For some people, it’s the wrong question. SQL CURSOR IS the mistake. The devil is in the details! You can read all sorts of blasphemy in the entire SQL blogosphere in the name of SQL CURSOR.
If you feel the same way, what made you come to this conclusion?
If it’s from a trusted friend and colleague, I can’t blame you. It happens. Sometimes a lot. But if someone convinced you with proof, that’s a different story.
We haven’t met before. You don’t know me as a friend. But I hope that I can explain it with examples and convince you that SQL CURSOR has its place. It’s not much, but that small place in our code has rules.
But first, let me tell you my story.
I started programming with databases using xBase. That was back in college until my first two years of professional programming. I’m telling you this because back in the day, we used to process data sequentially, not in set batches like SQL. When I learned SQL, it was like a paradigm shift. The database engine decides for me with its set-based commands that I issued. When I learned about SQL CURSOR, it felt like I was back with the old but comfortable ways.
But some senior colleagues warned me, “Avoid SQL CURSOR at all costs!” I got a few verbal explanations, and that was it.
SQL CURSOR can be bad if you use it for the wrong job. Like using a hammer to cut wood, it’s ridiculous. Of course, mistakes can happen, and that’s where our focus will be.

1. Using SQL CURSOR When Set Based Commands Will Do
I can’t emphasize this enough, but THIS is the heart of the problem. When I first learned what SQL CURSOR was, a light bulb lit. “Loops! I know that!” However, not until it gave me headaches and my seniors scolded me.
You see, the approach of SQL is set-based. You issue an INSERT command from table values, and it will do the job without loops on your code. Like I said earlier, it’s the database engine’s job. So, if you force a loop to add records to a table, you’re bypassing that authority. It’s going to get ugly.
Before we try a ridiculous example, let’s prepare the data:
SELECT TOP (500)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
, modified = GETDATE()
, status = 'inserted'
INTO dbo.TestTable
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
SELECT
tt.val
,GETDATE() AS modified
,'inserted' AS status
INTO dbo.TestTable2
FROM dbo.TestTable tt
WHERE CAST(val AS VARCHAR) LIKE '%2%'
The first statement will generate 500 records of data. The second one will get a subset of it. Then, we’re ready. We are going to insert the missing data from TestTable into TestTable2 using SQL CURSOR. See below:
DECLARE @val INT
DECLARE test_inserts CURSOR FOR
SELECT val FROM TestTable tt
WHERE NOT EXISTS(SELECT val FROM TestTable2 tt1
WHERE tt1.val = tt.val)
OPEN test_inserts
FETCH NEXT FROM test_inserts INTO @val
WHILE @@fetch_status = 0
BEGIN
INSERT INTO TestTable2
(val, modified, status)
VALUES
(@val, GETDATE(),'inserted')
FETCH NEXT FROM test_inserts INTO @val
END
CLOSE test_inserts
DEALLOCATE test_inserts
That’s how to loop using SQL CURSOR to insert a missing record one by one. Quite long, isn’t it?
Now, let’s try a better way – the set-based alternative. Here goes:
INSERT INTO TestTable2
(val, modified, status)
SELECT val, GETDATE(), status
FROM TestTable tt
WHERE NOT EXISTS(SELECT val FROM TestTable2 tt1
WHERE tt1.val = tt.val)
That’s short, neat, and fast. How fast? See Figure 1 below:
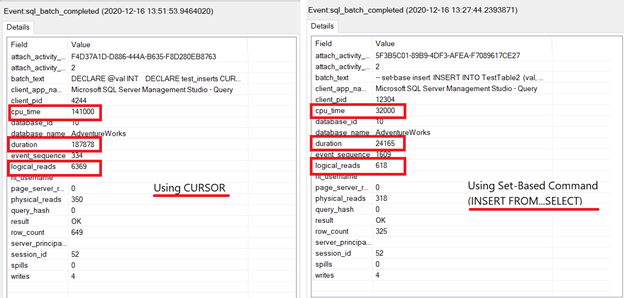
Using xEvent Profiler in SQL Server Management Studio, I compared the CPU time figures, duration, and logical reads. As you can see in Figure 1, using the set-based command to INSERT records wins the performance test. The numbers speak for themselves. Using SQL CURSOR consumes more resources and processing time.
Hence, before you use SQL CURSOR, try to write a set-based command first. It will pay off better in the long run.
But what if you need SQL CURSOR to get the job done?
2. Not Using the Appropriate SQL CURSOR Options
Another mistake even I made in the past was not using appropriate options in DECLARE CURSOR. There are options for scope, model, concurrency, and if scrollable or not. These arguments are optional, and it’s easy to ignore them. However, if SQL CURSOR is the only way to do the task, you need to be explicit with your intention.
So, ask yourself:
- When traversing the loop, will you navigate the rows forward only, or move to the first, last, previous, or next row? You need to specify if the CURSOR is forward-only or scrollable. That’s DECLARE <cursor_name> CURSOR FORWARD_ONLY or DECLARE<cursor_name> CURSOR SCROLL.
- Are you going to update the columns in the CURSOR? Use READ_ONLY if it’s not updateable.
- Do you need the latest values as you traverse the loop? Use STATIC if the values won’t matter if latest or not. Use DYNAMIC if other transactions update columns or delete rows you use in the CURSOR, and you need the latest values. Note: DYNAMIC will be expensive.
- Is the CURSOR global to the connection or local to the batch or a stored procedure? Specify if LOCAL or GLOBAL.
For more information on these arguments, look up the reference from Microsoft Docs.
Example
Let’s try an example comparing three CURSORs for the CPU time, logical reads, and duration using xEvents Profiler. The first will have no appropriate options after DECLARE CURSOR. The second is LOCAL STATIC FORWARD_ONLY READ_ONLY. The last is LOtyuiCAL FAST_FORWARD.
Here’s the first:
-- NOTE: Don't just COPY and PASTE this code then run in your machine. Read and assess.
-- DECLARE CURSOR with no options
SET NOCOUNT ON
DECLARE @command NVARCHAR(2000) = N'SET NOCOUNT ON;'
CREATE TABLE #commands (
ID INT IDENTITY (1, 1) PRIMARY KEY CLUSTERED
,Command NVARCHAR(2000)
);
INSERT INTO #commands (Command)
VALUES (@command)
INSERT INTO #commands (Command)
SELECT
'SELECT ' + CHAR(39) + a.TABLE_SCHEMA + '.' + a.TABLE_NAME
+ ' - ' + CHAR(39)
+ ' + cast(count(*) as varchar) from '
+ a.TABLE_SCHEMA + '.' + a.TABLE_NAME
FROM INFORMATION_SCHEMA.tables a
WHERE a.TABLE_TYPE = 'BASE TABLE';
DECLARE command_builder CURSOR FOR
SELECT
Command
FROM #commands
OPEN command_builder
FETCH NEXT FROM command_builder INTO @command
WHILE @@fetch_status = 0
BEGIN
PRINT @command
FETCH NEXT FROM command_builder INTO @command
END
CLOSE command_builder
DEALLOCATE command_builder
DROP TABLE #commands
GO
There’s a better option than the above code, of course. If the purpose is just to generate a script from existing user tables, SELECT will do. Then, paste the output to another query window.
But if you need to generate a script and run it at once, that’s a different story. You must evaluate the output script if it’s going to tax your server or not. See Mistake #4 later.
To show you the comparison of three CURSORs with different options, this will do.
Now, let’s have a similar code but with LOCAL STATIC FORWARD_ONLY READ_ONLY.
--- STATIC LOCAL FORWARD_ONLY READ_ONLY
SET NOCOUNT ON
DECLARE @command NVARCHAR(2000) = N'SET NOCOUNT ON;'
CREATE TABLE #commands (
ID INT IDENTITY (1, 1) PRIMARY KEY CLUSTERED
,Command NVARCHAR(2000)
);
INSERT INTO #commands (Command)
VALUES (@command)
INSERT INTO #commands (Command)
SELECT
'SELECT ' + CHAR(39) + a.TABLE_SCHEMA + '.' + a.TABLE_NAME
+ ' - ' + CHAR(39)
+ ' + cast(count(*) as varchar) from '
+ a.TABLE_SCHEMA + '.' + a.TABLE_NAME
FROM INFORMATION_SCHEMA.tables a
WHERE a.TABLE_TYPE = 'BASE TABLE';
DECLARE command_builder CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT
Command
FROM #commands
OPEN command_builder
FETCH NEXT FROM command_builder INTO @command
WHILE @@fetch_status = 0
BEGIN
PRINT @command
FETCH NEXT FROM command_builder INTO @command
END
CLOSE command_builder
DEALLOCATE command_builder
DROP TABLE #commands
GO
As you can see above, the only difference from the previous code is the LOCAL STATIC FORWARD_ONLY READ_ONLY arguments.
The third will have a LOCAL FAST_FORWARD. Now, according to Microsoft, FAST_FORWARD is a FORWARD_ONLY, READ_ONLY CURSOR with optimizations enabled. We’ll see how this will fare with the first two.
How do they compare? See Figure 2:
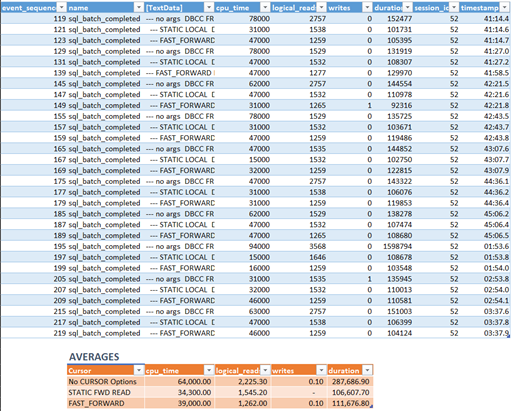
The one that takes less CPU time and duration is the LOCAL STATIC FORWARD_ONLY READ_ONLY CURSOR. Note also that SQL Server has defaults if you don’t specify arguments like STATIC or READ_ONLY. There’s a terrible consequence to that as you will see in the next section.
What sp_describe_cursor Revealed
sp_describe_cursor is a stored procedure from the master database that you can use to get information from the open CURSOR. And here’s what it revealed from the first batch of queries with no CURSOR options. See Figure 3 for the result of sp_describe_cursor:

Overkill much? You bet. The CURSOR from the first batch of queries is:
- global to the existing connection.
- dynamic, which means it tracks changes in the #commands table for updates, deletes, and inserts.
- optimistic, which means that SQL Server added an extra column to a temporary table called CWT. This is a checksum column for tracking changes in the values of the #commands table.
- scrollable, meaning you can traverse to the previous, next, top, or bottom row in the cursor.
Absurd? I strongly agree. Why do you need a global connection? Why do you need to track changes to the #commands temporary table? Did we scroll anywhere other than the next record in the CURSOR?
As an SQL Server determines this for us, the CURSOR loop becomes a terrible mistake.
Now you realize why explicitly specifying SQL CURSOR options is so crucial. So, from now on, always specify these CURSOR arguments if you need to use a CURSOR.
The Execution Plan Reveals More
The Actual Execution Plan has something more to say on what happens every time a FETCH NEXT FROM command_builder INTO @command is executed. In Figure 4, a row is inserted in the Clustered Index CWT_PrimaryKey in the tempdb table CWT:
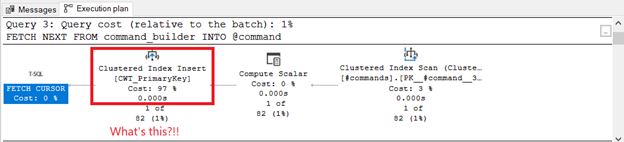
Writes happen to tempdb on every FETCH NEXT. Besides, there’s more. Remember that the CURSOR is OPTIMISTIC in Figure 3? The properties of the Clustered Index Scan on the rightmost part of the plan reveal the extra unknown column called Chk1002:
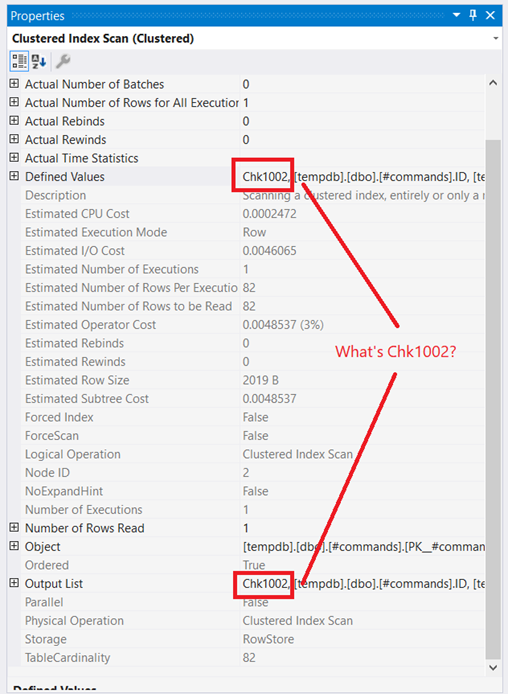
Could this be the Checksum column? The Plan XML confirms that this is the case indeed:
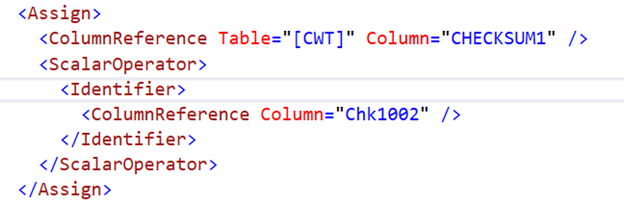
Now, compare the Actual Execution Plan of the FETCH NEXT when the CURSOR is LOCAL STATIC FORWARD_ONLY READ_ONLY:
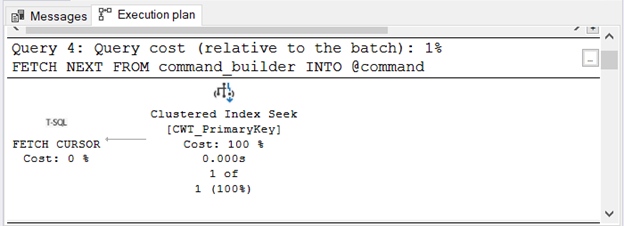
It uses tempdb too, but it’s much simpler. Meanwhile, Figure 8 shows the Execution Plan when LOCAL FAST_FORWARD is used:
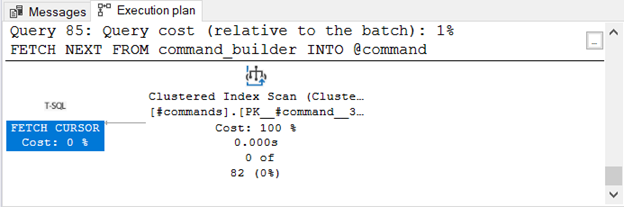
Takeaways
One of the appropriate uses of SQL CURSOR is generating scripts or running some administrative commands towards a group of database objects. Even if there are minor uses of it, your first option is to use the LOCAL STATIC FORWARD_ONLY READ_ONLY CURSOR or LOCAL FAST_FORWARD. The one with a better plan and logical reads will win.
Then, replace any of these with the appropriate one as the need dictates. But you know what? In my personal experience, I only used a local read-only CURSOR with forward-only traversal. I never needed to make the CURSOR global and updateable.
Aside from using these arguments, the timing of the execution matters.
3. Using SQL CURSOR on Daily Transactions
I’m not an administrator. But I have an idea of what a busy server looks like from the DBA’s tools (or from how many decibels users scream). Under these circumstances, will you want to add further burden?
If you are trying to craft your code with a CURSOR for day-to-day transactions, think again. CURSORs are fine for one-time runs on a less busy server with small datasets. However, on a typical busy day, a CURSOR can:
- Lock rows, especially if the SCROLL_LOCKS concurrency argument is explicitly specified.
- Cause high-CPU usage.
- Use tempdb extensively.
Imagine you have several of these running concurrently on a typical day.
We’re about to end but there’s one more mistake we need to talk about.
4. Not Assessing the Impact SQL CURSOR Brings
You know that CURSOR options are good. Do you think specifying them is enough? You’ve already seen the results above. Without the tools, we would not come up with the right conclusion.
Furthermore, there’s code inside the CURSOR. Depending on what it does, it adds more to the resources consumed. These may have been available for other processes. Your entire infrastructure, your hardware, and SQL Server configuration will add more to the story.
How about the volume of data? I only used SQL CURSOR on a few hundred records. It can be different for you. The first example only took 500 records because that was the number that I would agree to wait for. 10,000 or even 1000 didn’t cut it. They performed badly.
Eventually, no matter how less or more, checking the logical reads, for example, can make a difference.
What if you don’t check the Execution Plan, the logical reads, or the elapsed time? What terrible things can happen other than SQL Server freezes? We can only imagine all sorts of doomsday scenarios. You get the point.
Conclusion
SQL CURSOR works by processing data row by row. It has its place, but it can be bad if you’re not careful. It’s like a tool that seldom comes out of the toolbox.
So, first thing, try solving the problem by using set-based commands. It answers most of our SQL needs. And if ever you use SQL CURSOR, use it with the right options. Estimate the impact with the Execution plan, STATISTICS IO, and xEvent Profiler. Then, pick the right time to execute.
All this will make your use of SQL CURSOR a bit better.
Tags: sql cursor, sql functions, sql server Last modified: September 17, 2021





