
Indexing the database tables is one of the ways to up your game in tuning queries. How do you do it? Today’s post will give you 22 SQL index examples of SQL query optimization to run your queries in a flash.
You can add an index using CREATE TABLE along a column, or in the CONSTRAINT clause. You can also use ALTER TABLE with ADD CONSTRAINT. And finally, by using CREATE INDEX. But what if you prefer a graphical interface?
The visual mode is convenient. It helps you do all tasks faster, while the decent GUI tool is ensuring the correctness of performance. In our case, you can use the default SQL Server Management Studio or its more powerful alternative — dbForge Studio for SQL Server.
Before we get right into it, note the following types that will group the SQL index examples:
- Clustered index
- Non-clustered index
- Unique index
- Index with included columns
- Index on computed columns
- Filtered index
- Columnstore index
- Memory-optimized hash index
- Memory-optimized non-clustered index
- Spatial index
- XML index
- Full-text index
Aside from examples, we’ll also get tips and curated facts along the way. Ready to learn the SQL best practices? Then let’s start!

[sendpulse-form id=”13580″]
Clustered Index Examples
A clustered index sorts and stores table rows based on the clustered index key. If you want a table physically sorted by people’s names, create a clustered index based on those names.
Quick Tips
- You can use clustered indexes on tables and views, but only 1 clustered index is allowed per table or view.
- You can eliminate ORDER BY if the required data is pre-sorted using a clustered index.
- To pick the right columns as clustered index keys, understand how you will access the data. What columns do you use more in your WHERE clause?
- Do not use columns that frequently change as clustered index keys.
- Clustered index keys can be simple (1-column) or composite (multiple columns).
- You can sort each column ascending or descending. Use ASC or DESC keywords for this (ASC is the default option).
- Do not use large-sized columns as composite clustered index keys.
Example 1: Adding a clustered index within CREATE TABLE
-- Use EpisodeID as the Primary Key and clustered index
CREATE TABLE [dbo].[Episodes](
[EpisodeID] [int] NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
[TitleID] [smallint] NOT NULL,
[EpisodeTitle] [varchar](50) NOT NULL,
[AirDate] [datetime] NOT NULL,
[Synopsis] [nvarchar](255) NOT NULL,
[SeasonNo] [tinyint] NOT NULL,
[EpisodeNo] [tinyint] NOT NULL
)
GO
You can import the needed data for this example from this Excel file.
Example 2: Adding a clustered index within CREATE TABLE using CONSTRAINT
-- Use EpisodeID as the Primary Key and clustered index
CREATE TABLE [dbo].[Episodes](
[EpisodeID] [int] IDENTITY(1,1) NOT NULL,
[TitleID] [smallint] NOT NULL,
[EpisodeTitle] [varchar](50) NOT NULL,
[AirDate] [datetime] NOT NULL,
[Synopsis] [nvarchar](255) NOT NULL,
[SeasonNo] [tinyint] NOT NULL,
[EpisodeNo] [tinyint] NOT NULL
CONSTRAINT PK_Episodes_EpisodeID PRIMARY KEY CLUSTERED
(EpisodeID ASC)
)
What’s different aside from the keyword CONSTRAINT? In this case, you can specify a name for the primary key. In the previous example, you let SQL Server do the naming for you.
Example 3: Adding a clustered index using ALTER TABLE…ADD CONSTRAINT
CREATE TABLE [dbo].[Episodes](
[EpisodeID] [int] IDENTITY(1,1) NOT NULL,
[TitleID] [smallint] NOT NULL,
[EpisodeTitle] [varchar](50) NOT NULL,
[AirDate] [datetime] NOT NULL,
[Synopsis] [nvarchar](255) NOT NULL,
[SeasonNo] [tinyint] NOT NULL,
[EpisodeNo] [tinyint] NOT NULL
)
GO
ALTER TABLE Episodes
ADD CONSTRAINT PK_Episodes_EpisodeID PRIMARY KEY CLUSTERED
(EpisodeID ASC)
GO
This example shows that you can add a clustered index after creating the table. But if you do this much later, make sure the column doesn’t have duplicate values. Also, there shouldn’t be any existing clustered index, or an error will be triggered.
Example 4: Adding a clustered index Using CREATE INDEX
This example has the same effect as the previous one:
CREATE TABLE [dbo].[Episodes](
[EpisodeID] [int] IDENTITY(1,1) NOT NULL,
[TitleID] [smallint] NOT NULL,
[EpisodeTitle] [varchar](50) NOT NULL,
[AirDate] [datetime] NOT NULL,
[Synopsis] [nvarchar](255) NOT NULL,
[SeasonNo] [tinyint] NOT NULL,
[EpisodeNo] [tinyint] NOT NULL
)
GO
CREATE CLUSTERED INDEX PK_Episodes_EpisodeID ON dbo.Episodes(EpisodeID)
GO
Example 5: Adding a clustered composite Index
What if the primary key is not the clustered index? Here’s an example using 2 columns as the clustered index:
CREATE TABLE [dbo].[Episodes](
[EpisodeID] [int] NOT NULL IDENTITY(1,1) PRIMARY KEY,
[TitleID] [smallint] NOT NULL,
[EpisodeTitle] [varchar](50) NOT NULL,
[AirDate] [datetime] NOT NULL,
[Synopsis] [nvarchar](255) NOT NULL,
[SeasonNo] [tinyint] NOT NULL,
[EpisodeNo] [tinyint] NOT NULL,
)
GO
-- Create a clustered, composite index based on TitleID and SeasonNo
CREATE CLUSTERED INDEX IX_TitleID_Season_No ON dbo.Episodes(TitleID, SeasonNo)
GO
But what’s the scenario? If you have a web page like this, the query below will run over and over again. Therefore, a stored procedure makes sense.
CREATE PROCEDURE spGetEpisodesList
(
@TitleID SMALLINT,
@SeasonNo TINYINT
)
AS
SET NOCOUNT ON
SELECT
e.EpisodeNo
,e.EpisodeTitle
,e.AirDate
,e.Synopsis
FROM Episodes e
INNER JOIN Titles t ON e.TitleID = t.TitleID
WHERE e.TitleID = @TitleID
AND e.SeasonNo = @SeasonNo
It also suggests that TitleID and SeasonNo are your best bet for a clustered index.
Why?
Let’s say you still use the EpisodeID as the clustered index. Then, the stored procedure above gets called repeatedly. Here’s the STATISTICS IO and Execution Plan if TitleID = 1 and SeasonNo = 2:

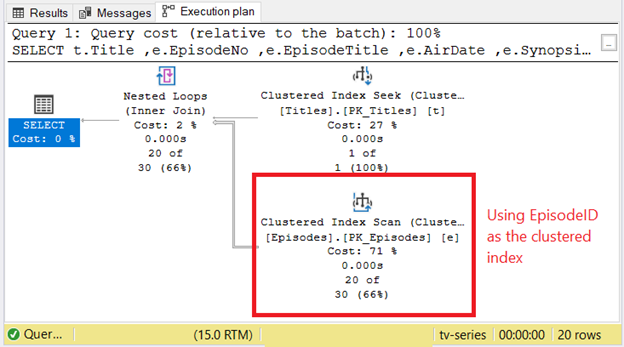
EpisodeID is the sort order of the table. The SQL Server will scan the index until it finds the requested TitleID and SeasonNo. It takes longer.
But what if the clustered index key is TitleID and SeasonNo? Check Figure 3 for the STATISTICS IO and compare it to Figure 1 above.

Did you notice that the logical reads are cut by more than half compared to Figure 1?
Now, check the Execution Plan:
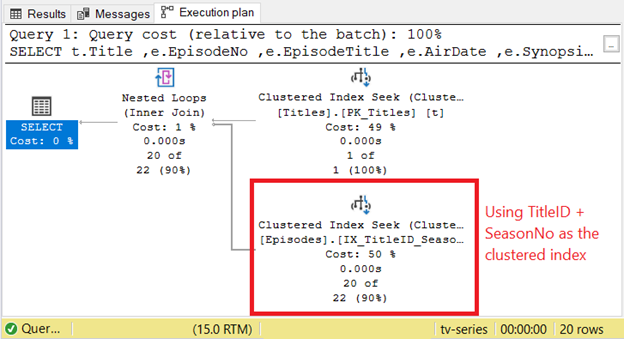
You can see that instead of Clustered Index Scan, it becomes Clustered Index Seek. What does this all mean?
Using TitleID + SeasonNo is faster than using EpisodeID as the clustered index key. Use it for query optimization in SQL Server.
Example 6: Create a clustered index on a view
USE [AdventureWorks]
GO
CREATE VIEW [Person].[vStateProvinceCountryRegion]
WITH SCHEMABINDING
AS
SELECT
sp.[StateProvinceID]
,sp.[StateProvinceCode]
,sp.[IsOnlyStateProvinceFlag]
,sp.[Name] AS [StateProvinceName]
,sp.[TerritoryID]
,cr.[CountryRegionCode]
,cr.[Name] AS [CountryRegionName]
FROM [Person].[StateProvince] sp
INNER JOIN [Person].[CountryRegion] cr
ON sp.[CountryRegionCode] = cr.[CountryRegionCode];
GO
CREATE UNIQUE CLUSTERED INDEX [IX_vStateProvinceCountryRegion] ON [Person].[vStateProvinceCountryRegion]
(
[StateProvinceID] ASC,
[CountryRegionCode] ASC
)
GOMore Information
- Clustered and Nonclustered Indexes Described
- CREATE INDEX (Transact-SQL) – Clustered Index
- Clustered Index Design Guidelines
- Top 3 Tips You Need to Know to Write Faster SQL Views
- 3 Nasty IO Statistics That Lag SQL Query Performance
Non-clustered Index Examples
Our next set of SQL performance tuning examples is about non-clustered indexes. These indexes don’t physically sort your table records. Instead, they use a row locator to point to the clustered index or table having the key value.
Quick Tips
- You don’t need to specify the keyword NONCLUSTERED – it comes by default.
- Each table can have up to 999 non-clustered indexes.
- Avoid over-indexing, as it slows down UPDATE, DELETE and INSERT commands. So, use caution.
- Non-clustered index keys can be simple (1-column) or composite (multiple columns).
- Use narrow or as few columns as possible as index keys.
- Instead of adding more columns as index keys, use included columns to extend the non-clustered index.
Example 7: Add a non-clustered index with one column
USE [AdventureWorks]
GO
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_OrderDate] ON [Sales].[SalesOrderHeader]
(
[OrderDate] ASC
)
GO
Example 8: Add a non-clustered composite index
Do you want to have a working example but of a poor choice? Sounds crazy, doesn’t it? But a working code doesn’t mean it’s the best choice you made. Keep on reading.
Here is the working example:
CREATE NONCLUSTERED INDEX IX_TitleID_Season_No ON dbo.Episodes(TitleID, SeasonNo)
GO
The columns are the same as the clustered index earlier. And yes, this code will work. But to give it more sense, you have to switch back the clustered index to EpisodeID.
Why is it a wrong choice? Check out Figure 5:

Figure 5 is not a duplicate of Figure 1. Notice the physical reads. The logical reads are still 12 8KB-pages. Now, check the Execution Plan in Figure 6.
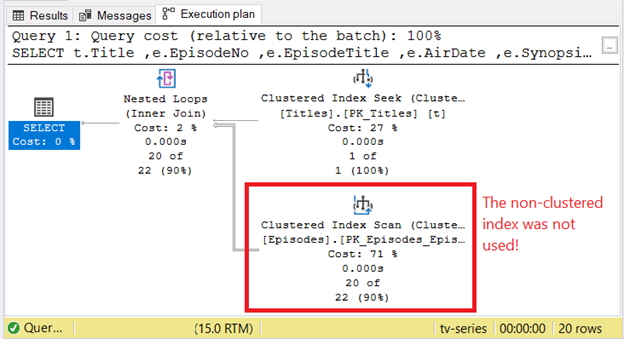
Figure 6 shows that the query optimizer did not use the non-clustered index. That explains 12 logical reads. Poor choice? Yes, definitely. Not suitable for SQL optimisation at all. This setup is slower than TitleID + SeasonNo as the clustered index.
More Information
- Clustered and Nonclustered Indexes Described
- Create Nonclustered Indexes
- Nonclustered Index Design Guidelines
Unique Index Examples
Our next set of SQL index examples is about unique indexes. A unique index ensures that the unique index key values have no duplicates. It is essential for database optimisation.
Quick Tips
- Uniqueness can be a property of both clustered and non-clustered indexes.
- You cannot create a unique index on a table with data if duplicate values exist.
- Unique indexes can contain included columns.
- The query optimizer can use a unique index to produce more efficient execution plans. Thus, instead of creating a non-unique index on unique column values, use a unique index.
- If a column is nullable and the data contains many rows of null values, a unique index is not allowed.
Example 9: Create a unique non-clustered simple index
USE [AdventureWorks]
GO
CREATE UNIQUE NONCLUSTERED INDEX [AK_SalesTerritory_Name] ON [Sales].[SalesTerritory]
(
[Name] ASC
)
GO
Example 10: Create a unique non-clustered composite index
-- unique index
USE [AdventureWorks]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_SalesOrderDetail_OrderID_ProductID] ON [Sales].[SalesOrderDetail]
(
[SalesOrderID] ASC,
[ProductID] ASC
)
GO
More Information
Index with Included Columns
Another SQL index example set relates to indexes with included columns. This happens when you extend a non-clustered index to include non-key columns.
Quick Tips
- It applies to non-clustered indexes only.
- Columns with text, ntext, and image data types are not allowed as included columns.
- You cannot drop included columns unless you drop the index first.
- Include non-key columns to avoid exceeding the index size limitations. The latest limitation is up to 32 key columns, and an index key size is up to 1,700 bytes.
- Included columns are not used when calculating the number of index key columns or index key size.
Examples 11 and 12: Create a non-clustered index with included columns
-- EXAMPLE 11: Create an index with included columns
USE [AdventureWorks]
GO
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate] ON [Sales].[SalesOrderHeader]
(
[ShipDate] ASC
)
INCLUDE([OrderDate],[Status],[CustomerID])
GO
You may wonder, what difference can this make? Is this any better compared to the index without the included columns? Let’s consider the query:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Before running it, recreate the index without included columns. Then, run the query above with STATISTICS IO ON. Note the logical reads, and run Example 12 below.
-- EXAMPLE 12. Create the index but drop it first if it exists
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate] ON [Sales].[SalesOrderHeader]
(
[ShipDate] ASC
)
INCLUDE([OrderDate],[Status],[CustomerID])
WITH (DROP_EXISTING=ON)
GO
After that, rerun the query with STATISTICS IO ON.
What do you see now? Here’s what I got:
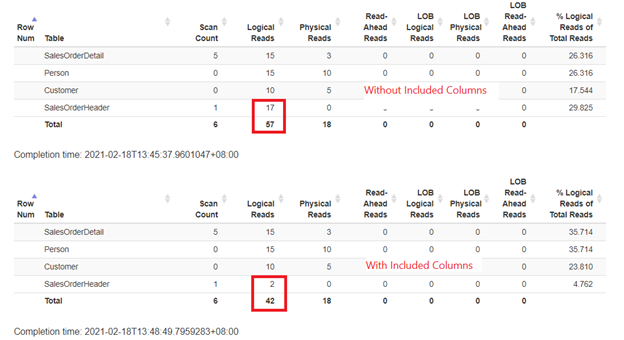
Looks like using included columns consumes less logical reads. Let’s check the Execution Plan to see why.
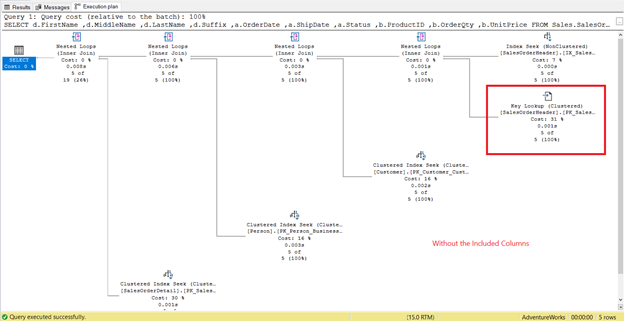
Compare it to the Execution Plan with included columns:
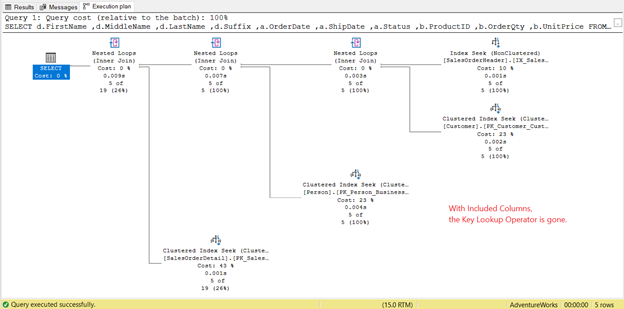
The Execution Plan in Figure 9 is much simpler. It also explains why logical reads are lesser when there are included columns. Also, the Execution Plan in Figure 8 has a Key Lookup operator. But for what?
Try to check the properties of that operator. Did you notice the Output List with the 3 columns? The 3 columns are OrderDate, Status, and CustomerID. To get the values of these columns, SQL Server needs to go back to the table using the clustered index.
This can only happen with the Key Lookup. But when you add those 3 columns as included columns in the index, that extra step is unnecessary.
In this case, included columns helped to speed up the query performance.
More Information
Create Indexes with Included Columns
Index on Computed Columns
Next in line are SQL index examples on computed columns. A computed column derives from values of other columns. You can create an index using these columns.
Quick Tips
- Functions used in computed columns should be deterministic. Their returned value should not change. Functions, such as GETDATE(), NEWID(), RANK() are non-deterministic. Why? Because their values can change.
- Data types of columns used in the computed column should be precise. Float and real types are not precise. But decimal and integers are precise.
- Conversion of strings to date should be deterministic. The following code is non-deterministic. You can’t be sure what the value is.
-- Is the date string August 11, 2020, or November 8, 2020?
DECLARE @dateString NVARCHAR(10) = '11/08/2020';
PRINT @dateString + ' = the input.';
SET DATEFORMAT dmy;
SELECT CONVERT(DATE, @dateString) AS [DMY-format]; -- Output: 2020-08-11
SET DATEFORMAT mdy;
SELECT CONVERT(DATE, @dateString) AS [MDY-format]; -- Output: 2020-11-08
SET DATEFORMAT ymd;
SELECT CONVERT(DATE, @dateString) AS [YMD-format]; -- Output: 2020-11-08
Example 13: Create a unique index on computed column AccountNumber
USE [AdventureWorks]
GO
CREATE TABLE [Sales].[Customer](
[CustomerID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[PersonID] [int] NULL,
[StoreID] [int] NULL,
[TerritoryID] [int] NULL,
[AccountNumber] AS (isnull('AW'+[dbo].[ufnLeadingZeros]([CustomerID]),'')),
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Customer_CustomerID] PRIMARY KEY CLUSTERED
(
[CustomerID] ASC
))
-- Create an index on AccountNumber computed column
CREATE UNIQUE NONCLUSTERED INDEX [AK_Customer_AccountNumber] ON [Sales].[Customer]
(
[AccountNumber] ASC
)
GO
Example 14: Create an index on computed column SalesOrderNumber
USE [AdventureWorks]
GO
CREATE TABLE [Sales].[SalesOrderHeader](
[SalesOrderID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[RevisionNumber] [tinyint] NOT NULL,
[OrderDate] [datetime] NOT NULL,
[DueDate] [datetime] NOT NULL,
[ShipDate] [datetime] NULL,
[Status] [tinyint] NOT NULL,
[OnlineOrderFlag] [dbo].[Flag] NOT NULL,
[SalesOrderNumber] AS (isnull(N'SO'+CONVERT([nvarchar](23),[SalesOrderID]),N'*** ERROR ***')),
[PurchaseOrderNumber] [dbo].[OrderNumber] NULL,
[AccountNumber] [dbo].[AccountNumber] NULL,
[CustomerID] [int] NOT NULL,
[SalesPersonID] [int] NULL,
[TerritoryID] [int] NULL,
[BillToAddressID] [int] NOT NULL,
[ShipToAddressID] [int] NOT NULL,
[ShipMethodID] [int] NOT NULL,
[CreditCardID] [int] NULL,
[CreditCardApprovalCode] [varchar](15) NULL,
[CurrencyRateID] [int] NULL,
[SubTotal] [money] NOT NULL,
[TaxAmt] [money] NOT NULL,
[Freight] [money] NOT NULL,
[TotalDue] AS (isnull(([SubTotal]+[TaxAmt])+[Freight],(0))),
[Comment] [nvarchar](128) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_SalesOrderHeader_SalesOrderID] PRIMARY KEY CLUSTERED
(
[SalesOrderID] ASC
))
GO
CREATE NONCLUSTERED INDEX [AK_SalesOrderHeader_SalesOrderNumber] ON [Sales].[SalesOrderHeader]
(
[SalesOrderNumber] ASC
)
GO
Running the SELECT query below will use the computed column index we created above with an Index Seek operator.
SELECT * FROM Sales.SalesOrderHeader
WHERE SalesOrderNumber = 'SO43659'
More Information
- Indexes on Computed Columns
- CREATE INDEX (Transact-SQL) – Computed Columns
- Deterministic and Non-deterministic Functions
Filtered Index Examples
Our next entry on SQL index examples is about filtered indexes. Filtered indexes use a filter expression to index a subset of rows in a table.
Quick Tips
- Well-defined filtered indexes can improve query performance and plan quality. The index is smaller and statistics get filtered to become more accurate.
- It can improve index maintenance costs. Only when data affecting the index is updated the index is updated too.
- It can reduce index storage costs compared to a whole-table index.
- If the filtered index covers all columns needed in the query, the optimizer will choose the filtered index.
Example 15: Create a filtered index
CREATE NONCLUSTERED INDEX FI_MacGyver_Season3_Episodes ON Episodes(TitleID,SeasonNo)
INCLUDE(EpisodeNo,EpisodeTitle, AirDate)
WHERE TitleID = 1 AND SeasonNo = 3;
The WHERE clause defines the filter expression of a filtered index. To check if the query optimizer will use it, let’s use a query example:
SELECT
EpisodeNo
,EpisodeTitle
,AirDate
FROM Episodes
WHERE TitleID = 1
AND SeasonNo = 3
AND EpisodeNo BETWEEN 10 AND 15
Then, let’s see if the query optimizer uses the filtered index:
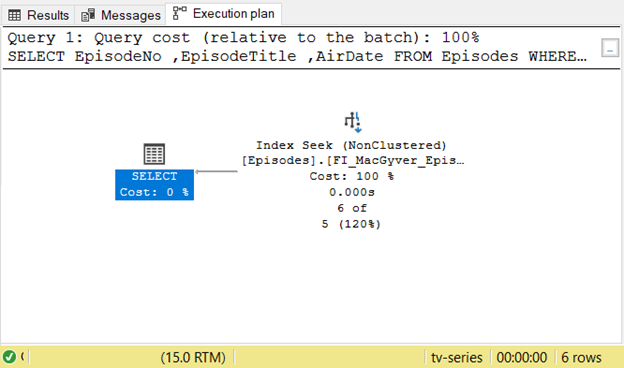
The query optimizer used an Index Seek operator on the filtered index. Changing the WHERE clause of the query to SeasonNo = 2 will result in a different plan.
More Information
- Create Filtered Indexes
- Filtered Index Design Guidelines
- CREATE INDEX (Transact-SQL) – Filtered Indexes
Columnstore Index Examples
The Columnstore indexes store and manage data using column-based storage and query processing. These indexes are best for the data warehousing workloads that perform bulk loads and read-only queries and are good means for SQL optimisation.
Quick Tips
- Using columnstore index can do 100 times better performance on data analytics and data warehousing workloads.
- It provides 10 times better compression.
- It works best on tables with at least a million records per partition.
- It also works best on tables with minimal updates and deletes, which is less than 10% of operations involving updates and deletes.
Example 16: Create a clustered columnstore index
USE [WideWorldImporters]
GO
CREATE TABLE dbo.TestValues
(val BIGINT NOT NULL UNIQUE,
modified DATETIME NOT NULL DEFAULT GETDATE(),
[status] VARCHAR(10) NOT NULL)
INSERT INTO dbo.TestValues
SELECT TOP (1000000)
val = ROW_NUMBER() OVER (ORDER BY sol.[OrderLineID])
, modified = GETDATE()
, status = 'inserted'
FROM sales.OrderLines sol
CROSS JOIN sales.OrderLines sol2
CREATE CLUSTERED COLUMNSTORE INDEX ccix_testTable_val ON TestValues
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
Note that you cannot specify a column or 2 in creating a clustered columnstore index. As it becomes the primary storage of the entire table, a clustered columnstore index will use all columns in the table.
Example 17: Create a non-clustered columnstore index
Meanwhile, you need to specify columns for a non-clustered columnstore index.
USE [WideWorldImporters]
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX [NCCX_Sales_InvoiceLines] ON [Sales].[InvoiceLines]
(
[InvoiceID],
[StockItemID],
[Quantity],
[UnitPrice],
[LineProfit],
[LastEditedWhen]
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [USERDATA]
GO
More Information
Hash Index Examples
Memory-optimized tables can use 2 types of indexes. One is a hash index. The other one is a memory-optimized non-clustered index. You can use a hash index for point lookups and not for range scans.
Quick Tips
- Hash indexes are for memory-optimized tables only.
- You cannot create a clustered hash index.
- You cannot use CREATE INDEX. Use ALTER TABLE…ADD INDEX instead.
- Index changes are not written to disks.
- No STATISTICS IO will come out even if you turn it ON.
- Memory-optimized indexes are rebuilt when the database is brought back online.
- Great for seeks with equality predicate utilizing all columns used in the hash index.
Before we proceed with the examples, let’s create the memory-optimized table:
CREATE TABLE [dbo].[Titles_MO](
[TitleID] [int] IDENTITY(1,1) NOT NULL,
[Title] [varchar](50) NOT NULL,
[From] [smallint] NOT NULL,
[To] [smallint] NOT NULL,
CONSTRAINT [PK_Titles_MO] PRIMARY KEY NONCLUSTERED
(
[TitleID] ASC
)
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY= SCHEMA_AND_DATA)
GO
CREATE TABLE [dbo].[Episodes_MO](
[EpisodeID] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED,
[TitleID] [smallint] NOT NULL,
[EpisodeTitle] [varchar](50) NOT NULL,
[AirDate] [datetime] NOT NULL,
[Synopsis] [nvarchar](255) NOT NULL,
[SeasonNo] [tinyint] NOT NULL,
[EpisodeNo] [tinyint] NOT NULL
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY= SCHEMA_AND_DATA)
GO
INSERT INTO Titles_MO
(Title, [From], [To])
SELECT Title, [From], [To] FROM Titles
INSERT INTO Episodes_MO
(TitleID, EpisodeTitle, AirDate, Synopsis, SeasonNo, EpisodeNo)
SELECT TitleID, EpisodeTitle, AirDate, Synopsis, SeasonNo, EpisodeNo FROM Episodes
Now, we’re ready.
Example 18: Creating a memory-optimized hash index
ALTER TABLE Episodes_MO
ADD INDEX NCIX_Episodes_NO_TitleID_SeasonNo
HASH (TitleID, SeasonNo) WITH (BUCKET_COUNT=64);
How does this fare compare to the disk-based tables we used earlier? Is it faster?
Let’s find out by comparing the results from 2 similar queries:
-- Using memory-optimized tables and index
SELECT
t.Title
,e.EpisodeNo
,e.EpisodeTitle
,e.AirDate
,e.Synopsis
FROM Episodes_MO e
INNER JOIN Titles_MO t ON e.TitleID = t.TitleID
WHERE e.TitleID = 1
AND e.SeasonNo = 2
-- Using disk-based tables and index
SELECT
t.Title
,e.EpisodeNo
,e.EpisodeTitle
,e.AirDate
,e.Synopsis
FROM Episodes e
INNER JOIN Titles t ON e.TitleID = t.TitleID
WHERE e.TitleID = 1
AND e.SeasonNo = 2
The first SELECT statement ran for 66ms with 0 logical reads. The second ran 275ms with 5 logical reads like in Figure 3. Thus, memory-optimized tables and indexes won the race. But let’s see what the Execution Plan has to say:
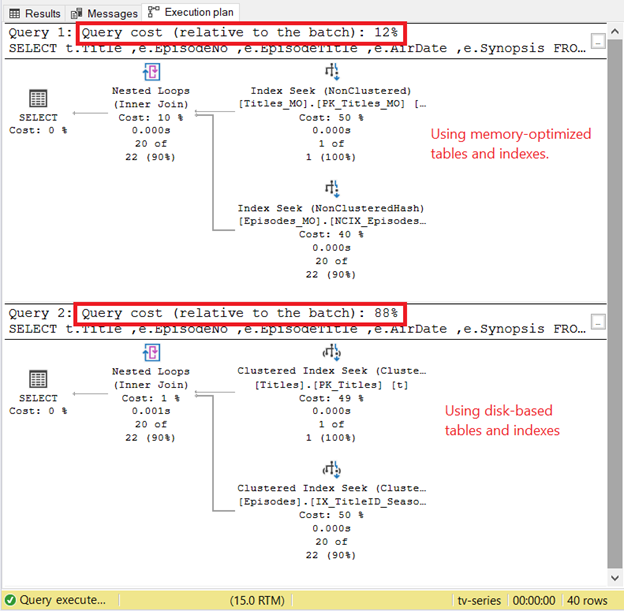
The Execution plan in Figure 11 confirms that memory-optimized tables and indexes ran quicker. Also, check the query costs of both. The disk-based tables and indexes have higher query costs.
Does it mean that we should all move our tables from disk to memory? Even Microsoft warns us that it is not a magic go-fast button. It is not suitable for all workloads. But there are SQL performance tuning scenarios for this kind of feature – check it out from here.
More Information
- Hash Index Design Guidelines
- Indexes on Memory-Optimized Tables
- In-Memory OLTP: Overview and Usage Scenarios
Memory-Optimized Non-clustered Index Examples
Next in line is the memory-optimized non-clustered index. We use it for memory-optimized tables and range scans.
Quick Tip
Memory-optimized non-clustered index shares similar rules as hash index except for:
- it is great for WHERE clause with equality and inequality, and also for range predicates (>,<,>=,<=, between).
- It is great for ORDER BY that matches the index. Therefore, these methods are fine for query optimization in SQL Server.
Example 19: Creating a non-clustered memory-optimized index
ALTER TABLE Episodes_MO
ADD CONSTRAINT UNCIX_Episodes_MO_EpisodeTitle UNIQUE NONCLUSTERED (EpisodeTitle);More Information
Spatial Index Examples
A spatial index is a type of extended index you can use on spatial data types like geometry and geography.
Quick Tips
- It applies to both geography and geometry data types.
- The default cells_per_object is 16 which provides a satisfactory trade-off between space and precision for most spatial indexes. But values can be 1 to 8192.
- If you need to indicate general index options like DROP_EXISTING, place it after the spatial index options. Or you will trigger an error.
Example 20: Creating a spatial index
CREATE TABLE [dbo].[Cities](
[CityID] [int] IDENTITY(1,1) NOT NULL,
[CityName] [varchar](50) NOT NULL,
[RegionID] [int] NOT NULL,
[GeoLocation] [geography] NULL,
CONSTRAINT [PK_Cities] PRIMARY KEY CLUSTERED
(
[CityID] ASC
))
GO
CREATE SPATIAL INDEX [SI_City_Geolocation] ON [dbo].[Cities]
(
[GeoLocation]
)USING GEOGRAPHY_GRID
WITH (CELLS_PER_OBJECT = 16, DROP_EXISTING=OFF)
GOMore Information
XML Index Examples
XML indexes are for columns with XML data type. You can index paths, values, and tags to gain performance benefits and thus apply SQL best practices.
Quick Tips
- This index is for XML data type columns only.
- Consider it if querying on XML columns is a common scenario.
- Consider it when XML values are large.
- There are 2 types of XML indexes: primary and secondary.
- Primary XML index indexes all tags, values, and paths.
- Primary XML index on a table needs a clustered index on the table.
- You can’t have a secondary XML index without the primary index.
- Secondary XML index can be path, value, or property XML index.
Example 21: Creating primary and secondary XML indexes
CREATE TABLE XMLTable
(id INT NOT NULL PRIMARY KEY IDENTITY,
xCol XML)
GO
CREATE PRIMARY XML INDEX PIX_XMLTable_xCol ON XMLTable(xCol);
CREATE XML INDEX IX_XMLTable_xCol_PATH ON XMLTable(xCol)
USING XML INDEX PIX_XMLTable_xCol
FOR PATH;
CREATE XML INDEX IX_XMLTable_xCol_VALUE ON XMLTable(xCol)
USING XML INDEX PIX_XMLTable_xCol
FOR VALUE;
CREATE XML INDEX IX_XMLTable_xCol_PROPERTY ON XMLTable(xCol)
USING XML INDEX PIX_XMLTable_xCol
FOR PROPERTY;More Information
Full-text Index Examples
A full-text index is a special token-based functional index for sophisticated word searches on large string data.
Quick Tips
- It works on large object (LOB) data types like varchar(max) or varbinary(max).
- Before creating a full-text index, you need to create a full-text catalog for organizing full-text indexes.
- The candidate table for full-text indexing requires a unique index before the full-text index is created.
Example 22: Creating a full-text catalog and index
USE AdventureWorks
GO
CREATE FULLTEXT CATALOG [DocumentFullTextCatalog] WITH ACCENT_SENSITIVITY = ON
AS DEFAULT
GO
SELECT * INTO dbo.DocLibrary
FROM production.document
CREATE FULLTEXT INDEX ON dbo.DocLibrary
(DocumentSummary, Document TYPE COLUMN FileExtension LANGUAGE 1033)
KEY INDEX PK_DocLibrary
ON [DocumentFullTextCatalog]
WITH STOPLIST = SYSTEM
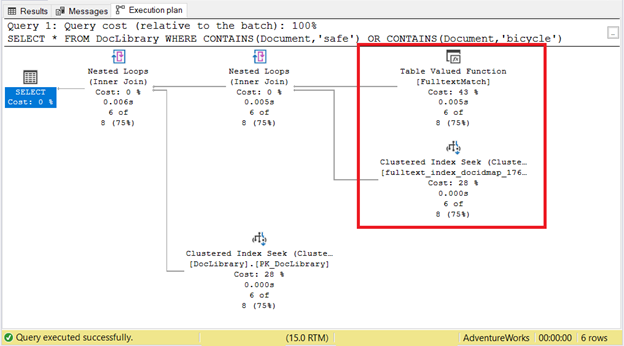
To check if this index is used by SQL Server, try this query:
-- Display all documents having the word 'safe' and 'bicycle'
SELECT * FROM DocLibrary
WHERE CONTAINS(Document,'safe')
OR CONTAINS(Document,'bicycle')
This query returns 6 MS Word documents containing the words safe and bicycle. Check how it turns out in the Execution Plan:
More Information
- Populate Full-Text Indexes
- How to Use Stopwords and Stoplists to Improve SQL Server Full-Text Search
- Mastering the Use of Stoplists with SQL Server Full-Text Search
Conclusion
We have now all index types, all with examples, and all in one place. If you need more information, it’s just a click away. I hope these 22 SQL index examples will be a worthwhile go-to reference for SQL query optimization. You can use these methods where applicable.
Oscar Wilde once said, “The only thing to do with good advice is to pass it on.” So, if you find this post helpful, please pass it on by sharing it on your favorite social media platforms. And if you have something else to add, for instance, about other areas, like PostgreSQL query optimization, let us know in the Comments section below.
Tags: indexes, sql functions, sql server Last modified: October 07, 2022






