Recently, I was involved in the development of the functionality that required a fast and frequent transfer of large volumes of data to disc. In addition, this data was supposed to be read from disk from time to time. Therefore, I was destined to find out the place, the way and the means for storing this data. In this article, I will briefly review the task, as well as investigate and compare solutions for completion of this task.
Context of the task: I work in a team that develops tools for relative database development (SQL Server, MySQL, Oracle). The tool range includes both, standalone tools, and add-ins for MS SSMS.
Task: Restoring documents that were opened at the moment of IDE closing at the next start of IDE.
Usecase: To close IDE quickly before leaving the office without thinking of which documents were saved, and which ones were not. At the next start of IDE, we need to get the same environment that was at the moment of closing and continue the work. All results of work must be saved at the moment of disorderly close down, e.g. during the crash of a program or operating system, or during power-off.
Task analysis: The similar feature is present in web browsers. However, browsers store only URLs that consist of approximately 100 symbols. In our case, we need to store the entire document content. Therefore, we need a place to save and store user’s documents. What is more, sometimes users work with SQL in a different way than with other languages. For instance, if I write a C# class of more than 1000 rows long, it will hardly be acceptable. While, in the SQL universe, alongside with 10-20-row queries, the monstrous database dumps exist. Such dumps are hardly editable, which means that users would prefer to keep their edits safe.
Requirements to a storage:
- It should be a lightweight embedded solution.
- Is should have high writing speed.
- It should have an option of the multiprocessing access. This requirement is not critical, since we can ensure the access with help of the synchronization objects, but still, it would be nice to have this option.
Candidates
The first candidate is rather clumsy, that is to store everything in a folder, somewhere in AppData.
The second candidate is obvious – SQLite, a standard of embedded databases. Very solid and popular candidate.
The third candidate is the LiteDB database. It is the first result for the “embedded database for .net” query in Google.
First sight
File system. Files are files, they require maintenance and proper naming. Besides the file content, we will need to store a small set of properties (original path on disc, connection string, version of IDE, in which it was opened). It means, that we will have to either create two files for one document, or to invent a format that separates properties from content.
SQLite is a classic relational database. The database is represented by one file on disc. This file is being bound with database schema, after which we have to interact with it with help of the SQL means. We will be able to create 2 tables, one for properties, and the other one for content, – in case we will need to use properties or content separately.
LiteDB is a non-relational database. Similar to SQLite, the database is represented by a single file. It is entirely written in С#. It has captivating usage simplicity: we just need to give an object to the library, while serialization will be performed by its own means.
Performance test
Before providing code, I’d like to explain the general conception and provide comparison results.
The general conception is comparing speed of writing large quantity of small files to database, average quantity of average files, and a small quantity of large files. The case with average files is mostly close to real case, while cases with small and large files are borderline cases, which must be also taken into account.
I was writing content into a file with help of FileStream with the standard buffer size.
There was one nuance in SQLite which I would like to mention. We were unable to put all document content (as I mentioned above, they can be really large) into one database cell. The thing is that for optimization purposes, we store document text line by line. This means, that in order to put text into a single cell, we need to put all document into a single row, which would double the quantity of the used operating memory. The other side of the problem would reveal itself during data read from the database. That’s why, there was a separate table in SQLite, where data was stored row by row and data was linked with help of foreign key with the table containing only file properties. Besides, I managed to speed up the database with batch data insert (several thousand rows at a time) in the OFF synchronization mode without logging and within one transaction.
LiteDB received an object having List among its properties and the library saved it to disc on its own.
During development of test application, I understood that I prefer LiteDB. The thing is that the test code for SQLite takes more that 120 rows, while code, that solves the same problem in LiteDb, takes only 20 rows.
Test Data Generation
FileStrings.cs
internal class FileStrings {
private static readonly Random random = new Random();
public List Strings {
get;
set;
} = new List();
public int SomeInfo {
get;
set;
}
public FileStrings() {
}
public FileStrings(int id, int minLines, decimal lineIncrement) {
SomeInfo = id;
int lines = minLines + (int)(id * lineIncrement);
for (int i = 0; i < lines; i++) {
Strings.Add(GetString());
}
}
private string GetString() {
int length = 250;
StringBuilder builder = new StringBuilder(length);
for (int i = 0; i < length; i++) { builder.Append(random.Next((int)'a', (int)'z')); } return builder.ToString(); } } Program.cs List files = Enumerable.Range(1, NUM_FILES + 1) .Select(f => new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES))
.ToList();
SQLite
private static void SaveToDb(List files) {
using (var connection = new SQLiteConnection()) {
connection.ConnectionString = @"Data Source=data\database.db;FailIfMissing=False;";
connection.Open();
var command = connection.CreateCommand();
command.CommandText = @"CREATE TABLE files
(
id INTEGER PRIMARY KEY,
file_name TEXT
);
CREATE TABLE strings
(
id INTEGER PRIMARY KEY,
string TEXT,
file_id INTEGER,
line_number INTEGER
);
CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON strings(file_id,line_number);
PRAGMA synchronous = OFF;
PRAGMA journal_mode = OFF";
command.ExecuteNonQuery();
var insertFilecommand = connection.CreateCommand();
insertFilecommand.CommandText = "INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();";
insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter());
insertFilecommand.Prepare();
var insertLineCommand = connection.CreateCommand();
insertLineCommand.CommandText = "INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);";
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Prepare();
foreach (var item in files) {
using (var tr = connection.BeginTransaction()) {
SaveToDb(item, insertFilecommand, insertLineCommand);
tr.Commit();
}
}
}
}
private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) {
string fileName = Path.Combine("data", item.SomeInfo + ".sql");
insertFileCommand.Parameters[0].Value = fileName;
var fileId = insertFileCommand.ExecuteScalar();
int lineIndex = 0;
foreach (var line in item.Strings) {
insertLinesCommand.Parameters[0].Value = line;
insertLinesCommand.Parameters[1].Value = fileId;
insertLinesCommand.Parameters[2].Value = lineIndex++;
insertLinesCommand.ExecuteNonQuery();
}
}
LiteDB
private static void SaveToNoSql(List item) {
using (var db = new LiteDatabase("data\\litedb.db")) {
var data = db.GetCollection("files");
data.EnsureIndex(f => f.SomeInfo);
data.Insert(item);
}
}
The following table shows average results for several runs of the test code. During modifications, the statistical deviation was quite imperceivable.
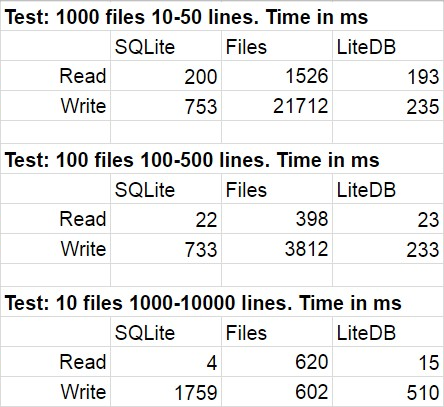
I was not surprised that LiteDB won in this comparison. However, I was shocked by the win of LiteDB over files. After a brief study of the library repository, I found out very meticulously implemented paginal write to disc, but I’m sure that this is only one of many performance tricks used there. One more thing I’d like to point out is a fast speed of the file system access decrease when the quantity of files in the folder becomes really large.
We selected LiteDB for the development of our feature, and we hardly regretted about this choice. The thing is that the library is written in native for everyone C#, and if anything was not quite clear, we could always refer to the source code.
Cons
Besides the above mentioned pros of LiteDB in comparison with its contenders, we began noticing cons during development. Most of these cons can be explained by ’youth’ of the library. Having begun using the library slightly beyond the boundaries of ‘standard’ scenario, we discovered several issues (#419, #420, #483, #496). The author of the library answered to questions quite fast, and most of the problems were quickly resolved. Now, only one task is left (don’t be confused with its Closed status). This is an issue of the competitive access. It seems like very nasty race-condition is hiding somewhere deep in the library. We passed over this bug in quite original way (I intend to write a separate article on this subject).
I would also like to mention the absence of neat editor and viewer. There is LiteDBShell, but is only for true console fans.
Summary
We have built a big and important functionality over LiteDB, and now we are working on another big feature where we will use this library as well. For those looking for an in-process database, I suggest paying attention to LiteDB and to the way it will prove itself in the context of your task, since, as you know, if something had worked out for one task, it would not necessarily work out for another task.
Tags: sql server Last modified: September 23, 2021





SQLite for IIS ? multi-thread, multi-session (per user) ?