JSON is one of the most widely used data interchange formats. It is also a storing format in several NoSQL solutions, in particular, in Microsoft Azure DocumentDB. One of the reasons for its popularity is a simpler form and better readability in comparison with XML.
Naturally, there was a need in processing data in the JSON format within SQL Server, and this option was introduced in SQL Server 2016.
This article will focus on working with JSON data in SQL Server and performing the fundamental tasks:
Data Extraction
Data Generation
Transformation into Relational Structure
Data Modification
Storage and Indexation
Performance Comparison of JSON vs XML
Data Extraction
There is no separate type for storing JSON. It is stored in the standard variables or in the varchar or nvarchar fields.
To extract data from JSON to SQL Server 2016, we have the following 3 functions:
The ISJSON function allows you to check whether a text contains the correct JSON format. It returns 1 if it is JSON, 0 if it is not JSON, and null if NULL was passed to it.
declare
@json1 varchar(max) = N'{"test": 1}',
@json2 varchar(max) = N'1',
@json3 varchar(max) = null;
select
isjson(@json1) as json1,
isjson(@json2) as json2,
isjson(@json3) as json3;
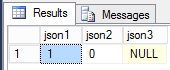
To extract a certain value, we can use the JSON_VALUE function:
declare @json varchar(max) =
'{
"info":{
"specialization":"computer science",
"course number":1,
"address":{
"town":"Moscow",
"region":"Moscow",
"country":"Russia"
},
"parents":["Anna", "Peter"]
},
"type":"Student"
}';
select
json_value(@json, '$.info.specialization') as [specialization],
json_value(@json, '$.info."course number"') as [course_number],
json_value(@json, '$.info.address.town') as [town],
json_value(@json, '$.info.parents[0]') as [mother],
json_value(@json, '$.info.parents[1]') as [father];

Finally, to extract a certain fragment from JSON, we can use the JSON_QUERY function:
declare @json varchar(max) =
'{
"info":{
"specialization":"computer science",
"course number":1,
"address":{
"town":"Moscow",
"region":"Moscow",
"country":"Russia"
},
"parents":["Anna", "Peter"]
},
"type":"Student"
}';
select
json_query(@json, '$.info.address') as [address],
json_query(@json, '$.info.parents') as [parents];

Let’s explore the JSON path expressions that are used in the JSON_VALUE and JSON_QUERY functions. They are quite simple.
$ – reference to JSON entity in text
$.property1 – a reference to property1
$.array1[0] – a reference to the first array element array1 (the numeration begins with zero, as in JavaScript)
$.property1.property2.property3 – reference to property3 that is nested into property2 and property1. This is how objects are extracted on several nesting levels.
$.”property name 1″ – if a property name contains special characters and spaces, its name should be enclosed within the quotation marks.
Also, there are 2 types of such expressions, lax and strict.
lax is used by default and you don’t need to specify anything else, but still, you can do it forcibly. For this, you need to specify lax at the beginning of the expression, e.g., “lax$.property1” or “strict$.property1”.
The difference between these two types is that if you specify non-existing or wrong paths for functions, you get NULL with lax expression, and an error, if you specify strict.
For example, if you specify an expression that returns the nonscalar value for the JSON_VALUE function, the lax expression will rerun NULL, while strict will throw an error.
declare @json varchar(max) =
'{
"info":{
"specialization":"computer science",
"course number":1,
"address":{
"town":"Moscow",
"region":"Moscow",
"country":"Russia"
},
"parents":["Anna", "Peter"]
},
"type":"Student"
}';
select
json_value(@json, '$.property.not.exists') as [not exists], -- Property does not exist.
json_value(@json, 'lax$.property.not.exists') as [not exists], -- Property does not exist.
json_value(@json, '$.info.address[0]') as [address_0] – An attempt to refer the element that is not an array.
;
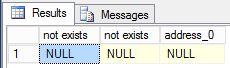
In the case of using the strict type, we will get the error:
declare @json varchar(max) =
'{
"info":{
"specialization":"computer science",
"course number":1,
"address":{
"town":"Moscow",
"region":"Moscow",
"country":"Russia"
},
"parents":["Anna", "Peter"]
},
"type":"Student"
}';
select json_value(@json, 'strict$.property.not.exists') as [not exists]; -- Property does not exist
Msg 13608, Level 16, State 5, Line 16
Property cannot be found on the specified JSON path.
All these functions can work with both functions and table columns.
declare @json varchar(max) =
'{
"info":{
"specialization":"computer science",
"course number":1,
"address":{
"town":"Moscow",
"region":"Moscow",
"country":"Russia"
},
"parents":["Anna", "Peter"]
},
"type":"Student"
}';
if object_id('tempdb..#test', 'U') is not null
drop table #test;
create table #test (
json_text varchar(max) null
);
insert into #test (json_text) values (@json);
select json_value(json_text, 'strict$.info.parents[0]') as [parents]
from #test;
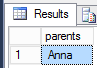
That’s all about extracting data from JSON.
Data Generation
To generate JSON from relational data, we use the FOR JSON statement.
The easiest way is using FOR JSON AUTO. It will generate the JSON object array where each row in the selection will be a separate object, while a column will be a property.
use tempdb;
go
drop table if exists dbo.test_table;
go
create table dbo.test_table (
id int not null,
name varchar(100) null,
dt datetime null
);
go
insert into dbo.test_table (id, name, dt)
values
(1, 'qwe', '19000101'),
(2, 'asd', null),
(3, null, '20000101');
go
select id, name, dt
from dbo.test_table
for json auto;
go
[{“id”:1,”name”:”qwe”,”dt”:”1900-01-01T00:00:00″},
{“id”:2,”name”:”asd”},
{“id”:3,”dt”:”2000-01-01T00:00:00″}]
As you can see, NULL values are ignored. If we want to include them in JSON, we can use the additional INCLUDE_NULL_VALUES option.
select id, name, dt
from dbo.test_table
for json auto, include_null_values;
go
[{“id”:1,”name”:”qwe”,”dt”:”1900-01-01T00:00:00″},
{“id”:2,”name”:”asd”,”dt”:null},
{“id”:3,”name”:null,”dt”:”2000-01-01T00:00:00″}]
The WITHOUT_ARRAY_WRAPPER statement may help if we want to display JSON without square brackets.
select id, name, dt
from dbo.test_table
for json auto, without_array_wrapper;
go
{“id”:1,”name”:”qwe”,”dt”:”1900-01-01T00:00:00″},
{“id”:2,”name”:”asd”},
{“id”:3,”dt”:”2000-01-01T00:00:00″}
If we need to combine the results with the root component, it is better to use the ROOT statement and specify its proper name.
select id, name, dt
from dbo.test_table
for json auto, root('root');
go
{“root”:
[{“id”:1,”name”:”qwe”,”dt”:”1900-01-01T00:00:00″},
{“id”:2,”name”:”asd”},
{“id”:3,”dt”:”2000-01-01T00:00:00″}]
}
Finally, if you want to create JSON with a more complex structure, specify proper names for properties, and group them, use the FOR JSON PATH statement.
To check how you can generate JSON with a more complex structure, run this query:
select
id,
name as 'data.full_name',
dt as 'data.add date'
from dbo.test_table
for json path;
go
[{“id”:1,”data”:{“full_name”:”qwe”,”add date”:”1900-01-01T00:00:00″}},
{“id”:2,”data”:{“full_name”:”asd”}},
{“id”:3,”data”:{“add date”:”2000-01-01T00:00:00″}}]
Note: You can use the dbForge Data Generator for SQL Server for generation of meaningful test data for databases quickly – it is a powerful and user-friendly GUI tool.
Transformation into Relational Structure
We have explored generating JSON from relational data. Now, let us examine the reverse operation. We are going to transform JSON into a relational structure.
To do this, you can use the OPENJSON statement (but notice that it will work only in databases with the 130-compatibility level).
There are two modes of the OPENJSON statement. The easiest one is to use it without specifying a scheme for the target selection.
declare @json varchar(max) = '{"first name":"Sergey","last name":"Olontsev","age":32,"skills":
["SQL Server 2016","T-SQL","JSON"],"additional info":{"data1":1,"data2":2}}';
select * from openjson(@json);
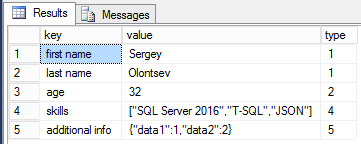
In this case, it will return the result in three columns:
- Key – shows the property name;
- Value – shows the value;
- Type – presents the type.
In our example, JSON has a hierarchical structure with an array for one of the properties.
The OPENJSON statement retrieves all the properties from the first level and outputs them as a list. We can retrieve all array components or their properties from the necessary level separately by specifying the path.
declare @json varchar(max) = '{"first name":"Sergey","last name":"Olontsev","age":32,"skills":
["SQL Server 2016","T-SQL","JSON"],"additional info":{"data1":1,"data2":2}}';
select * from openjson(@json, '$.skills');
select * from openjson(@json, 'strict$."additional info"');
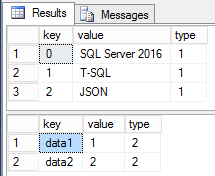
The data in the table can have the following values:
[table “6” not found /]
In the second mode of the OPENJSON statement, you can describe what the target result will be: column names, the number, and where to obtain values from JSON.
declare @json varchar(max) = '{"first name":"Sergey","last name":"Olontsev","age":32,"skills":
["SQL Server 2016","T-SQL","JSON"],"additional info":{"data1":1,"data2":2}}';
select *
from openjson(@json)
with (
fisrt_name varchar(100) '$."first name"',
last_name varchar(100) '$."last name"',
age tinyint '$.age',
skill1 varchar(50) '$.skills[0]',
skill2 varchar(50) '$.skills[1]',
data1 varchar(50) '$."additional info".data1'
);

If there are several objects in JSON, a separate row will be generated for each object, as well as column values will be selected by corresponding paths.
declare @json varchar(max) = '[
{"first name":"Sergey","last name":"Olontsev","age":32,"skills":
["SQL Server 2016","T-SQL","JSON"],"additional info":{"data1":1,"data2":2}},
{"first name":"John","last name":"Smith","age":18,"skills":
["SQL Server 2014","In-Memory OLTP"],"additional info":{"data2":4}}
]';
select *
from openjson(@json)
with (
fisrt_name varchar(100) '$."first name"',
last_name varchar(100) '$."last name"',
age tinyint '$.age',
skill1 varchar(50) '$.skills[0]',
skill2 varchar(50) '$.skills[1]',
data1 varchar(50) '$."additional info".data1'
);

That is all about how you can select data from the JSON object and transform it into the relational structure.
Data Modification
To modify data, it is necessary to use the JSON_MODIFY statement with the JSON file as an input, as well as a necessary property and a new value.
declare @json varchar(max) = '{"first name":"Sergey","last name":"Olontsev","age":30,"skills":
["SQL Server 2014","T-SQL","JSON"]}';
set @json = json_modify(@json, 'lax$.age', json_value(@json, '$.age') + 2);
set @json = json_modify(@json, '$.skills[0]', 'SQL Server 2016');
set @json = json_modify(@json, 'append strict$.skills', 'In-Memory OLTP');
select * from openjson(@json);
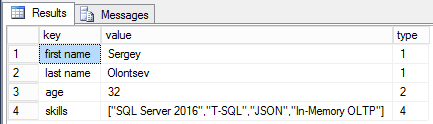
As you can see, everything seems to be easy. Also, you can use the keyword append if you want to add a new value to the data array.
To delete any property in the file, you need to specify the NULL value in the lax mode.
declare @json varchar(max) = '{"first name":"Sergey","last name":"Olontsev","age":30,"skills":
["SQL Server 2014","T-SQL","JSON"]}';
select * from openjson(json_modify(@json, 'lax$.age', null));
select * from openjson(json_modify(@json, 'strict$.age', null));
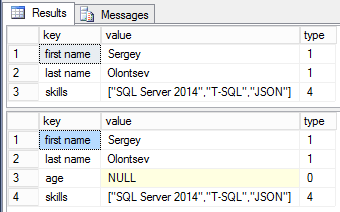
However, if you try to do this in the strict mode, the null value will be specified for the property. Besides, the property will not be deleted from the file. If you try to assign null or any value to a non-existing element in the strict mode, you will receive an error.
declare @json varchar(max) = '{"first name":"Sergey","last name":"Olontsev","age":30,"skills":
["SQL Server 2014","T-SQL","JSON"]}';
select * from openjson(json_modify(@json, 'strict$.hobby', null));
Msg 13608, Level 16, State 2, Line 3
Property cannot be found on the specified JSON path.
That is all about the data modification in JSON files.
Storage and Indexation
As we know, developers did not add a separate type for JSON to SQL Server 2016 as they did for XML. Thus, you can use any string data types to store JSON.
VARCHAR(MAX) and NVARCHAR(MAX) are more suitable depending on whether there are Unicode symbols in JSON files. Also, you can use “smaller” data types if you are sure that your JSON objects will fit those data types correctly.
If you worked with XML, you should remember that SQL Server provides several types of indexes, which help to reduce the selection time. However, there are no such indexes for string data types that are supposed to store JSON.
As a workaround, we can use calculated columns that can represent particular properties of JSON files by which we are going to search. We can create indexes for these columns.
use test;
go
drop table if exists dbo.test_table;
go
create table dbo.test_table (
id int not null,
json_data varchar(max) null,
constraint pk_test_table primary key clustered (id)
);
go
insert into dbo.test_table (
id,
json_data
)
values
(1, '{"first name":"Sergey","last name":"Olontsev","age":32,"skills":
["SQL Server 2016","T-SQL","JSON"]}'),
(2, '{"first name":"John","last name":"Smith","sex":"m","skills":
["SQL Server 2014","In-Memory OLTP"]}'),
(3, '{"first name":"Mary","last name":"Brown","age":25,"skills":
["SQL Server 2016","In-Memory OLTP"]}');
go
alter table dbo.test_table
add v_age as json_value(json_data, '$.age') persisted;
go
alter table dbo.test_table
add v_skills as json_query(json_data, '$.skills') persisted;
go
create nonclustered index ix_nc_test_table_v_age on [dbo].[test_table] (v_age);
go
create fulltext catalog [jsonFullTextCatalog] with accent_sensitivity =
on authorization [dbo];
go
create fulltext index on [dbo].[test_table] (v_skills)
key index pk_test_table ON jsonFullTextCatalog;
go
select *
from [dbo].[test_table] as t
where
t.[v_age] = 32;
select *
from [dbo].[test_table] as t
where
contains(t.v_skills, 'OLTP');
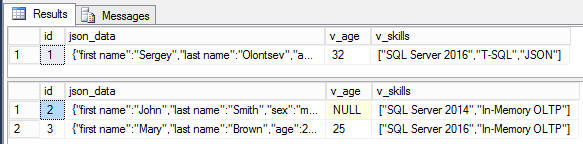
Create calculated columns as persisted. Otherwise, there is no sense to add indexes to those columns. Additionally, you can create both standard and full-text indexes if you want to get a flexible search by the array content or by the objects.
In addition, full-text indexes have no special rules for processing JSON. They simply split the text into separate words using double quotes, commas, brackets, etc. as unit separators.
JSON vs XML: Performance Comparison
I have mentioned that developers give preferences to JSON as it has a clearer structure and smaller data size comparing to XML. What are the other differences?
To compare JSON vs XML performance, I have created a script, which measures the speed of the JSON_VALUE statement and the value() method for XML. For JSON, I have decided to check how the data retrieval of both varchar(max) and nvarchar(max) works.
I have created JSON and XML queries similar in structure. Now, we will try to retrieve different data types (numeric and string data types) from various file parts.
declare @json varchar(max) = '[
{"first name":"Sergey","last name":"Olontsev","age":32,"skills":["SQL Server 2016","T-SQL","JSON"]},
{"first name":"John","last name":"Smith","sex":"m","skills":["SQL Server 2014","In-Memory OLTP"]},
{"first name":"Mary","last name":"Brown","age":25,"skills":["SQL Server 2016","In-Memory OLTP"]}]';
declare @json_u nvarchar(max) = N'[
{"first name":"Sergey","last name":"Olontsev","age":32,"skills":["SQL Server 2016","T-SQL","JSON"]},
{"first name":"John","last name":"Smith","sex":"m","skills":["SQL Server 2014","In-Memory OLTP"]},
{"first name":"Mary","last name":"Brown","age":25,"skills":["SQL Server 2016","In-Memory OLTP"]}]';
declare @xml xml = N'
32SQL Server 2016T-SQLJSON
mSQL Server 2014In-Memory OLTP
25SQL Server 2016In-Memory OLTP
';
declare
@i int,
@v1 int,
@v2 varchar(100),
@start_time datetime,
@end_time datetime,
@iterations int = 1000000,
@path_expression nvarchar(1000),
@returned_type varchar(100);
declare @results table (
data_type varchar(100) not null,
test_id tinyint not null,
path_expression varchar(1000) not null,
returned_type varchar(1000),
elapsed_time_ms int not null
);
set @returned_type = 'int';
set @path_expression = '$[0].age'
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v1 = json_value(@json, '$[0].age');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json', 1, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '$[2]."first name"';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = json_value(@json, '$[2]."first name"');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json', 2, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '$[2].skills[0]';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = json_value(@json, '$[2].skills[0]');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json', 3, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'int';
set @path_expression = '$[0].age'
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v1 = json_value(@json_u, '$[0].age');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json u', 1, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '$[2]."first name"';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = json_value(@json_u, '$[2]."first name"');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json u', 2, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '$[2].skills[0]';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = json_value(@json_u, '$[2].skills[0]');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json u', 3, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'int';
set @path_expression = '(/root/rec/age)[1]';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v1 = @xml.value('(/root/rec/age)[1]', 'int');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'xml', 1, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '(/root/rec/@first_name)[3]';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = @xml.value('(/root/rec/@first_name)[3]', 'varchar(100)');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'xml', 2, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '/root[1]/rec[3]/skills[1]/skill[1]';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = @xml.value('/root[1]/rec[3]/skills[1]/skill[1]', 'varchar(100)');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'xml', 3, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
select *
from @results;
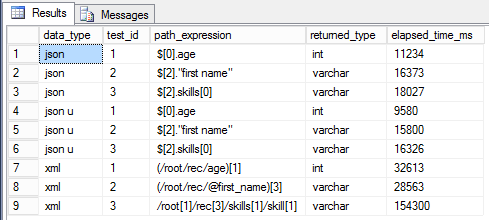
The results were surprising. The data selection from the JSON file stored in the nvarchar(max) type is processed faster by 5-15%, comparing to the standard type without Unicode. However, we should have got a vice versa result.
It turns out that it is beneficial to process JSON stored in the Unicode format.
Besides, the data retrieval from JSON is 2-10 times faster comparing to XML. Thus, I highly recommend using JSON instead of XML whenever it is possible.
Conclusion
The existing JSON functionality in SQL Server is extremely helpful. You can query and analyze the JSON data and transform it into relational structures (and vice versa).
Considering the popularity of JSON and its many advantages in comparison with XML, the possibility to integrate SQL Server into larger JSON-based systems with no additional transformations is only welcome.
Tags: json, sql server 2016, xml Last modified: October 13, 2021





https://uploads.disquscdn.com/images/f9c91393fd05bd1df7bfb5c44fb1d440722925bf0df3a15c2f89719782869f1f.jpg
Hi,
I run the script several times, and my result show that xml run faster.
Any idea why ?
Regards
Sammy Vaknin