The Relational Model of data management was first developed by Dr. Edgar F. Codd in 1969. Modern relational database management systems (RDBMSes) are aligned with the paradigm. The key structure identified with RDBMS is the logical structure called a “table”. Tables are primarily composed of rows and columns (also called records and attributes or tuples and fields). In a strict mathematical sense, the term table is actually referred to as a relation and accounts for the term “Relational Model”. In mathematics, a relation is a representation of a set.
The expression attribute gives a good description of the purpose of a column – it characterizes the set of rows associated with it. Each column must be of a particular data type and each row must have some unique identifying characteristics called “keys”. Data change is typically more efficient when done using the relational model while data retrieval may be faster with the older Hierarchical Model which has been redefined in model NoSQL systems.
Data Normalization is a mathematical process of modeling business data into a form which ensures that each entity is represented by a single relation (table). The early proponents of the relational model proposed a concept of Normal Forms. Edgar Codd defined the first, the second, and third Normal Forms. He was then joined by Raymond F. Boyce. Together they defined the Boyce-Codd Normal Form. By now, six Normal Forms are defined theoretically but in most practical applications, we typically extend Normalization up to the Third Normal Form. Each Normal Form strives to avoid anomalies during data modification, reduce the redundancy and dependency of data within a table. Each level of normalization tends to introduce more tables, reduce redundancy, increase the simplicity of each table but also increases the complexity of the entire relational database management system. So structurally RDBM systems tend to be more complex than Hierarchical systems.
Why Database Normalization: Four Anomalies
Data storage without normalization causes a number of problems with data consumption. The proponents of normalization called such problems anomalies. In order to describe these anomalies, let’s look at the data presented in Fig. 1.

Fig. 1 Staffers Table
Listing 1. Basic Table to Demonstrate Database Normalization.
1.1. Create Table
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Insert Rows
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965');
1.3. Query the Table
select * from staffers;
This table represents in essence two sets of data that have been inadvertently combined: staff names and departments. Notice that all staff is from the same department: Engineering. That was done for simplicity and in order to demonstrate normalization. There are three main problems associated with manipulating this structure:
The Insertion Anomaly
In order to insert a new record, we have to keep repeating the department and manager names.
The Deletion Anomaly
In order to delete a staffer’s record, we must also delete the associated manager and department. If there is a need to remove ALL staffers’ records, we must also remove all departments and all managers.
The Update Anomaly
If there is a need to change the manager of any department, we must make the change in every single row of this table since the values are duplicated for each staffer.
Database Normal Forms
In the following sections of the article, we shall try to describe the 1st, the 2nd, and the 3rd Normal Forms which are much more likely to be observed in real RDBM Systems. There are other extensions of the theory such as the Fourth, the Fifth, and Boyce-Codd Normal Forms but in this article, we shall limit ourselves to Three Normal Forms.
The First Normal Form
The 1st Normal Form is defined by four rules:
-
Each column must contain values of the same data type.
The Staffers table already meets this rule.
-
Each column in a table must be atomic.
This essentially means you should divide the contents of a column until they can no longer be divided. Notice that the Role column in the Staffers table breaks rule 2 for the row with StaffID=3.
-
Each row in a table must be unique.
Uniqueness in normalized tables is typically achieved using Primary Keys. A Primary Key uniquely defines each row in a table. Most of the time a Primary Key is defined by only one column. A Primary Key composed of more than one column is called a Composite Key.
-
The order in which records are stored does not matter.
To align the data in the Staffers table with the tenets of the First Normal Form we need to split the table as shown in Figures 2, 3 and 4.
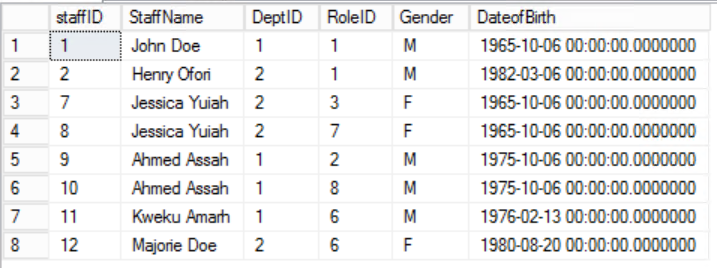
Fig. 2 Staffers Table
We have narrowed down the data in the Staffers table and implemented a Composite Primary Key to guarantee uniqueness. We have also created two additional tables Roles and Departments which have relationships with the core Staffers table implemented using Foreign Keys. Review the DDL in Listing 2.
Listing 2. DDL of New Staffers Table for the First Normal Form.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
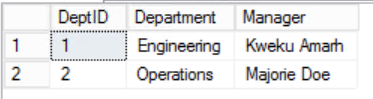
Fig. 3 Departments Table
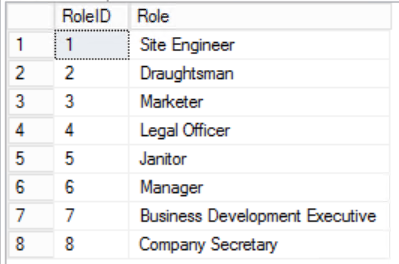
Fig. 4 Roles Table
The Second Normal Form
-
The 1st Normal form must already be in place.
-
Every non-key column must not have Partial Dependency on the Primary Key.
The thrust of the second rule is that all columns of the table must depend on all columns that comprise the Primary Key together. Looking back at the tables in Figures 2, 3 and 4, we find we have achieved all the requirements of the First Normal Form. We have also achieved the requirements of the Second Normal Form for two tables Roles and Departments. However, in the case of the Staffers table, we still have a problem. Our Primary Key is composed of the columns StaffID and RoleID.
Rule 2 of the Second Normal Form is broken here by the fact that the Gender and DateofBirth of staff do not depend on the RoleID. There is a Partial Dependency.
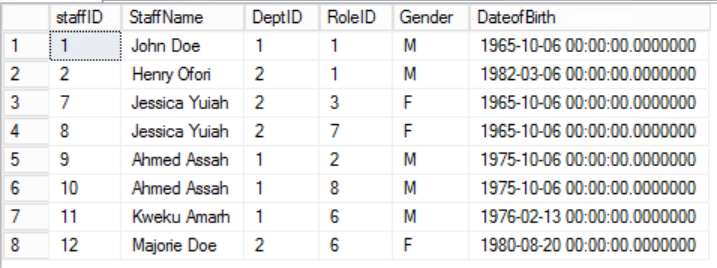
Fig. 5 Staffers for the First Normal Form
In the given example, we can try to fix this by removing RoleID from the Primary Key but if we do this we shall break another rule: the role of uniqueness stated in the First Normal Form. We must take another approach. We’ll modify the Staffers table with the understanding that a staffer can play more than one role. See Fig. 6.
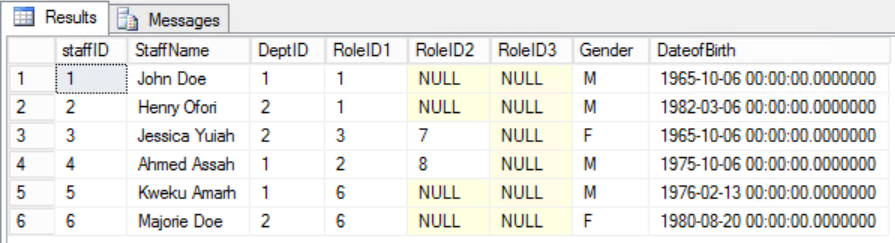
Fig. 6 Staffers Table for the Second Normal Form
We have succeeded in maintaining uniqueness as well as removing Partial Dependency.
Listing 3. DDL of New Staffers Table for the Second Normal Form.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
The Third Normal Form
-
The 2nd Normal form must already be in place.
-
Every non-key column must not have Transitive Dependency on the Primary Key.
The thrust of the third normal form is that there mustn’t be any columns that depend on non-key columns even if that non-key columns already depend on the Primary Key.
As an example, assume we decided to add an additional column to the Staffers table as shown in Fig. 7 in order to clearly see the staffer’s manager. By doing that we would have broken the second Third Normal Form rule, because the Manager Name depends on the DeptID and the DeptID, in turn, depends on the StaffID. This is a Transitive Dependency.
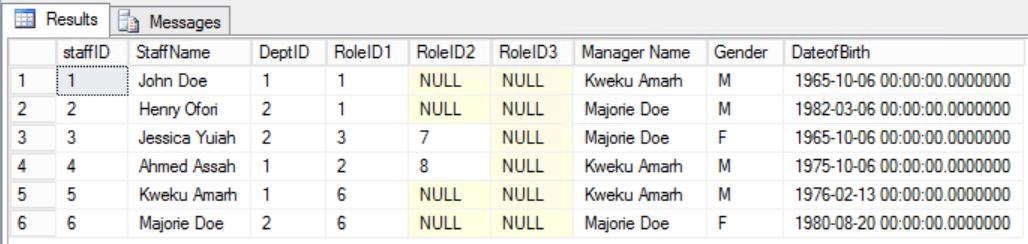
Fig. 7 Staffers Table for the Third Normal Form (Broken Rule)
It would be better to retain the old form and display the required information using a join between the Staffers table and the Department table.
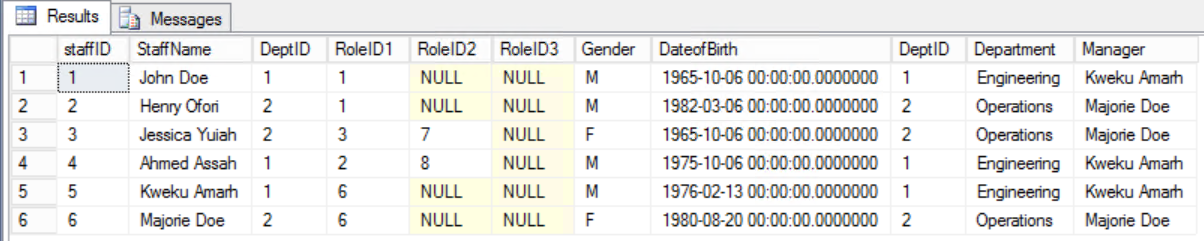
Fig. 8 Join Between Staffer and Department
Listing 4. Query to Display Staff and Managers.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Practical Application
Most mature applications implement the rules of normalization to reasonable extents. We see that data normalization implementation gives rise to the use of Primary Key Constraints and Foreign Key Constraints. In addition, such issues as Foreign Keys indexing also show up as we delve deeper into the subject. Earlier we mentioned how the lack of normalization can affect the smooth manipulation of data as described in the Insertion, Deletion, and Update Anomalies. A lack of proper normalization can also indirectly impact query performance.
I’ve recently come across a table which was of the form shown in table 1 which we shall call Customer_Accounts.
|
S/No |
Name |
Account_No |
Phone_No |
|
1 |
Kenneth Igiri |
9922344592 |
2348039988456, 2348039988456, 2348039988456 |
|
2 |
Ernest Doe |
6677554897 |
2348022887546, 2348039988456 |
Table 1 Customer_Accounts
The main problem with this table is that it breaks the second rule of the First Normal Form. The result in our case was that searching for customers based on their phone numbers required the use of a LIKE in the WHERE clause and a leading %.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
The impact of the above construct was that the optimizer never ever used an index which was a huge performance problem.
Conclusion
Data Normalization lies in the realm of Database Design and both developers and DBAs should pay attention to the rules outlined in this article. It is always better to get normalization done before the database goes into production. The benefits of a properly designed Relational Database Management System are simply worth the effort.
Tags: database administration, rdbms Last modified: September 21, 2021





