In this article, we will talk about SQL Server Checkpoints.
To enhance performance, SQL Server applies modifications to database pages in memory. Often, this memory is called the buffer cache or buffer pool. SQL Server does not flush these pages to disk after every change. Instead, the database engine does checkpoint operation on each database from time to time. The CHECKPOINT operation writes the dirty pages (current in-memory modified pages) and also writes details about the transaction log.
SQL Server supports four types of checkpoints:
1. Automatic — This type of checkpoints occur behind the scenes and depend on the recovery interval server configurations. The value is measured in minutes, and the default value is 1 minute (cannot be set lower). The checkpoint will complete in the time that minimizes the impact to performance.
EXEC sp_configure 'recovery interval', 'seconds'
Under the SIMPLE recovery model, an automatic checkpoint is also triggered when the transaction log is 70% full.
2. Indirect — This type of checkpoints also occur behind the scenes according to the user-specified database recovery time settings. Starting from SQL Server 2016 CTP2 the default value for this type of checkpoint is 1 minute. It means that a database will use indirect checkpoints. For older SQL Server versions the default is 0. This means that a database will use automatic checkpoints, whose frequency depends on the recovery interval setting of the SQL Server instance. Microsoft recommends 1 minute for most systems.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
When setting this, consider the underlying I/O subsystem’s capabilities. Might make sense to set to set this lower for faster I/O subsystems (e.g. SSDs). Be careful, this setting persists through backup and restore so restoring to slower hardware may cause performance problems from driving too much I/O load.
3. Manual — Occurs while executing the T-SQL CHECKPOINT command.
CHECKPOINT [ checkpoint_duration ]
checkpoint_duration is an integer used to define the amount of time in which a checkpoint should complete. This parameter also governs how many resources are assigned to the checkpoint operation. If the parameter is not specified, the checkpoint will complete in the time that minimizes impact to performance.
4. Internal — Some SQL Server operations issue this type of checkpoints to ensure that disk images match the current transaction log state. These are checkpoints that are performed when a certain operation takes place:
- A data file is added or removed
- A database shutdown occurs (for whatever reason)
- A backup or database snapshot is created
- A DBCC command is run that creates a hidden database snapshot (or e.g. DBCC_CHECKDB, DBCC_CHECKTABLE).
Why are checkpoints useful?
Checkpoints reduce crash-recovery time. This happens because data file pages are not written to disk at the same time as the log records. There are data file pages in-memory that are more up-to-date than data file pages on disk.
Checkpoints reduce I/O to disk and improve performance.The reason that data file pages are not written to disk at the time the transaction commits is to reduce the number of I/O operations. Imagine the several thousands of UPDATE transactions to a single data page. It is more efficient to write a data page to disk just once, during a checkpoint, rather than after each change.
Clean and dirty pages
The buffer pool maintains a number of data pages in-memory. There are two types of data pages: clean and dirty. A clean page is one that has not been changed since it was the last read from disk or written to disk. A dirty page is a page that has been changed and the changes have not been written to disk. Checkpoints refer to “dirty pages”.
The information about the page can be seen using sys.dm_os_buffer_descriptors. Let’s see what this function returns:
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
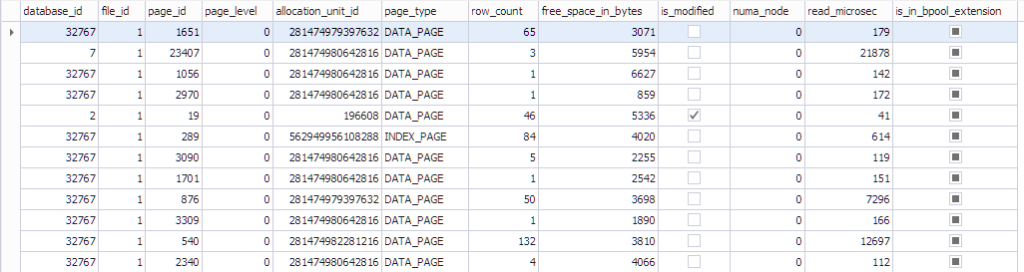
Each page has a control structure associated with it that tracks page state:
- A database that has the datdabase_id 32767 is a read-only Resource Database that contains all the system objects.
- file_id, page_id, allocation_unit_id that page belongs to.
- What kind of page it is: either data page or index page.
- The number of rows on the page.
- The free space on the page
- Whether the page is dirty or not
- The numa_node that the particular page belongs to
- Some info about the Last-Recently-Used algorithm
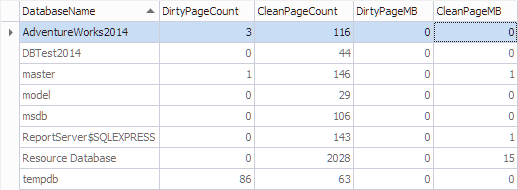
Let’s aggregate this information by database using the following code:
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Checkpoint mechanism
When the checkpoint occurs it writes all dirty pages to disk. Pages marked as dirty as soon as the have some changes. It doesn’t matter whether the transaction that made the change is committed or uncommitted at the time of the checkpoint. After the pages have been written to disk, the “dirty” bit is cleared. When the checkpoint occurs, the following actions take place:
- A new log record indicates a start of a checkpoint
- Additional log records appear with a checkpoint information (like the state of the transaction log at the time when the checkpoint is started)
- All dirty pages are written to disk
- Mark the LSN of the checkpoint in the database boot page (in the dbi_checkptLSN), this is critical for crash recovery
- If SIMPLE recovery model is used, try to clear the log
- A final log record indicates that the checkpoint is done
It is possible for checkpoints of multiple databases to occur in parallel. The SQL Server 2000 was limited to one checkpoint at a time. When the buffer manager writes a page, it searches for adjacent dirty pages that can be included in a single gather-write operation. Also, the buffer pool is going to try to make sure that it doesn’t overload the I/O sub-system. It keeps track of how long does it take for I/O to complete. If the write latency exceeds 20 ms during the checkpoint, it throttles itself. During the shutdown, the throttling threshold increases to 100 ms. You can find a more detailed explanation here. You can use undocumented “-kXX” startup option to set the checkpoint I/O rate at XX MB/s.
When the data file page is written to disk by a checkpoint, write-ahead logging guarantees that all log records affecting that page must be written to the transaction log on disk first. All log records up to and including the last one that affected the page are written out, regardless of which transaction they are part of. Log records are written out in three ways:
- When any transaction commits or aborts
- When data-file page written to disk
- When a log block hits the maximum size of 60KB and forcibly ended
Checkpoint log record
Checkpoints write multiple log records in the transaction log:
- LOP_BEGIN_CKPT — signifies that the checkpoint started
- LOP_XACT_CKPT with NULL context (only if there are uncommitted transactions at the time when the checkpoint started) — contains a count of the number of uncommitted transactions. It also lists the LSNs of the LOP_BEGIN_XACT log records of the uncommitted transactions.
- LOP_BEGIN_CKPT with a context of LOP_BOOT_PAGE_CKPT (SQL Server 2012 only) — signifies that the boot page has been updated.
- LOP_END_CKPT — signifies the end of the checkpoint.
Checkpoint monitoring
It can be useful to correlate checkpoints occurring with spikes in I/O so that changes can be made to the specific database (for the I/O subsystem) to alleviate the I/O spike if it overloads the I/O subsystem. For instance, doing more frequent, manual checkpoints, or configuring a lower recovery interval on SQL Server 2012 with indirect checkpoints. This will produce a more constant I/O load without high spikes that overload the I/O subsystem. However, the root cause may be more I/O being performed because of a change somewhere so do not just accept a sudden increase in checkpoint activity without investigating why it occurred.
The Buffer Manager/Checkpoint pages/sec counter is not database specific so identifying which database is involved requires trace flags or extended events.
Trace flag 3502 writes messages to the error log about which database checkpoint is occurring for.
Trace flag 3504 writes more detailed information about how many pages were written out and the average write latency.
These trace flags are safe to use in production for a limited lime. All they do is print messages in the error log.
If you want to use extended events, there are two events you can use: checkpoint_begin and checkpoint_end.
Summary
In this article, we have talked about checkpoints in SQL Server — the main mechanism for writing data file pages to disk after they have been changed.
Tags: sql server, t-sql Last modified: September 23, 2021





