Do you use SQL subqueries or avoid using them?
Let’s say the chief credit and collections officer asks you to list down the names of people, their unpaid balances per month, and the current running balance and wants you to import this data array into Excel. The purpose is to analyze the data and come up with an offer making payments lighter to mitigate the effects of the COVID19 pandemic.
Do you opt to use a query and a nested subquery or a join? What decision will you make?
SQL Subqueries – What Are They?
Before we do a deep dive into syntax, performance impact, and caveats, why not define a subquery first?
In the simplest terms, a subquery is a query within a query. While a query that embodies a subquery is the outer query, we refer to a subquery as the inner query or inner select. And parentheses enclose a subquery similar to the structure below:
SELECT
col1
,col2
,(subquery) as col3
FROM table1
[JOIN table2 ON table1.col1 = table2.col2]
WHERE col1 <operator> (subquery)We are going to look upon the following points in this post:
- SQL subquery syntax depending on different subquery types and operators.
- When and in what sort of statements one can use a subquery.
- Performance implications vs. JOINs.
- Common caveats when using SQL subqueries.
As is customary, we provide examples and illustrations to enhance understanding. But bear in mind that the main focus of this post is on subqueries in SQL Server.
Now, let’s get started.
Make SQL Subqueries That Are Self-Contained or Correlated
For one thing, subqueries are categorized based on their dependency on the outer query.
Let me describe what a self-contained subquery is.
Self-contained subqueries (or sometimes referred to as non-correlated or simple subqueries) are independent of the tables in the outer query. Let me illustrate this:
-- Get sales orders of customers from Southwest United States
-- (TerritoryID = 4)
USE [AdventureWorks]
GO
SELECT CustomerID, SalesOrderID
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (SELECT [CustomerID]
FROM [AdventureWorks].[Sales].[Customer]
WHERE TerritoryID = 4)As demonstrated in the above code, the subquery (enclosed in parentheses below) has no references to any column in the outer query. Additionally, you can highlight the subquery in SQL Server Management Studio and execute it without getting any runtime errors.
Which, in turn, leads to easier debugging of self-contained subqueries.
The next thing to consider is correlated subqueries. Compared to its self-contained counterpart, this one has at least one column being referenced from the outer query. To clarify, I will provide an example:
USE [AdventureWorks]
GO
SELECT DISTINCT a.LastName, a.FirstName, b.BusinessEntityID
FROM Person.Person AS p
JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE 1262000.00 IN
(SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE p.BusinessEntityID = spq.BusinessEntityID)Were you attentive enough to notice the reference to BusinessEntityID from the Person table? Well done!
Once a column from the outer query is referenced in the subquery, it becomes a correlated subquery. One more point to consider: if you highlight a subquery and execute it, an error will occur.
And yes, you are absolutely right: this makes correlated subqueries pretty harder to debug.
To make debugging possible, follow these steps:
- isolate the subquery.
- replace the reference to the outer query with a constant value.
Isolating the subquery for debugging will make it look like this:
SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE spq.BusinessEntityID = <constant value>Now, let’s dig a little deeper into the output of subqueries.
Make SQL Subqueries With 3 Possible Returned Values
Well, first, let’s think of what returned values can we expect from SQL subqueries.
In fact, there are 3 possible outcomes:
- A single value
- Multiple values
- Whole tables
Single Value
Let’s start with single-valued output. This type of subquery can appear anywhere in the outer query where an expression is expected, like the WHERE clause.
-- Output a single value which is the maximum or last TransactionID
USE [AdventureWorks]
GO
SELECT TransactionID, ProductID, TransactionDate, Quantity
FROM Production.TransactionHistory
WHERE TransactionID = (SELECT MAX(t.TransactionID)
FROM Production.TransactionHistory t)When you use a MAX() function, you retrieve a single value. That’s exactly what happened to our subquery above. Using the equal (=) operator tells SQL Server that you expect a single value. Another thing: if the subquery returns multiple values using the equals (=) operator, you get an error, similar to the one below:
Msg 512, Level 16, State 1, Line 20
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.Multiple Values
Next, we examine the multi-valued output. This kind of subquery returns a list of values with a single column. Additionally, operators like IN and NOT IN will expect one or more values.
-- Output multiple values which is a list of customers with lastnames that --- start with 'I'
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.lastname LIKE N'I%' AND p.PersonType='SC')Whole Table Values
And last but not least, why not delve into whole table outputs.
-- Output a table of values based on sales orders
USE [AdventureWorks]
GO
SELECT [ShipYear],
COUNT(DISTINCT [CustomerID]) AS CustomerCount
FROM (SELECT YEAR([ShipDate]) AS [ShipYear], [CustomerID]
FROM Sales.SalesOrderHeader) AS Shipments
GROUP BY [ShipYear]
ORDER BY [ShipYear]Have you noticed the FROM clause?
Instead of using a table, it used a subquery. This is called a derived table or a table subquery.
And now, let me present you some ground rules when using this sort of query:
- All columns in the subquery should have unique names. Much like a physical table, a derived table should have unique column names.
- ORDER BY is not allowed unless TOP is also specified. That’s because the derived table represents a relational table where rows have no defined order.
In this case, a derived table has the benefits of a physical table. That’s why in our example, we can use COUNT() in one of the columns of the derived table.
That’s about all regarding subquery outputs. But before we get any further, you may have noticed that the logic behind the example for multiple values and others as well can also be done using a JOIN.
-- Output multiple values which is a list of customers with lastnames that start with 'I'
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.LastName LIKE N'I%' AND p.PersonType = 'SC'In fact, the output will be the same. But which one performs better?
Before we get into that, let me tell you that I have dedicated a section to this hot topic. We’ll examine it with complete execution plans and have a look at illustrations.
So, bear with me for a moment. Let’s discuss another way to place your subqueries.
Other Statements Where You Can Use SQL Subqueries
So far, we’ve been using SQL subqueries on SELECT statements. And the thing is, you can enjoy the benefits of subqueries on INSERT, UPDATE, and DELETE statements or in any T-SQL statement that forms an expression.
So, let’s take a look at a series of some more examples.
Using SQL Subqueries in UPDATE Statements
It’s simple enough to include subqueries in UPDATE statements. Why not check this example out?
-- In the products inventory, transfer all products of Vendor 1602 to ----
-- location 6
USE [AdventureWorks]
GO
UPDATE [Production].[ProductInventory]
SET LocationID = 6
WHERE ProductID IN
(SELECT ProductID
FROM Purchasing.ProductVendor
WHERE BusinessEntityID = 1602)
GODid you catch sight of what we did there?
The thing is, you can put subqueries in the WHERE clause of an UPDATE statement.
Since we don’t have it in the example, you can also use a subquery for the SET clause like SET column = (subquery). But be warned: it should output a single value because otherwise, an error occurs.
What do we do next?
Using SQL Subqueries in INSERT Statements
As you already know, you can insert records into a table using a SELECT statement. I’m sure you have an idea of what the subquery structure will be, but let’s demonstrate this with an example:
-- Impose a salary increase for all employees in DepartmentID 6
-- (Research and Development) by 10 (dollars, I think)
-- effective June 1, 2020
USE [AdventureWorks]
GO
INSERT INTO [HumanResources].[EmployeePayHistory]
([BusinessEntityID]
,[RateChangeDate]
,[Rate]
,[PayFrequency]
,[ModifiedDate])
SELECT
a.BusinessEntityID
,'06/01/2020' as RateChangeDate
,(SELECT MAX(b.Rate) FROM [HumanResources].[EmployeePayHistory] b
WHERE a.BusinessEntityID = b.BusinessEntityID) + 10 as NewRate
,2 as PayFrequency
,getdate() as ModifiedDate
FROM [HumanResources].[EmployeeDepartmentHistory] a
WHERE a.DepartmentID = 6
and StartDate = (SELECT MAX(c.StartDate)
FROM HumanResources.EmployeeDepartmentHistory c
WHERE c.BusinessEntityID = a.BusinessEntityID)So, what are we looking at here?
- The first subquery retrieves the last salary rate of an employee before adding the additional 10.
- The second subquery gets the last salary record of the employee.
- Lastly, the result of the SELECT is inserted into the EmployeePayHistory table.
In Other T-SQL Statements
Aside from SELECT, INSERT, UPDATE, and DELETE, you can also use SQL subqueries in the following:
Variable Declarations or SET statements in Stored Procedures and Functions
Let me clarify using this example:
DECLARE @maxTransId int = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)Alternatively, you can do this the following way:
DECLARE @maxTransId int
SET @maxTransId = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)In Conditional Expressions
Why don’t you take a peek at this example:
IF EXISTS(SELECT [Name] FROM sys.tables where [Name] = 'MyVendors')
BEGIN
DROP TABLE MyVendors
ENDApart from that, we can do it like this:
IF (SELECT count(*) FROM MyVendors) > 0
BEGIN
-- insert code here
ENDMake SQL Subqueries with Comparison or Logical Operators
So far, we have seen the equals (=) operator and the IN operator. But there is much more to explore.
Using Comparison Operators
When a comparison operator like =, <, >, <>, >=, or <= is used with a subquery, the subquery should return a single value. Moreover, an error occurs if the subquery returns multiple values.
The example below will generate a runtime error.
USE [AdventureWorks]
GO
SELECT b.LastName, b.FirstName, b.MiddleName, a.JobTitle, a.BusinessEntityID
FROM HumanResources.Employee a
INNER JOIN Person.Person b on a.BusinessEntityID = b.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory c on a.BusinessEntityID
= c.BusinessEntityID
WHERE c.DepartmentID = 6
and StartDate = (SELECT d.StartDate
FROM HumanResources.EmployeeDepartmentHistory d
WHERE d.BusinessEntityID = a.BusinessEntityID)Do you know what’s wrong in the above code?
First of all, the code uses the equals (=) operator with the subquery. Additionally, the subquery returns a list of start dates.
In order to fix the problem, make the subquery use a function like MAX() on the start date column to return a single value.
Using Logical Operators
Using EXISTS or NOT EXISTS
EXISTS returns TRUE if the subquery returns any rows. Otherwise, it returns FALSE. Meanwhile, using NOT EXISTS will return TRUE if there are no rows and FALSE, otherwise.
Consider the example below:
IF EXISTS(SELECT name FROM sys.tables where name = 'Token')
BEGIN
DROP TABLE Token
ENDFirst, allow me to explain. The code above will drop the table Token if it’s found in sys.tables, meaning if it exists in the database. Another point: the reference to the column name is irrelevant.
Why is that?
It turns out that the database engine only needs to get at least 1 row using EXISTS. In our example, if the subquery returns a row, the table will be dropped. On the other hand, if the subquery didn’t return a single row, the succeeding statements will not be executed.
Thus, the concern of EXISTS is just rows and no columns.
Additionally, EXISTS uses two-valued logic: TRUE or FALSE. There are no cases that it will return NULL. The same thing happens when you negate EXISTS using NOT.
Using IN or NOT IN
A subquery introduced with IN or NOT IN will return a list of zero or more values. And unlike EXISTS, a valid column with the appropriate data type is required.
Let me clarify this with another example:
-- From the product inventory, extract the products that are available
-- (Quantity >0)
-- except for products from Vendor 1676, and introduce a price cut for the --- whole month of June 2020.
-- Insert the results in product price history.
USE [AdventureWorks]
GO
INSERT INTO [Production].[ProductListPriceHistory]
([ProductID]
,[StartDate]
,[EndDate]
,[ListPrice]
,[ModifiedDate])
SELECT
a.ProductID
,'06/01/2020' as StartDate
,'06/30/2020' as EndDate
,a.ListPrice - 2 as ReducedListPrice
,getdate() as ModifiedDate
FROM [Production].[ProductListPriceHistory] a
WHERE a.StartDate = (SELECT MAX(StartDate)
FROM Production.ProductListPriceHistory
WHERE ProductID = a.ProductID)
AND a.ProductID IN (SELECT ProductID
FROM Production.ProductInventory
WHERE Quantity > 0)
AND a.ProductID NOT IN (SELECT ProductID
FROM [Purchasing].[ProductVendor]
WHERE BusinessEntityID = 1676As you can see from the above code, both IN and NOT IN operators are introduced. And in both cases, rows will be returned. Each row in the outer query will be matched against the result of each subquery in order to get a product that is on hand and a product that is not from vendor 1676.
Nesting of SQL Subqueries
You can nest subqueries even up to 32 levels. Nonetheless, this capability depends on the server’s available memory and the complexity of other expressions in the query.
What’s your take on this?
In my experience, I do not recall nesting up to 4. I rarely use 2 or 3 levels. But that’s just me and my requirements.
How about a good example to figure this out:
-- List down the names of employees who are also customers.
USE [AdventureWorks]
GO
SELECT
LastName
,FirstName
,MiddleName
FROM Person.Person
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Sales.Customer
WHERE BusinessEntityID IN
(SELECT BusinessEntityID
FROM HumanResources.Employee))As we can see in this example, nesting reached 2 levels.
Are SQL Subqueries Bad for Performance?
In a nutshell: yes and no. In other words, it depends.
And don’t forget, this is in the context of SQL Server.
For starters, many T-SQL statements that use subqueries can alternatively be rewritten using JOINs. And performance for both is usually the same. Despite that, there are particular cases when a join is faster. And there are cases when the subquery works more quickly.
Example 1
Let’s examine a subquery example. Before executing them, press Control-M or enable Include Actual Execution Plan from the toolbar of SQL Server Management Studio.
USE [AdventureWorks]
GO
SELECT Name
FROM Production.Product
WHERE ListPrice = SELECT ListPrice
FROM Production.Product
WHERE Name = 'Touring End Caps')Alternatively, the query above can be rewritten using a join that yields the same outcome.
USE [AdventureWorks]
GO
SELECT Prd1.Name
FROM Production.Product AS Prd1
INNER JOIN Production.Product AS Prd2 ON (Prd1.ListPrice = Prd2.ListPrice)
WHERE Prd2.Name = 'Touring End Caps'In the end, the result for both queries is 200 rows.
As well as that, you can check out the execution plan for both statements.
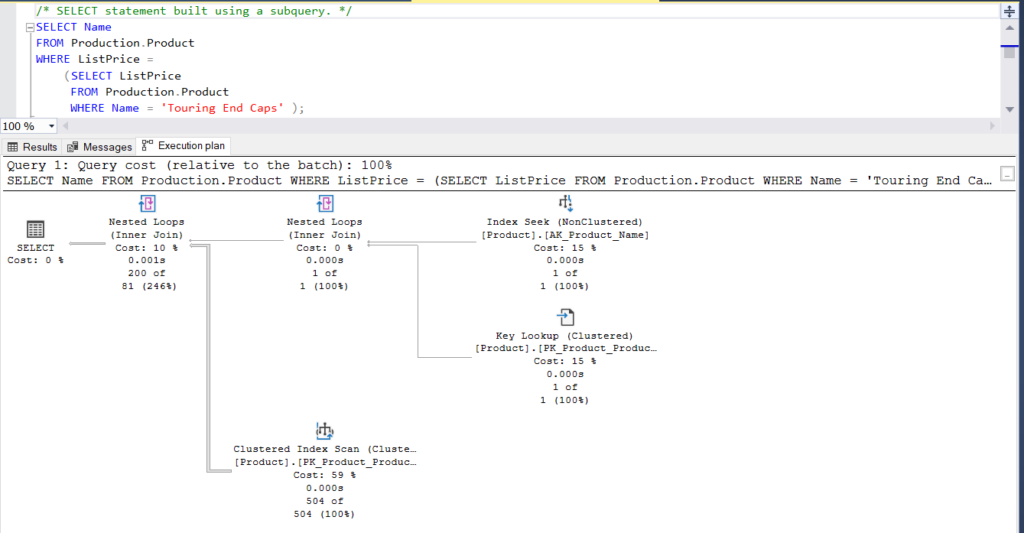
Figure 1: Execution Plan Using a Subquery
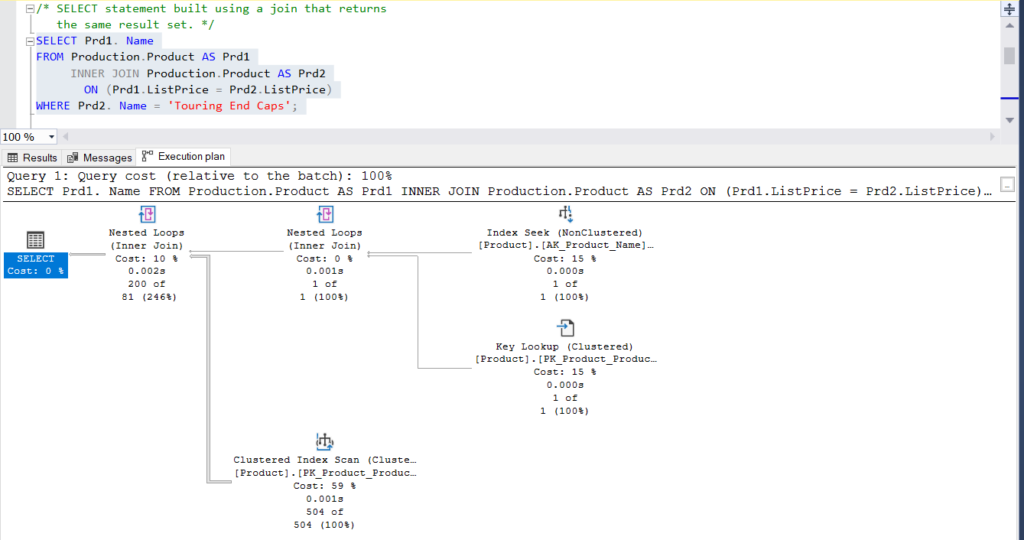
Figure 2: Execution Plan Using a Join
What do you think? Are they practically the same? Except for the actual elapsed time of each node, everything else is basically the same.
But here’s another way of comparing it aside from visual differences. I suggest using the Compare Showplan.
To perform it, follow these steps:
- Right-click the execution plan of the statement using the subquery.
- Select Save Execution Plan As.
- Name the file subquery-execution-plan.sqlplan.
- Go to the execution plan of the statement using a join and right-click it.
- Select Compare Showplan.
- Select the filename you saved in #3.
Now, check this out for more information about Compare Showplan.
You should be able to see something similar to this:
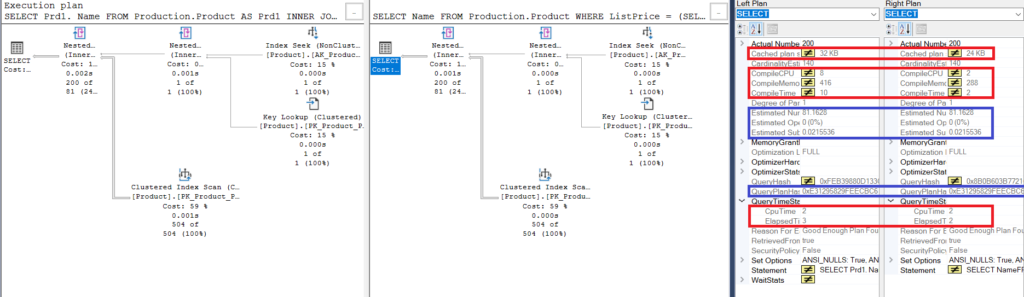
Figure 3: Compare Showplan for using a join vs. using a subquery
Notice the similarities:
- Estimated rows and costs are the same.
- QueryPlanHash is also the same, meaning they have similar execution plans.
Nevertheless, take a notice of the differences:
- Cache plan size is larger using the join than using the subquery
- Compile CPU and time (in ms), including the memory in KB, used to parse, bind, and optimize the execution plan is higher using the join than using the subquery
- CPU time and elapsed time (in ms) to execute the plan is slightly higher using the join vs. the subquery
In this example, the subquery is a tic faster than the join, even though the resulting rows are the same.
Example 2
In the previous example, we used just one table. In the example that follows, we are going to use 3 different tables.
Let’s make this happen:
-- Subquery example
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID =
p.BusinessEntityID
WHERE p.PersonType='SC')-- Join example
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'Both queries output the same 3806 rows.
Next, let’s have a look at their execution plans:
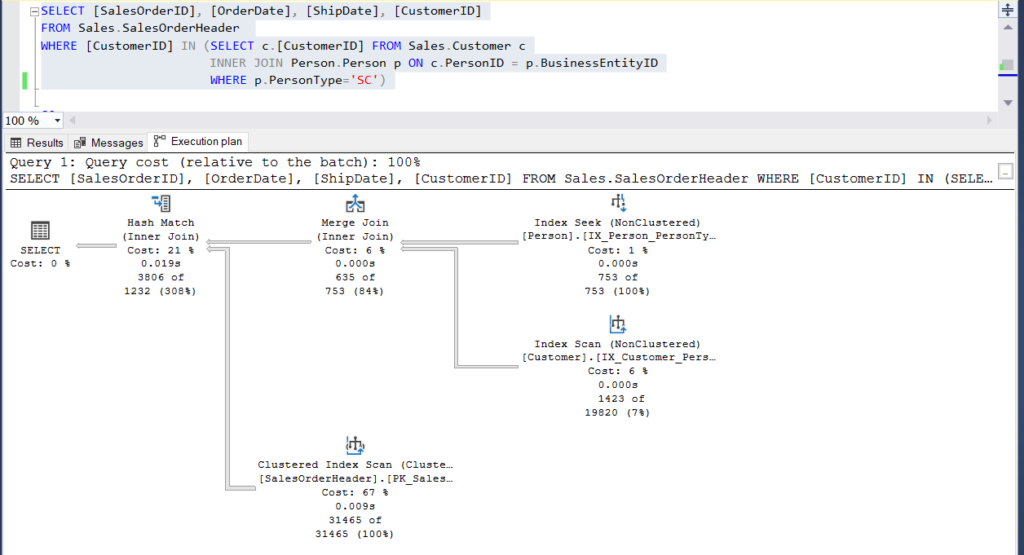
Figure 4: Execution Plan for our second example using a subquery
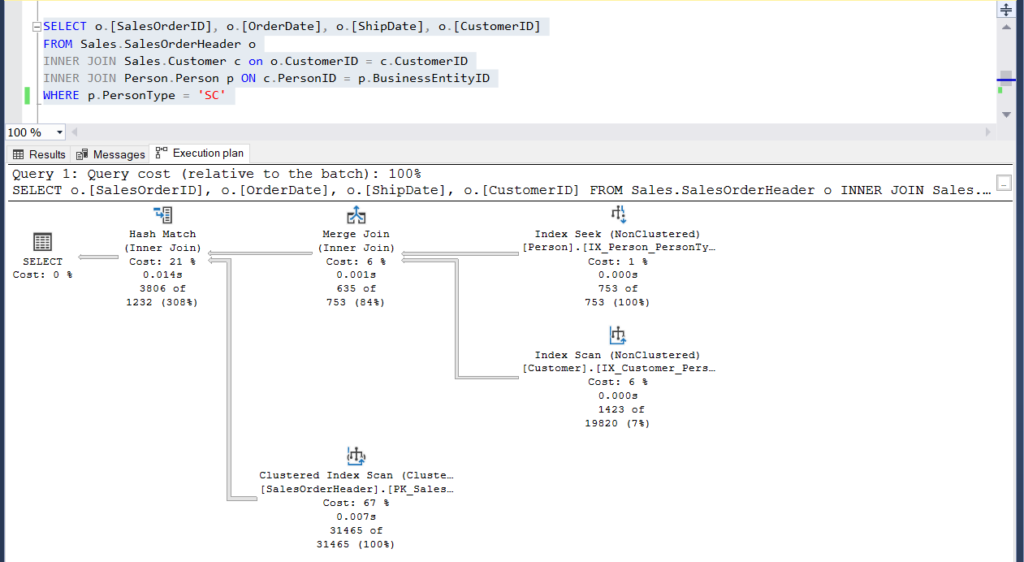
Figure 5: Execution Plan for our second example using a join
Can you see the 2 execution plans and find any difference between them? At a glance they look the same.
But a more careful examination with the Compare Showplan reveals what’s really inside.
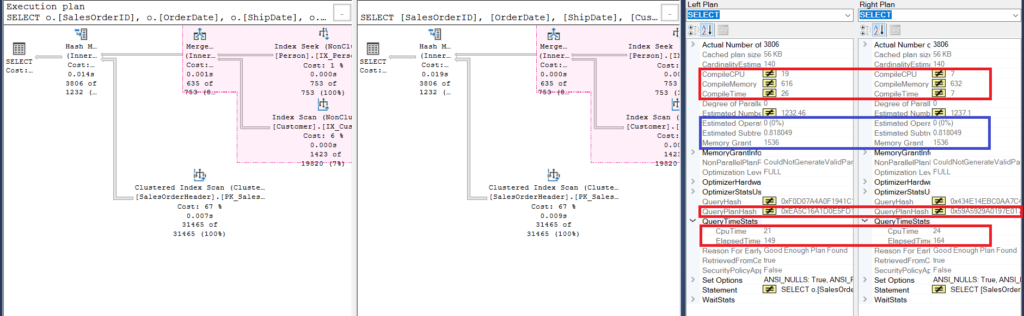
Figure 6: Details of Compare Showplan for the second example
Let’s start off by analyzing a few similarities:
- The pink highlight in the execution plan reveals similar operations for both queries. Since the inner query uses a join instead of nesting subqueries, this is quite understandable.
- The estimated operator and subtree costs are the same.
Next, let’s take a look at the differences:
- First, the compilation took longer when we used joins. You can check that in the Compile CPU and Compile Time. However, the query with a subquery took a higher Compile Memory in KB.
- Then, the QueryPlanHash of both queries is different, meaning they have a different execution plan.
- Lastly, the elapsed time and CPU time to execute the plan are faster using the join than using a subquery.
Subquery vs. Join Performance Takeaway
You are likely to face too many other query-related problems that can be solved by using a join or a subquery.
But the bottom line is a subquery is not inherently bad as compared to joins. And there is no rule of thumb that in a particular situation a join is better than a subquery or the other way around.
So, to make sure that you have the best choice, check the execution plans. The purpose of that is to gain insight into how SQL Server will process a particular query.
However, if you choose to use a subquery, be aware that problems may arise that will test your skill.
Common Caveats in Using SQL Subqueries
There are 2 common problems that may cause your queries to behave wildly when using SQL subqueries.
The Pain of Column Name Resolution
This problem introduces logical bugs into your queries and they may be very tricky to find. An example can further clarify this problem.
Let’s start by creating a table for demo purposes and populating it with data.
USE [AdventureWorks]
GO
-- Create the table for our demonstration based on Vendors
CREATE TABLE Purchasing.MyVendors
(
BusinessEntity_id int,
AccountNumber nvarchar(15),
Name nvarchar(50)
)
GO
-- Populate some data to our new table
INSERT INTO Purchasing.MyVendors
SELECT BusinessEntityID, AccountNumber, Name
FROM Purchasing.Vendor
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.ProductVendor)
AND BusinessEntityID like '14%'
GONow that the table is set, let’s fire some subqueries using it. But before executing the query below, remember that the vendor IDs we used from the previous code start with ’14’.
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.MyVendors)The above code runs without errors, as you can see below. Anyway, pay your attention to the list of BusinessEntityIDs.
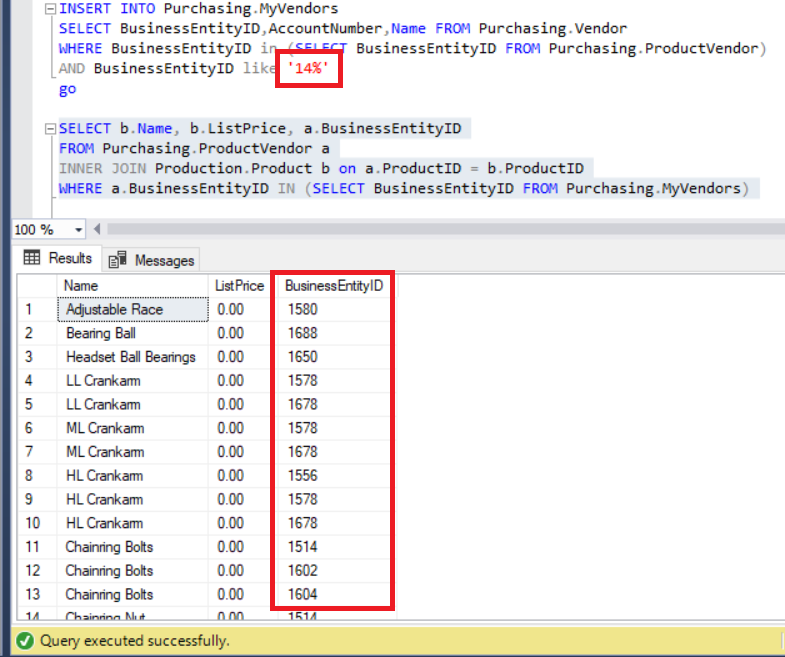
Figure 7: BusinessEntityIDs of the result set are inconsistent with the records of MyVendors table
Didn’t we insert data with BusinessEntityID starting with ’14’? Then what’s the matter? In fact, we can see BusinessEntityIDs that start with ’15’ and ’16’. Where did these come from?
Actually, the query listed all the data from ProductVendor table.
In that case, you might think that an alias will resolve this problem so that it will refer to MyVendors table just like the one below:
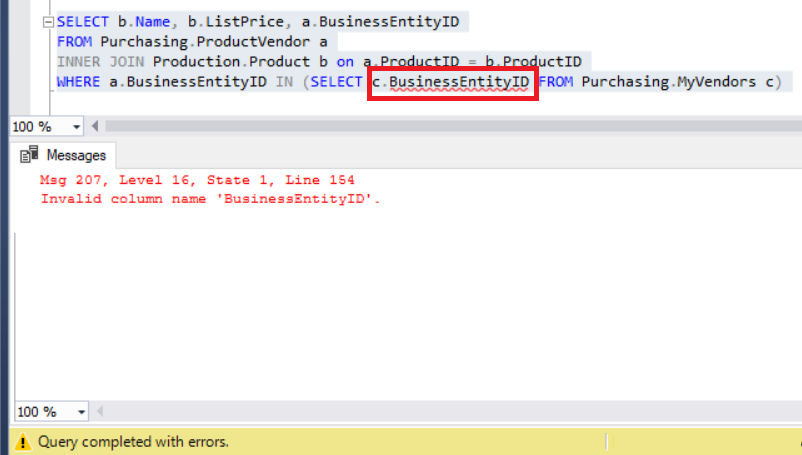
Figure 8: Adding an alias to the BusinessEntityID results in an error
Except that now the real problem showed up because of a runtime error.
Check the MyVendors table again and you will see that instead of BusinessEntityID, the column name has to be BusinessEntity_id (with an underscore).
Thus, using the correct column name will finally fix this issue, as you can see below:
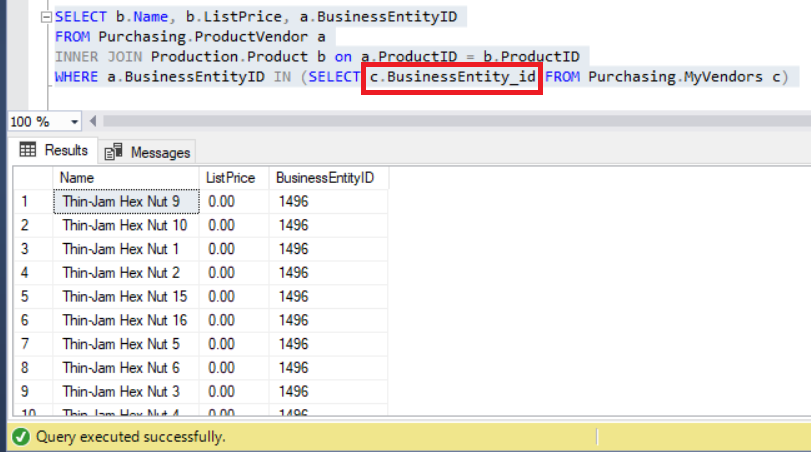
Figure 9: Changing the subquery with the correct column name solved the problem
As you can see above, we can now observe BusinessEntityIDs starting with ’14’ just as we have expected previously.
But you may wonder: why on Earth did SQL Server allow to run the query successfully in the first place?
Here’s the kicker: The resolution of column names with no alias works in the context of the subquery from in itself going out to the outer query. That is why the reference to BusinessEntityID inside the subquery didn’t trigger an error because it is found outside the subquery – in the ProductVendor table.
In other words, SQL Server looks for the non-aliased column BusinessEntityID in MyVendors table. Since it’s not there, it looked outside and found it in the ProductVendor table. Crazy, isn’t it?
You might say that is a bug in SQL Server, but, actually, it’s by design in the SQL standard and Microsoft followed it.
All right, that’s clear, we can’t do anything about the standard, but how can we avoid running into an error?
- First, prefix the column names with the table name or use an alias. In other words, avoid non-prefixed or non-aliased table names.
- Second, have a consistent naming of columns. Avoid having both BusinessEntityID and BusinessEntity_id, for instance.
Sounds good? Yup, this brings some sanity into the situation.
But this is not the end of it.
Crazy NULLs
Like I mentioned, there’s more to cover. T-SQL uses 3-valued logic because of its support for NULL. And NULL can nearly drive us nuts when we use SQL subqueries with NOT IN.
Let me start by introducing this example:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c)The output of the query leads us to a list of products not in MyVendors table., as seen below:
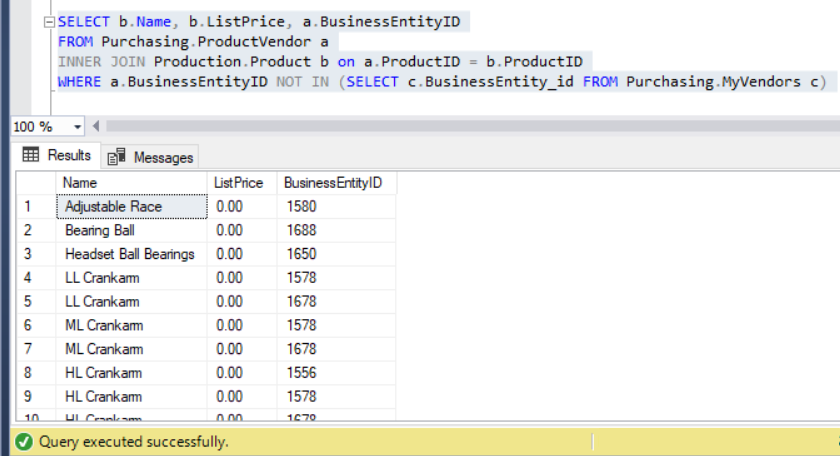
Figure 10: The output of the sample query using NOT IN
Now, suppose someone unintentionally inserted a record in the MyVendors table with a NULL BusinessEntity_id. What are we going to do about that?
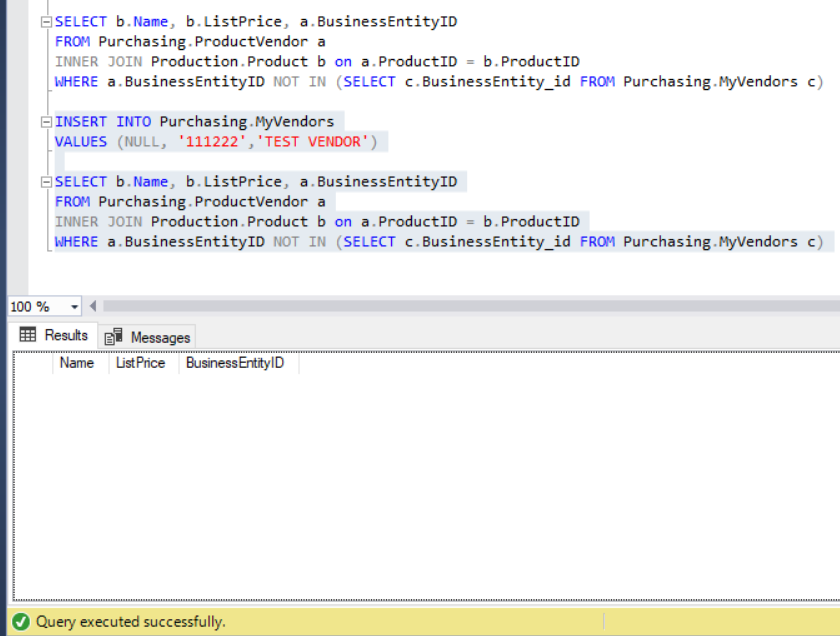
Figure 11: The result set becomes empty when a NULL BusinessEntity_id is inserted into MyVendors
Where did all the data go?
You see, the NOT operator negated the IN predicate. So, NOT TRUE will now become FALSE. But NOT NULL is UNKNOWN. That caused the filter to discard the rows that are UNKNOWN, and this is the culprit.
To make sure this doesn’t happen to you:
- Either make the table column disallow NULLs if data should not be that way.
- Or add the column_name IS NOT NULL to your WHERE clause. In our case, the subquery is as follows:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c
WHERE c.BusinessEntity_id IS NOT NULL)Takeaways
We have talked pretty much about subqueries, and the time has come to provide the major takeaways of this post in the form of a summarized list:
A subquery:
- is a query within a query.
- is enclosed in parentheses.
- can substitute an expression anywhere.
- can be used in SELECT, INSERT, UPDATE, DELETE, or other T-SQL statements.
- may be self-contained or correlated.
- outputs single, multiple, or table values.
- works on comparison operators like =, <>, >, <, >=, <= and logical operators like IN/NOT IN and EXISTS/NOT EXISTS.
- is not bad or evil. It can perform better or worse than JOINs depending on a situation. So take my advice and always check the execution plans.
- can have nasty behavior on NULLs when used with NOT IN, and when a column is not explicitly identified with a table or table alias.
Get familiarized with several additional references for your reading pleasure:
- Discussion of Subqueries from Microsoft.
- IN (Transact-SQL)
- EXISTS (Transact-SQL)
- ALL (Transact-SQL)
- SOME | ANY (Transact-SQL)
- Comparison Operators








[…] avoid duplicates, the COUNT or records returned by the subquery above should be […]