An Oracle developer who often uses regular expressions in code sooner or later can face a phenomenon that is indeed mystical. Long-term searches for the root of the problem can lead to weight loss, appetite and provoke various kinds of psychosomatic disorders – all this can be prevented with the help of the regexp_replace function. It can have up to 6 arguments:
REGEXP_REPLACE (
- source_string,
- template,
- substituting_string,
- the start position of the match search with a template (default 1),
- a position of occurrence of the template in a source string (by default 0 equals all occurrences),
- modifier (so far it is a dark horse)
)
Returns the modified source_string in which all occurrences of the template are replaced by the value passed in the substituting_string parameter. Often a short version of the function is used, where the first 3 arguments are specified, which is enough to solve many problems. I will do the same. Suppose we need to mask all the string characters with asterisks in the ‘MASK: lower case’ string. To specify the range of lowercase characters, the ‘[a-z]‘ pattern should suit.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
Expectation
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Reality
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
If this event has not been reproduced in your database, then you are lucky so far. But more often you start digging in code, convert strings from one set of characters to another and eventually, a despair comes.
Defining a problem
The question arises – what is so special about letter ‘A’ that it has not been replaced because the rest of the uppercase characters were not supposed to be replaced as well. Maybe there are other correct letters except for this one. It is necessary to look at the entire alphabet of uppercase characters.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+
However
If the 6th argument of the function is not explicitly specified, for example, ‘i’ is case-insensitivity or ‘c’ is case-sensitivity when comparing a source string to a template, the regular expression uses the NLS_SORT parameter of the session/database by default. For example:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
This parameter specifies the sorting method in ORDER BY. If we talk about sorting simple individual characters, then a certain binary number (NLSSORT-code) corresponds to each of them and the sorting actually takes place by the value of these numbers.
To illustrate this, let’s take the first and last few characters of the alphabet, both lowercase, and uppercase, and put them in a conditionally unordered table set and call it ABC. Then, let’s sort this set by the SYMBOL field and display its NLSSORT-code in the HEX format next to each symbol.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
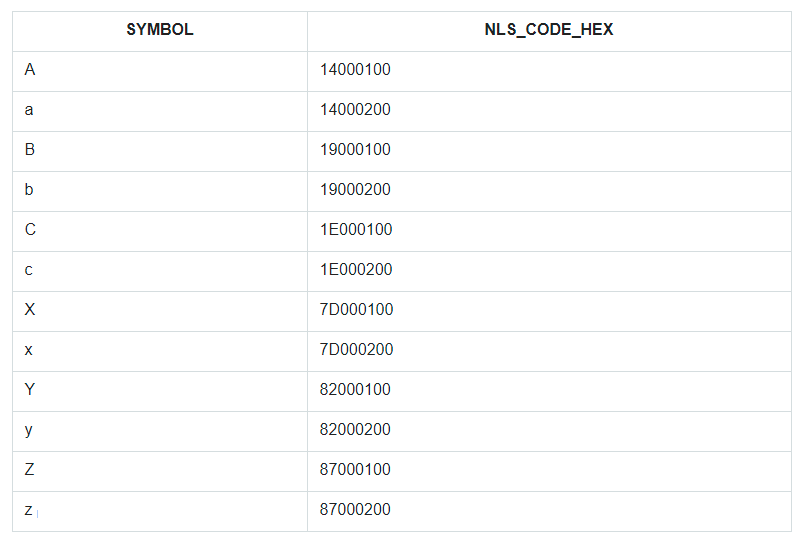
In the query, ORDER BY is specified for the SYMBOL field, but in fact, in the database, the sorting went by the values from the field NLS_CODE_HEX.
Now, go back to the range from the template and look at the table – what is vertical between the symbol ‘a’ (code 14000200) and ‘z’ (code 87000200)? Everything except the capital letter ‘A’. That’s all that has been replaced with an asterisk. And the code 14000100 of the letter ‘A’ is not included in the replacement range from 14000200 to 87000200.
Cure
Explicitly specify the case-sensitivity modifier
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Some sources say that modifier ‘c’ is set by default, but we have just seen that this is not quite true. And if someone did not see it, then the NLS_SORT parameter of its session/database is most likely set to BINARY and the sorting is performed in correspondence with real codes of characters. Indeed, if you change the session parameter, the problem will be solved.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Tests were carried out in Oracle 12c.
Feel free to leave your comments and take care.
Tags: oracle, sql Last modified: September 23, 2021





