In my previous article, we started to describe the basics of the EXPLAIN command and analyzed what happens in PostgreSQL when executing a query.
I am going to continue writing about the basics of EXPLAIN in PostgreSQL. The information is a short review of Understanding EXPLAIN by Guillaume Lelarge. I highly recommend reading the original since some information is missed out.
Cache
What happens at the physical level when executing our query? Let’s figure it out. I deployed my server on Ubuntu 13.10 and used disk caches of the OS level.
I stop PostgreSQL, commit changes to the file system, clear cache, and run PostgreSQL:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
When the cache is cleared, run the query with the BUFFERS option
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

We read the table by blocks. The cache is empty. We had to access 8334 blocks to read the whole table from the disk.
Buffers: shared read is the number of blocks PostgreSQL reads from the disk.
Run the previous query
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Buffers: shared hit is the number of blocks retrieved from the PostgreSQL cache.
With each query, PostgreSQL takes more and more data from the cache, thus, filling its own cache.
Cache read operations are faster than disk read operations. You can see this trend by tracking the Total runtime value.
Cache storage size is defined by the shared_buffers constant in the postgresql.conf file.
WHERE
Add the condition to the query
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
There are no indexes on the table. When executing the query, each record of the table is scanned sequentially (Seq Scan)and compared with the c1 > 500 condition. If the condition is met, the record is added to the result. Otherwise, it is discarded. Filter indicates this behavior, as well as the cost value increases.
The estimated number of rows decreases.
The original article explains why cost takes this value, and how the estimated number of rows is calculated.
It is time to create indexes.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

The estimated number of rows has changed. What about the index?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Only 510 rows of more than 1 million are filtered. PostgreSQL had to read more than 99.9 % of the table.
We will force to use the index by disabling Seq Scan:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

In Index Scan and Index Cond, the foo_c1_idx index is used instead of Filter.
When selecting the whole table, using the index will increase the cost and time to execute the query.
Enable Seq Scan:
SET enable_seqscan TO on;
Modify the query:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
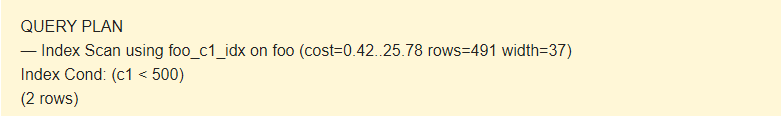
Here the planner uses the index.
Now, let’s complicate the value by adding the text field.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

As you can see, the foo_c1_idx index is used for c1 < 500. To perform c2 ~~ ‘abcd%’::text, use the filter.
It should be noted that the POSIX format of the LIKE operator is used in the output of the results. If there is only the text field in the condition:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Seq Scan is applied.
Build the index by c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

The index is not applied because my database for test fields uses the UTF-8 encoding.
When building the index, it is necessary to specify the class of the text_pattern_ops operator:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Great! It worked!
Bitmap Index Scan uses the foo_c2_idx1 index to determine the records we need. Then, PostgreSQL goes to the table (Bitmap Heap Scan) to make sure that these records actually exist. This behavior refers to the versioning of PostgreSQL.
If you select only the field, on which the index is built, instead of the whole row:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Index Only Scan will be performed faster, than Index Scan due to the fact that it is not necessary to read the row of the table: width=4.
Conclusion
- Seq Scan reads the whole table
- Index Scan uses the index for the WHERE statements and reads the table when selecting rows
- Bitmap Index Scan uses Index Scan and selection control through the table. Effective for a large number of rows.
- Index Only Scan is the fastest block, which reads only the index.
Further reading:
Query Optimization in PostgreSQL. EXPLAIN Basics – Part 3
Tags: execution plan, indexes, postgresql, query performance, sql Last modified: June 27, 2023





