
How to Set up Drill Through in Power BI Report
The Power BI Drill-through feature allows us to dig deeper into the data and get detailed...

Power BI Slicers: Tutorial with Examples [2022]
Power BI is a data analytics and interpretation tool developed by Microsoft. With Power BI, you can create various types of static and...

How to Create Paginated Report in Power BI: Definitive Tutorial
In this article, you will see how to create paginated reports using the Power BI Report Builder tool from Microsoft. You will also see how...

Troubleshooting Issues when Working with Date and Time in SQL Server
The Microsoft SQL Server database stores the date and time information in a variety of formats. The...

Converting DateTime to YYYY-MM-DD Format in SQL Server
An SQL Server database can store a variety of data types, such as numbers, text strings, Boolean values, dates, etc. However, storing and...
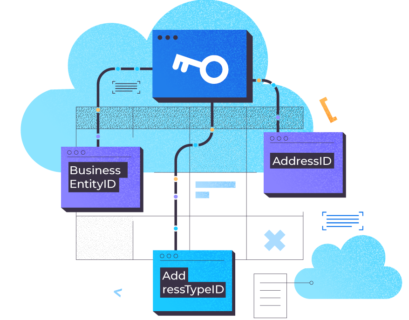
How to Create a Table with Multiple Foreign Keys and Not Get Confused
Understanding Table Relations SQL server adds foreign keys to implement relations between tables in a relational database. A table can have...
9 Best Practices for Writing SQL Queries
If you are reading this article, most probably, you are already familiar with SQL. You know how to...

How to Download and Install SQL Server Express Edition?
SQL Server is Microsoft’s premier database management system that we can use to develop relational databases. It also offers support for...

How to Easily Get Data from Web Source Using Power BI Rest API Calls
Microsoft Power BI is a data visualization and analytics tool which lets you create powerful visualizations with a graphical user...

Power BI REST API No Code Options for Easy Data and Reports Download
Microsoft’s Power BI REST API no-code option is extremely helpful as it allows calling Power...


