
COUNT is one of the common SQL Server Aggregate operations done by almost all SQL Server Developers for their day-to-day needs. In this article, we can understand the COUNT Aggregate function, other possibilities of using the COUNT operation, and other functions to perform complicated Data Aggregate requirements.
What Is Aggregate Function
Aggregate functions perform a calculation on a set of values and return a single value. They are deterministic i.e. they will return the same set of output values whenever executed on a set of input values. All Aggregate functions in SQL Server ignore NULL values except the COUNT function. The Aggregate functions syntax will be:
SELECT column_name, AGGREGATE_function_name()
FROM table_name
GROUP BY column_name
HAVING column_name = 'some_condition' -- optional
ORDER BY column_name – optionalIf there is no column_name fetched in the SELECT clause, the GROUP BY clause is optional:
SELECT AGGREGATE_function_name()
FROM table_nameSQL Server supports lots of Aggregate functions like COUNT, MIN, MAX, SUM, AVG, COUNT_BIG, STDEV, and several other functions requiring a column name inside the Aggregate function call.
COUNT Aggregate Function
The COUNT Aggregate function is used to count the number of records in the set of input values supplied to the function and return the value as an int datatype. One special feature about the COUNT function is that it will include the NULL values in the input set of values provided (excluding certain scenarios which we will explore in this article). The syntax of the COUNT function is:
COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
And with Analytic function OVER, syntax would be
COUNT ( [ ALL ] { expression | * } ) OVER ( [ <partition_by_clause> ] ) Across both the syntaxes, the ALL keyword is the default behavior if DISTINCT or expression isn’t specified.
To count the number of records in a table let’s say Person.Person in AdventureWorks database, we can use the below Syntax.
SELECT COUNT(*)
FROM Person.Person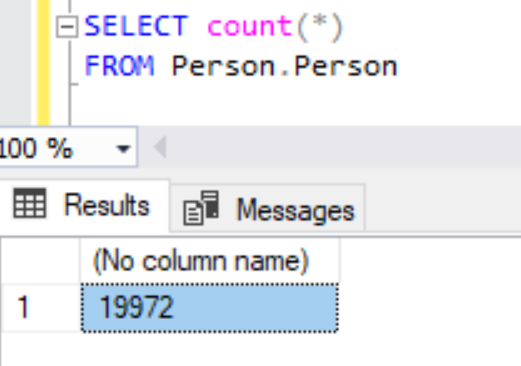
Myth: COUNT (*) vs COUNT (1) which one is faster
Personally, I’ve seen a lot of developers complaining that COUNT (*) is slower than COUNT (1) and vice versa, but it is a common myth about COUNT (*) vs COUNT (1). Let’s quickly debunk that myth with the Person.Person table itself by executing both COUNT (*) and COUNT (1) on Person.Person table.
SELECT COUNT(*)
FROM Person.Person
SELECT count(1)
FROM Person.Person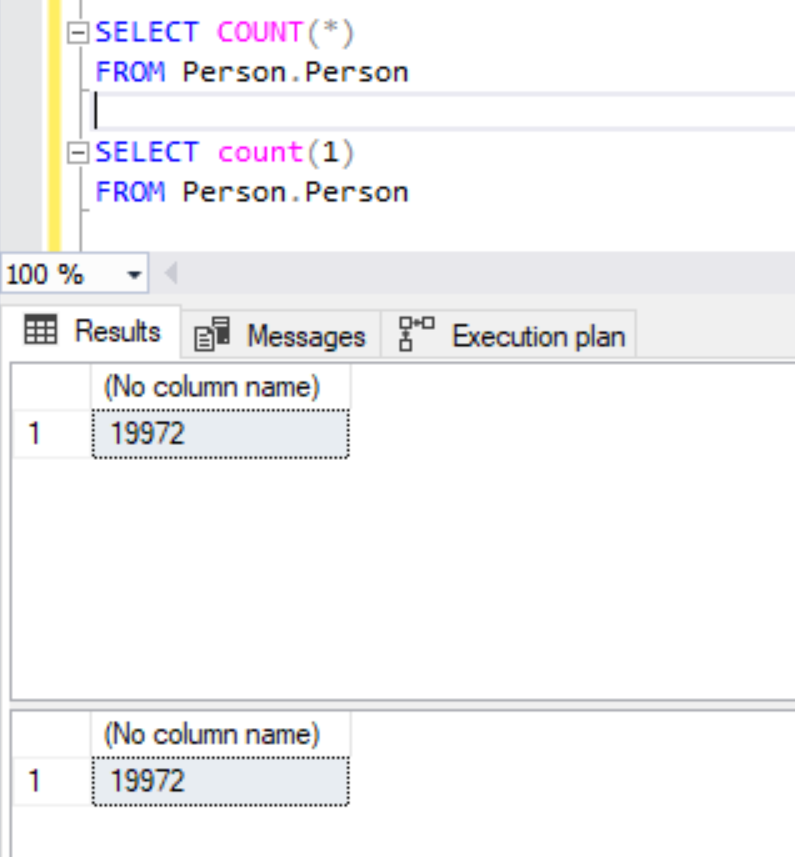
Executing both queries returned the same result. Let’s verify the Execution Plan to compare their performance.
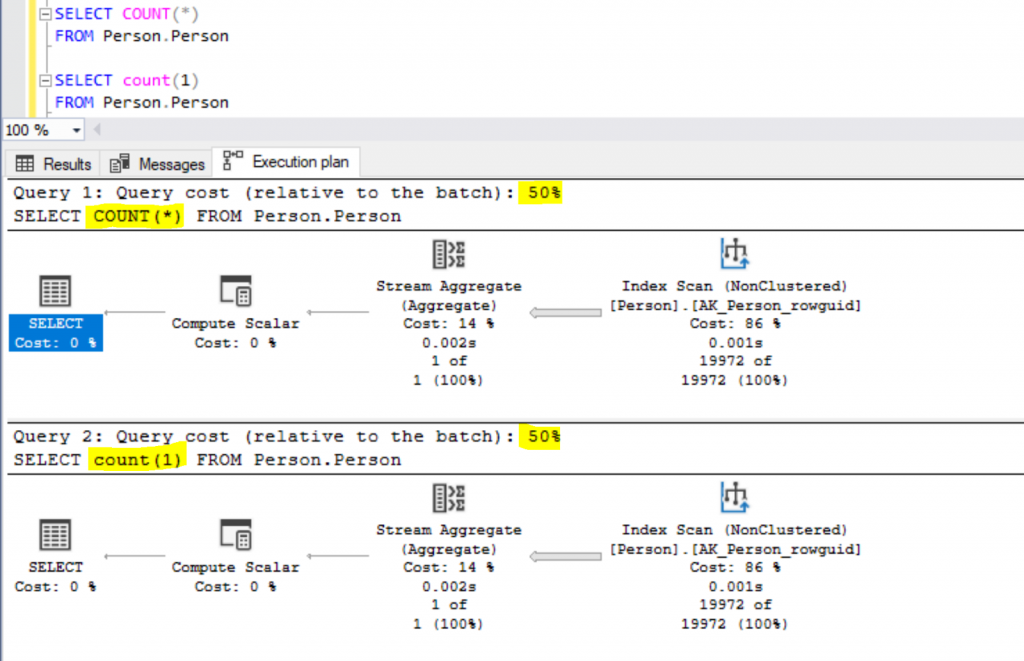
Both queries performed equally and internally used the same Index Scan along with Stream Aggregate and Compute Scalar operation to fetch the results and both of them took 50% time to execute. So, this confirms that both COUNT (*) and COUNT (1) perform equally in terms of execution time or internal operations.
COUNT and NULL VALUES
Earlier, we saw that COUNT is the only operation that will include NULL values excluding certain scenarios and we can verify this one with the same example by changing from Results to Grid to Results to Text option and executing the below query.
SELECT COUNT(*) Total_Records
FROM Person.Person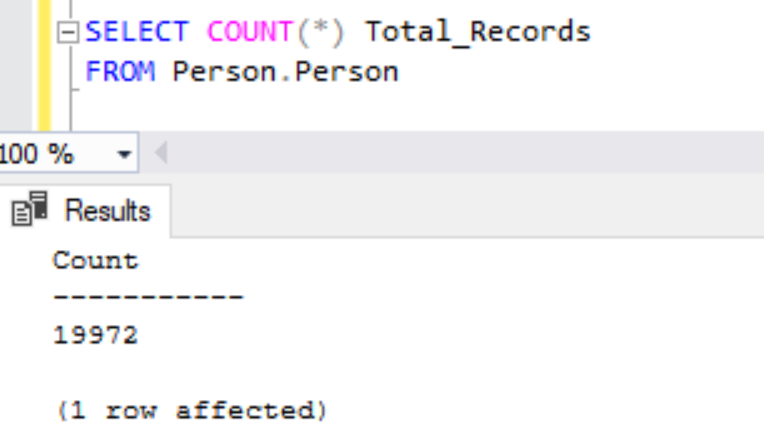
Let’s try using the MAX() option to find out the Maximum Title value from Person.Person table as shown below.
SELECT MAX(Title) MAX_Title
FROM Person.Person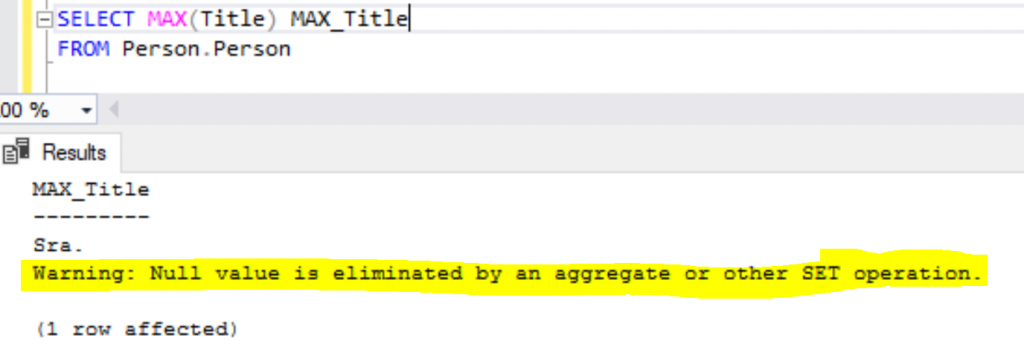
As we can see, the MAX function eliminated all NULL values present in the Nullable column Title before performing the Aggregate operation.
Let’s verify the COUNT function on a NOT NULL column named FirstName and a NULL column named Title and see the difference.
SELECT COUNT(FirstName) Total_FirstName
FROM Person.Person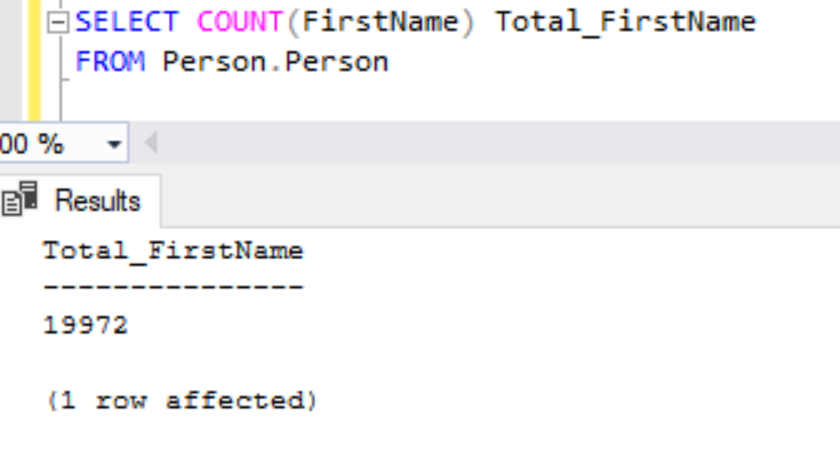
We haven’t received any warnings about excluding NULL values since the column doesn’t allow NULL values.
SELECT COUNT(Title) Total_Title
FROM Person.Person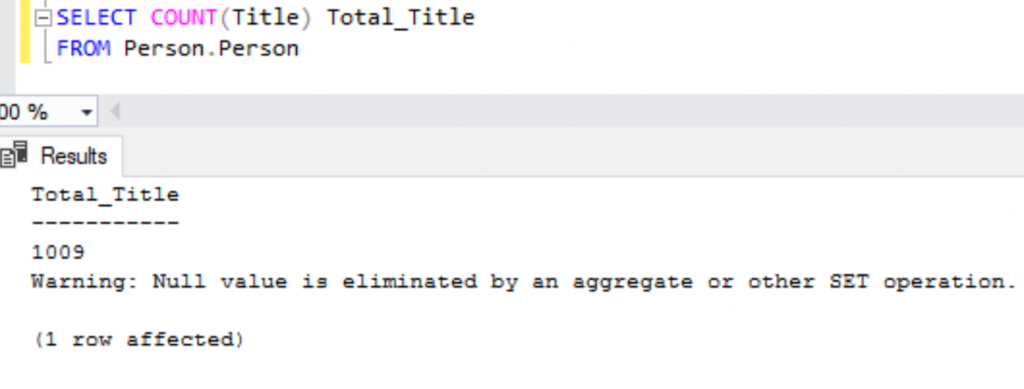
Here, we have received a warning.
To Summarize,
- COUNT (*) or COUNT (1) will always include NULL values present in the table records.
- COUNT on NOT NULL columns will match with the COUNT (*) or COUNT (1) values since there is no NULL values.
- COUNT on NULL able columns will ignore the NULL values and give the count of records only having values excluding NULL records.
Hence, we should be careful while using COUNT (*) or COUNT (1) or COUNT (column_name) as it might have slightly varying values based upon the Nullable values.
COUNT DISTINCT Records
Till now, we have counted all records in the table or the records from the SELECT query including Duplicate values. To count only the unique values within the SELECT query result set, we can use the DISTINCT clause together with the COUNT function.
Let’s first count the FirstName values from the table using the below query.
SELECT COUNT(FirstName) Total_FirstName
FROM Person.Person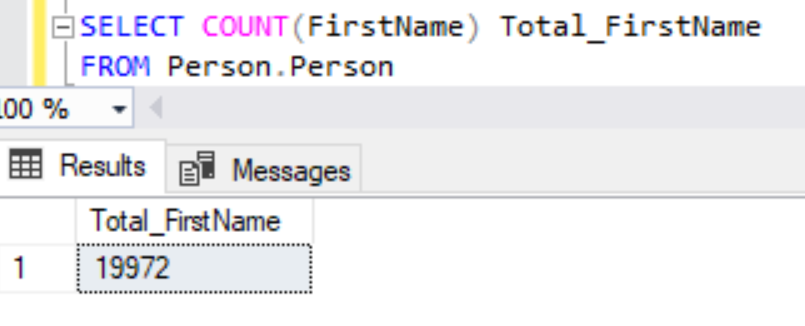
Let’s verify the unique FirstName values in the table by executing the below query.
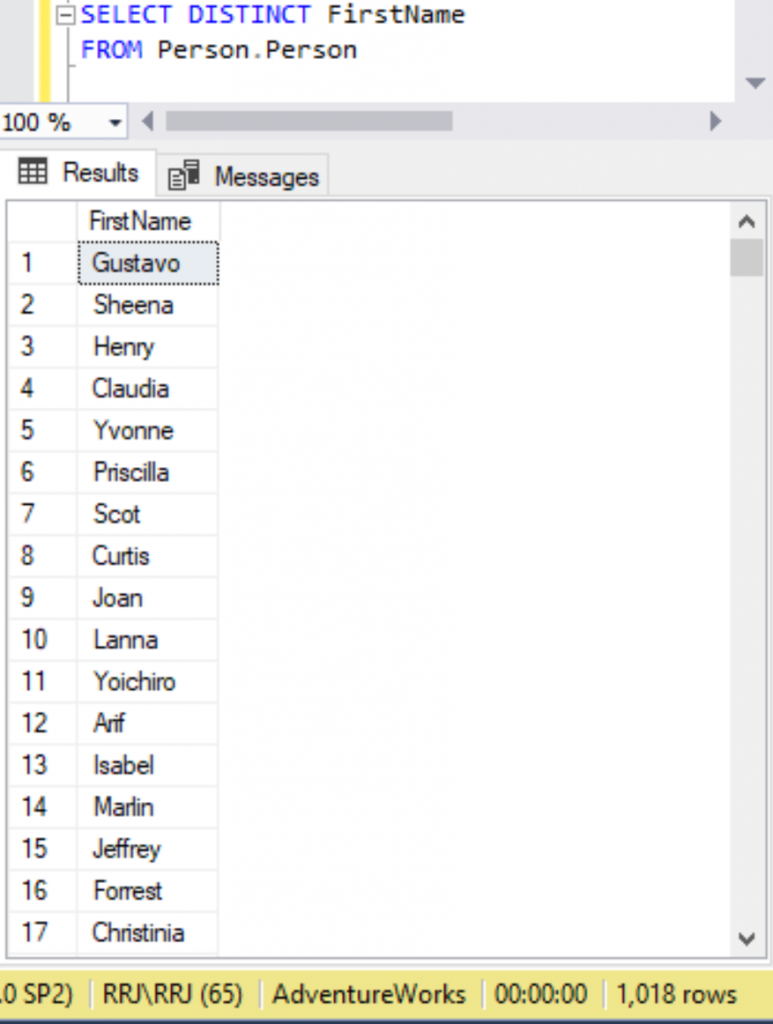
Selecting unique FirstName values fetched around 1018 values and let’s try combining the DISTINCT Clause and COUNT function by executing the below query.
SELECT COUNT(DISTINCT FirstName) Distinct_FirstName
FROM Person.Person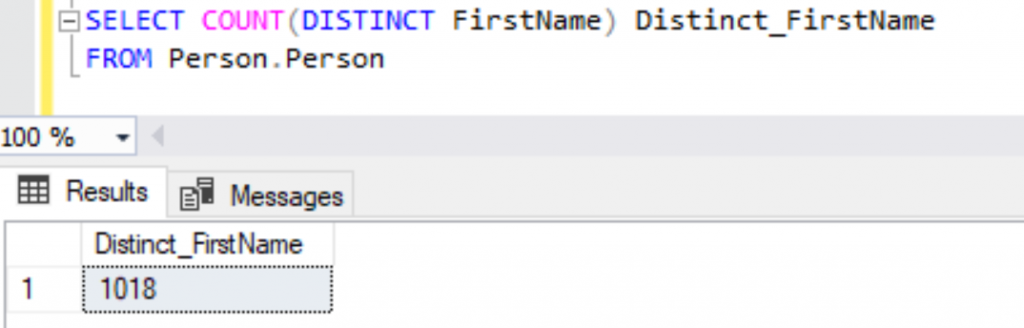
We have successfully obtained the Count of Unique FirstName values from the SELECT query and if we need to fetch any other column in the SELECT clause, we might need to use the GROUP BY Clause.
COUNT with the GROUP BY Clause
In our earlier example, we identified the count of unique values but we aren’t sure about the distribution of duplicate data like which FirstName is most commonly or least commonly occurring. In order to do the detailed analysis or fetch a few columns in the SELECT query along with the COUNT function, then we need to use the GROUP BY Clause as shown below.
SELECT FirstName, COUNT(*) Records_Count
FROM Person.Person
GROUP BY FirstName
ORDER BY 2 DESCBased upon the above results, we can realize that the FirstName value Richard is most repeating for around 103 persons and the distribution of duplicates for detailed analysis.
Similarly, we can add any number of columns in the SELECT clause and in the GROUP BY clause to see the distribution of records. We can add the HAVING clause to filter out more records based upon the COUNT (*) function as shown below.
SELECT FirstName, COUNT(*) Records_Count
FROM Person.Person
GROUP BY FirstName
HAVING COUNT(*) > 95
ORDER BY 2 DESC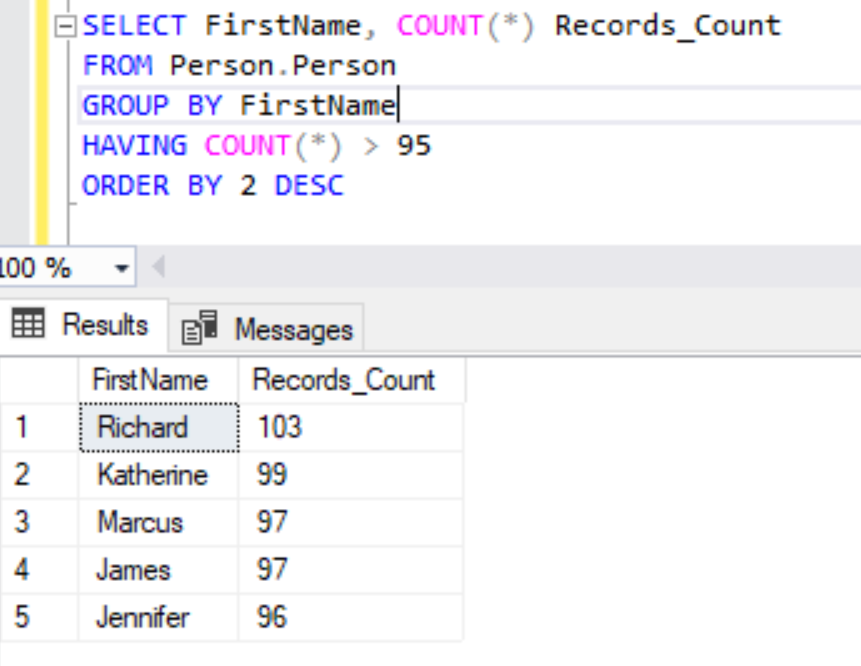
COUNT with CASE Clause
Without using the COUNT function, we can also COUNT the number of records in a matching criterion by using the SUM function and CASE statement combination as well. To count the no. of records based upon Title values equals or not equals Mr. then we can use the below construct.
SELECT FirstName
, SUM(CASE WHEN Title = 'Mr.' THEN 1 ELSE 0 END) Male_Count
, SUM(CASE WHEN Title <> 'Mr.' THEN 1 ELSE 0 END) Female_Count
FROM Person.Person
GROUP BY FirstName
ORDER BY 2 DESC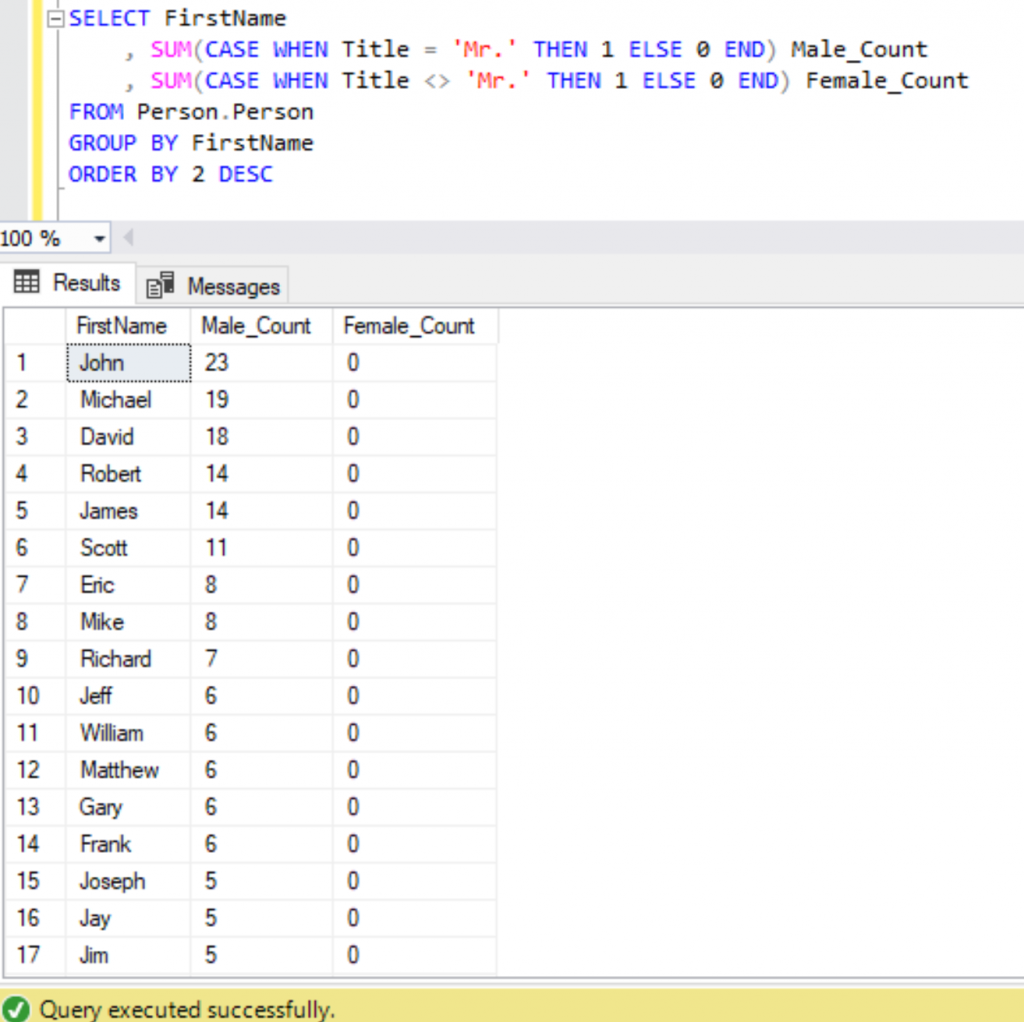
COUNT with OVER Clause
Similar to all other Aggregate functions, we can also use the OVER clause together with the COUNT function as well. While using the OVER clause, adding the GROUP BY clause is optional. To count the number of records matching a particular Title, we can execute the below query.
SELECT Title, Count(*) OVER (Partition BY Title) Title_Count
FROM Person.Person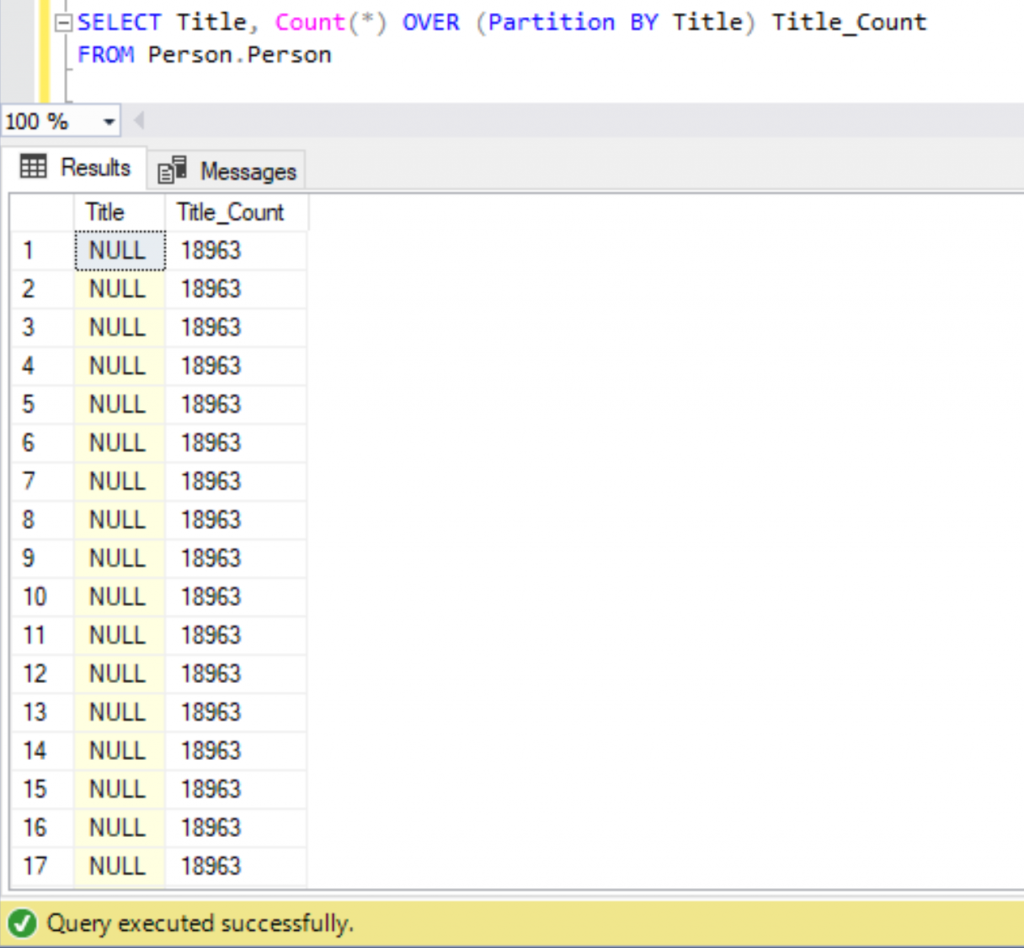
We can see around 19972 records matching the number of records present in Person.Person table and to find out the unique values, let’s add a DISTINCT clause as shown below.
SELECT DISTINCT Title, Count(*) OVER (Partition BY Title) Title_Count
FROM Person.Person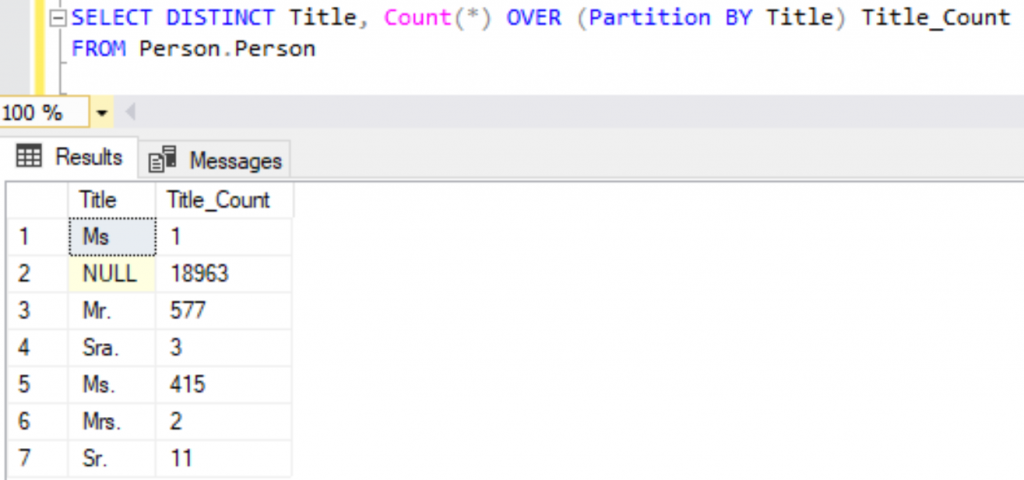
We can fetch any number of columns without worrying about using the GROUP BY clause and achieve any Aggregate logic implemented in our query results using the OVER() clause.
COUNT_BIG () Function
In SQL Server 2012, COUNT_BIG () function was introduced which operates similar to COUNT () function with a single difference which is COUNT () function by default returns the values as an integer data type whereas COUNT_BIG () function returns values as bigint datatype. Using COUNT () function supports a maximum value of 2,147,483,647 (2^31 -1) whereas COUNT_BIG () function supports a maximum value of 9,223,372,036,854,775,807 (2^63-1).
Conclusion
Today, we have seen the functionality of COUNT () and explored various possible combinations we can use COUNT () function with several other constructs like DISTINCT, GROUP BY, HAVING, CASE, and OVER clauses to view the count of complicated records more easily. We have also gone through the myth of COUNT (*) versus COUNT (1) and learned that they both behave equally in terms of performance. Finally, we have explored the COUNT_BIG () function and how to use it whenever the number of records in the result exceeds the integer data type limit and falls under bigint data type. SQL Complete is an advanced IntelliSense-style code completion add-in for SSMS and VS that allows you to show different aggregate functions of the selected range of values on the fly in the SSMS Results grid. Let’s meet up again with another interesting article.
Last modified: October 13, 2022



