Introduction
Developers are often told to use stored procedures in order to avoid the so-called ad hoc queries which can result in unnecessary bloating of the plan cache. You see, when recurrent SQL code is written inconsistently or when there’s code that generates dynamic SQL on the fly, SQL Server has a tendency to create an execution plan for each individual execution. This may decrease overall performance by:
-
Demanding a compilation phase for every code execution.
-
Bloating the Plan Cache with too many plan handles that may not be reused.
Optimize for Ad Hoc Workloads
One way this problem was handled in the past is Optimizing the instance for Ad Hoc Workloads. Doing this can only be helpful if most databases or most significant databases on the instance are predominantly executing Ad Hoc SQL.
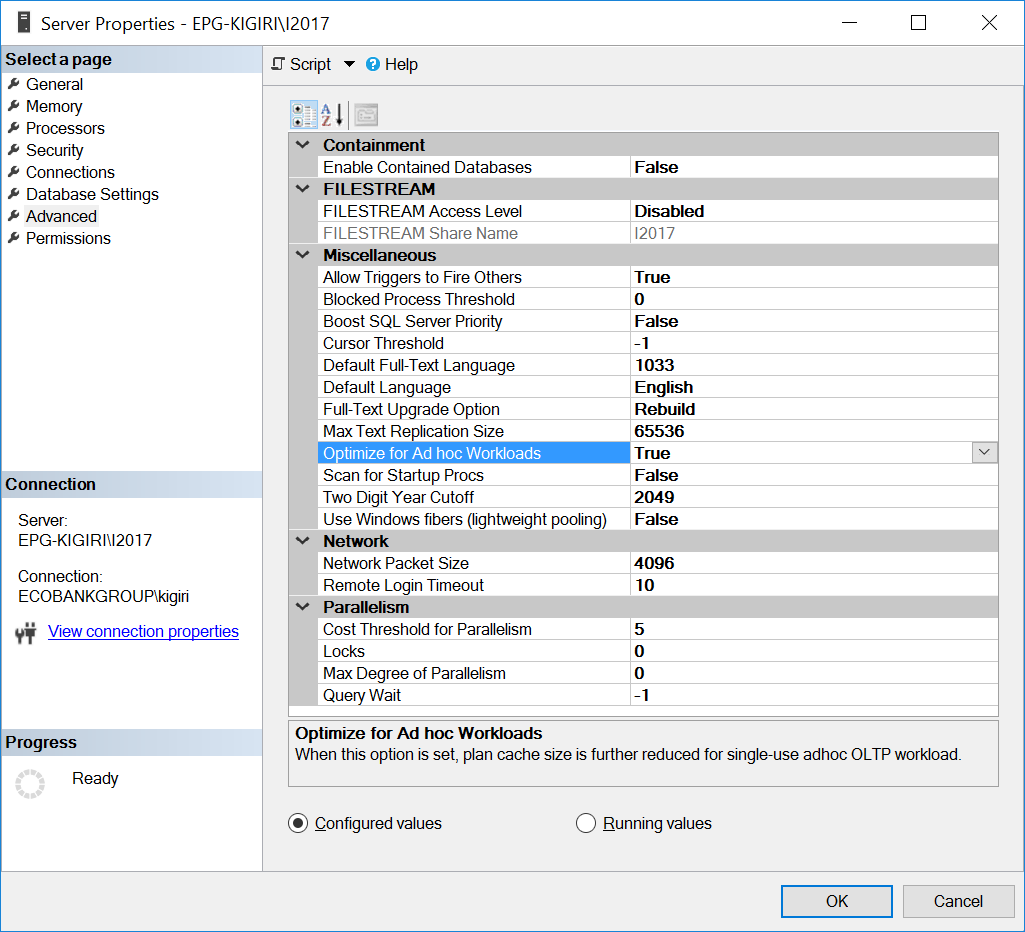
Fig. 1 Optimize for Ad Hoc Workloads
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
Essentially, this option tells SQL Server to save a partial version of the plan known as the compiled plan stub. The stub occupies much less space than the entire plan.
As an alternative to this method, some people approach the issue rather brutally and flush the plan cache every now and then. Or, in a more careful way, flush “single-use plans” by using DBCC FREESYSTEMCACHE. Flushing the entire plan cache has its downsides, as you may already know.
Using Stored Procedures and Parameters
By using stored procedures, one can virtually eliminate the problem caused by Ad Hoc SQL. A stored procedure is compiled only once and the same plan is reused for subsequent executions of the same or similar SQL queries. When stored procedures are used to implement business logic, the key difference in the SQL queries that will be eventially executed by SQL Server lies in the parameters passed at execution time. Since the plan is already in place and ready for use, SQL Server will use the same plan no matter what parameter is passed.
Skewed Data
In certain scenarios, the data we are dealing with is not distributed evenly. We can demonstrate this – first, we will need to create a table:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode);
Our table contains data of club members from different countries. A large number of club members are from Ghana, while two other nations have ten and two members respectively. To keep focused on the agenda and for simplicity’s sake, I only used three countries and the same name for members coming from the same country country. Also, I added a clustered index in the ID column and a non-clustered index in the CountryCode column to demonstrate the effect of different execution plans for different values.
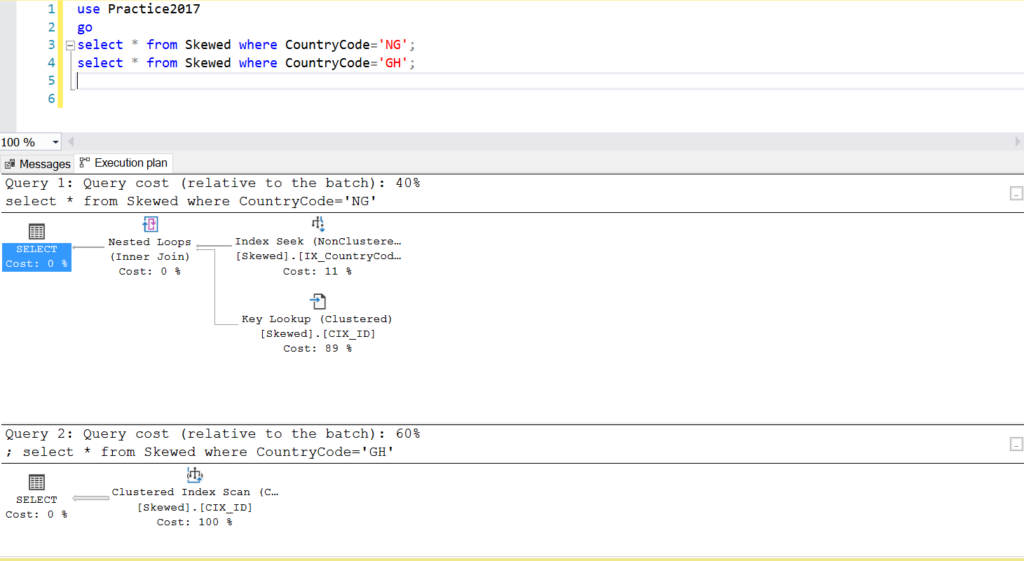
Fig. 2 Execution plans for two queries
When we query the table for records where CountryCode is NG and GH, we find that SQL Server uses two different execution plans in these cases. This happens because the expected number of rows for CountryCode=’NG’ is 10, while that for CountryCode=’GH’ is 10000. SQL Server determines the preferable execution plan based on table statistics. If the expected number of rows is high compared with the total number of rows in the table, SQL Server decides that it is better to simply do a full table scan rather than referring to an index. With a much smaller estimated number of rows, the index becomes useful.
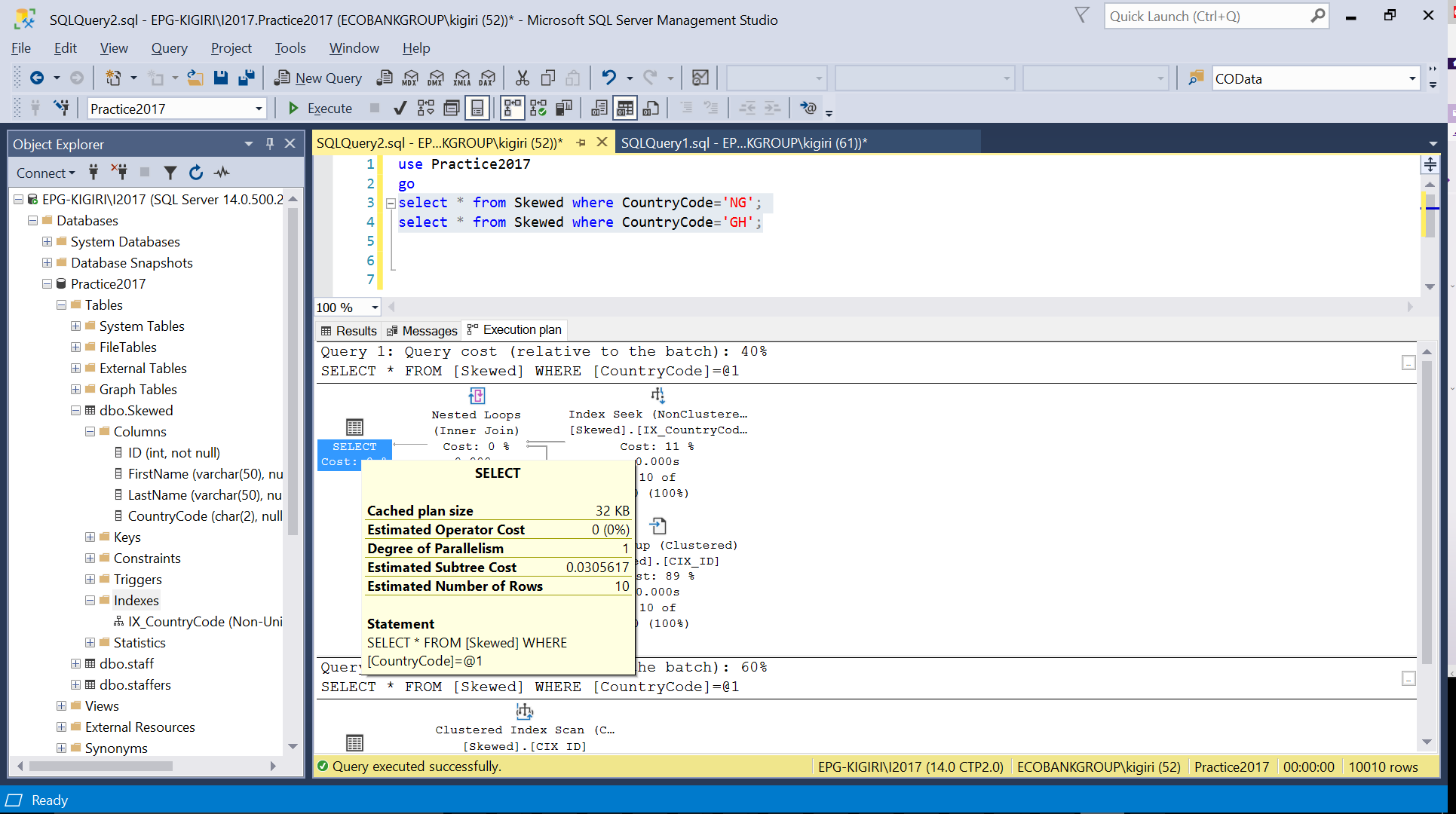
Fig. 3 Estimated number of rows for CountryCode=’NG’
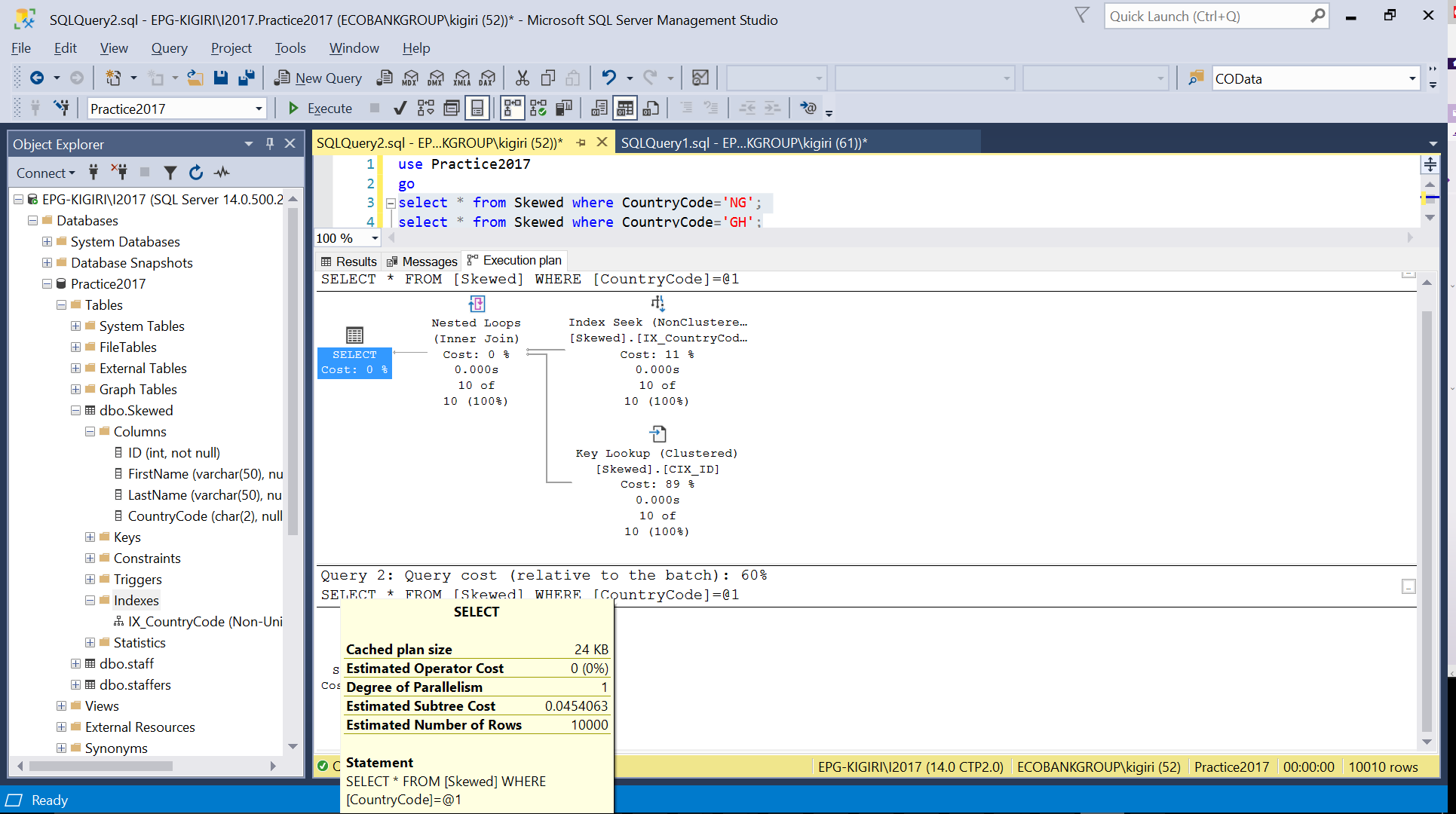
Fig. 4 Estimated number of Rows for CountryCode=’GH’
Enter Stored Procedures
We can create a stored procedure to fetch the records we want by using the very same query. The only difference this time is that we pass CountryCode as a parameter (see Listing 3). When doing this, we discover that the execution plan is the same no matter what parameter we pass. The Execution plan that will be used is determined by the execution plan returned at the first time the stored procedure is invoked. For example, If we run the procedure with CountryCode=’GH’ first, it will use a full table scan from that point on. If we then clear the procedure cache and run the procedure with CountryCode=’NG’ first, it will use index-based scans in future.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where CountryCode=@countrycode end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
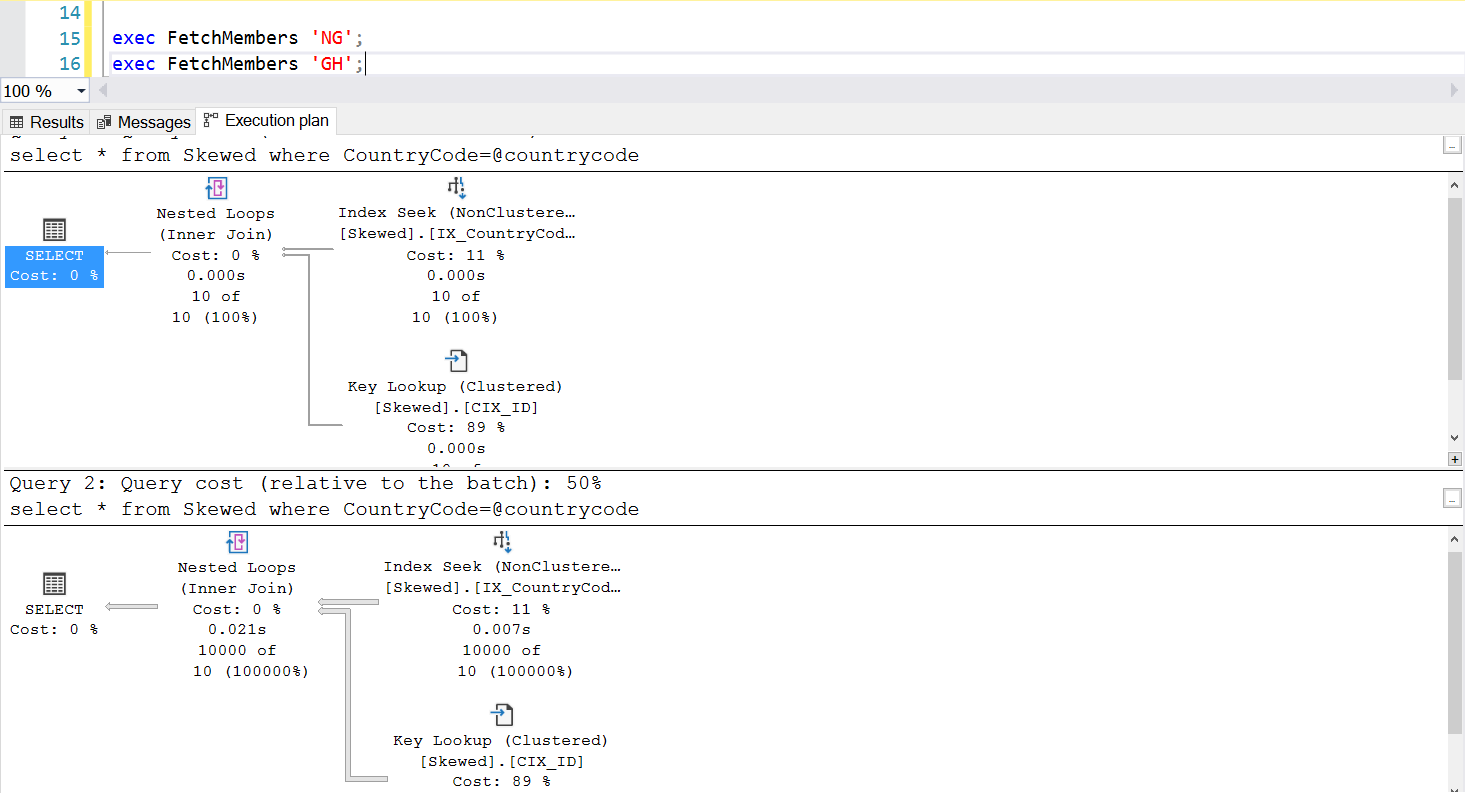
Fig. 5 Index seek execution plan when ‘NG’ is used first
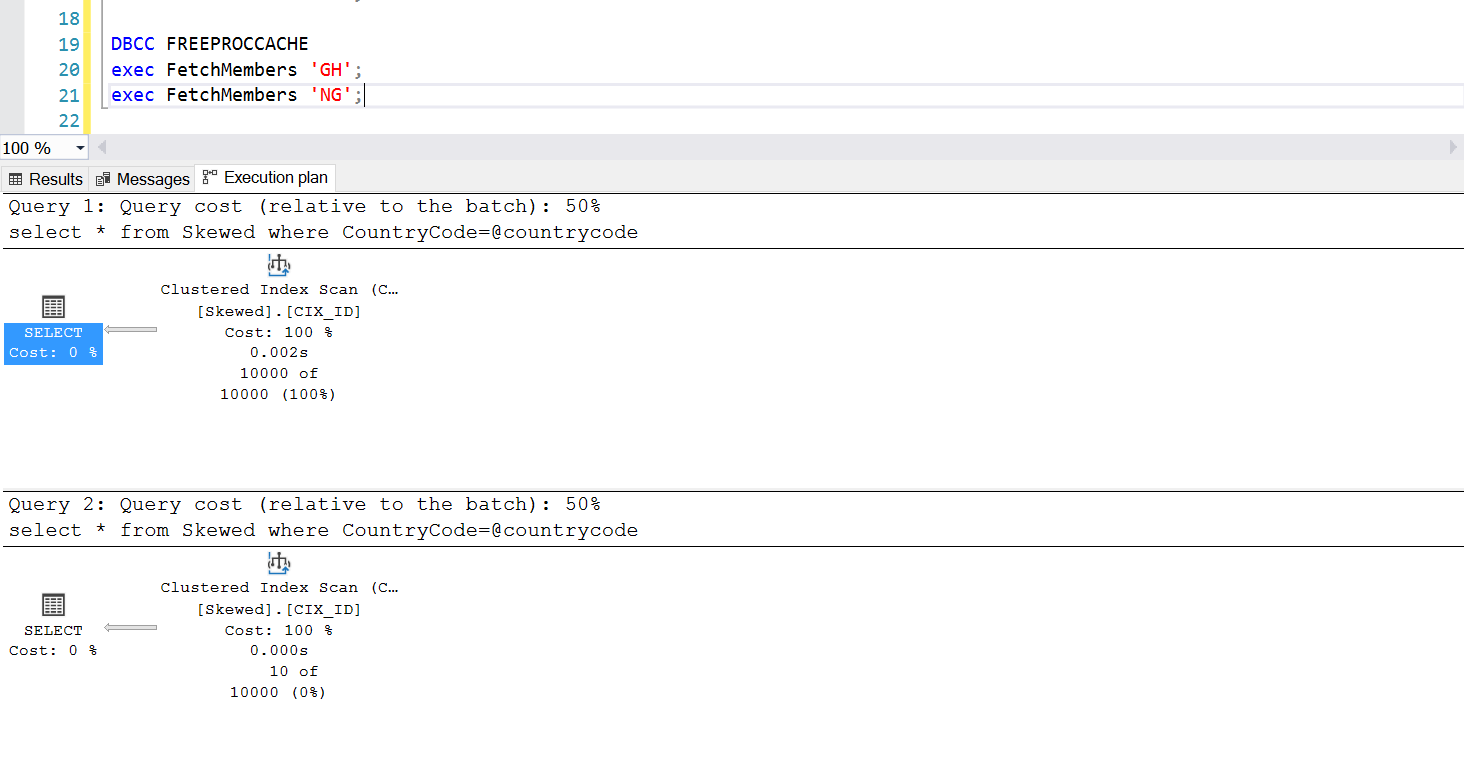
Fig. 6 Clustered index scan execution plan when ‘GH’ is used first
Execution of the stored procedure is behaving as designed – the required execution plan is used consistently. However, this can be an issue because one execution plan is not suited for all queries if the data is skewed. Using an index to retrieve a collection of rows almost as large as the entire table is not efficient – neither is using a full scan to retrieve only a small number of rows. This is the Parameter Sniffing problem.
Possible Solutions
One common way to manage the Parameter Sniffing problem is to deliberately invoke recompilation whenever the stored procedure is executed. This is much better than flushing the Plan Cache – except if you want to flush the cache of this specific SQL query, which is entirely possible. Take a look at an updated version of the stored procedure. This time, it uses OPTION (RECOMPILE) to manage the problem. Fig.6 shows us that, whenever the new stored procedure is executed, it uses a plan appropriate to the parameter we are passing.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where CountryCode=@countrycode OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
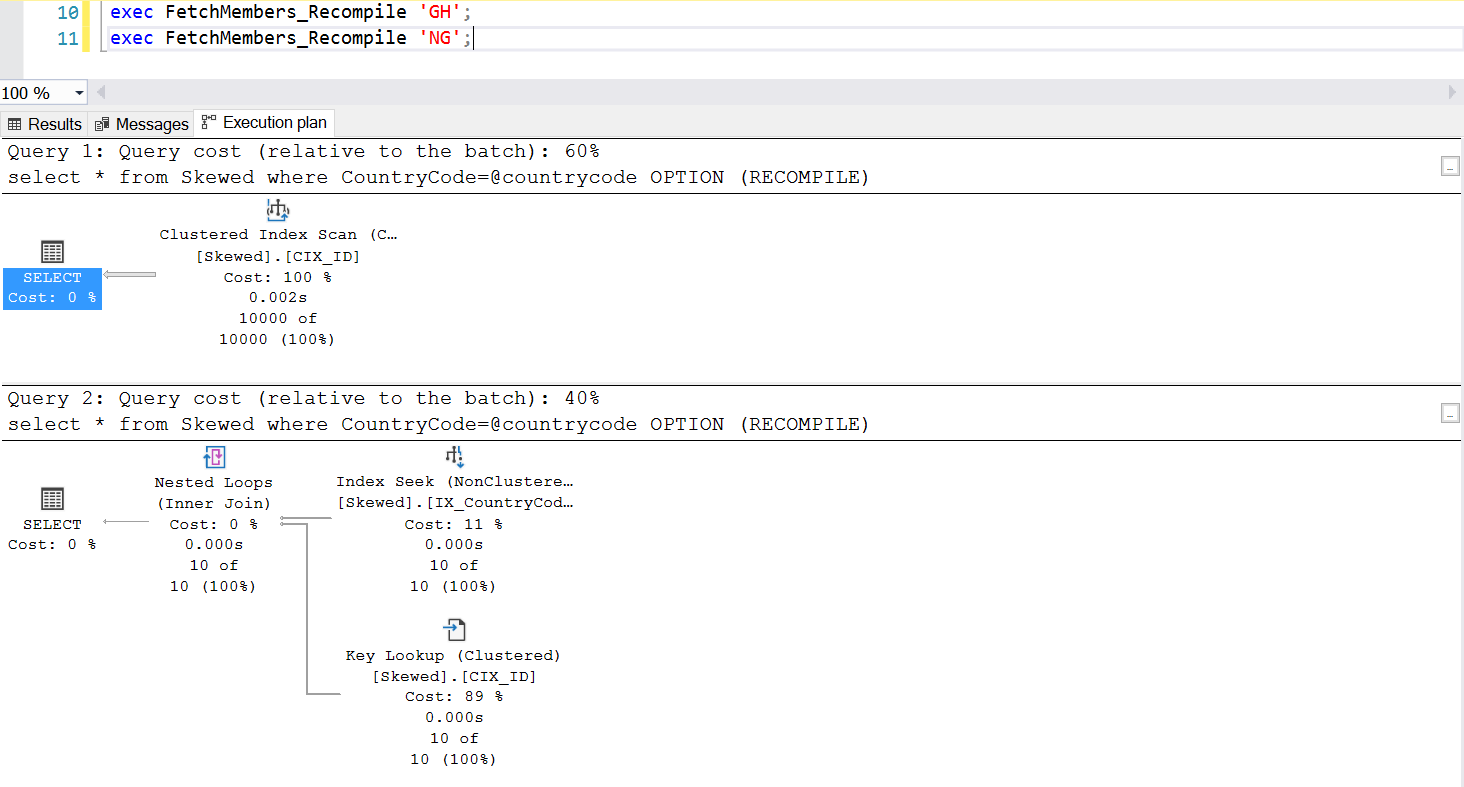
Fig. 7 Behaviour of the stored procedure with OPTION (RECOMPILE)
Conclusion
In this article, we have looked at how consistent execution plans for stored procedures can become a problem when the data we are dealing with is skewed. We have also demonstrated this in practice and learned about a common solution to the problem. I dare say this knowledge is invaluable to developers who use SQL Server. There are a number of other solutions to this problem – Brent Ozar went deeper into the subject and highlighted some more profound details and solutions at SQLDay Poland 2017. I have listed the corresponding link in the reference section.
References
Plan Cache and Optimizing for Adhoc Workloads
Identifying and Fixing Parameter Sniffing Issues
Tags: execution plan, query performance, sql Last modified: September 21, 2021





