“What is the difference between a primary key constraint and a unique key constraint?”
This is probably the most frequently-asked job interview question for database developers. In this article, we will try to answer it.
Let’s start by looking at what primary and unique keys are, as well as at their similarities.
Primary Key
A primary key is used to uniquely identify each record in the table. Each table must have at least one primary key. To define a primary key in SQL server, you would simply need to use the keywords ‘Primary Key’ after the column’s name.
Unique Key
A column with a unique key constraint can only contain unique values – this is the result of the unique key prohibiting duplicate values to be stored inside a column.
To define a unique key, you have to append ‘Unique’ to the name of the field. Please keep in mind that it’s not mandatory to have a Unique key in a table.
Example of Creating Primary and Unique Keys
The following script creates a ‘Test’ database which contains one table called ‘Cars’.
This table will have a primary key column named ‘ID’ and a unique key column named ‘NumberPlate’.
CREATE DATABASE TEST
GO
USE TEST
GO
CREATE TABLE Cars (
ID int PRIMARY KEY,
Name varchar(255) NOT NULL,
NumberPlate varchar(255) UNIQUE,
Model int
);
Next, let’s add a few dummy records to our ‘Cars’ table. Execute the following script:
INSERT INTO Cars VALUES (1, 'Toyota', 'ABC 123', 199), (2, 'Toyota', 'ABC 345', 207), (3, 'Toyota', 'ABC 758', 205), (4, 'Toyota', 'ABC 741', 306), (5, 'Toyota', 'ABC 356', 124)
Before we talk about the differences, let’s first look at the similarities between primary and unique keys.
Similarities between Primary and Unique Keys
- Columns with primary or unique keys cannot have duplicate values.
Let’s try to add a new record with an ID value of 2 (which already exists) to the ‘Cars’ table. Execute the following script:
INSERT INTO Cars VALUES (2, 'Toyota', 'ABC 345', 356)
When you execute the script above, the following error will be displayed:

The error clearly says that this statement violates the primary key constraint and that duplicate values cannot be inserted into the primary key column.
Similarly, let’s try to insert a duplicate value into the ‘NumberPlate’ column with a unique key constraint by using the following query:
INSERT INTO Cars VALUES (6, 'Toyota', 'ABC 345', 356)
This time, you will see that there is a violation of the unique key constraint since the value ‘ABC 345’ already exists in the ‘NumberPlate’ column which has a unique key constraint. The error message will look like this:

- Since both primary key and unique columns do not accept duplicate values, they can be used for uniquely identifying a record in the table. This means that, for each value in the primary or unique key column, only one record will be returned.
Differences between Primary and Unique Keys
Now that we understand the similarities between primary and unique keys, let’s take a look at their differences.
- A table can only have one primary key, but multiple unique keys.
The following example will help us understand this better.
Inside the ‘Test’ database we made earlier, let’s create a new ‘Cars2’ table with two primary keys. To do this, execute the following script:
CREATE TABLE Cars2 (
ID int PRIMARY KEY,
Name varchar(255) NOT NULL,
NumberPlate varchar(255) UNIQUE,
Model int PRIMARY KEY
);
In the script above, we set primary key constraints on the ID and Model columns. However, since only one column in a table can have a primary key constraint, you will see the following error:

This error message clearly informs us that a table cannot have multiple primary key constraints.
Now, let’s add multiple unique key constraints to the ‘Cars2’ table. Take a look at the following script:
CREATE TABLE Cars2 (
ID int PRIMARY KEY,
Name varchar(255) NOT NULL,
NumberPlate varchar(255) UNIQUE,
Model int UNIQUE
);
This allows us to add unique key constraints on the ‘NumberPlate’ and ‘Model’ columns. Since a table can have multiple columns with unique key constraints, you will not see any error messages when executing the above script.
- The primary key column cannot have null values while the Unique Key column can have one null value.
Let’s see this in action. First, let’s add a record with a null value to a primary key column in the ‘Cars’ table. Look at the script below:
INSERT INTO Cars VALUES ( null, 'Toyota', 'ABC 345', 356)
You can see that this script inserts null as a value into the ID column. When you execute it, you should see the following error in the output message window:
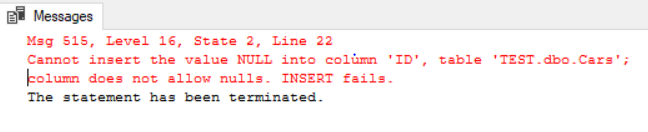
The error tells us that a null value cannot be inserted as the primary key column doesn’t allow null values.
Let’s now try to add null values to the ‘NumberPlate’ unique key column. To do this, execute the following script:
INSERT INTO Cars VALUES ( 6, 'Toyota',null, 356)
This adds a new record with an ID value of 6 and null value to the ‘Cars’ table – specifically, the null value is assigned to the ‘NumberPlate’ column. You will see that the above script will execute be executed without errors since the unique key column can accept null values by default.
To verify if the null value has actually been inserted into the ‘NumberPlate’ column, we will need to select all records from the ‘Cars’ table by using the following script:
SELECT * FROM Cars
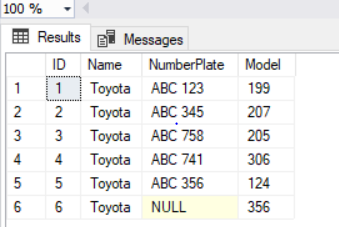
In the result set above, we can clearly see that the primary key column ‘ID’ doesn’t contain any null values. On the other hand, the ‘NumberPlate’ column with a unique key constraint does contain a null value that we just inserted. Remember, you cannot add more than one null value to a unique key column since the second null value will be the duplicate of the first one – and duplicates are not allowed.
- By default, a unique clustered index is created on the primary key column; on the other hand, a unique non-clustered index is created on the unique key column.
To see the indexes on the ‘Cars’ table, execute the following script:
USE TEST GO sp_help Cars
In the output, you will see details of the ‘Cars’ table including the indices as shown in the figure below:

From the figure above, you can see that the ‘NumberPlate’ column has a non-clustered unique index while the ID column has clustered unique index.
Conclusion
Despite a few basic similarities, primary and unique keys have significant differences. You can only have one primary key per table, but multiple unique keys. Similarly, a primary key column doesn’t accept null values, while unique key columns can contain one null value each. And finally, the primary key column has a unique clustered index while a unique key column has a unique non-clustered index.
Tags: sql, sql constraints Last modified: September 22, 2021





