In the software programming world, there are several approaches used by developers that help them with effortless software development. Design patterns, object-oriented programming, test driven development are some of them. If we particularly mention the code reuse; “Reuse of a typed code. It is written once and can be used in most places. It is a basic concept of software engineering. It is a structure necessary for modular programming. ”
For this reason, user-defined functions in SQL Server help us to avoid rewriting of T-SQL queries. At the same time, they improve code readability. In this post, we will discuss the pros and cons (advantages and disadvantages) of the traditional and natively compiled scalar user-defined functions and make a simple performance test.
Scalar-valued user-defined functions
SQL Server User Defined Function can be described as a programmed routine which makes calculations and returns results of the calculations. But if you use a scalar-valued user-defined function in your queries, you need to be aware of the negative effect on performance. The main reason for this performance issue is the row-by-row processing. If you use scalar user-defined functions in a large number of rows, most probably it will damage the query performance. SQL Server invokes scalar valued user-defined functions for each row. Now we will prove this mechanism. For this, we will create extended events in SQL Server to capture a number of the scalar-valued user-defined functions invoked.
We want to get square of InvoiceLines table LineProfit values in the WideWorldImporters database. We will use the following query for this purpose. This query will create a simple scalar user-defined functions.
CREATE Function [dbo].[GetSquare] (@Val AS FLOAT) RETURNS FLOAT AS BEGIN DECLARE @Ret AS FLOAT SELECT @Ret=SQUARE (@Val) RETURN @Ret end
After this step, we will create an extended event in SQL Server for monitoring the scalar valued user defined function behavior.
Click the Extended Events node and select New Session Wizard.
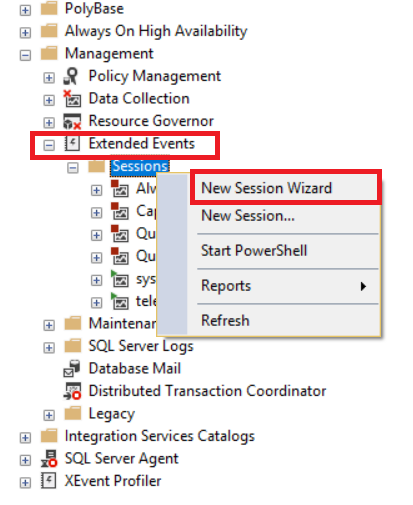
In the Session name text box, provide a name for Extended Events.
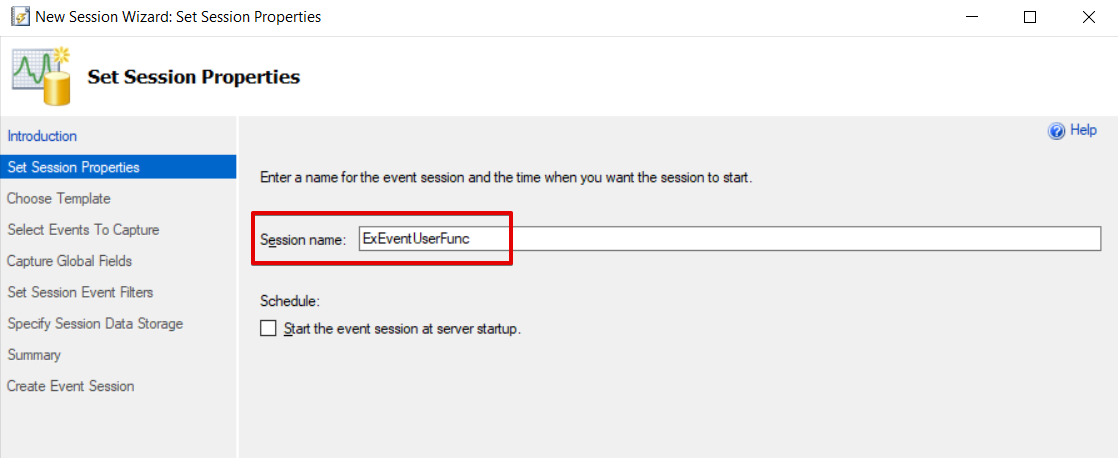
Chose Do not use a template and click Next.
Find module_end event in the Event library and add it to the selected events. Click Next.

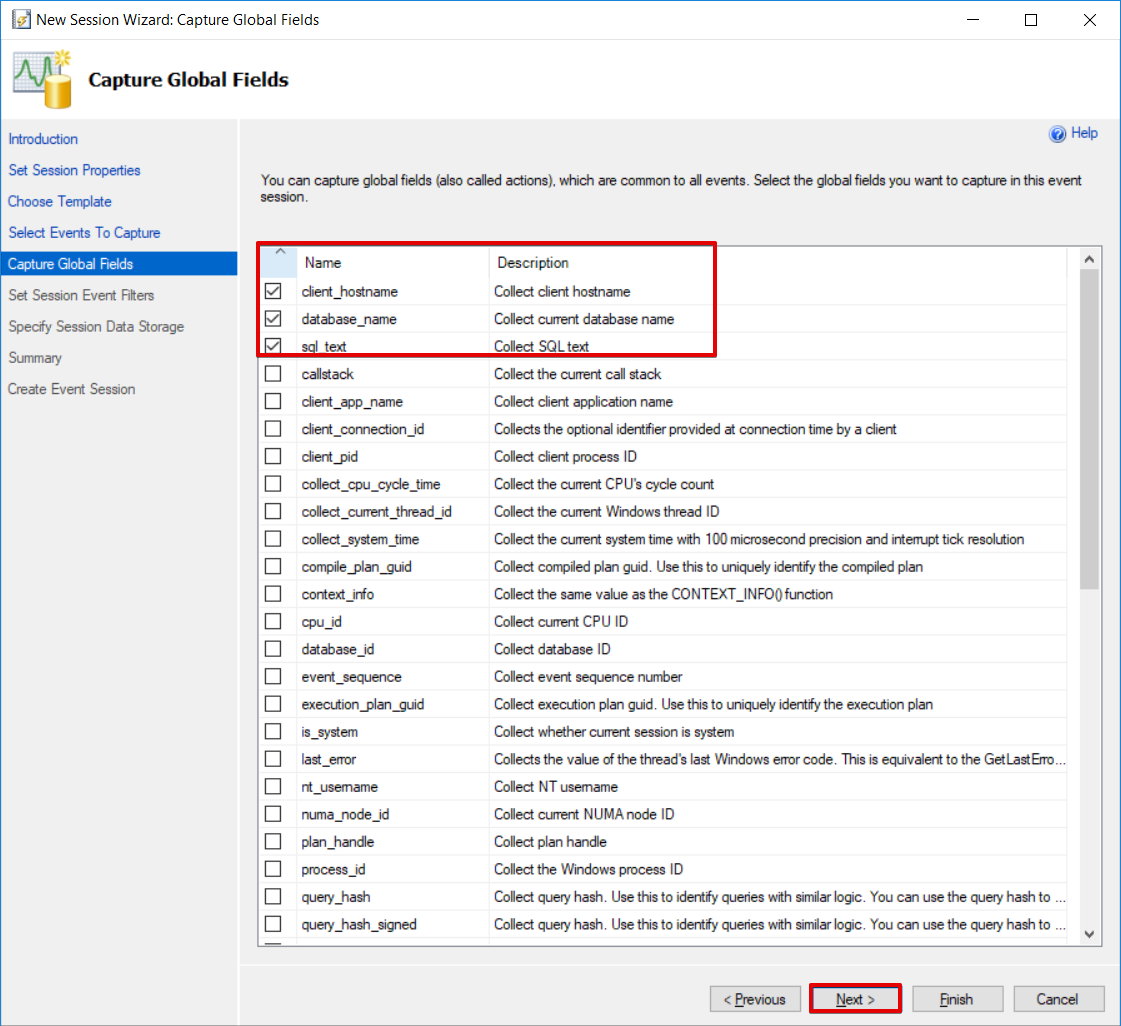
Check client_hostname, database_name, and sql_text and then click Next.
Set the WideWorldImporters database as a filter for the extended events.
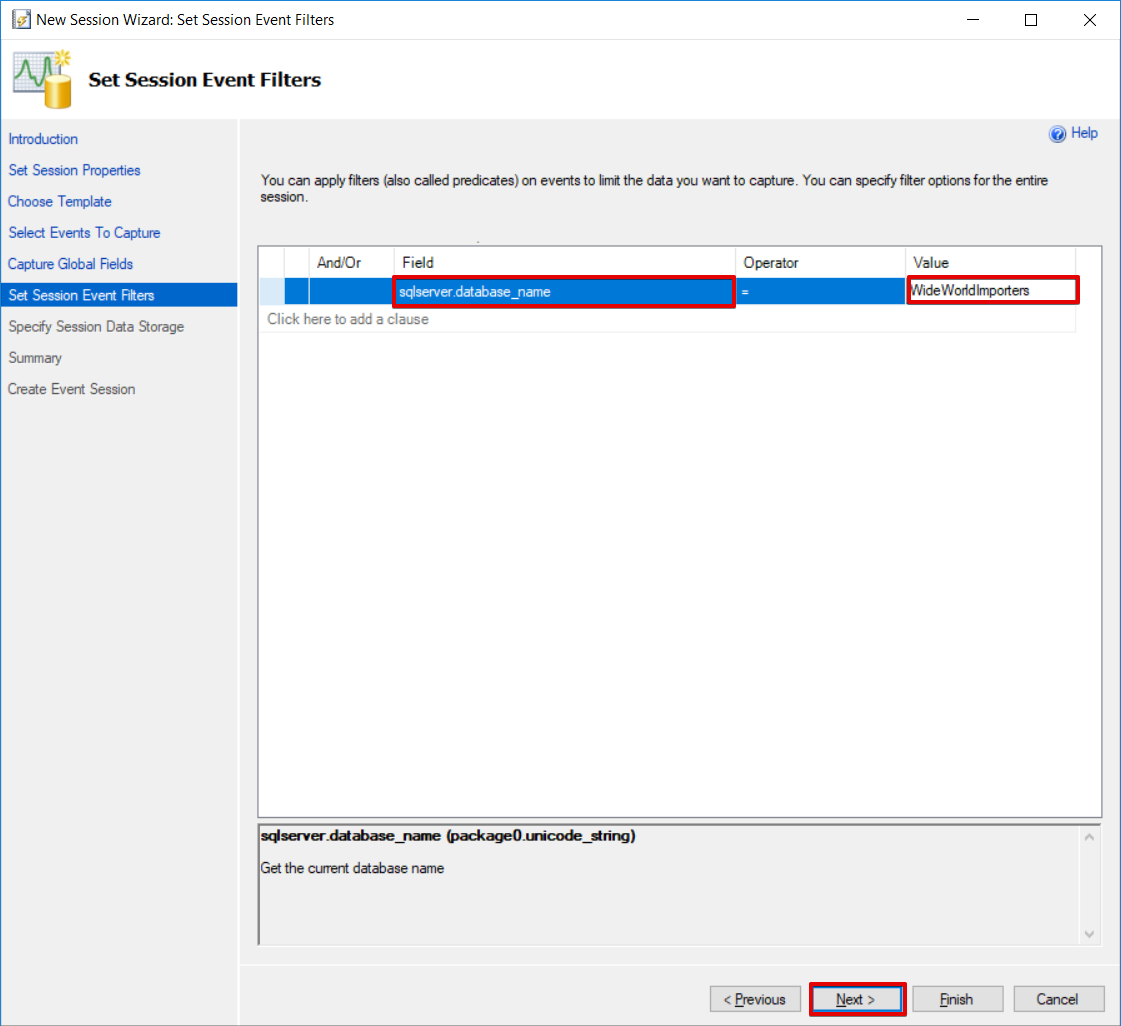
Click Finish.
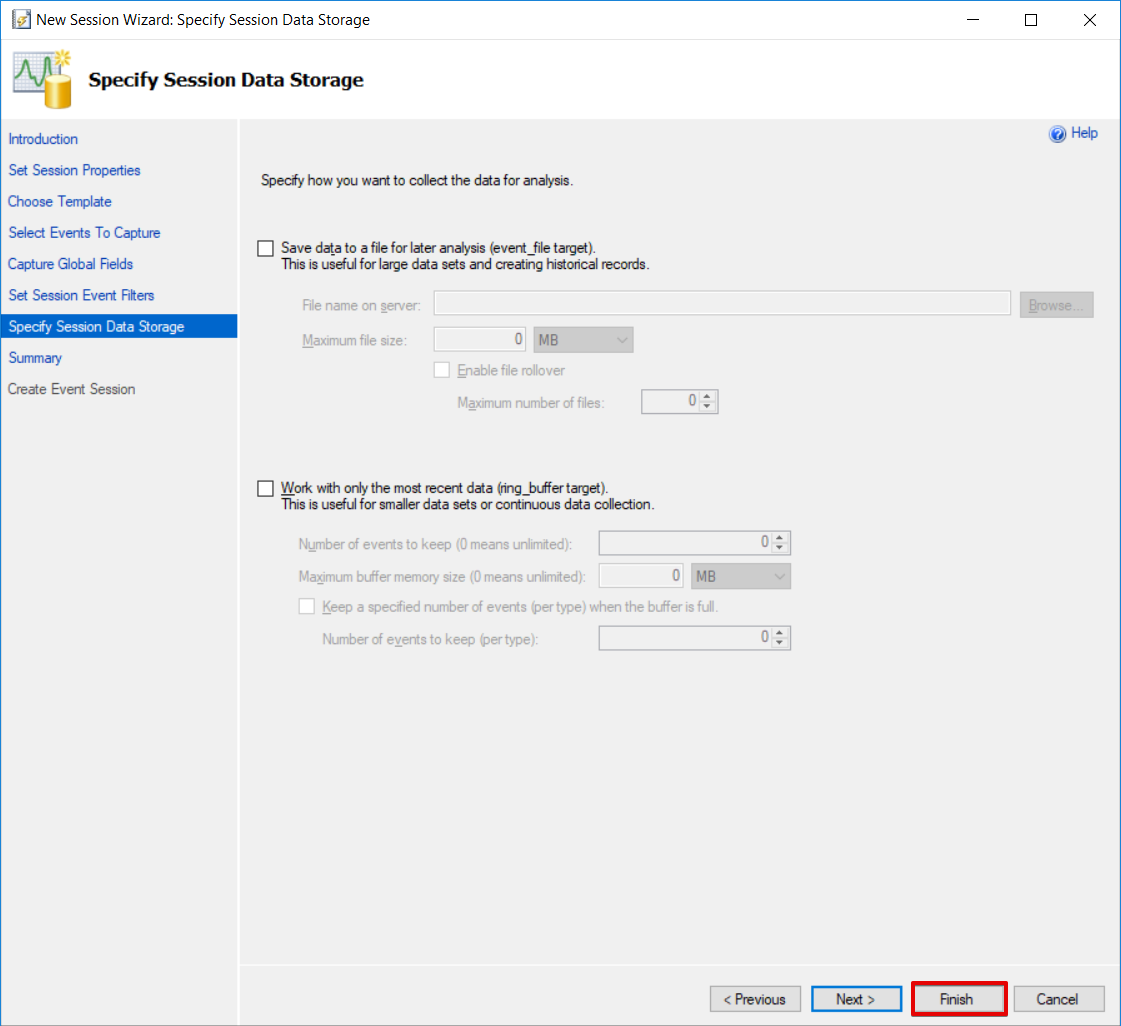
Check Start the event session immediately after session creation and Watch live data on screen as it is being captured. Click Close.
Execute the following query in the query tab.
SELECT dbo.GetSquare(LineProfit),* FROM [Sales].[InvoiceLines]
When we analyze the extended event screen we can see several events and each event row represents the same event which is GetSquare scalar valued user-defined function.

As we mentioned at the beginning of this section, SQL Server invokes the scalar-valued user-defined function row by row and this methodology can damage query performance. I would like to add an interesting note about the execution plan of this query. The Scalar Function is represented by the Compute Scalar operator. When clicking the Compute Scalar operator in the execution plan, it shows Number of Executions as 1.
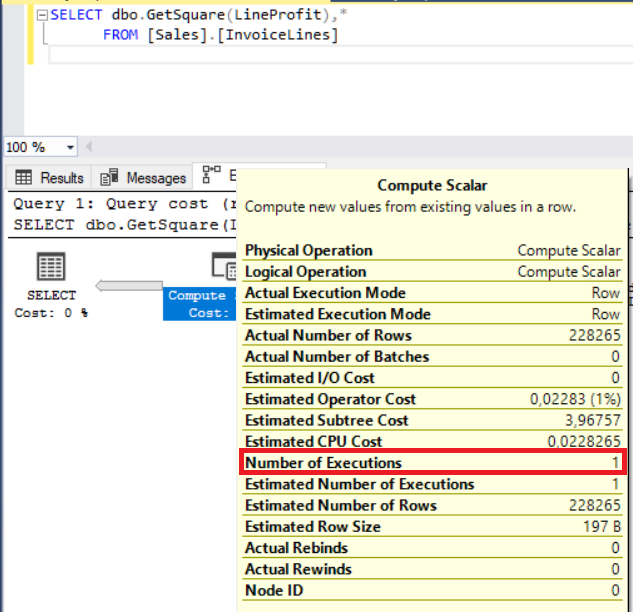
Scalar functions are executed in a separate context. For this reason, SQL Server Query Optimizer can make some wrong estimations and create poor quality execution plans.
Natively compiled scalar-valued user-defined functions
Microsoft added a new feature to SQL Server 2016 known as natively compiled user-defined functions. Natively compiled functions can only be accessed in-memory tables. At the same time, natively compiled functions provide string formatting or date manipulation are the parameters of the user-defined function. In this section, we will look at the details of scalar-valued used defined functions and benchmark performance of traditional scalar function versus natively complied scalar function.
Natively compiled scalar user-defined functions are used in native compilation, converts T-SQL to DLL and use this DLL in runtime. It can be created like the below query.
CREATE FUNCTION dbo.DateDiffDayMem (@DateInput DATETIME) RETURNS INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'English') RETURN DATEDIFF(DAY,GETDATE(),@DateInput) END GO
When we execute this query, SQL Server creates a DLL file which can be used in run time. We can find this DLL path in the following query.
SELECT name,description FROM sys.dm_os_loaded_modules WHERE description = 'XTP Native DLL' order by name
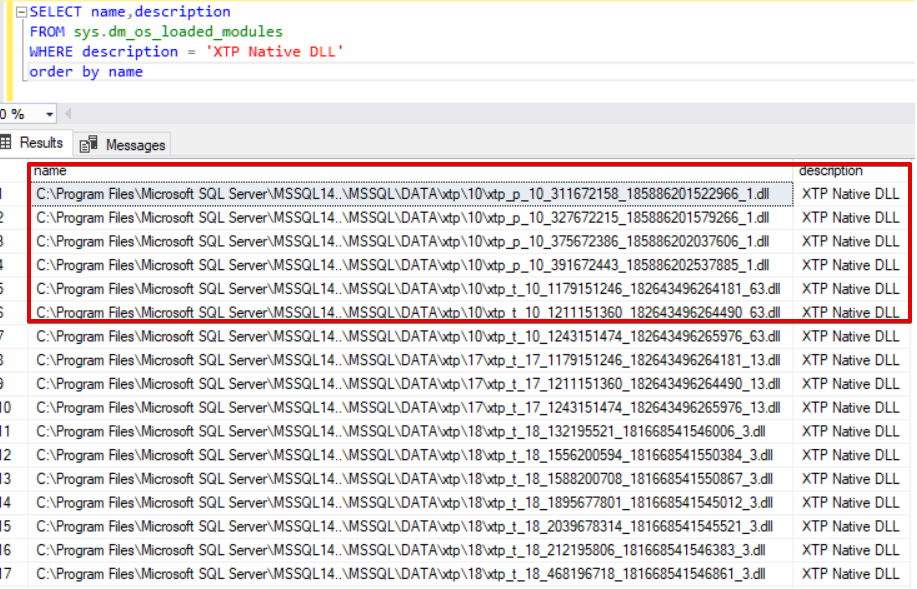
When we open the path of DLL files we can find the source code of DLL. When we open C source files we can find out C codes.

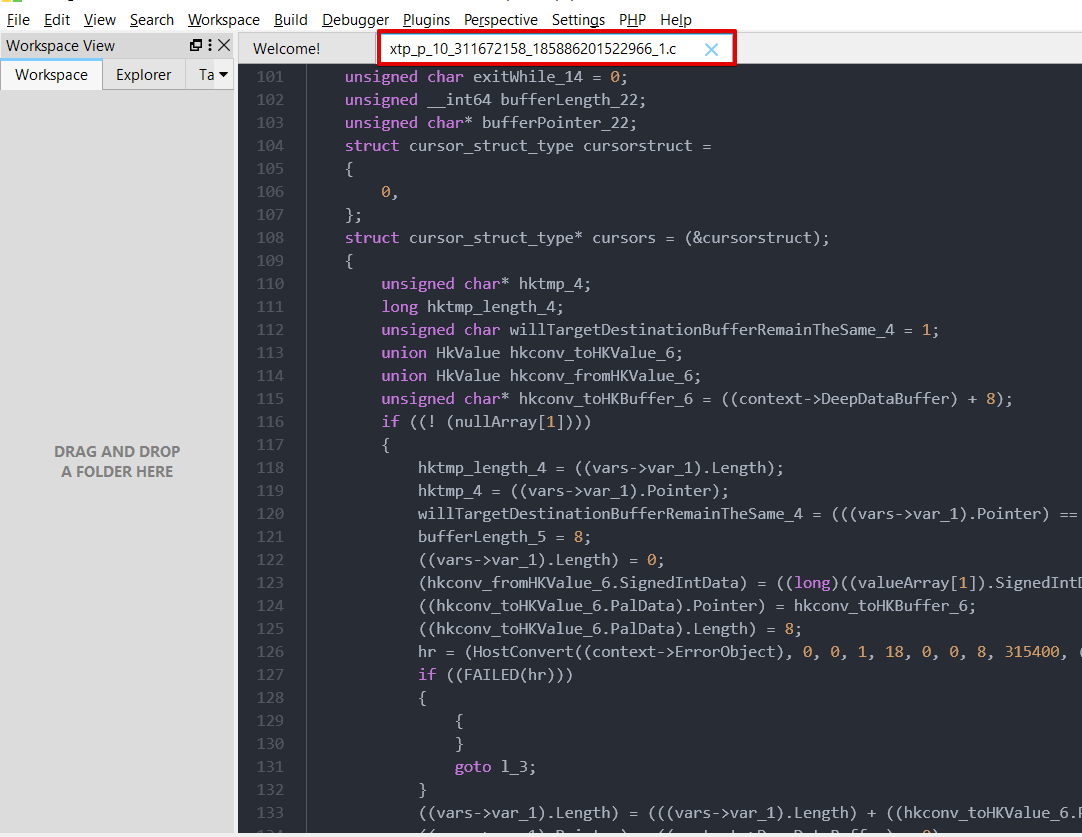
When we look at the DLL file name, it includes several definitions about the native compiled object.
xtp_p_10_311672158_185886201522966_1.dll file definitions will look like this
xtp_p is a defined native compiled stored procedure or function.
xtp_t is defined in the memory table.
10 is the database id.
311672158 defines the object id.
After all these explanations about traditional and natively compiled scalar user-defined function, a question appears in our mind. Is there any performance difference between traditional scalar user-defined function and natively compiled scalar user defined function?
Let’s do a simple test to answer this questions.
Performance test
In this performance test, we will use two scalar valued user-defined functions. One of them is traditional and the other one is natively compiled function. These functions make the same calculations and only the compilation types are different. These functions do not access any table but make meaningless calculations. We will measure the 10.000 invokes performance.
create FUNCTION traditionalUDF(@InputNum AS FLOAT) RETURNS FLOAT AS BEGIN DECLARE @DummyString VARCHAR(50)='xxxxxx' SET @DummyString=SUBSTRING(@DummyString,1,1) SET @DummyString=SUBSTRING(@DummyString,1,1) SET @DummyString=SUBSTRING(@DummyString,1,1) SET @DummyString=SUBSTRING(@DummyString,1,1) SET @DummyString=SUBSTRING(@DummyString,1,1) DECLARE @DummyTime AS DATETIME=GETDATE() SET @DummyTime =DATEADD(DAY,CAST(@InputNum AS INT),@DummyTime) DECLARE @ReturnVal FLOAT SELECT @ReturnVal=TAN(COS(SIN(LOG10(@InputNum)))) RETURN @ReturnVal END CREATE FUNCTION nativecompilelUDF(@InputNum AS FLOAT) RETURNS FLOAT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'English') DECLARE @DummyString VARCHAR(50)='xxxxxx' SET @DummyString=SUBSTRING(@DummyString,1,1) SET @DummyString=SUBSTRING(@DummyString,1,1) SET @DummyString=SUBSTRING(@DummyString,1,1) SET @DummyString=SUBSTRING(@DummyString,1,1) SET @DummyString=SUBSTRING(@DummyString,1,1) DECLARE @DummyTime AS DATETIME=GETDATE() SET @DummyTime =DATEADD(DAY,CAST(@InputNum AS INT),@DummyTime) DECLARE @ReturnVal FLOAT SELECT @ReturnVal=TAN(COS(SIN(LOG10(@InputNum)))) RETURN @ReturnVal END
After the creation of this scalar valued user-defined functions, we will run the above query. This query will invoke each function 10.000 times and return two results.
DBCC DROPCLEANBUFFERS DBCC FREEPROCCACHE GO DECLARE @Counter INT = 0, @CountLoops INT = 100000 DECLARE @TestX FLOAT, @Result FLOAT DECLARE @BegTime AS DATETIME SET @BegTime=GETDATE() WHILE @Counter < @Te@CountLoopsstLoops BEGIN SET @Result=dbo.traditionalUDF(RAND()*1000) SET @Counter = @Counter+1 END DECLARE @EndTime AS DATETIME SET @EndTime=GETDATE() select DATEDIFF(MILLISECOND,@BegTime,@EndTime) AS 'traditional' DBCC DROPCLEANBUFFERS DBCC FREEPROCCACHE GO DECLARE @Counter INT = 0, @CountLoops INT = 100000 DECLARE @TestX FLOAT, @Result FLOAT DECLARE @BegTime AS DATETIME SET @BegTime=GETDATE() WHILE @Counter < @CountLoops BEGIN SET @Result=dbo.nativecompilelUDF(RAND()*1000) SET @Counter = @Counter+1 END DECLARE @EndTime AS DATETIME SET @EndTime=GETDATE() select DATEDIFF(MILLISECOND,@BegTime,@EndTime) As 'natively compiled'
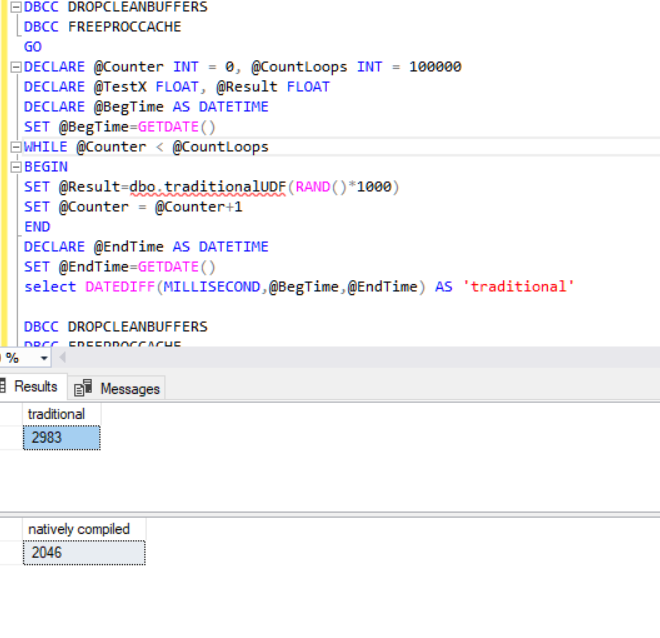
This table illustrates the result of the performance test.
[table id=51 /]
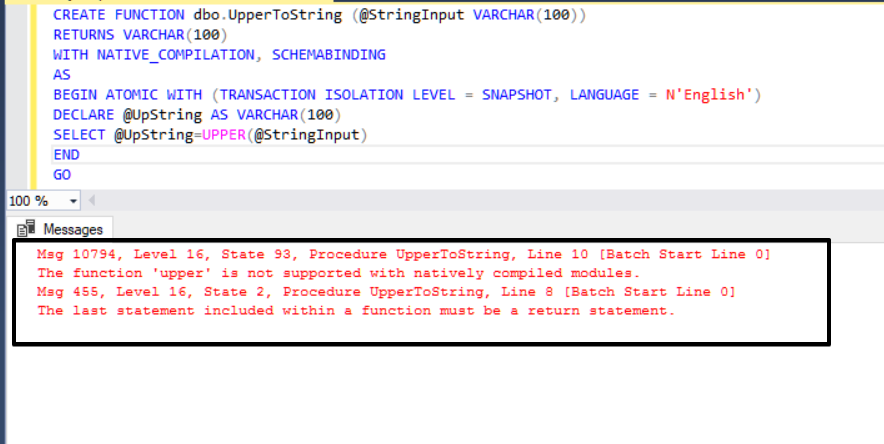
After this performance test, there isn’t any dramatic performance difference between traditional and natively compiled scalar user-defined function. With this performance test, we only compare some of the date, string, and mathematical functions performance. But if the natively compiled function will in-memory tables, this case increases the performance of the natively compiled function. On the other hand still, native compiled functions have some limitations. Still, we can’t use some functions in native compiled functions. We can‘t use some string functions in natively compiled functions. Such as when we try to use UPPER (Returns a character expression with lowercase character data converted to uppercase) function SQL Server returns an error like this; “The function ‘upper’ is not supported with natively compiled modules.”
As a result, this two type of scalar-valued user-defined functions have some advantages and disadvantages. But if we will make only arithmetical, string or date calculations you can use the traditional one.
References
Scalar User-Defined Functions for In-Memory OLTP
Supported Features for Natively Compiled T-SQL Modules
How to: Use Scalar-Valued User-Defined Functions
Tags: query performance, sql, sql server 2016 Last modified: October 23, 2024





