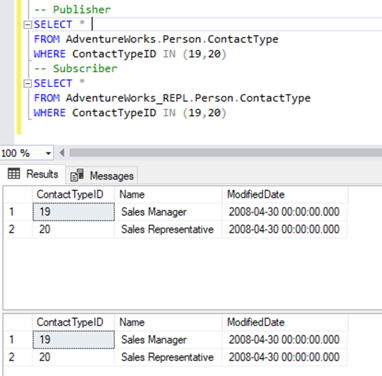
Now, we can delete these 2 ContactTypeId using the following statement:
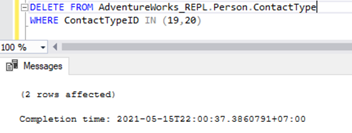
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
The above script lets us delete 2 records from the Person.ContactType table in the Subscriber database:
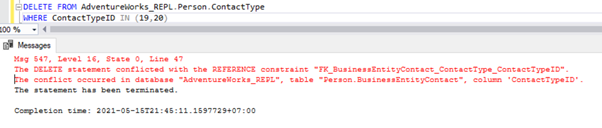
We have the Foreign key reference that prevents deletion of these 2 records from the Person.ContactType table. We can handle this scenario by disabling the Foreign key constraint on the child table temporarily. The script is below:
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
Once the Foreign keys are disabled, we can delete records successfully from the Person.ContactType table:
This has also modified the Foreign key Referential constraint across the 2 tables. We can try to simulate SQL Replication issues based upon this scenario.
In our current scenario, we know that the Person.ContactType table did not have synchronized data across the Publisher and the Subscriber.
Believe me, in few Production environments, developers or DBAs do some data fixes on the Subscriber database. like all changes we performed earlier caused the data integrity issues across the Publisher and the Subscriber databases in the same table. As a DBA, I need a simpler mechanism to verify these kinds of discrepancies. Otherwise, it would make the DBA’s life pathetic.
Here comes the solution from Microsoft that allows us to verify the data discrepancies across tables in the Publisher and the Subscriber. Yes, you guessed it right. It’s the TableDiff utility that we discussed in previous articles.
TableDiff Utility
The TableDiff utility is primarily used in Replication environments. We can also use it for other cases where we need to compare 2 SQL Server tables for non-convergence. We can compare them and identify the differences between these 2 tables. Then the utility helps to synchronize the Destination table to the Source table by generating necessary INSERT/UPDATE/DELETE scripts.
TableDiff is a standalone program tablediff.exe installed by default at C:\Program Files\Microsoft SQL Server\130\COM once we have installed the Replication Components. Please note that the default path may vary according to the SQL Server Installation parameters. The number 130 in the path indicates the SQL Server version (SQL Server 2016). Hence, it will vary for every different version of the SQL Server installation.
You can access the TableDiff utility via Command Prompt or from batch files only. The utility does not have a fancy Wizard or GUI to use. The detailed syntax of the TableDiff utility is in the MSDN article. Our current article focuses on some necessary options only.
To Compare 2 tables using the TableDiff utility, we need to provide mandatory details for the Source and Destination tables, such as the Source Server Name, Source Database Name, Source Schema Name, Source Table Name, Destination Server Name, Destination Database Name, Destination Schema Name, and Destination Table Name.
Let’s try testing TableDiff with the Person.ContactType table having differences across the Publisher and the Subscriber.
Open the Command prompt and navigate to the TableDiff utility path (if that path is not added to the Environment variables).
To view the list of all available parameters, type the command “tablediff-?” to list down all options and parameters available. The results are below:
Let’s check the Person.ContactType table across our Publisher and Subscriber databases by running the below command:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypeNote that I haven’t provided the sourceuser, sourcepassword, destinationuser, and destinationpassword since my Windows login has access to the tables. If you wish to use SQL Credentials instead of Windows Authentication, the above parameters are mandatory to access the tables for comparison. Otherwise, you will receive errors.
The results of the correct command execution:
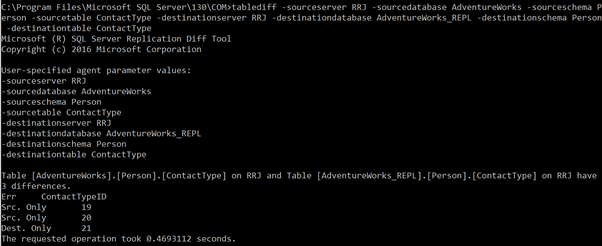
It shows that we have 3 discrepancies. One is a new record in the Destination database, and two records are not available in the Destination database.
Now, let’s have a quick look at the Miscellaneous options available for the TableDiff utility.
- -et – logs the result summary to the destination table
- -dt – drops the result destination table if it already exists
- -f – generates a T-SQL DML script with INSERT/UPDATE/DELETE statements to bring the Destination table to convergence with the Source table.
- -o – output file name if option -f is used to generate the convergence file.
We’ll create a convergence file with the -f and -o options to our earlier command:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlThe convergence file is created successfully:
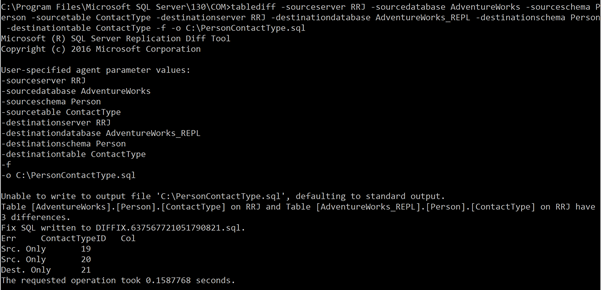
As you can see, the creation of a new file in the root folder of the C: drive isn’t allowed for security reasons. Hence, it shows an error message and creates the output file DIFFIX.*.sql file in the TableDiff utility folder. When we open that file, we can see the below details:

The INSERT scripts were created for the 2 deleted records, and the DELETE scripts were created for the records newly inserted into the Subscriber database. The tool also cares about using the IDENTITY_INSERT options as required for the Destination table. Hence, this tool will be of great use whenever a DBA needs to synchronize two tables.
In our case, I won’t execute the scripts, as we need these variances to simulate our SQL Replication issues.
Advantages of TableDiff Utility
- TableDiff is a free utility that comes as part of the SQL Server Replication components installation to be used for table comparison or convergence.
- The convergence creation scripts can be created without manual intervention.
Limitations of TableDiff Utility
- The TableDiff utility can be executed only from the command prompt or batch file.
- From the command prompt, you can perform only one table comparison at a time, unless you have multiple commands prompts open in parallel to compare several tables.
- The Source table that you need to compare using the TableDiff utility requires either a Primary Key or an Identity column defined, or the ROWGUID column available to perform the row-by-row comparison. If the -strict option is used, the Destination table also requires a Primary key, or an Identity column, or the ROWGUID column available.
- If the Source or destination table contains the sql_variant datatype column, you can’t use the TableDiff utility to compare it.
- Performance issues can be noticed while executing the TableDiff utility on tables containing huge records, as it will perform the row-by-row comparison on these tables.
- Convergence scripts created by the TableDiff utility don’t include the BLOB character data type columns, such as varchar(max), nvarchar(max), varbinary(max), text, ntext, or image columns, and xml or timestamp columns. Hence, you need alternative approaches to handle the tables with these datatype columns.
However, even with these limitations, the TableDiff utility can be used across any SQL Server table for quick data verification or convergence check. However, you can purchase a good third-party tool too.
Now, let’s consider the various SQL Replication issues in detail.
Configuration Issues
From my experience, I’ve categorized the frequently missed Replication Configuration options that can lead to critical SQL Replication issues as Configuration issues. Some of them are below.
Max Text Replication Size
Max Text Repl Size refers to the Maximum Text Replication size in bytes. It applies to all datatypes like char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, and image.
SQL Server has a default option to limit the maximum string datatype column length (in bytes) to be replicated as 65536 bytes.
We need to evaluate the Max Text Repl Size carefully whenever Replication is configured for a database. For that, we must check all the above datatype columns and identify the maximum possible bytes that will get transferred via Replication.
Changing the value to -1 indicates that there are no limits. However, we recommend you evaluate the maximum string length and configure that value.
We can configure Max Text Repl Size using SSMS or T-SQL.
In SSMS, right-click on the Server name > Properties > Advanced:
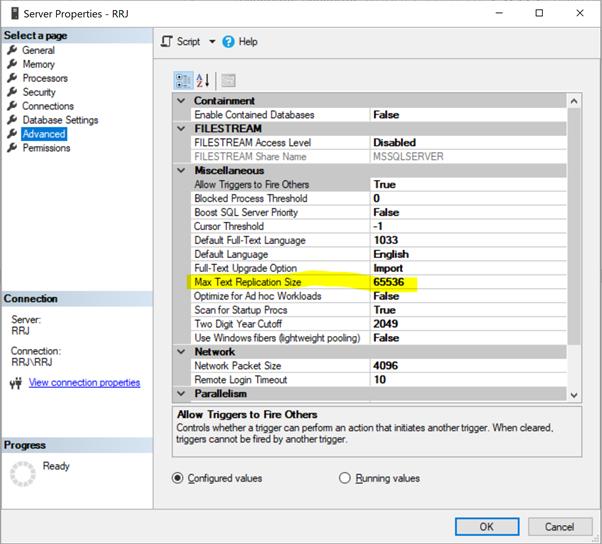
Just click on 65536 to modify it. For tests, I’ve changed 65536 to 1000000 and clicked OK:
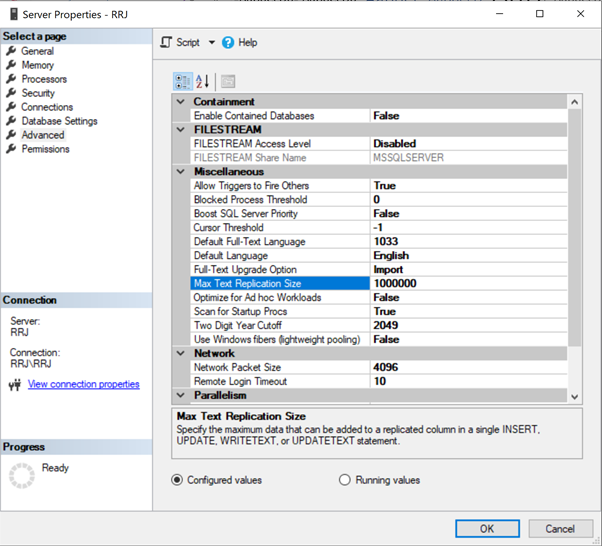
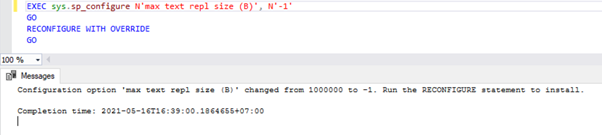
To configure the Max Text Repl Size option via T-SQL, open a new query window and execute the below script against the master database:
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
This query will allow Replication not to restrict the size of the above datatype columns.
To verify, we can perform a SELECT on sys.configurations DMV and check the value_in_use column as below:

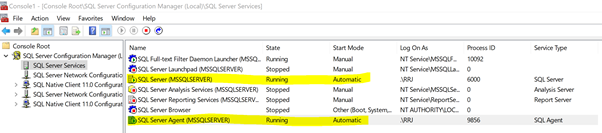
SQL Server Agent Service Not Set to Start Automatic Mode
Replication relies on Replication Agents which are executed as SQL Server Agent jobs. Hence, any issue with some SQL Server Agent Service will have a direct impact on the Replication functionality.
We need to make sure that the Start Mode of SQL Server and SQL Server Agent Services are set to Automatic. If set to Manual, we should configure some alerts. They would notify the DBA or Server Admins to start the SQL Server Agent Service when the Server restarts either planned or unplanned ones.
If not done, the Replication might not be running for a long time, which affects other SQL Server Agent jobs too.
Unmonitored Replication Instances Get into an Uninitialized Subscriptions State
Similar to monitoring SQL Server Agent Service, configuring Database Mail Service in any SQL Server instance plays a vital role in alerting DBA or the person configured on a timely manner. For any job failures or issues, SQL Server Agent jobs like Log Reader Agent or Distribution Agent can be configured to send alerts to DBA or the respective team member via email. The failure of the Replication Agent job execution can lead to the below scenarios:
Non-execution of the Log Reader Agent Job. The Transaction Log file of the Publisher database will be reused only after the command marked for Replication is read by the Log Reader Agent and successfully sent to the distribution database. Otherwise, the log_reuse_wait_desc column of sys.databases will show the value as Replication, indicating that the database log can’t be reused till it successfully transfers changes to the distribution database. Hence, non-execution of the Log Reader agent will keep increasing the size of the Transactional Log file of the Publisher database, and we will encounter performance issues during the Full Backup, or disk space issues on the Publisher database instance.
Non-execution of Distribution Agent Job. The Distribution Agent job reads the data from the distribution database and sends it to the Subscriber database. Then it marks those records for deletion in the distribution database. If the Distribution Agent job isn’t executing, it will increase the size of the distribution database causing performance issues to the overall Replication performance. By default, the distribution database is configured to hold records to a maximum of 0-72 hours as shown in the Transaction Retention property below. If the Replication is failing for more than 72 hours, the corresponding subscription will be marked as uninitialized, forcing us to either reconfigure the Subscription or generate a new snapshot to have the Replication working again.
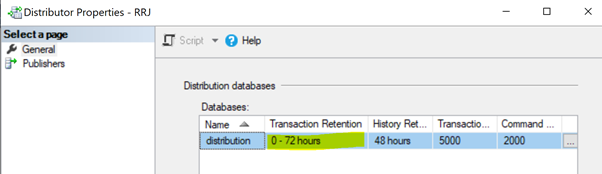
Non-execution of the Distribution clean-up: distribution job. The Distribution clean-up job is responsible for deleting all replicated records from the distribution database to keep the distribution database size under control. Non-execution of this job leads to the increased size of the distribution database resulting in Replication performance issues.
To ensure that we don’t land up across any of these unmonitored issues, the Database Mail should be configured to report all job failures or retries to the respective team members for prompt action.
Known Issues within SQL Server
Certain SQL Server versions had known Replication issues in the RTM version or earlier versions. These issues were fixed in the subsequent Service Packs or CU packs. Therefore, it is recommended to apply the latest Service packs or CU packs once available to all SQL Server after testing them in the QA environment. Even though this is a general recommendation for servers running SQL Server, it is applicable for Replication as well.
Permission Issues
In an environment with the SQL Server Transactional Replication configured, we can observe the Permissions issues frequently. We may face them during the time of Replication configuration or any Maintenance activities on the Publisher, or Distributor, or the Subscriber database instances. It results in lost credentials or permissions. Let’s now observe some frequent permission issues related to Replication.
SQL Server Agent Job Permission Issues
All Replication agents use SQL Server Agent jobs. Each SQL Server Agent job related to the Snapshot or the Log Reader Agent, or Distribution is executed under some Windows or SQL Login credentials as shown below:
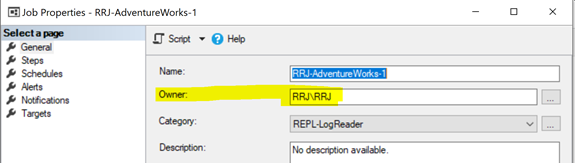
To start an SQL Server Agent job, you need to possess either the SQLAgentOperatorRole to start all jobs or either SQLAgentUserRole or the SQLAgentReaderRole to start jobs that you own. If any jobs couldn’t start properly, check whether the job owner has the necessary rights to execute that job.
Snapshot Agent Job Credential Can’t Access Snapshot Folder Path
In our previous articles, we noticed that the Snapshot agent execution would create the snapshot of the articles in either local or shared folder path to be propagated to the Subscriber database via the Distribution agent. The Snapshot path location can be identified under the Publication Properties > Snapshot:
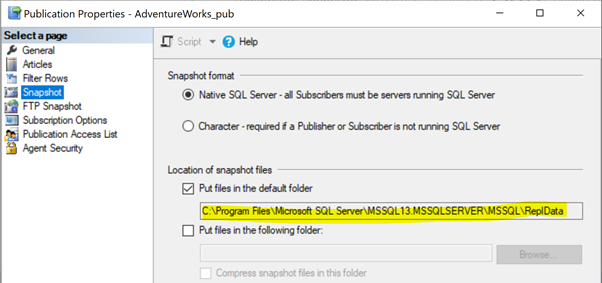
If the Snapshot agent doesn’t have access to this Snapshot files location, we may receive the error:
Access to the path ‘C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\YYYYMMDDHHMISS\’ is denied.
To resolve the issue, it’s better to grant complete access to the folder path C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ for the account under which the Snapshot Agent executes. In our configuration, we use the SQL Server Agent account, and the SQL Server Agent Service is running under the RRJ\RRJ account.
The Log Reader Agent Job Credential Can’t Connect to Publisher/Distribution Database
Log Reader Agent connects to the Publisher database to execute the sp_replcmds procedure to scan for the transactions that are marked for Replication from the Transactional logs of the Publisher database.
If the database owner of the Publisher database is not set properly, we might receive the following errors:
The process could not execute ‘sp_replcmds’ on ‘RRJ.
Or
Cannot execute as the database principal because the principal “dbo” does not exist, this type of principal cannot be impersonated, or you do not have permission.
To resolve this issue, ensure that the database owner property of the Publisher database is set to sa or another valid account (see below).
Right-click on the Publisher database (AdventureWorks) > Properties > Files. Make sure that the Owner field is set to sa or any valid login and not blank.
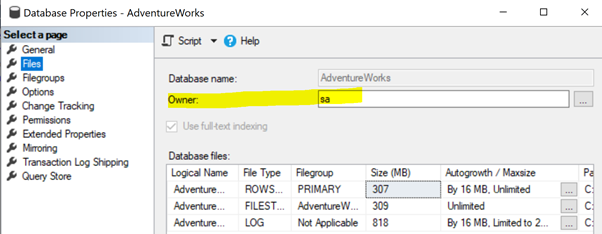
If any permission issues take place when we are connecting to the Publisher or distribution database, check the credentials used for the Log Reader Agent and grant them permissions to access those databases.
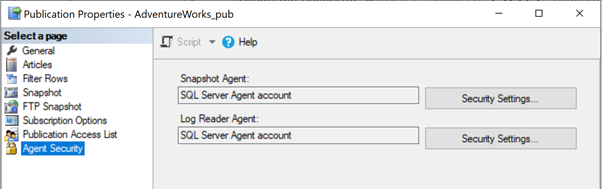
The Distribution Agent Job Credential Can’t Connect to the Distribution/Subscriber Database
The Distribution agent might have permission issues if the account isn’t allowed to access the distribution database or connect to the Subscriber database. In this case, we may get the following errors:
Unable to start execution of step 2 (reason: Error authenticating proxy RRJ\RRJ, system error: The user name or password is incorrect.)
The process could not connect to Subscriber ‘RRJ.
Login failed for user ‘RRJ\RRJ’.
To resolve it, check the account used in the Subscription Properties and ensure that it has the necessary permissions to connect to the Distribution or Subscriber database.
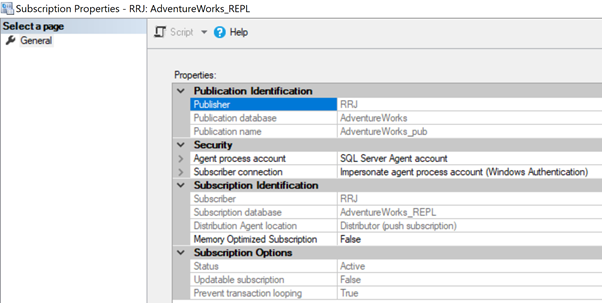
Connectivity Issues
We usually configure the Transactional Replication across servers within the same network or across geographically distributed locations. If the distribution database is located on a dedicated server apart from the Publisher or Subscriber, it becomes susceptible to network packet losses – connectivity issues.
In case of such issues, Replication agents (Log Reader or Distribution Agent) can report the below errors:
Publisher server was not found or was not accessible
Distribution server was not found or was not accessible
Subscriber server was not found or was not accessible
To troubleshoot these issues, we might try connecting to the Publisher, Distributor, or the Subscriber database in SSMS to check whether we are able to connect to these SQL Server instances without any issues or not.
If connectivity issues happen frequently, we can try pinging the server continuously to identify any packet losses. Also, we have to work with the necessary team members to resolve those issues and get the server up and running for Replication to resume transferring data.
Data Integrity Issues
Since Transactional Replication is a one-way mechanism, any data changes happening on the Subscriber (manually or from the application) won’t get reflected on the Publisher. It might lead to data variances across the Publisher and the Subscriber.
Let’s review those issues related to Data Integrity and see how to resolve them. Note that we have inserted a record into the Person.ContactType table and deleted 2 records from the Person.ContactType table in the Subscriber database. We are going to use these 3 records to find errors.
The Primary Key or Unique Key Violation Errors
I’m going to test the INSERT record on the Person.ContactType table. Let’s insert that record into the Publisher database and see what happens:
Launch the Replication Monitor to see how it goes. We get the error:
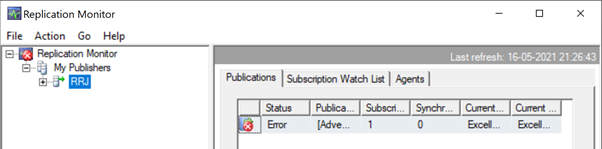
Expanding Publisher and Publication, we get the following details:
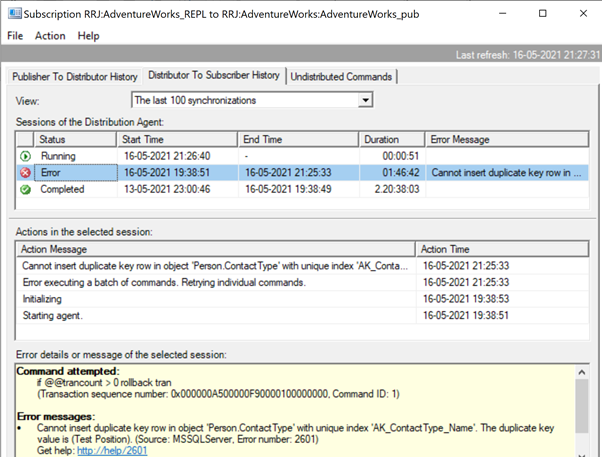
If we have configured the Replication Alerts and assigned respective persons to receive their mail alert, we’ll receive appropriate email notifications with the error message: Cannot insert a duplicate key row in object ‘Person.ContactType’ with unique index ‘AK_ContactType_Name’. The duplicate key value is (Test Position). (Source: MSSQLServer, Error number: 2601)
To resolve the issue concerning Unique key violations or Primary key issues, we have several options:
- Analyze why this error has happened, how the record was available in the Subscriber database, and who inserted it for what reasons. Identify whether it was necessary or not.
- Add the skiperrors parameter to the Distribution Agent profile to skip Error Number 2601 or Error Number 2627 in case of the Primary Key violation.
In our case, we purposefully inserted data to receive this error. To handle this issue, delete that manually inserted record to continue replicating changes received from the Publisher.
DELETE from Person.ContactType
where ContactTypeID = 21
To study other options and to compare the differences between these two approaches, I’m skipping the first option (which is efficient and recommended) and proceed to the second option by adding the -skiperrors parameter to the Distribution Agent job.
We can implement it by editing the Distribution Agent Job > Steps > click 2nd Job Step named Run Agent > click Edit to view the command available:
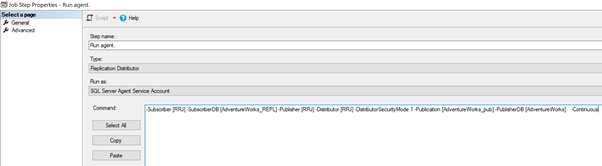
Now, add the -SkipErrors 2601 keyword in the end (2601 is the error number – we can skip any error number received as part of Replication) and click OK.
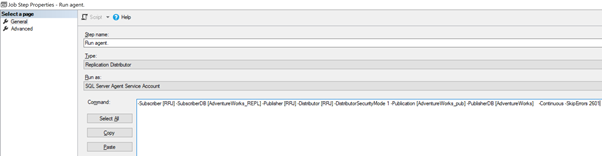
To make sure that the Distribution job is aware of this configuration change, we need to restart the Distribution agent job. For that, stop it and start again from Step 1 as shown below:
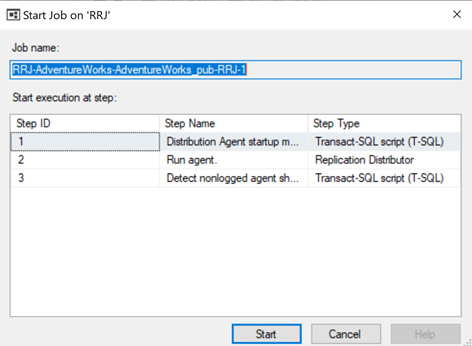
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
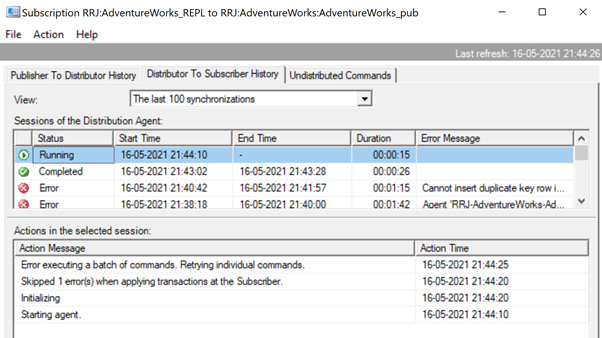
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue:
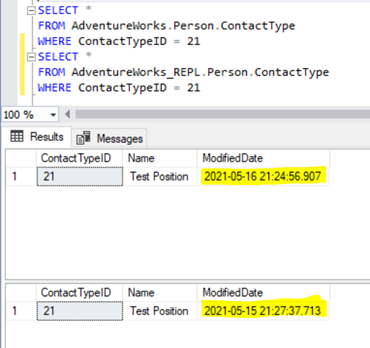
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors command.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
Row Not Found Errors
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
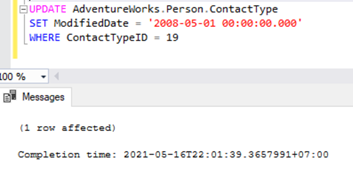
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s): [ContactTypeID] = 19 (Source: MSSQLServer, Error number: 20598).
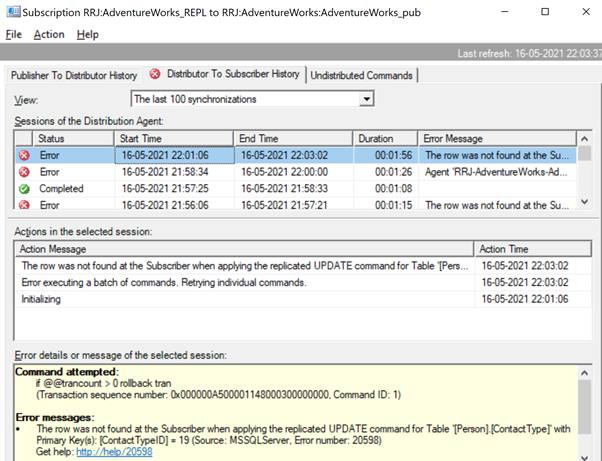
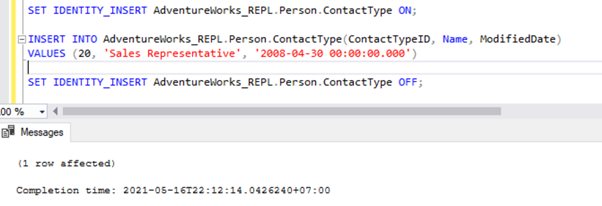
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598. Or, we can INSERT the record with ContactTypeID = 19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId = 19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors option. Instead, we’ll apply the INSERT approach.
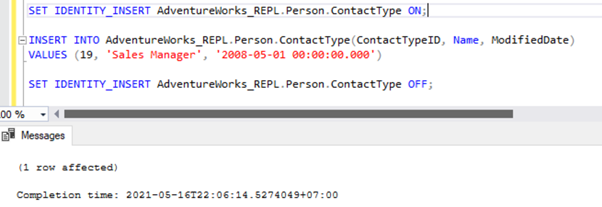
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
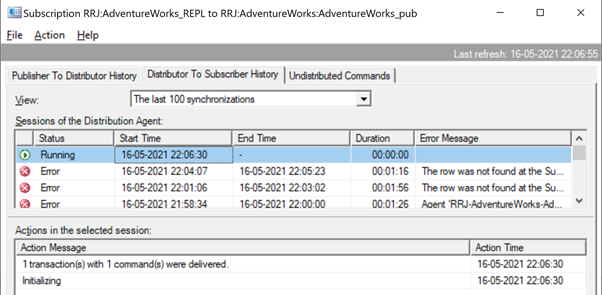
It is the same when we try to delete the ContactTypeId = 20 from the Publisher database and see the error popping up in the Replication Monitor.
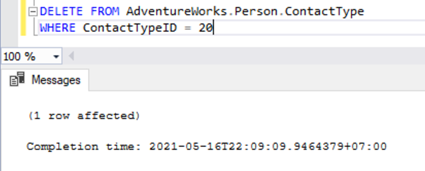
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s): [ContactTypeID] = 20 (Source: MSSQLServer, Error number: 20598)
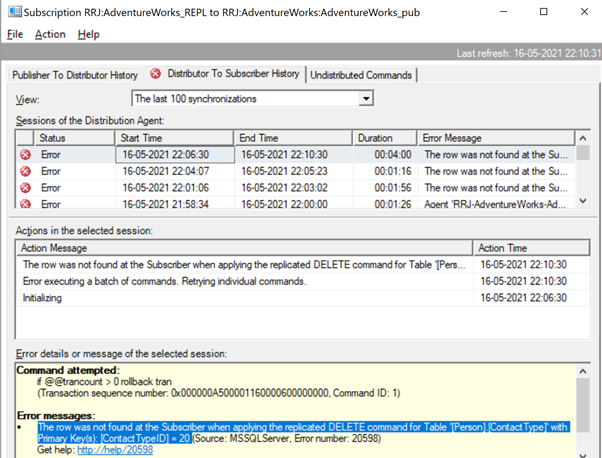
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Conclusion
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.
Tags: replication issues, transactional replication Last modified: October 31, 2021