Do you think about something when you create a new database? I guess that most of you would say no, since we all use default parameters, though they are far from being optimal. However, there is a bunch of disc settings, and they really help to increase system reliability and performance.
We won’t speak of the importance of the NTFS file system for data reliability, though this file system allows MS SQL Server to use the disk in the most effective way.
If you are short of resources and something starts working slow, the first thing that comes to mind is upgrading. But upgrading is not required in every case. You can get away with tuning, though it should be done not when the server starts running slow, but at the stage of design and installation.
Optimization is a complex process and is often related not only to a certain program (in our case, to a certain database) but also to OS and hardware. Though we will mostly speak about databases, we cannot ignore the outward things.
Data Architecture
SQL Server stores, reads and writes data by blocks 8 KB each. These blocks are called pages. A database can store 128 pages per megabyte (1 megabyte or 1048576 bytes divided by 8 kilobytes or 8192 bytes). All pages are stored in an extent. An extent is last 8 sequential pages or 64 KB. Thus, 1 megabyte stores 16 extents.
Pages and extents are the basis of the SQL Server physical database structure. MS SQL Server uses various page types, some of them track allocated space, some contain user data and indexes. Pages that track the allocated space contain the densely compressed data. It allows MS SQL Server to effectively store them in memory for easy reading.
SQL Server uses two kinds of extents:
- Extents that store pages from two to many objects are called mixed extents. Each table begins as a mixed extent. You use mixed extent mainly for the pages that store space and contain small objects.
- Extents that have all 8 pages allocated to one object are called uniform extents. They are used when a table or index requires more than 64 KB.
The first extent for each file is a uniform one and contains pages of the file header, the next extents contain 3 allocated pages each. The server allocates these mixed extents when you create a basic data file and uses these pages for its internal tasks. The file header page contains file attributes, such as the name of the database stored in the file, filegroup, minimum size, increment size. This is the first page of each file (page 0).

Query Execution Plan in SQL Query Analyzer
Page Free Space (PFS) in an allocated page that contains information about free space available in the file. This information is stored on page 1. Each such page can extend to 8000 contiguous pages, which is approximately 64 Mb of data.
The transaction log collects all the information about the changes taking place on the server to restore a database at the moment of system error and to ensure data integrity.
Note that all numbers are multiples of 8 or 16. This is because the hard disc controller reads data of this size more easily. The Data is read from the disk by pages, i.e. by 8 kilobytes, which is quite an optimal value.
Page Protection
As from MS SQL Server 2005, the database server features a new option – the page-level data control. If the AGE_VERIFY_CHECKSUM parameter is enabled (it is enabled by default), the server will control the checksums of pages. If we look into the manual for this parameter, we will see that the checksum allows tracking the input/output errors that OS is unable to track. What kind of errors are they? It seems they are the internal issues of the database server.
The data integrity check never goes amiss, so it is better to enable it. For this, we need to execute the following command:
ALTER DATABASE имя базы SET PAGE_VERIFY
If there is an error on the page, the server will notify us about it. But how can we fix it quickly? There is an option to restore data on the page level for this.
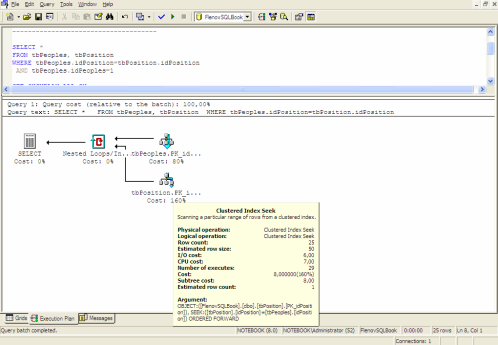
Graphical Execution Plan
File Growth
When we create a database, we are prompted to select the initial size and the increment method. When we are short of the current space, the server extends it in correspondence with the preset increment method.
There are three increment methods for files:
- Growth in megabytes.
- Growth by percent.
- Manual growth.
The first two methods are performed automatically, but they are recommended only for test databases since an administrator does not have a control over the file size.
If a file is incremented by a certain amount of megabytes, at some point, the speed of data insertion may increase and the file growth may become too frequent, and this is extra costs. File growth in percents is unprofitable as well. It is recommended to use a 10% file growth and this is OK for small and medium databases. But when it reaches 1000 gigabytes, it will require 100 gigabytes at each growth. It will lead to meaningless waste of disk space.
Always control changes in the size of files and transaction logs. It will allow you to use the disc resources in the most effective way.
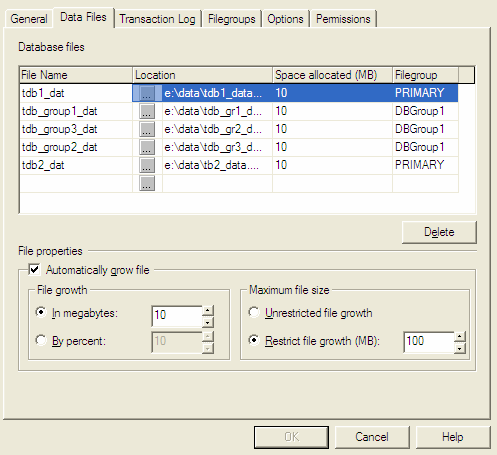
MS SQL Server Database Properties
Data Compression
Hard drive remains a sensible spot of a computer. The performance of processors grows headily, while hard disks cannot offer something new. To save the number of input/output operations and reduce the data stored on the hard disk, you can use disks with compression. Only such discs are good for storing read-only file groups. Perhaps, it is because compression is required for writings, and it requires additional processor costs.
Data compression and read-only state are good for the archival data. For example, accounting data for the past years is not required for writing and can take too much space. By placing data on the archival section of the disk, you will greatly save space.
Disks for Reliability
The following method allows increasing reliability and performance at the same time, and again, it is related to hard drives. Well, there it is, mechanics is not only the slowest but the most unreliable. As for reliability, I did not collect the statistics, but both, at home and at work, I deal mostly with hard drives.
So, to increase performance and reliability, you can simply use two or more hard drives instead of one. It will be even better if they will be connected to separate controllers. You can store the database on one disk, and transaction logs on another. If there is a third disk, it can store the system.
Storing data and a log on separate disks allows you to greatly increase the reliability. Suppose you have everything on one disk and it goes down. What to do? You can reach a company that will try to recover everything or try to do the same on your own, but the chance of recovery is far from 100%. Besides, returning server back to work may take a considerable volume of time. Fast recovery can be done only to the moment of the last backup copy. The rest is questionable.
And now, suppose you have data and a transaction log on different disks. If the disk with the log goes off, data will be still there. The only thing is that you cannot add new data, but if you create a new log, you can continue working.
If the disk with data goes off, we still can reserve the transaction log to prevent the smallest data loss. After that, we recover the data from the complete backup (it should always be done beforehand, a good administrator does this least once a day) and add changes from the backup copy of the log.
Disks for Performance
If data and a log are located on separate disks, it means not only safety but also performance growth. The thing is that the database server can simultaneously write data into the log and data file.
We can go further and allocate one hard drive to the transaction log and several hard drives to data. The server works with data more often, that is why it requires several storages with which you can work at the same time. And if these storages are connected to different controllers, the simultaneous work is guaranteed.
The fastest and most reliable variant is to use RAID. However, not every RAID is reliable and fast at the same time. For the file groups, it is recommended to choose RAID10, since it contains well-balanced features, but depending on the database data, you can choose another variant.
You can use a software or hardware solution as RAID. A software solution is cheaper, but it takes extra resources of CPU. And a processor does not have spare resources. That is why it is better to use hardware solutions where a dedicated chip is responsible for RAID.
Indexes
Everyone knows that indexes help to increase the data search speed. Most of us understand that indexes negatively affect data insert and update, so the more indexes you have, the harder it is for the server to maintain them. At that, not many even think that indexes require maintenance. Database pages containing index data may overflow and eventually become unbalanced.
Yes, we can ignore various parameters and simply recreate indexes once in a month, which that is similar to maintenance. SQL Server includes two parameters that prevent indexes from outdating in a half an hour after their creation: FILLFACTOR and PAD_INDEX.
You can use the FILLFACTOR option to optimize the performance of the insert and update operations that contain a clustered or non-clustered index. Index data can be stored in many data pages. As I mentioned above, each page consists of 8 KB. When an index page is full, the server creates a new page and divides the page for the data insert into two.
The server requires time for the page division and creation of a new page. To optimize the page division, use the FILLFACTOR option to determine the percent of free space on all leaves of the index page. The larger disk space the leaf-level pages have, the less frequent you will have to divide index pages. At that, the index tree will be too large and its bypassing will take extra time.
The PAD_INDEX option indicates the filling percentage of the non-leaf pages. You can use PAD_INDEX only when the FILLFACTOR option is specified since the percentage value of PAD_INDEX depends on the percentage specified in FILLFACTOR.
Statistics
Statistics allow the server to make the right decision between index usage and full table scanning. Suppose you have a list of employees of a foundry shop. Such list will be made of approximately 90% of men.
Now, suppose we need to find all the women. Since there are not many of them, the most effective option will be to use the index. But if we need to find all the men, the index efficiency slows down. The number of selected records is too big and bypassing the index tree for each of them will be an overhead. It is much simpler easier to scan all the entire table – the execution will be much faster since the server will need to read all low-level leaves of the index once without the need of multiple reads of all levels.
SQL Server collects statistics by reading all field values or with a template for creation of the uniformly distributed and sorted value list. SQL Server dynamically detects the percent of rows that must be tested on the basis of the number of rows in the table. When collecting statistics, the query optimizer will execute either a full scan or row templates.
To make statistics work, it must be created. In case of massive data update, the statistics may contain incorrect data, and the server will make a wrong decision. But everything can be put right, – you need to monitor statistics. For more detailed information, refer to the books on Transact-SQL or MS SQL Server.
Summary
The default settings do not allow using all the potential of hardware and work with all the variety of servers. The responsibility for the settings rests with administrators. The fact that the Microsoft products have simple installation programs, graphical administration utilities and ability to work offline does not mean that this is an optimal variant.
We do not consider such database tuning options as hardware acceleration. If all tuning options are depleted, it is better to think about the upgrade, since hardware acceleration negatively affects the system reliability. Highly recommend reading this insightful post for a comprehensive understanding of how to get server storage information using stored procedures in SQL Server.
The most important thing is that any database server optimization or any upgrade will not help if queries are not optimized.
Tags: database administration, sql server Last modified: October 23, 2024




