In the previous part of this article, we discussed how to import CSV files to SQL Server with the help of BULK INSERT statement. We discussed the main methodology of bulk insert process and also the details of BATCHSIZE and MAXERRORS options in scenarios. In this part, we will go through some other options (FIRE_TRIGGERS, CHECK_CONSTRAINTS and TABLOCK) of bulk insert process in various scenarios.
Scenario 1: Can we enable triggers in the destination table during the bulk insert operation?
By default, during the bulk insert process, the insert triggers which are specified in the target table are not fired, however, in some situations we may want to enable these triggers. A solution to this issue is to use FIRE_TRIGGERS option in bulk insert statements. I want to add a notice that this option can affect and decrease the bulk insert operation performance because trigger/triggers can make separate operations in the database. In the following sample, we will demonstrate this. At first, we will not set the FIRE_TRIGGERS parameter and the bulk insert process will not fire the insert trigger. In the following T-SQL script, we will define an insert trigger for the Sales table.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLog
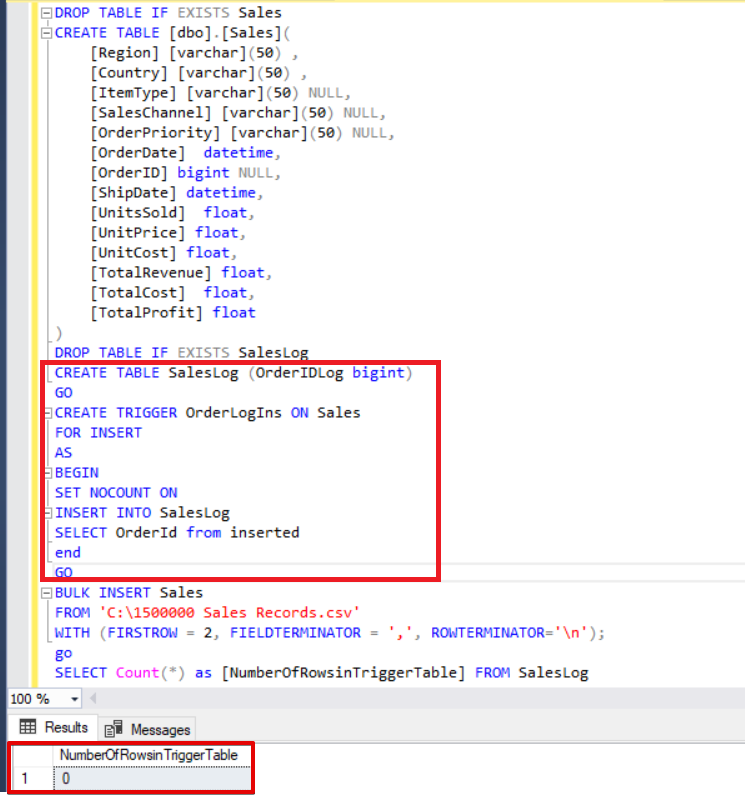
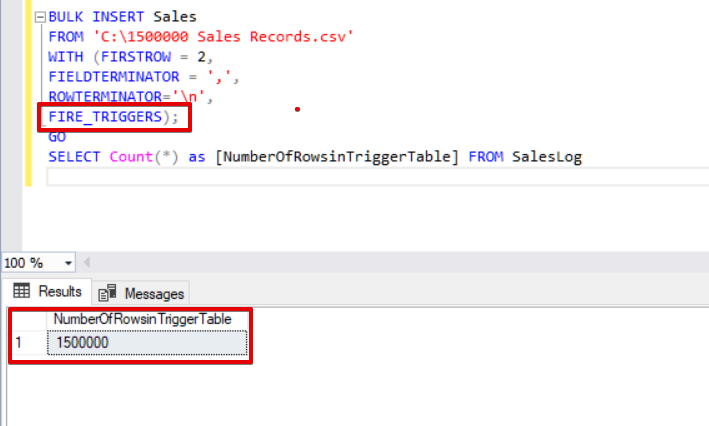
As you can see above, the insert trigger did not fire because we did not set the FIRE_TRIGGERS option. Now, we will add the FIRE_TRIGGERS option to the bulk insert statement so that this option enables to insert a fire trigger.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FIRSTROW = 2, FIELDTERMINATOR = ',', ROWTERMINATOR='\n', FIRE_TRIGGERS); GO SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog
Scenario 2: How can enable a check constraint during the bulk insert operation?
Check constraints allow us to enforce data integrity in SQL Server tables. The purpose of the constraint is to check inserted, updated or deleted values according to their syntax regulation. Such as, the NOT NULL constraint provides that a specified column cannot be modified by the NULL value. Now, we will focus on constraints and bulk insert interaction. By default, during bulk insert process any check and foreign key constraints are ignored, but this option has some exceptions. According to the Microsoft documentation “UNIQUE and PRIMARY KEY constraints are always enforced. When importing into a character column for which the NOT NULL constraint is defined, BULK INSERT inserts a blank string when there is no value in the text file.” In the following T-SQL script, we will add a check constraint to the OrderDate column which controls the order date greater than 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'
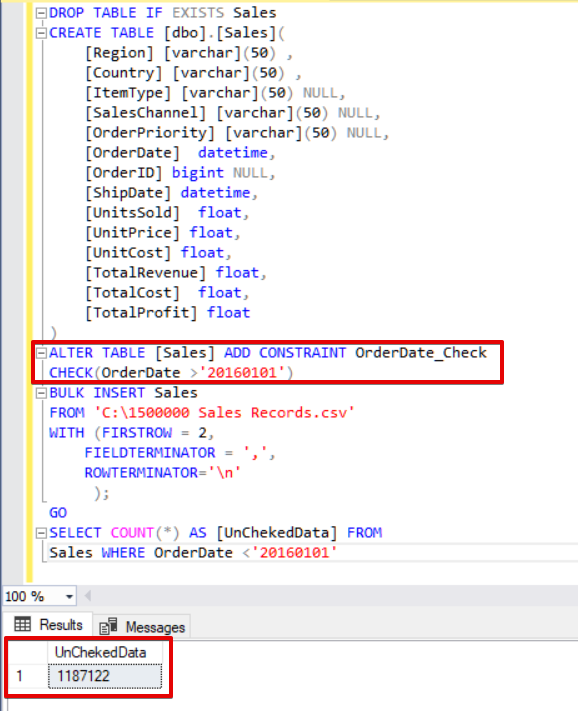
As you can see in the above sample, the bulk insert process skips the check constraint control. However, SQL Server indicates check constraint as not-trusted.
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'
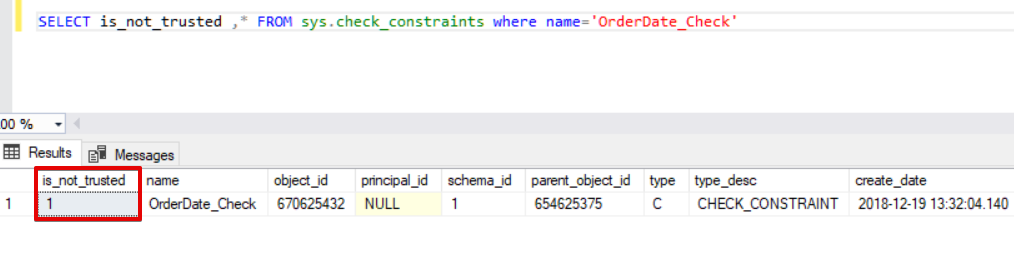
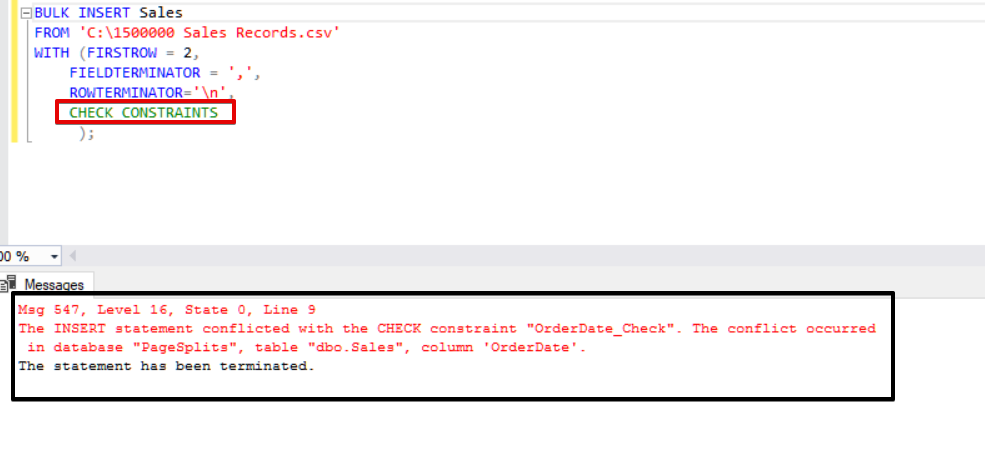
This value indicates that somebody inserted or updated some data to this column by skipping the check constraint, at the same time this column may contain inconsistent data with reference to that constraint. Now, we will try to execute the bulk insert statement with the CHECK_CONSTRAINTS option. The result is very simple, check constraint returns an error because of improper data.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
Scenario 3: How to increase performance in multiple bulk inserts into one destination table?
The main purpose of the locking mechanism in SQL Server is to protect and ensure the integrity of data. In the Main concept of SQL Server locking article, you can find details about lock mechanism. Now, we will focus on bulk insert process locking details. If you run the bulk insert statement without the TABLELOCK option, it acquires the lock of rows or table according to lock hierarchy. However, in some cases, we may want to execute multiple bulk insert processes against one destination table, so we can decrease the operation time of the bulk insert. At first, we will execute two bulk insert statements simultaneously and analyze the behavior of the locking mechanism. We will open two query windows in SQL Server Management Studio and run the following bulk insert statements simultaneously.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
When we execute the following dmv (Dynamic Management View) query, which helps to monitor the status of the bulk insert process.
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle) where text like '%BULK INSERT Sales%' and session_id <>@@SPID
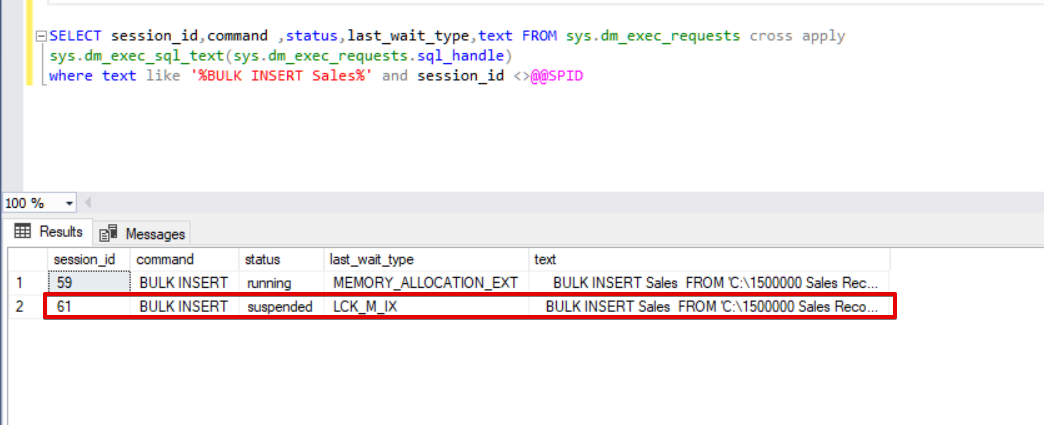
As you can see in the above image, session 61, the bulk insert process status is suspended due to locking. If we verify the problem, session 59 locks the bulk insert destination table and session 61 waits for releasing of this lock to continue the bulk insert process. Now, we will add the TABLOCK option to the bulk insert statements and execute the queries.
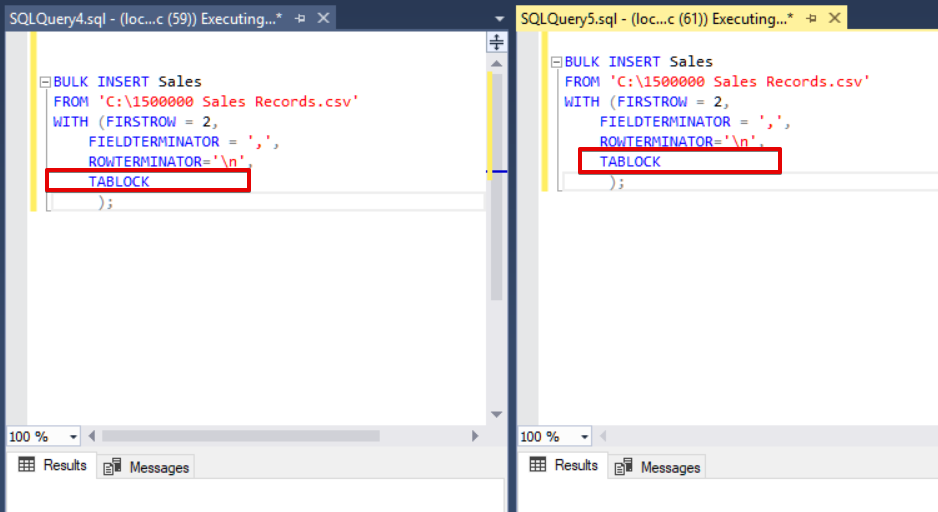
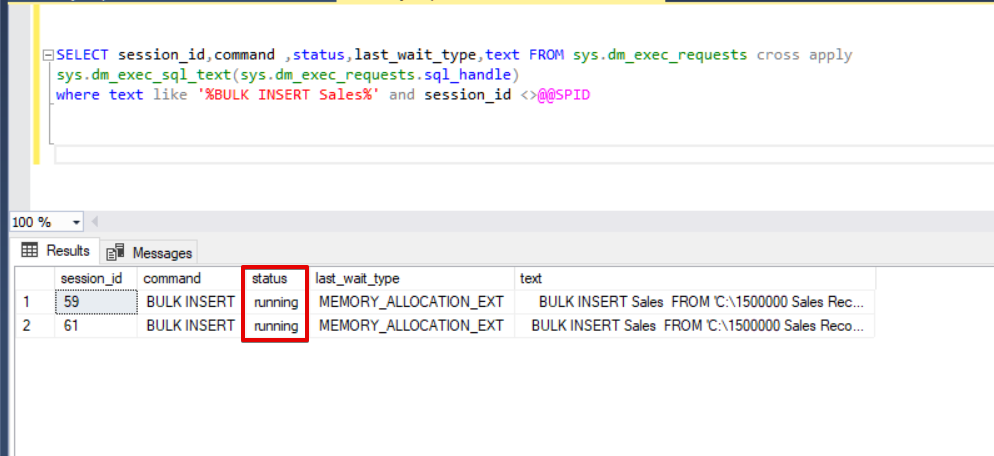
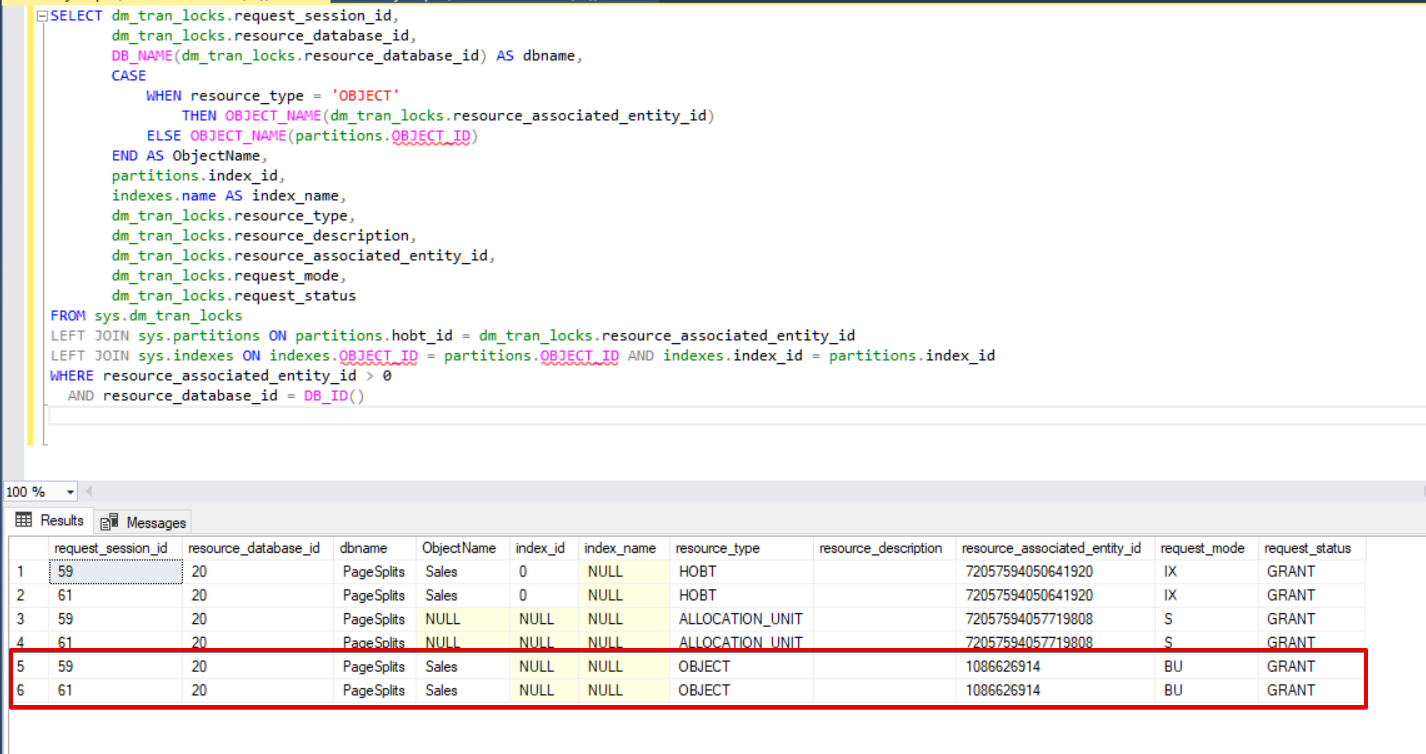
When we execute the dmv monitoring query again, we cannot see any suspended bulk insert process because SQL Server uses a special lock type called bulk update lock (BU). This lock type allows to process multiple bulk insert operations against the same table simultaneously and this option also decreases the total time of the bulk insert process.
When we execute the following query during the bulk insert process, we can monitor the locking details and lock types.
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()
Conclusion
In this article, we explored all details of bulk insert operation in SQL Server. Particularly, we mentioned BULK INSERT command and its settings and options, and we also analyzed various scenarios which are close to real life problems.
References
Prerequisites for Minimal Logging in Bulk Import
Controlling Locking Behavior for Bulk Import
Further Reading
Exporting Data to Flat File with BCP Utility and Importing data with Bulk Insert
Useful tool:
dbForge Data Pump – an SSMS add-in for filling SQL databases with external source data and migrating data between systems.
Tags: sql, sql server, t-sql, t-sql statements Last modified: September 22, 2021




