This article is devoted to the GetHashCode method and the GetHashCode implementation in the .NET Framework. The article also discusses the different behavior of the method for reference types and value types. The topic is quite interesting and any self-respecting .NET developer needs to know it. So let’s go!
What’s stored in reference-type objects apart from their field?
Let’s begin our story with learning what is stored in reference-type objects in addition to their fields.
Each reference type object has the so-called header, which consists of two fields: a pointer to the type of the object (MethodTablePointer), as well as a synchronization index (SyncBlockIndex).
What are they needed for?
The first field is required to allow every managed object to provide information about its type at runtime. to ensure type security, it is impossible to substitute one type for another. The pointer is also used to implement dynamic dispatch of methods. In fact, it is used to call the methods of this object. The Object.GetType method actually returns MethodTablePointer.
The second field is required for a multi-threaded environment, namely, to allow using every object in a thread-safe manner.
When CLR is loaded, it creates a so-called pool of sync blocks, in other words, a standard array of the sync blocks. When the object needs to operate in a multithreaded environment (this is done using the Monitor.Enter method or the C# construct lock), CLR searches a free synchronization block in its list and records its index in the field in the object’s header. Once the object no longer requires the multi-threaded environment, CLR simply assigns value -1 to this field and thereby frees the synchronization block.
A synchronization block is actually a new embodiment of critical sections from C++. The authors of CLR felt that associating a critical section structure with each managed object would be too laborious, considering that most of the objects do not use a multi-threaded environment.
For better insight into the situation, consider the following picture:
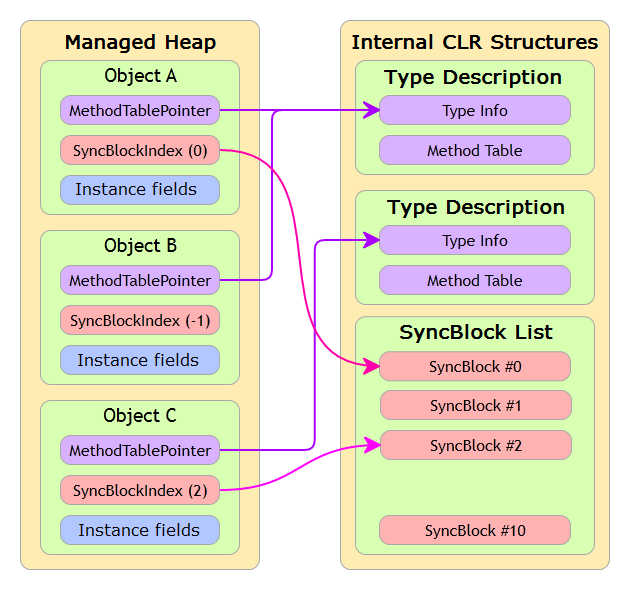
As the picture shows, ObjectA and ObjectB have the same type since their MethodTablePointer point to the same type. Whereas ObjectC has a different type. You can see that ObjectA and ObjectC use the pool of synchronization blocks, i.e. they use a multi-threaded environment. ObjectB does not use the pool since its SyncBlockIndex = -1.
Now, after we have considered how objects are stored, we can proceed to the generation of hash codes.
How GetHashCode deals with reference types
The fact that the GetHashCode method returns the object address in a managed heap is a myth. This cannot be true because of its inconstancy. The garbage collector while compacting a hip shifts objects and thus changes all their addresses.
There is a good reason why I’ve started the article with the explanation of what SyncBlock is since the first version of the framework used a free index of a SyncBlock as a reference type hash code. Thus, in .NET 1.0 and .NET 1.1, call of the GetHashCode method leads to the creation of SyncBlock and recording its index into the object’s header in the SyncBlockIndex field. As you can see, this is not a good implementation of the hash function, because, in the first place, it creates unnecessary internal structures that occupy memory + it takes up time for creating them, and, secondly, the hash codes will come in succession, i.e. they will be predictable. Here is a link to the blog, in which one of the CLR developers reports that such implementation is bad and that they will change it in the next version.
Starting from .NET 2.0, the hashing algorithm has been changed. Now, it uses a managed identifier of the thread, in which the method is running. Relying on the implementation in SSCLI20, the method looks like this:
inline DWORD GetNewHashCode()
{
// Every thread has its own generator for hash codes so that we won't get into a situation
// where two threads consistently give out the same hash codes.
// Choice of multiplier guarantees period of 2**32 - see Knuth Vol 2 p16 (3.2.1.2 Theorem A)
DWORD multiplier = m_ThreadId*4 + 5;
m_dwHashCodeSeed = m_dwHashCodeSeed*multiplier + 1;
return m_dwHashCodeSeed;
}
Thus, each thread has its own generator for hash codes, so that we can not get into a situation where the two threads sequentially generate the same hash codes.
As before, the hash code is calculated once and stored in the object’s header in the SyncBlockIndex field (this is the CLR optimization). Now the question arises: what if after calling GetHashCode, we will need to use the synchronization index? Where should we write it? And what should we do with the hash code?
To answer these questions, let’s consider the SyncBlock structure.
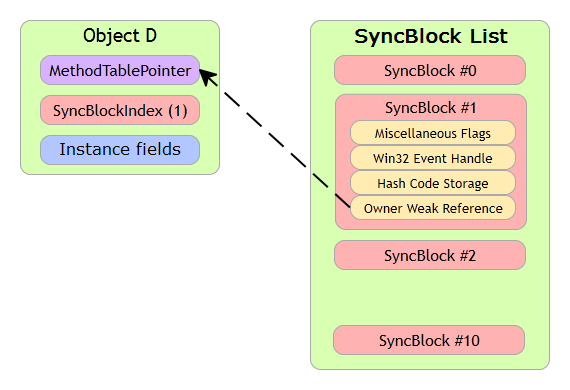
When you first call the GetHashCode method, CLR evaluates the hash code and puts it in the SyncBlockIndex field. If SyncBlock is associated with the object, i.e. the SyncBlockIndex field is used, CLR records the hash code in SyncBlock itself. The drawing shows a place in SyncBlock, which is responsible for storing the hash code. Once SyncBlock is free, CLR copies the hash code from its body to the object’s header SyncBlockIndex. That’s all.
How GetHashCode deals with value types
Now, let’s talk about how the GetHashCode method works for value types. Looking ahead, I can say that it is a matter of interest.
The first thing to mention is the fact that the authors of CLR recommend you to always override this method in user-defined types, since it may work not very quickly, and its default behavior may not always satisfy you.
In fact, CLR has two versions of implementation of the GetHashCode method for value types, and the version to be used depends entirely on the type itself.
First version:
If the structure does not have reference fields and there is no free space between its fields, then a quick version of the GetHashCode method is used. CLR simply xors every 4th byte of the structure and receives a response. This is a good hash because all the structure contents are involved. For example, a structure that has a field of type bool and int will have a 3-byte free space, since JIT, when allocating fields, aligns them by 4 bytes, and therefore, the second version will be used for obtaining the hash code.
By the way, this version had a bug which was corrected only in .NET 4. The bug was the incorrectly calculated hash code for the decimal type.
Consider the following code:
decimal d1 = 10.0m; decimal d2 = 10.00000000000000000m;
In terms of numbers, d1 and d2 are equal, but their bit representations differ (due to some peculiarities of decimal representation). And since CLR xors every 4th byte (there are only 4 of them since decimal takes up 16 bytes), we obtain different hash codes. By the way, this bug manifested itself not only in decimal, but also in any structure that contains this type, and also uses the fast version to calculate hash codes.
The second version:
If the structure contains reference fields or there is a free space between the fields, the slow version of the method is used. CLR selects the first field of the structure on the basis of which it creates a hash code. Preferably, this field should be immutable, for example, be of the string type. Otherwise, when it changes, the hash code will also change, and we will no longer be able to find our structure in the hash table if it was used as a key. So, if the first field of the structure will be changeable, then this breaks the standard logic of the GetHashCode method. This is another reason why the structure should not be changed. CLR xors the hash code of this field with a pointer to the type of this field (MethodTablePointer). CLR does not consider static fields, as may the field with the same type can be a static field, whereby we will fall into an infinite recursion.
Comments of the CLR developers to the GetHashCode method in ValueType:
/*=================================GetHashCode=========================== ** Action: Our algorithm for returning the hashcode is a little bit complex. We look ** for the first non-static field and get it's hashcode. If the type has no ** non-static fields, we return the hashcode of the type. We can't take the ** hashcode of a static member because if that member is of the same type as ** the original type, we'll end up in an infinite loop. **Returns: The hashcode for the type. **Arguments: None. **Exceptions: None. ======================================================================*/ [MethodImplAttribute(MethodImplOptions.InternalCall)] public extern override int GetHashCode(); // Note that for correctness, we can't use any field of the value type // since that field may be mutable in some way. If we use that field // and the value changes, we may not be able to look up that type in a // hash table. For correctness, we need to use something unique to // the type of this object. // HOWEVER, we decided that the perf of returning a constant value (such as // the hash code for the type) would be too big of a perf hit. We're willing // to deal with less than perfect results, and people should still be // encouraged to override GetHashCode.
Note
Structures cannot have instance fields of the same type. That is, the following code will not be compiled:
public struct Node
{
int data;
Node node;
}
This is due to the fact that the structure can not be set to null. The following code proves that this is not possible:
var myNode = new Node (); myNode.node.node.node.node.node.node.node.node.node .......
Whereas, static fields of the same type are allowed, as they are stored in a single copy in the type of this structure. That is, the following code is perfectly valid:
public struct Node
{
int data;
static Node node;
}
Note
To understand the situation better, consider the following code:
var k1 = new KeyValuePair <int, int> (10, 29);
var k2 = new KeyValuePair <int, int> (10, 31);
Console.WriteLine ( "k1 - {0}, k2 - {1}", k1.GetHashCode (), k2.GetHashCode ());
var v1 = new KeyValuePair <int, string> (10, "abc");
var v2 = new KeyValuePair <int, string> (10, "def");
Console.WriteLine ( "v1 - {0}, v2 - {1}", v1.GetHashCode (), v2.GetHashCode ());
In the first case, the structure does not have reference fields and free space between the fields, since the int field occupies 4 bytes, so the fast version is used for calculating the hash code. Thus, the following will be displayed on the screen:
k1 – 411 217 769, k2 – 411217771
In the second case, the structure has a reference field (string), so the slow version is used. CLR uses the int type field as a field for generating a hash code, and the string field is simply ignored, as a result, the console will display the following:
v1 – 411 217 780, v2 – 411217780
Now you understand why the CLR developers say that all user-defined value types (and not only value types, but all types) override the GetHashCode method. Firstly, it can work not very quickly, and secondly, to avoid misunderstanding of why hash codes of different objects are equal, as in the second case of the example.
If you do not override the GetHashCode method, you can get a big performance hit when using a value type as a key in the hash table.
How GetHashCode deals with string type
The String class overrides the GetHashCode method. Its implementation in .NET 4.5 is as follows:
GetHashCode X64
public override unsafe int GetHashCode()
{
if (HashHelpers.s_UseRandomizedStringHashing)
return string.InternalMarvin32HashString(this, this.Length, 0L);
fixed (char* chPtr1 = this)
{
int num1 = 5381;
int num2 = num1;
char* chPtr2 = chPtr1;
int num3;
while ((num3 = (int) *chPtr2) != 0)
{
num1 = (num1 << 5) + num1 ^ num3;
int num4 = (int) chPtr2[1];
if (num4 != 0)
{
num2 = (num2 << 5) + num2 ^ num4;
chPtr2 += 2;
}
else
break;
}
return num1 + num2 * 1566083941;
}
}
This is the code for a 64-bit machine, but if you look at the general code with directives:
GetHashCode
public int GetHashCode()
{
#if FEATURE_RANDOMIZED_STRING_HASHING
if(HashHelpers.s_UseRandomizedStringHashing)
{
return InternalMarvin32HashString(this, this.Length, 0);
}
#endif // FEATURE_RANDOMIZED_STRING_HASHING
unsafe
{
fixed (char* src = this)
{
#if WIN32
int hash1 = (5381<<16) + 5381;
#else
int hash1 = 5381;
#endif
int hash2 = hash1;
#if WIN32
// 32 bit machines.
int* pint = (int *)src;
int len = this.Length;
while (len > 2)
{
hash1 = ((hash1 << 5) + hash1 + (hash1 >> 27)) ^ pint[0];
hash2 = ((hash2 << 5) + hash2 + (hash2 >> 27)) ^ pint[1];
pint += 2;
len -= 4;
}
if (len > 0)
{
hash1 = ((hash1 << 5) + hash1 + (hash1 >> 27)) ^ pint[0];
}
#else
int c;
char* s = src;
while ((c = s[0]) != 0)
{
hash1 = ((hash1 << 5) + hash1) ^ c;
c = s[1];
if (c == 0)
break;
hash2 = ((hash2 << 5) + hash2) ^ c;
s += 2;
}
#endif
return hash1 + (hash2 * 1566083941);
}
}
}
Implementation of hash-coding for a string type does not imply caching the result. That is, every time you call the GetHashCodemethod, the hash code for the string will be calculated. According to Eric Lippert, this is done to save memory, extra 4 bytes for each string type object are not worth it. Given that the implementation of very fast, I think that’s the right decision.
If you noticed, the implementation of the GetHashCode method now includes the code, which was not there before:
if (HashHelpers.s_UseRandomizedStringHashing) return string.InternalMarvin32HashString (this, this.Length, 0L);
It appears that in .NET 4.5, you can calculate a hash code for lines for each domain. Thus, by setting the attribute value to 1, you can get to the hash code to be calculated basing on the domain in which the method is called. Thus, the same lines in different domains will have different hash codes. The method that generates a hash code is secret and its implementation is not disclosed.
How GetHashCode deals with delegates
Before proceeding to the discussion on how the GetHashCode method is implemented in delegates, let’s talk about how they are implemented.
Each delegate is inherited from the MulticastDelegate class, which, in turn, is inherited from the Delegate class. This hierarchy has developed historically, as one could do with the MulticastDelegate class alone.
The implementation of the GetHashCode method in the Delegate class looks as follows:
public override int GetHashCode ()
{
return this.GetType () GetHashCode ();
}
That is, the hash code of the delegate type actually returns. It turns out that the delegates of the same type containing different methods to call always return the same hash code.
As is known, delegates may contain chains of methods, that is, the call of one delegate will lead to the call of several methods. In this case, such implementation is not suitable since the delegates of the same type, regardless of the number of methods, would have the same hash code, which is not very good. Therefore, in MulticastDelegate, the GetHashCode method has been overridden such that it uses every method underlying the delegate. However, if the number of methods and the type of delegates are the same, then the hash codes will be identical as well.
The method implementation in the MulticastDelegate class looks as follows:
public override sealed int GetHashCode ()
{
if (this.IsUnmanagedFunctionPtr ())
return ValueType.GetHashCodeOfPtr (this._methodPtr) ^ ValueType.GetHashCodeOfPtr
(this._methodPtrAux);
object[] objArray = this._invocationList as object [];
if (objArray == null)
return base.GetHashCode ();
int num = 0;
for (int index = 0; index <(int) this._invocationCount; ++ index)
num = num * 33 + objArray [index] .GetHashCode ();
return num;
}
The delegate is known to store its methods in _invocationList only when there is more than one method.
If the delegate has only one method, then in the code above objArray = null and, therefore, the delegate hash code will be equal to the hash code of the delegate type.
object[] objArray = this._invocationList as object []; if (objArray == null) return base.GetHashCode ();
To clarify the matter, consider the following code:
Func <int> f1 = () => 1; Func <int> f2 = () => 2;
The hash codes of these delegates are equal to the Func <int> type hash code, that is, they are identical.
Func <int> f1 = () => 1; Func <int> f2 = () => 2; f1 + = () => 3; f2 + = () => 4;
In this case, the hash codes of the delegates coincide as well, though the methods are different. In this case, the following code is used to calculate the hash code:
int num = 0; for (int index = 0; index <(int) this._invocationCount; ++ index) num = num * 33 + objArray [index] .GetHashCode (); return num;
and the last case:
Func <int> f1 = () => 1; Func <int> f2 = () => 2; f1 + = () => 3; f1 + = () => 5; f2 + = () => 4;
The hash codes will differ because the number of methods in theses delegates is not the same (each method has an impact on the resulting hash code).
How GetHashCode deals with anonymous types
As you know, the anonymous type is a new feature in C# 3.0. Moreover, this is the feature of the language, the so-called syntactic sugar because CLR knows nothing about them.
The GetHashCode method for them is overridden so that it uses every field. Using this implementation, two anonymous types return the same hash code if and only if all the fields are equal. This implementation makes the anonymous types suitable for the keys in hash tables.
var newType = new {Name = "Timur", Age = 20, IsMale = true};
The following code will be generated for such an anonymous type:
public override int GetHashCode ()
{
return -1521134295 * (-1521134295 * (-1521134295 * -974875401 +
EqualityComparer <string> .Default.GetHashCode (this.Name)) +
EqualityComparer <int> .Default.GetHashCode (this.Age)) +
EqualityComparer <bool>. Default.GetHashCode (this.IsMale);
}
Note
Since the GetHashCode method is overridden, the Equals method should be also overridden accordingly.
var newType = new {Name = "Timur", Age = 20, IsMale = true};
var newType1 = new {Name = "Timur", Age = 20, IsMale = true};
if (newType.Equals (newType1))
Console.WriteLine ( "method Equals return true");
else
Console.WriteLine ( "method Equals return false");
if (newType == newType1)
Console.WriteLine ( "operator == return true");
else
Console.WriteLine ( "operator == return false");
The following will be displayed on the console:
method Equals return true
operator == return false
The thing is that anonymous types override the Equals method so that it checks all the fields as it is implemented in ValueType (only without reflection), but does not override the equality operator. Thus, the Equals method compares by value, whereas the equality operator compares the references.
Reasons for overriding the Equals and GetHashCodemethods
Since anonymous types were created to simplify the work with LINQ, the answer becomes clear. It is convenient to use anonymous types as hash keys in the group and join operations in LINQ.
Conclusion
As you can see, the generation of hash codes is not an easy thing. In order to generate a good hash code, you need to make significant efforts, and the CLR developers had to make many concessions in order to make our lives easier. It is impossible to generate a good hash code for all cases, so it is better to override the GetHashCode method for all your user-defined types, thereby adjusting them to a particular situation of yours.
Thank you for reading! I hope this article was useful. Feel free to ask any questions, leave your comments and suggestions concerning this article.
Tags: .net, .net framework Last modified: September 23, 2021



Notice the bug in the 64-bit implementation of string’s GetHashCode… which has been there since .Net 2.0 despite being reported before 2.0 release and several times since?
The loop building hash codes terminates if there’s a zero-Char found in the string. Strings in .Net are NOT terminated by null bytes, they are given a length.
This caused all kinds of problems when I first saw code written and tested on 32-bit runtimes get used on the 64-bit runtime, tons of hash collisions because I had synthesized “keys” that used embedded nulls between the concatenated sub-strings. I later swapped to RS (control character 30 decimal)