You probably know how to insert records into a table using single or multiple VALUES clauses. You also know how to do bulk inserts using SQL INSERT INTO SELECT. But you still clicked the article. Is it about handling duplicates?

Many articles cover SQL INSERT INTO SELECT. Google or Bing it and pick the headline you like best – it will do. I won’t cover basic examples of how it is done either. Instead, you will see examples of how to use it AND handle duplicates at the same time. So, you can make this familiar message out of your INSERT efforts:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
But first things first.

[sendpulse-form id=”12989″]
Prepare Test Data for SQL INSERT INTO SELECT Code Samples
I kind of thinking about pasta this time. So, I’ll use data about pasta dishes. I found a good list of pasta dishes in Wikipedia that we can use and extracted in Power BI using a web data source. I entered the Wikipedia URL. Then I specified the 2-table data from the page. Cleaned it up a bit and copied data to Excel.
Now we have the data – you can download it from here. It’s raw because we are going to make 2 relational tables out of it. Using INSERT INTO SELECT will help us do this task,
Import the Data in SQL Server
You can either use SQL Server Management Studio or dbForge Studio for SQL Server to import 2 sheets into the Excel file.
Create a blank database before importing the data. I named the tables dbo.ItalianPastaDishes and dbo.NonItalianPastaDishes.
Create 2 More Tables
Let’s define the two output tables with the command SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Note: There are unique indexes created on two tables. It will prevent us from inserting duplicate records later. Restrictions will make this journey a bit harder but exciting.
Now that we’re ready, let’s dive in.
5 Easy Ways to Handle Duplicates Using SQL INSERT INTO SELECT
The easiest way to handle duplicates is to remove unique constraints, right?
Wrong!
With unique constraints gone, it’s easy to make a mistake and insert the data twice or more. We do not want that. And what if we have a user interface with a dropdown list for picking the origin of the pasta dish? Will the duplicates make your users happy?
Therefore, removing the unique constraints is not one of the five ways to handle or delete duplicate records in SQL. We have better options.
1. Using INSERT INTO SELECT DISTINCT
The first option for how to identify SQL records in SQL is to use DISTINCT in your SELECT. To explore the case, we’ll populate the Origin table. But first, let’s use the wrong method:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
This will trigger the following duplicate errors:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
There’s a problem when you try to select duplicate rows in SQL. To start the SQL check for duplicates that existed before, I ran the SELECT part of the INSERT INTO SELECT statement:
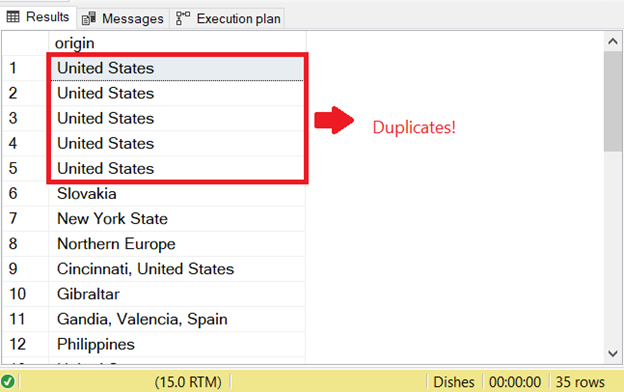
That’s the reason for the first SQL duplicate error. To prevent it, add the DISTINCT keyword to make the result set unique. Here’s the correct code:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
It inserts the records successfully. And we’re done with the Origin table.
Using DISTINCT will make unique records out of the SELECT statement. However, it does not guarantee that duplicates do not exist in the target table. It is good when you’re sure that the target table doesn’t have the values you want to insert.
So, do not run these statements more than once.
2. Using WHERE NOT IN
Next, we populate the PastaDishes table. For that, we need first to insert records from the ItalianPastaDishes table. Here’s the code:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Since ItalianPastaDishes contains raw data, we need to join the Origin text instead of the OriginID. Now, try to run the same code twice. The second time it runs won’t have records inserted. It happens because of the WHERE clause with the NOT IN operator. It filters out records that already exist in the target table.
Next, we need to populate the PastaDishes table from the NonItalianPastaDishes table. Since we are only at the second point of this post, we won’t insert everything.
We picked pasta dishes from the United States and the Philippines. Here goes:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
There are 9 records inserted from this statement – see Figure 2 below:
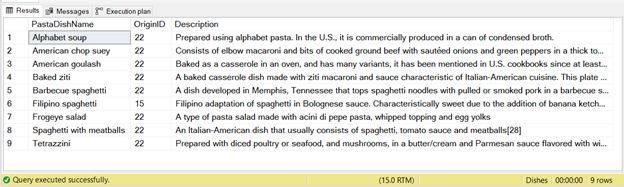
Again, if you run the code above twice, the second run won’t have records inserted.
3. Using WHERE NOT EXISTS
Another way to find duplicates in SQL is to use NOT EXISTS in the WHERE clause. Let’s try it with the same conditions from the previous section:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
The code above will insert the same 9 records you saw in Figure 2. It will avoid inserting the same records more than once.
4. Using IF NOT EXISTS
Sometimes you might need to deploy a table to the database and it is necessary to check if a table with the same name already exists to avoid duplicates. In this case, the SQL DROP TABLE IF EXISTS command can be of great help. Another way to ensure you won’t insert duplicates is using IF NOT EXISTS. Again, we will use the same conditions from the previous section:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
The above code will first check for the existence of 9 records. If it returns true, INSERT will proceed.
5. Using COUNT(*) = 0
Finally, the use of COUNT(*) in the WHERE clause can also ensure you won’t insert duplicates. Here’s an example:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
To avoid duplicates, the COUNT or records returned by the subquery above should be zero.
Note: You can design any query visually in a diagram using the Query Builder feature of dbForge Studio for SQL Server.
Comparing Different Ways to Handle Duplicates with SQL INSERT INTO SELECT
4 sections used the same output but different approaches to insert bulk records with a SELECT statement. You may wonder if the difference is just on the surface. We can check their logical reads from STATISTICS IO to see how different they are.
Using WHERE NOT IN:
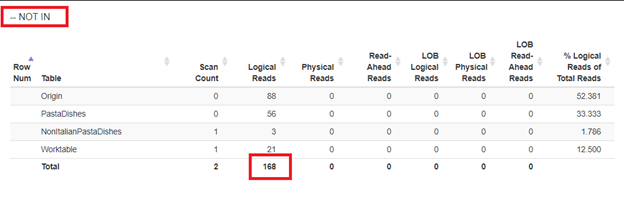
Using NOT EXISTS:
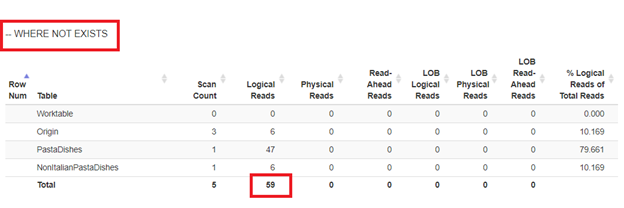
Using IF NOT EXISTS:
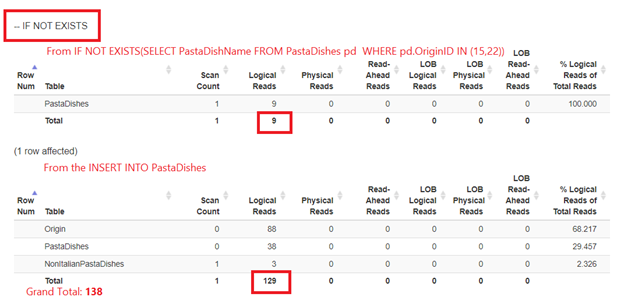
Figure 5 is a bit different. 2 logical reads appear for the PastaDishes table. The first one is from IF NOT EXISTS(SELECT PastaDishName from PastaDishes WHERE OriginID IN (15,22)). The second one is from the INSERT statement.
Finally, using COUNT(*) = 0
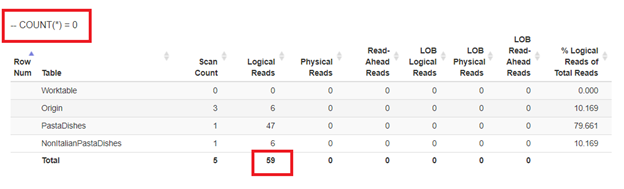
From the logical reads of 4 approaches we had, the best choice is WHERE NOT EXISTS or COUNT(*) = 0. When we inspect their Execution plans, we see they have the same QueryHashPlan. Thus, they have similar plans. Meanwhile, the least efficient one is using NOT IN.
Does it mean that WHERE NOT EXISTS is always better than NOT IN? Not at all.
Always inspect the logical reads and the Execution Plan of your queries!
But before we conclude, we need to finish the task at hand. Then we’ll insert the rest of the records and inspect the results.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
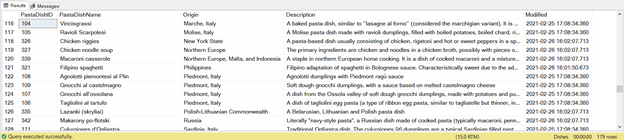
Browsing from the list of 179 pasta dishes from Asia to Europe makes me hungry. Check out a part of the list from Italy, Russia, and more from below:
Conclusion
Avoiding duplicates in SQL INSERT INTO SELECT is not so hard after all. You have operators and functions at hand to take you to that level. It is also a good habit to check the Execution Plan and logical reads to compare which is better.
If you think someone else will benefit from this post, please share it on your favorite social media platforms. And if you have something to add that we forgot, let us know in the Comments section below.