In this article, we will introduce SQL transformations in action. We will also see how to handle missing values in our dataset.
Consider a scenario of a movie rating dataset containing records of different movies along with the average user ratings associated with each movie. The ratings are in numeric form ranging from 1 to 10 with 1 as the lowest rating and, respectively, 10 as the highest rating (though no movie in the history has achieved 10 rating:). Suppose that we want to convert the numeric ratings into categorical ratings. For instance, we want to replace ratings of 1-3 with the categorical value “poor”, of 4-6 with “average” while ratings of 7-10 will have the value “good”. We can accomplish it with SQL transformation in Azure ML Studio.
SQL Transformations
SQL transformations are simple SQL statements that can be executed inside Azure ML studio to manipulate and transform data.
Uploading the Dataset
The dataset that we are going to use in this article can be downloaded from this Kaggle link. Download the dataset into your local drive.
The next step is to upload the dataset to Azure ML studio. To do so, login to Azure ML Studio and click on the “DATASETS” option from the menu on the left. Click the “NEW” button at the bottom of the screen and then select the option “FROM LOCAL FILE”.
You should see the following window.

Click on the “Choose” button and browse for the dataset file that you downloaded. Upload the file and then click the tick button at the bottom right of the above screen.
Dataset Analysis
The next step is to analyse the data that we just uploaded. To do so, click on the “Experiments” option on Azure ML and then create a new blank experiment.
From the window that opens, click on “Saved Datasets -> My Datasets”. Here you should see your newly uploaded “movie_ratings.csv” dataset as shown in the following screenshot:
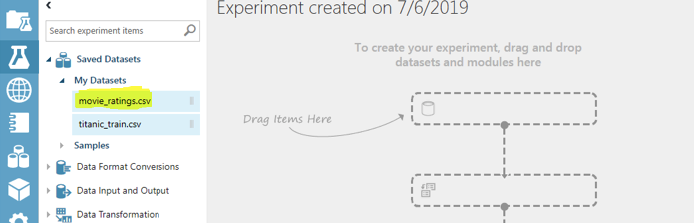
Next, drag the “movie_ratings.csv” dataset on the main window on the right.
Click the circle that contains 1 and then select “Visualize” you see highlighted on the screenshot below.
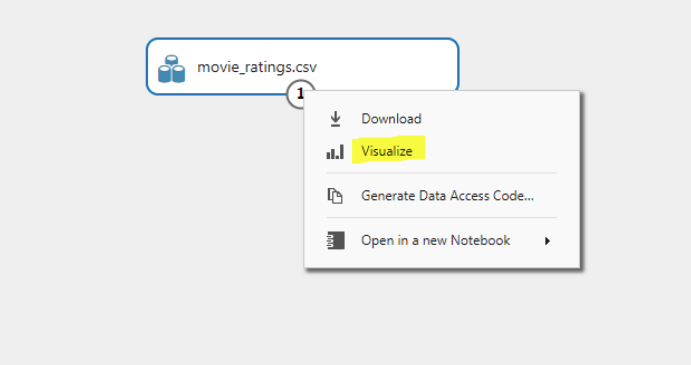
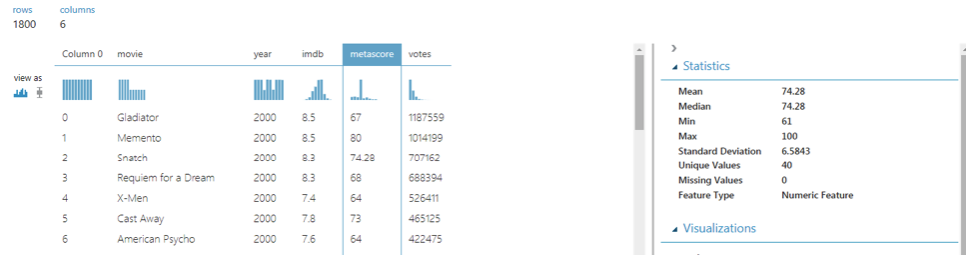
The movie ratings are in the “imdb” column. Click the column title. You should see the following image:
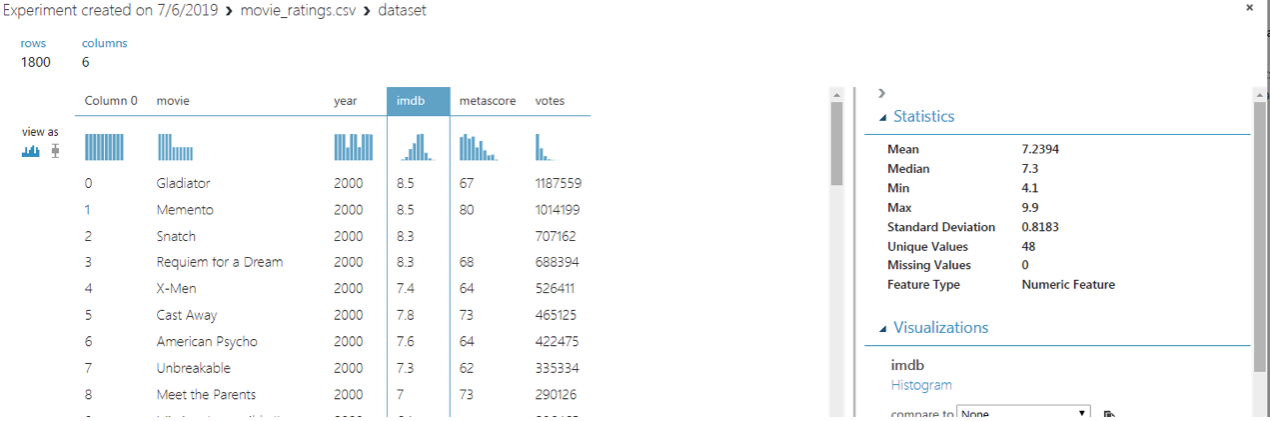
The minimum average rating for a movie is 4.1 while the maximum rating is 9.9. Furthermore, the mean of the average ratings of all the movies is 7.3.
Applying Transformation
The final step is to apply a transformation to the data.
We want to create a new column that contains the value “poor” if the movie rating is between 1 to 3, “average” if the movie rating is between 4 and 6, and, finally, the value “good” if the rating falls between 7 and 10.
To apply a SQL transformation, click “Data Transformation -> Manipulation -> Apply SQL Transformation” option from the left menu. Drag the option to the right window pane, just below the dataset.
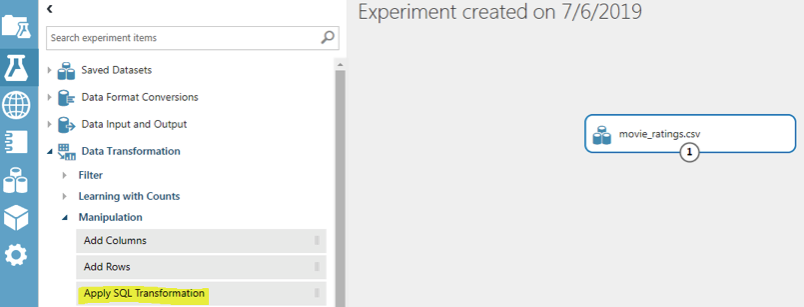
Connect the “movie_ratings.csv” dataset with the “Apply SQL Transformation” tab as shown below:
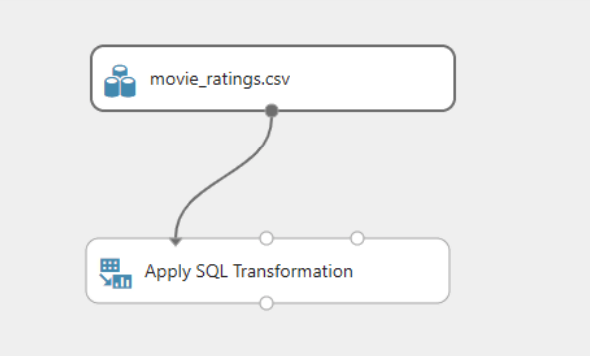
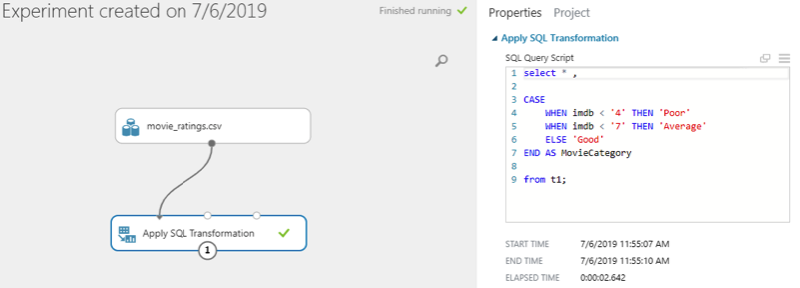
Next, in the SQL query window on the left, you have entered the SQL Query for transformation as shown below:
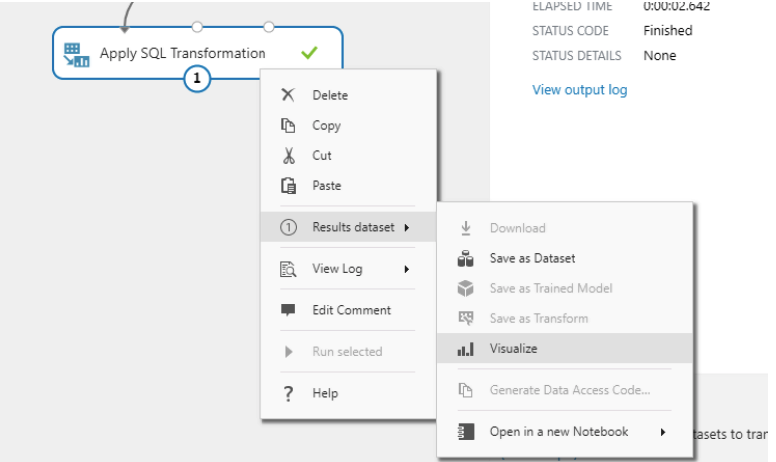
Finally, you have to click the “Run selected” option that appears when you right-click on “Apply SQL Transformation” option.
Let’s see what is happening in the query:
select * , CASE WHEN imdb < '4' THEN 'Poor' WHEN imdb < '7' THEN 'Average' ELSE 'Good' END AS MovieCategory from t1;
In the above SQL script, we basically select all the columns from the dataset. We then check if the value in the imdb column is less than 4, then set the value in the newly created column to “Poor”. Else, if the value in the imdb column is less than 7, then set the value in the newly created column to “Average”, else set the value in the newly created column to “Good”. Finally, we set the new column name to “MovieCategory”.
To view the new dataset, click on “Apply SQL Transformation -> Result Dataset -> Visualize as shown below:”
Your new dataset will look as follows:
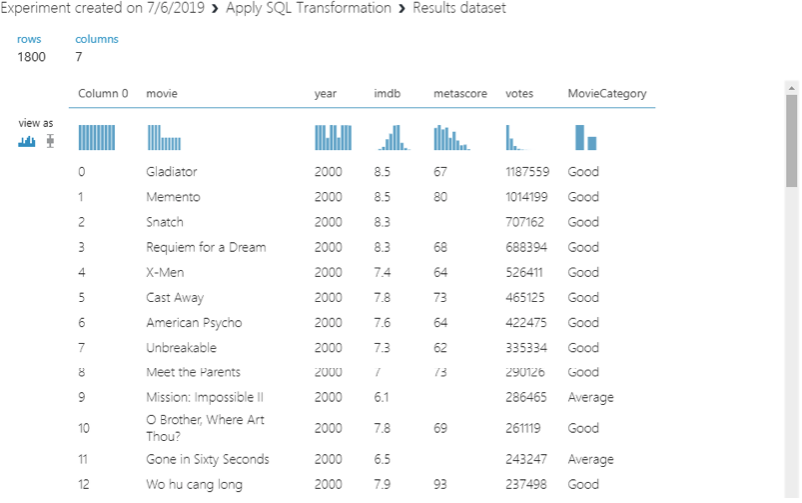
You can clearly see the newly created dataset “MovieCategory” that contains “Good”, “Average”etc. as values.
Keep in mind though that Azure ML Studio doesn’t support all the SQL statements. Therefore, if your code runs successfully, and you do not see any change in the dataset, there are two possibilities: either the SQL statement is not supported, or it doesn’t affect the dataset in any way.
Handling Missing Values
Sometimes that dataset that we want to use to perform classification or regression, contains missing values for some columns. Missing values can severely affect the performance of machine learning algorithms. Azure ML provides support to handle missing values in the data.
If you explore the “metascore” column, you will see that it contains 850 missing values as shown below:
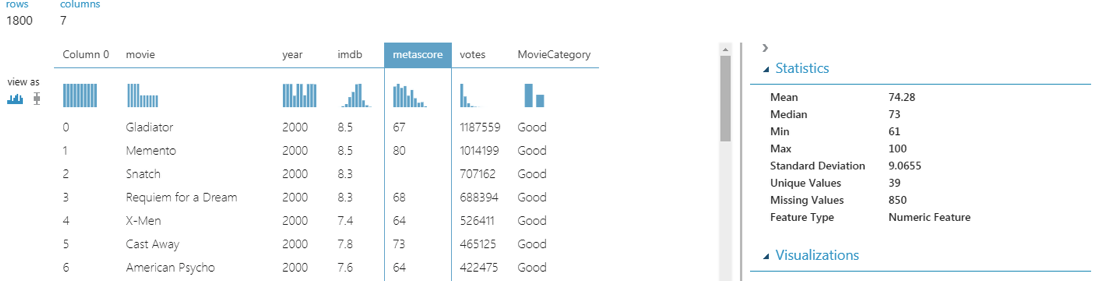
To handle missing data, you can use the “Clean Missing Data” module. To access the module, click on “Data Transformation-> Manipulation -> Clean Missing Data”. Drag the module to the experiment window and connect it with our “movie_ratings.csv” dataset as shown below:
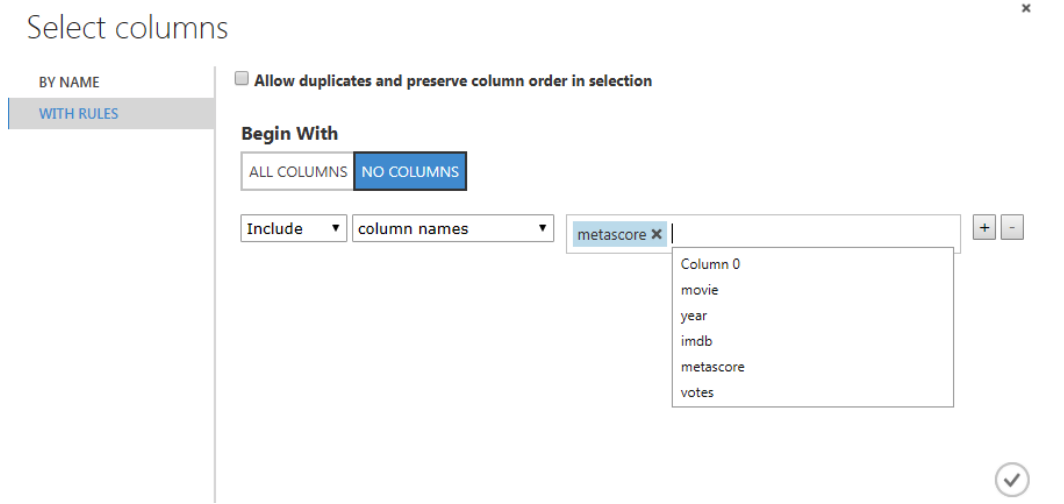
The first thing you need to do is to click on “Launch Column Selector” option from the left and then select the “Metascore” column as shown below:
The other option you need to specify is “Minimum missing value ratio” for specifying the minimum ratio of missing values needed before we can apply the transformation. Similarly, “Maximum missing value” ratio specifies the ratio of missing data that we want to replace. The default values i.e. 0 and 1 for the respective options will replace all the missing values.
Finally, the “Cleaning mode” option specifies the mode for cleaning the missing values. It contains such options as:
- “Replace with mean”
- “Replace with median”, etc.
We want to replace the missing values with the mean value of all the existing values. Therefore, we will select the option “Replace with mean”.
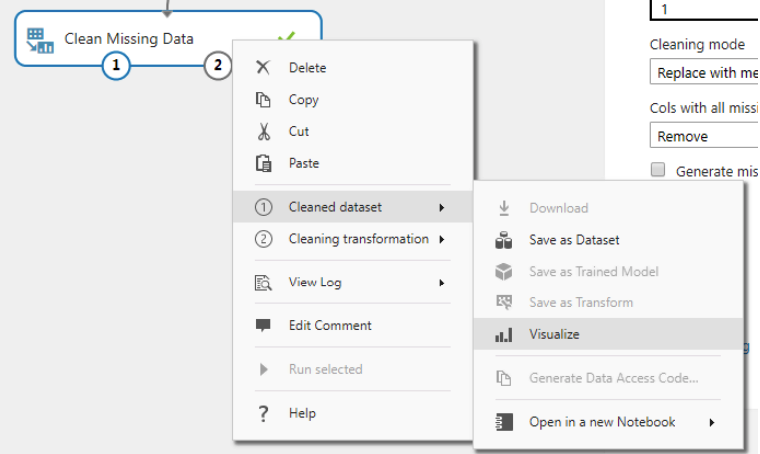
To view the processed dataset, click on“Clean Missing Data” module and then select “Cleaned dataset -> Visualize”.
Now, if you explore the “metascore” column again, you will see that it doesn’t contain any missing values as confirmed with a screenshot below:
Conclusion
Before we can use our dataset to train machine learning models, we need to convert data into the right format. One of the most important tasks is to perform data transformations and handle missing values.
In this article, we demonstrated how to perform SQL transformations so that we could transform our data in Azure ML studio. In addition, we showed how to handle missing values via Azure ML Studio.
Tags: azure, sql Last modified: September 20, 2021





