In this article, let us review row-level and column-level tracking options in merge replication and how these are used in detecting conflicts during merge replication.
Merge Replication: Merge replication is used to replicate data in both ways i.e. from the publisher to the subscriber and from the subscriber to the publisher.
The initial snapshot of objects is taken and applied to subscribers. Incremental data changes and schema changes are tracked using triggers and applied to subscribers when the subscriber synchronizes with the publisher.
Conflicts:
In merge replication, both the subscriber and publisher are independent, and data can be modified on any node.
When data is modified on both the publisher and the subscriber within the replication cycle, and when the subscriber synchronizes with the publisher, a conflict occurs. The merge agent determines the winner on both sides depending on the conflict resolver. By default, the winner is determined by different parameters such as a client or server subscription, pull or push subscription, etc.
Conflict Detection:
The conflict detection depends on the type of tracking we configure for the article.
- Row-level tracking: If data changes are made to any column on the same row at both ends, then it is considered a conflict.
- Column-level tracking: If data changes are made on the same column at both ends, this change is qualified as a conflict.
Resolvers:
Resolvers apply the winner data at both ends when a conflict occurs.
By default, if there is a conflict between the publisher and the subscriber, the publisher always wins.
If a conflict occurs between two subscribers, the winner is determined by the client/server subscriber and pull/push subscriptions.
In addition to the default resolver, there are few custom resolvers as well. We will discuss custom resolvers in upcoming articles.
Configure merge replication with row-level tracking:
Publisher database: pub_db
Subscriber database: sub_db
Let us create the “TBL_EMP” table and add it to merge replication.
CREATE TABLE TBL_EMP (EmpID INT, Emp_FName varchar(100),Emp_Lname varchar(100)) INSERT INTO TBL_EMP VALUES (1,'Jhon','P') INSERT INTO TBL_EMP VALUES (2,'Alison','P') INSERT INTO TBL_EMP VALUES (3,'Angela','P')
To configure the merge replication, the publisher should be configured to use local distribution or remote distribution.
Once the distribution is configured, navigate to the replication folder in SSMS and right-click local publications.
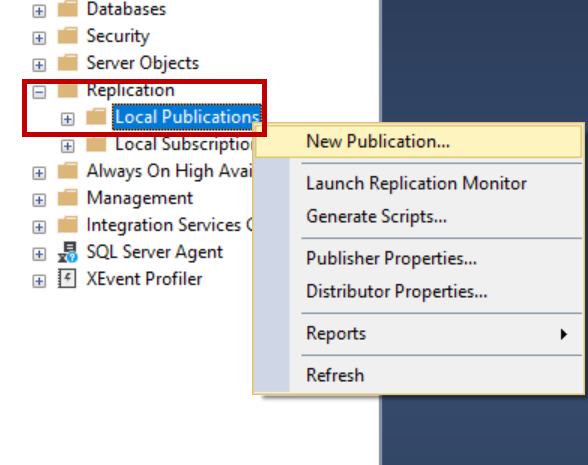
Click Next and select the publication database, click Next and select the merge replication, select 2008 or later and add the table to the replication.
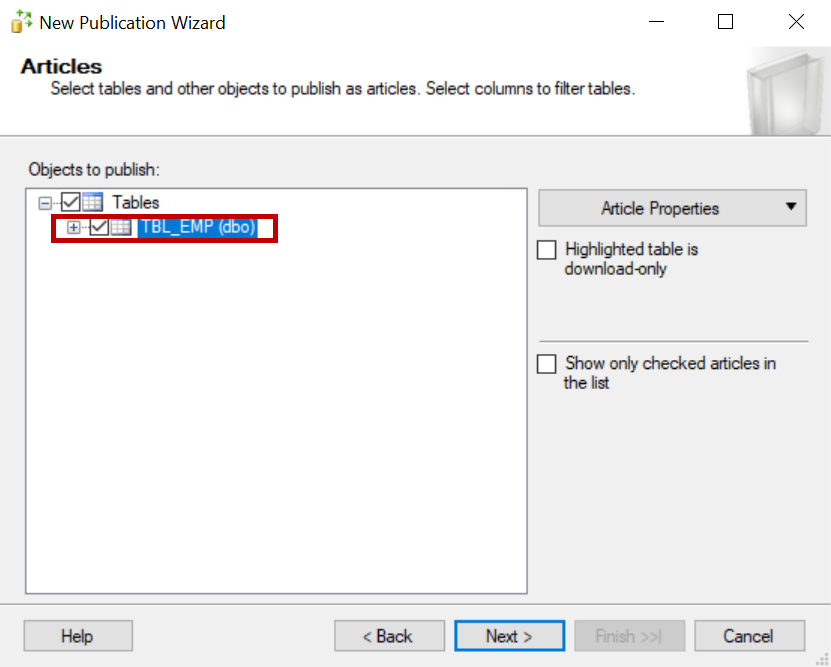
Now click the article properties and select the properties of the highlighted article.
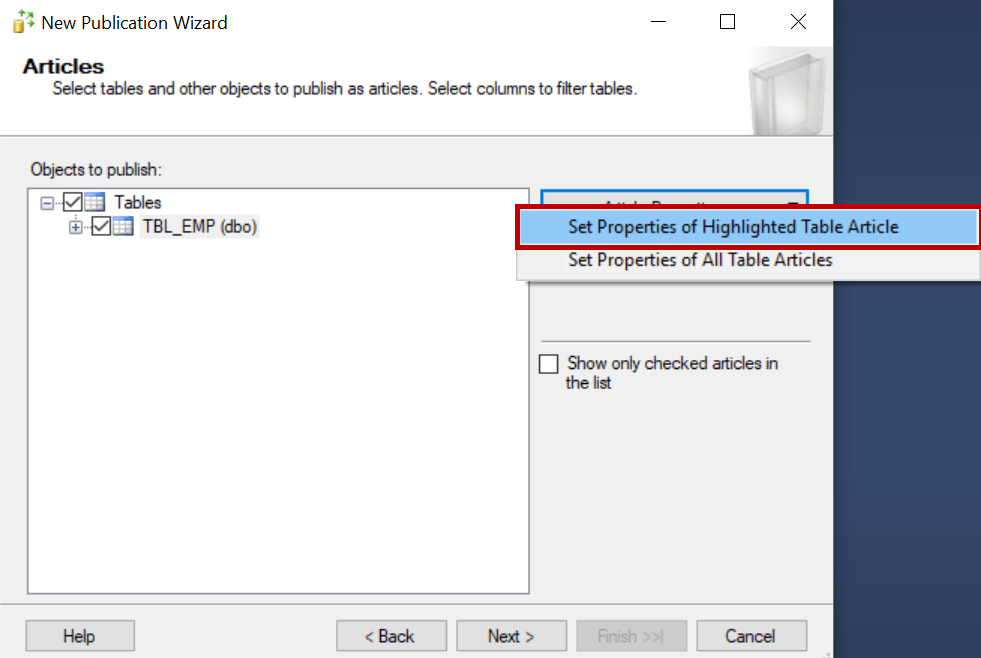
Select the tracking level to be the row-level tracking.
![]()
By default, it will be the row-level tracking. Click OK, Next, Next. Add a filter if you want to send specific data to the subscriber, else ignore, enable Create snapshot immediately, configure the agent security as per your needs, enable Create publication, specify the name of the publication and click Finish.
Once the initial snapshot is generated, add the subscriber.
Navigate to the publication you create in the replication folder on the publisher, right-click and select New subscription.
Click Next, select the publication, click Next and select the pull or push subscription as per your needs. In this case, I used push subscription.
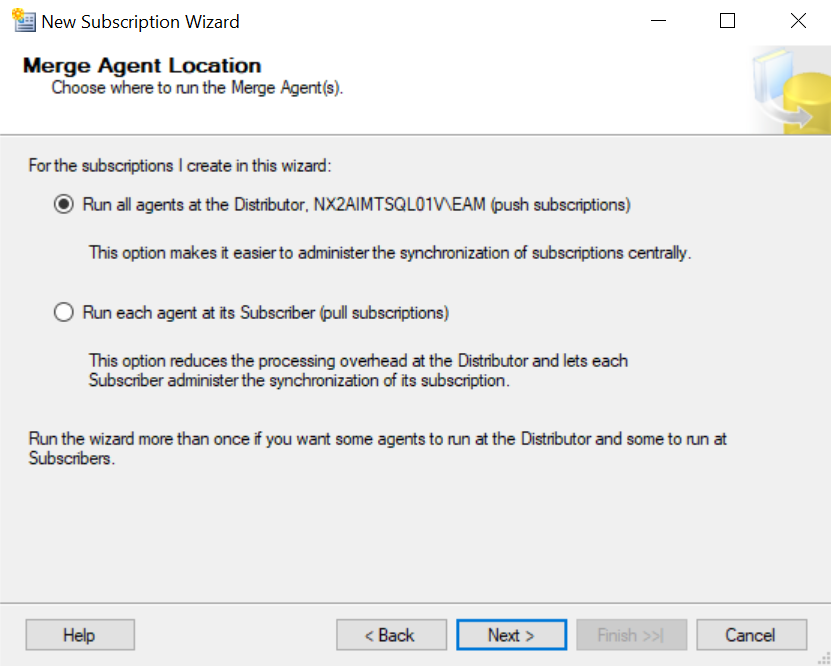
Select the subscription database and click Next, configure the login credentials for the merge agent, and click Next.
Choose the agent schedule as per your needs. In this case, I used Run on demand only. Click Next, select Initialize immediately and select client as the subscription type, click Next, enable Create subscription, click Next and Finish.
Once the initial snapshot is applied, run the statement below on the publisher to update the record.
update TBL_EMP set Emp_Fname = 'Amanda' where empid = 1
Now, on the subscriber db, run the statement below to update the last name.
update TBL_EMP set Emp_Lname = 'A' where empid = 1
Now, the same row was has been modified both in the publisher database and the subscriber database within the same replication cycle.
As per the tracking option we set i.e. row-level tracking, the change is considered a conflict and will be logged in the conflict tables when the merge agent runs.
Navigate to the publication you created and expand the publication to see subscriptions. Right-click the subscription, select View synchronization status, and click Start.
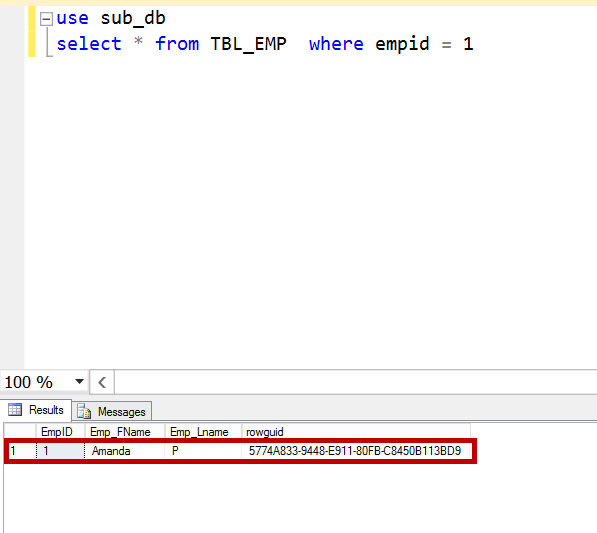
Once the merge agent has run successfully, go to the subscriber and check the data using the statement below.
use sub_db select * from TBL_EMP where empid = 1
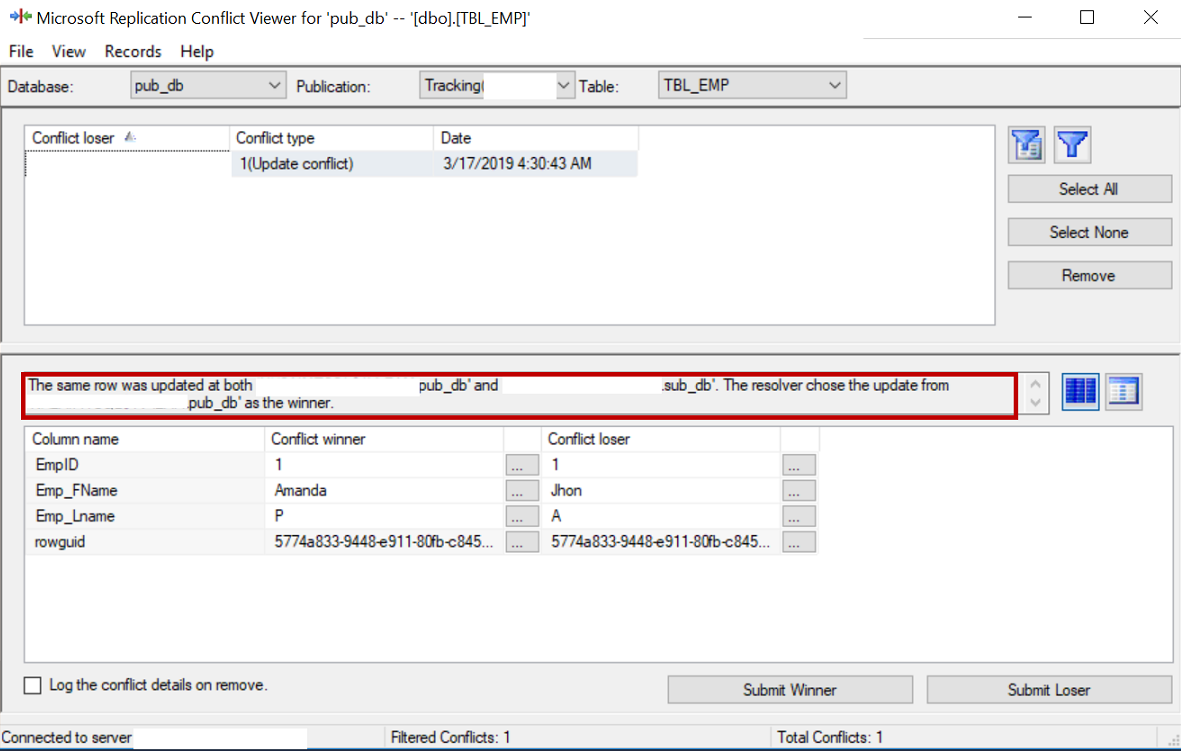
We can see that change from the publisher has won and the change from the subscriber has lost.
The conflict information is stored in the conflict tables and can be viewed in the conflict viewer.
Navigate to the publisher, right-click it and select View conflicts.
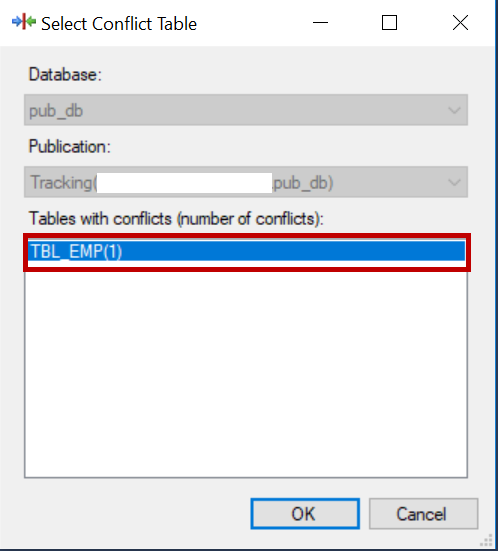
Select the conflict table and click OK to view details.
Changing the tracking level
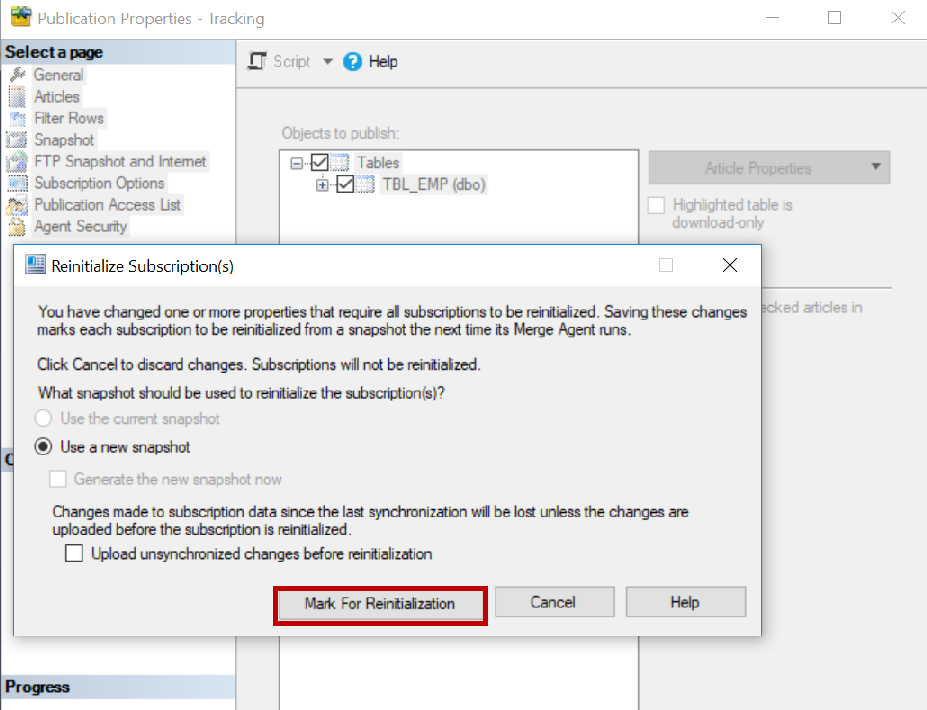
Now let us change the tracking level to the column-level tracking. Navigate to the publication, right-click it and select Publisher properties. Click Articles, select the table, click Article properties, set properties of highlighted table article, select Column-level tracking, click OK, click OK and then click Mark for reinitialization.
This will mark all the subscribers for reinitialization as we are changing the existing tracking level to a new one.
Navigate to the publication, right-click the publication and click View snapshot agent status, click Start to generate a new snapshot. There are other ways to generate a snapshot as well.
Now, run the statement below against the publisher to update a record.
update TBL_EMP set Emp_Fname = 'Amanda' where empid = 2
Now, run the statement below against the subscriber db to update the Last name.
update TBL_EMP set Emp_Lname = 'A' where empid = 2
Run the merge agent manually. I still see the conflict on the record even though we updated two different columns and set the tracking level to the column level.
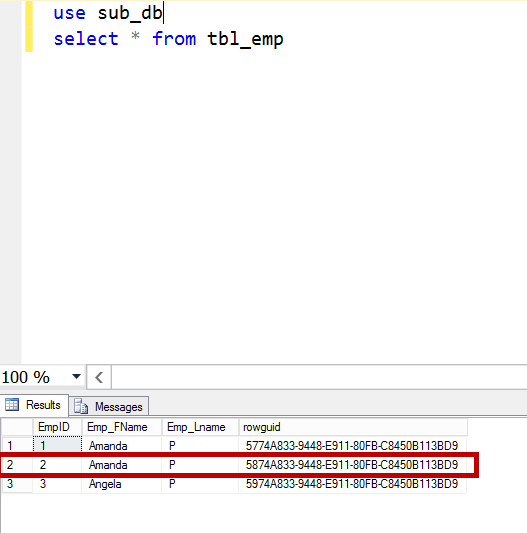
We can see the details in the conflict viewer. Changing the existing tracking level did not work. So, I reconfigured the publication, set the tracking level to the column-level tracking before generating the initial snapshot. A snapshot was created and a subscriber was added to the publication.
Once the initial snapshot is applied to the subscriber, run the following statements in the publisher database.
update TBL_EMP set Emp_Fname = 'Amanda' where empid = 3
Run the following statement in the subscriber database.
update TBL_EMP set Emp_Lname = 'A' where empid = 3
Run the merge agent manually. Now, in the subscriber database, query the TBL_EMP table.
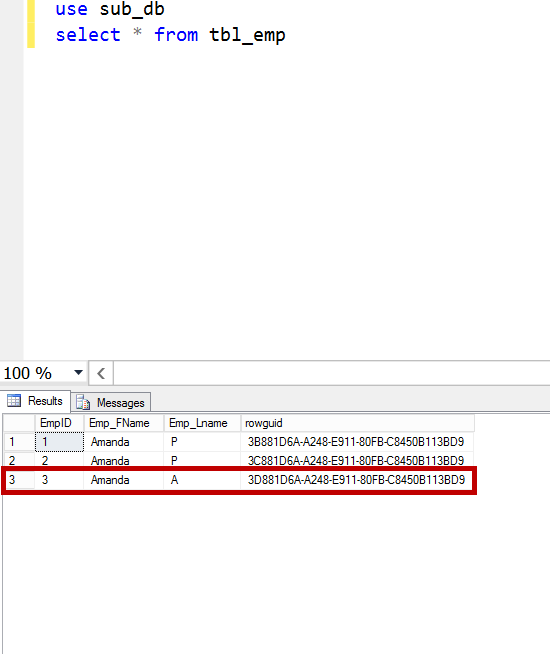
The update from the publisher and the subscriber are not qualified as a conflict as both are on different columns, and the tracking level is set to the column-level tracking. No conflict is logged in the conflict tables, the updates on both the publisher and the subscriber on different columns are not lost.
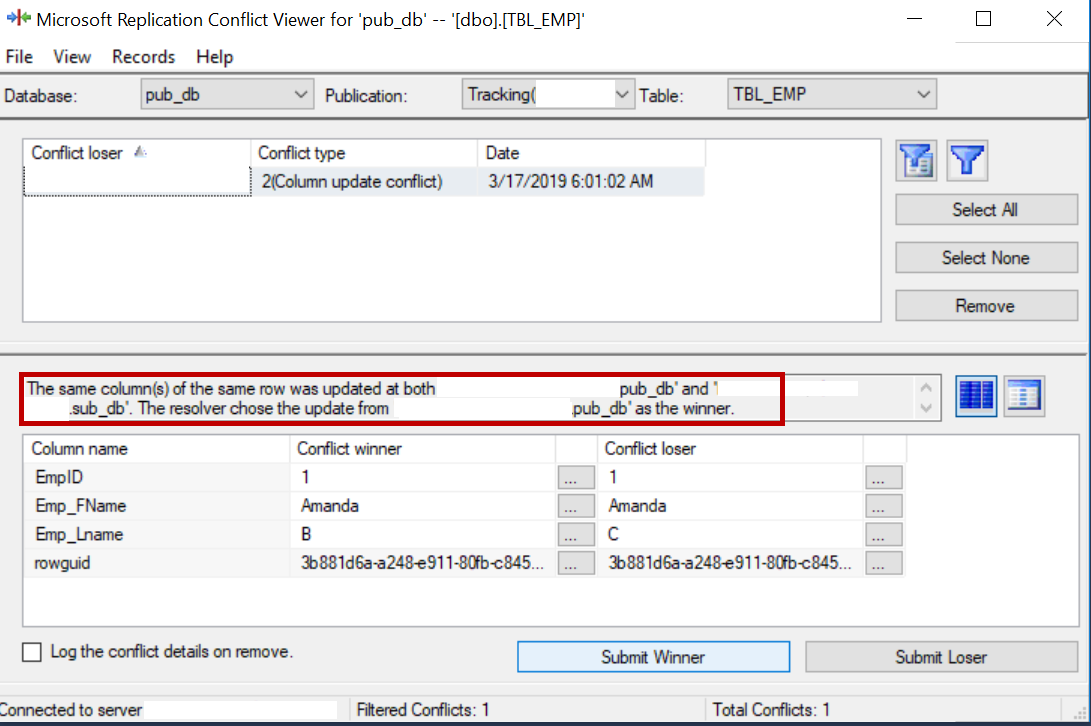
Let us update the same column on the publisher and the subscriber.
Execute the following statement against the publisher database.
use pub_db update TBL_EMP set Emp_Lname = 'B' where empid = 1
Execute the following statement against the subscriber database.
use sub_db update TBL_EMP set Emp_Lname = 'C' where empid = 1
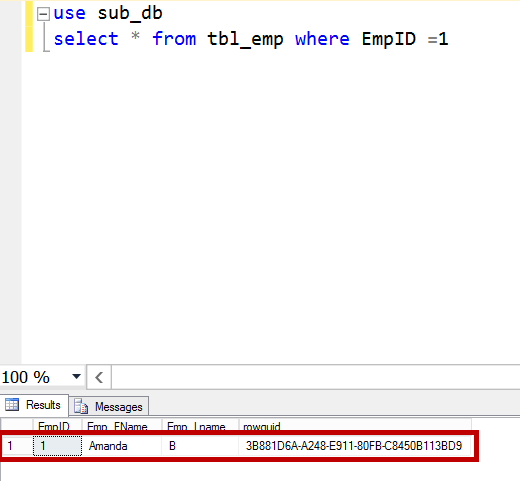
Run the merge agent and query the TBL_EMP table on the subscriber. The update on the subscriber is lost and the conflict is logged.
Performance:
There may be performance overhead with the column-level tracking as compared to the row-level tracking when there are huge updates. But in my case, I did not notice any difference in synchronization timings for both the row-level and column-level tracking in case of huge updates as the table may be simple in structure (i.e. very few columns) and both the subscriber and the publisher are on the same SQL server instance.
Notes:
- By default, it is always row-level tracking when merge replication is configured.
- The tracking level option depends on a table. So, you can have a row-level on one table and a column level on another table.
- These options only help when a conflict is detected based on an update, not resolving it.
- Reconfigure the publication if changing the existing tracking level does not work.
- Set tracking level according to your business needs.






