Introduction
In most scenarios when working with data, users do not require all the data in each instance of a query. T-SQL (and SQL of course) provide means of retrieving only part of a data set in a table or a similar structure. The WHERE, HAVING, TOP and OFFSET-FETCH clauses are used to accomplish this in different ways.
Predicate Logic
Predicate Logic is a foundational concept that is fundamental to Relational Database Management Systems. By definition, a predicate is an expression that evaluates to TRUE, FALSE or UNKNOWN. The result of such expression is often used on filtering clauses like WHERE, HAVING, and JOINS to determine the final result set extracted from a table or a set of tables.
Predicates are typically composed of a column or derivative of a column on one side of an operator which is compared with a value or expression on the other side. When executing an SQL statement which relies on a predicate to filter data, the database engine must evaluate the predicate and then return the result set defined by that predicate.
Filtering Rows
The very common WHERE clause is used to filter rows in T-SQL. WHERE is evaluated at the second stage of the Logical Query Processing sequence in SQL Server. The graphic in Fig. 1 shows the simplified order of clauses in Logical Query Processing. As soon as the table FROM which we must extract data is identified, we must then filter the data so that subsequent clauses are operating on the desired subset of data. This is more efficient than if done otherwise.

Fig. 1 Logical Query Processing
The simplest form of the WHERE clause is well known to many users of SQL and T-SQL. It is the first expression in Listing 1. Other forms are also shown in the Listing.
-- Listing 1: Exploring the WHERE Clause SELECT TOP 10 * from TAB2; -- Simple Predicate with = Operator USE KTrain GO SELECT * FROM TAB2 WHERE FName='Susan'; USE KTrain GO SELECT * FROM TAB2 WHERE EMPID=2; -- Simple Predicate with IN Operator USE KTrain GO SELECT * FROM TAB2 WHERE EMPID IN (2,3,4); -- Simple Predicate with OR Operator USE KTrain GO SELECT * FROM TAB2 WHERE EMPID=2 OR fname='Kenneth'; -- Predicate with Functions USE KTrain GO SELECT * FROM TAB2 WHERE DATEPART(YEAR,[Date of Birth]) >= 1975; -- Predicate with LIKE Operator USE KTrain GO SELECT * FROM TAB2 WHERE Department LIKE 'Info%';
Aside from the equality sign which is the most commonly used operator in the WHERE clauses, many other operators are used in constructing expressions on the right-hand side of predicates. The most common operators are processed in the following order:
- Parenthesis ()
- Multiplication Division and Modulo (* , / , % – )
- Positive, Negative, Addition, Concatenation, Subtraction (+, -)
- Comparison Operators (=, >, <, >=, <=, <>,!= , !>, !<)
- NOT
- AND
- BETWEEN, IN, LIKE, OR
- Assignment (=)
This implies that in order to guarantee some level of predictability when using complex expressions in your predicate, you should make use of parenthesis to explicit determine which parts of the expression are executed first. There are also important things one must know about the columns used in the WHERE clause:
- The way the Query Optimizer harnesses indexes is often dependent on whether the column(s) referred to in the WHERE clause are indexed
- When you use the function as part of a WHERE clause, it is likely that this behavior will be impacted and you will see a drop in performance
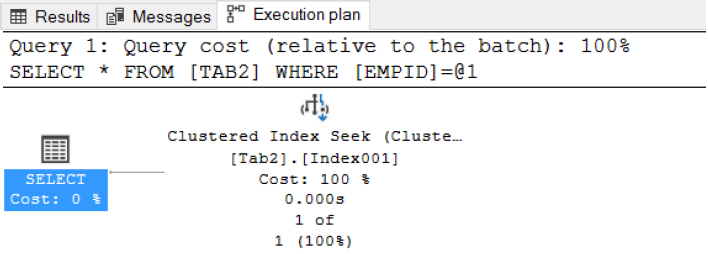
Fig. 2 Index Column: Clustered Index Seek in Execution Plan
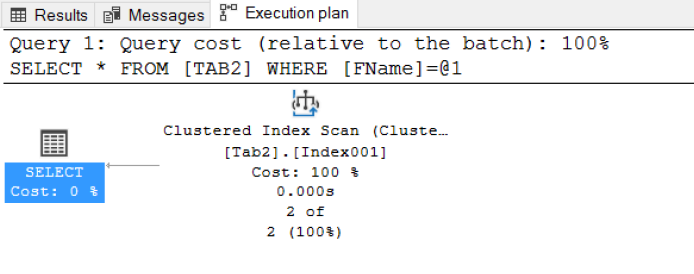
Fig. 3 Non-Index Column: Clustered Index Scan in Execution Plan
Filtering Groups of Rows
T-SQL provides a technique to organize a data set into groups of rows to perform aggregate operations on each group. Once these groups are achieved, it is then possible to filter the groups of rows using the HAVING Clause. The HAVING clause is essentially a way to filter groups in the same way the WHERE clause is used to filter rows.
The HAVING clause accepts predicates similar to the way the WHERE clause does except when the elements of the predicate are not columns themselves but aggregate expressions.
-- Listing 2: Exploring the HAVING Clause USE KTrain GO SELECT * from TAB2; -- HAVING Operator with COUNT Aggregate Function USE KTrain GO SELECT CountryCode, COUNT(*) FROM TAB2 GROUP BY CountryCode HAVING COUNT(*)=10; -- HAVING Operator with SUM Aggregate Function USE KTrain GO SELECT FName, SUM(Salary) FROM TAB2 GROUP BY FName HAVING SUM(Salary)>1;
Listing 2 shows samples of the COUNT and SUM aggregate functions being used in the HAVING clause. It’s worth mentioning that the HAVING clause is used to filter groups of rows in a similar way as the WHERE clause is used to filter individual rows.
Sampling Data Sets
In practice, regular users of SQL Server try to get a quick view of the data in a table or something as simple as viewing the structure by attempting to retrieve the entire data set using SELECT * FROM TABx. When one hits a large table – this is typically not a good idea. Using the TOP clause one can quickly sample the data in a table. When used by itself, the result set returned by the TOP clause is non-deterministic but when it’s used with the ORDER BY clause, you get the top N rows or the top N percent of rows based on the column used in the ORDER BY clause.
-- Listing 3: Exploring the TOP Clause -- Top 5 Rows (Non-deterministic) USE KTrain GO SELECT TOP 5 * FROM TAB2; -- Top 5 Rows (Determined by ORDER BY clause) USE KTrain GO SELECT TOP 5 * FROM TAB2 ORDER BY lname; -- Top 5 Rows WITH TIES USE KTrain GO SELECT TOP 5 WITH TIES * FROM TAB2 ORDER BY lname; -- Top 5 Rows WITH TIES USE KTrain GO UPDATE TOP (5) TAB2 SET CountryCode='NG' WHERE FName='Kenneth';
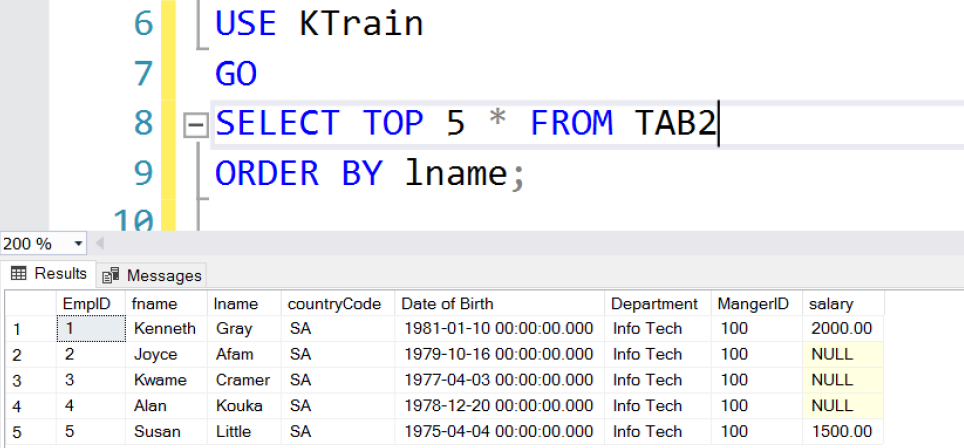
Fig. 4 TOP 5 Rows without ORDER BY
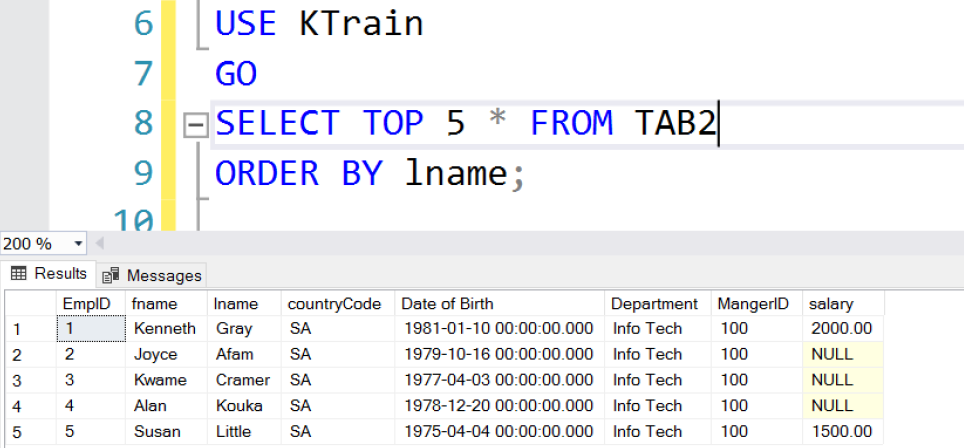
Fig. 5 TOP 5 Rows with ORDER BY
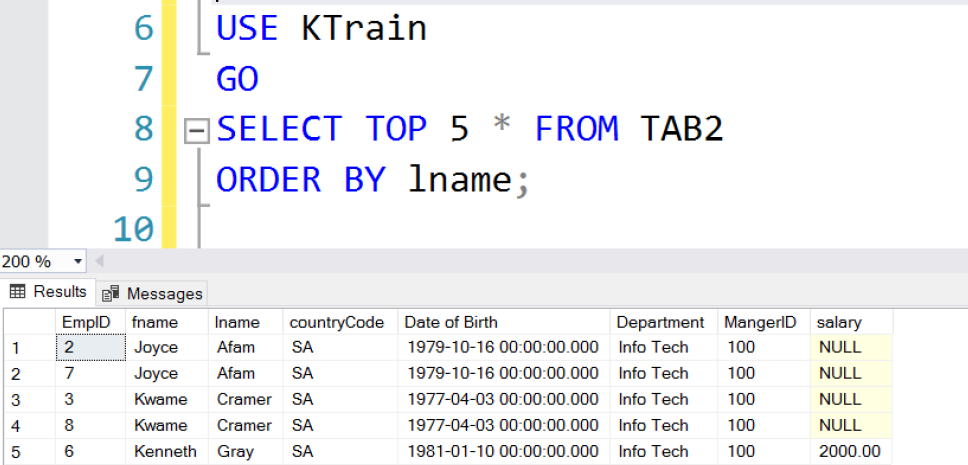
Fig. 6 TOP 5 Rows without ties
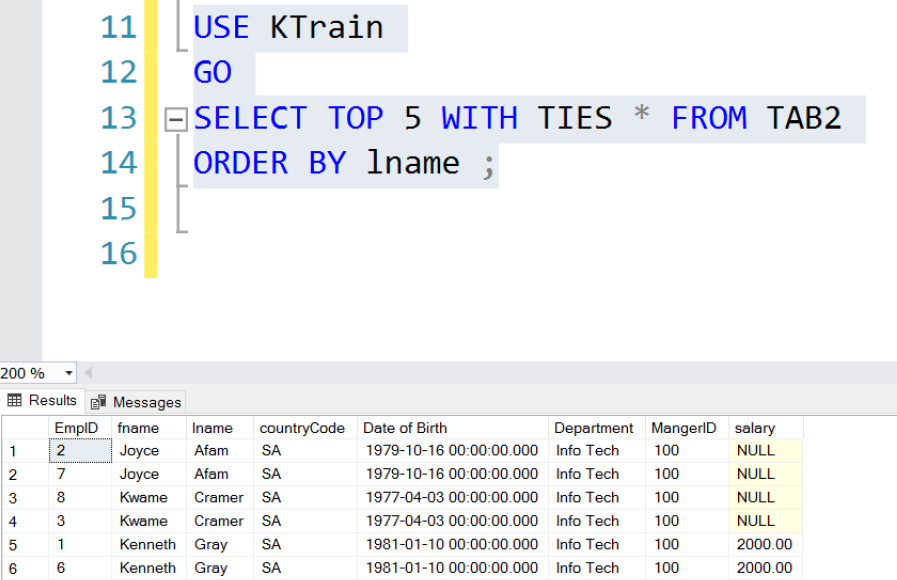
Fig. 7 TOP 5 Rows with ties
The WITH TIES clause includes rows with the same rank (based on a column in the ORDER BY clause). Figs 4, 5, 6 and 7 show the use of the TOP clause in the various ways already described. Also, note as shown in Listing 3 that TOP can be used in UPDATE statements.
Paging Data Sets
In addition to the TOP clause, we also have a use case where a user navigating a front-end application needs to sift through millions of rows of data. We find that attempting to load the entire data set at a go would be inefficient. The TOP clause allows us to view the first N rows of data or the first N PERCENT of data but we may need to see the NEXT N and so own. The OFFSET-FETCH command allows us to do this.
-- Listing 3: Exploring OFFSET-FETCH USE KairosTraining GO SELECT * FROM TAB1 ORDER BY fname OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY; USE KairosTraining GO SELECT * FROM TAB1 ORDER BY fname OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
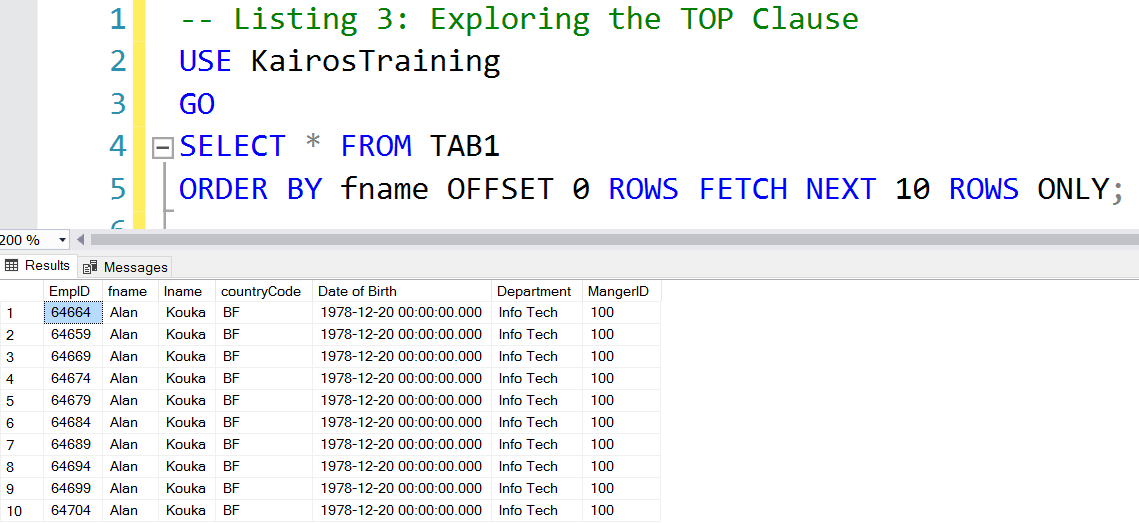
Fig. 8 First Page of an OFFSET-FETCH Query
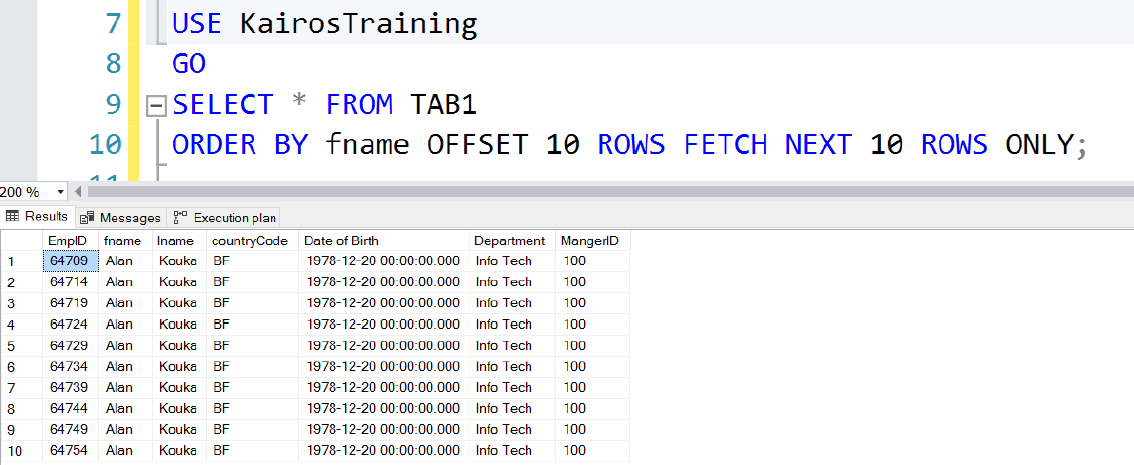
Fig. 9 Second Page of an OFFSET-FETCH Query
The largest cost associated with a query involving the TOP or OFFSET-FETCH clauses is the sorting. It is also important to realize that internally, SQL Server is using the same underlying mechanism to realize the OFFSET-FETCH results as it does for a TOP query. TOP is unique to Microsoft products while OFFSET-FETCH is ANSI-compliant.
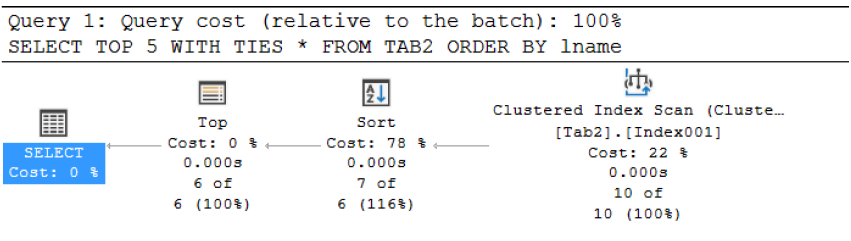
Fig. 10 Execution Plan for a TOP Query
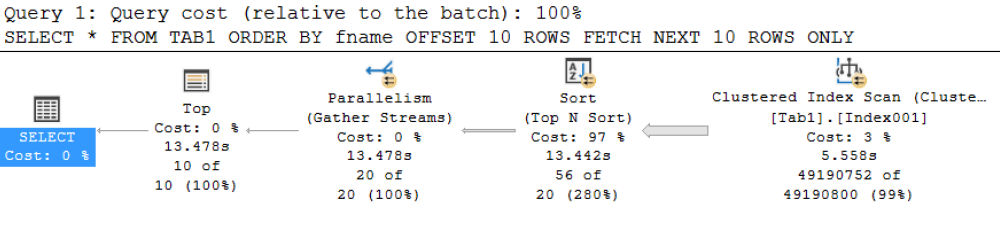
Fig. 11 Execution Plan for an OFFSET-FETCH Query
Conclusion
In this article, we have seen the various ways T-SQL allows us to extract subsets of data based on the conditions we define. In the case of the WHERE and HAVING clauses, a predicate is explicitly required. The TOP and FETCH simply return subsets of the data set based on some order.
References
- TOP (Transact-SQL)
- SELECT – ORDER BY Clause
- Ben-Gan, I. (2016) T-SQL Fundamentals. Microsoft Press






