Introduction
Transaction Log Shipping is a very well-known technology used in SQL Server to maintain a copy of the live database in the Disaster Recovery Site. The technology depends on three key jobs: the Backup Job, the Copy Job, and the Restore Job. While the Backup job runs on the Primary Server, the Copy and Restore jobs run on the Secondary Server. Essentially the process involves periodic transaction log backups to a share from which the Copy Job moves same to the Secondary Server; subsequently, the Restore Job applies the log backups to the secondary server. Before all this starts, the Secondary Database must be initialized with a full backup from the Primary server restored with NORECOVERY option.
Microsoft provides a set of stored procedure that can be used to configure Log Shipping end to end as well as GUI equivalents starting from the properties item of each database you may want to configure Log Shipping for. It is worth noting that the Secondary Database can be configured in NORECOVERY mode or in STANDBY mode. In NORECOVERY mode the database is never ever available for queries but in STANDBY mode, the Secondary database can be queried when no Transaction log restore operation is ongoing.
Setting Up the Environment
To get the ball rolling, we create two SQL Server instances on AWS with an identical Amazon EC2 image. This Amazon EC2 instance is running SQL Server 2017 RTM-CU5 on Windows Server 2016. Then we restore a copy of the WideWorldImporters database using a backup set acquired from GitHub to the first instance, our Primary Instance. We use the same backup set to create two identical databases named BranchDB and CorporateDB.
Fig. 1 SQL Server Version
Fig. 2 BranchDB and CorporateDB on Primary Instance (Secondary Instance Blank)
Listing 1: Restoring WideWorldImporters Sample Database
restore filelistonly from disk='WideWorldImporters-Full.bak' restore database CorporateDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_1.ndf' restore database BranchDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary1.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData1.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log1.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_11.ndf
We now have two instances, the Primary Instance hosting the two Primary databases (BranchDB and CorporateDB and the Secondary instance with no user databases. We proceed with configuring Transaction Log Shipping on both databases but differentiate them by applying a delay to the restore configuration of the first database. Recall that the databases are actually identical in terms of the data they contain. The following graphics show the key options selected in the Log Shipping Configuration.
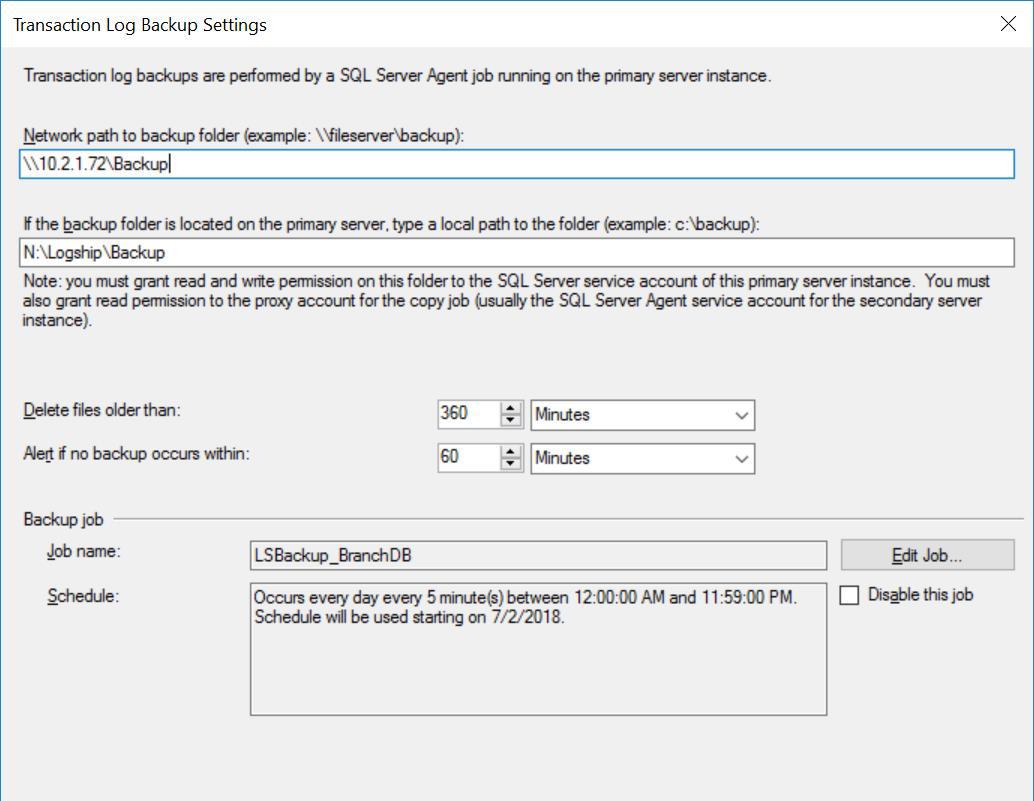
Fig. 3 Backup Settings for BranchDB
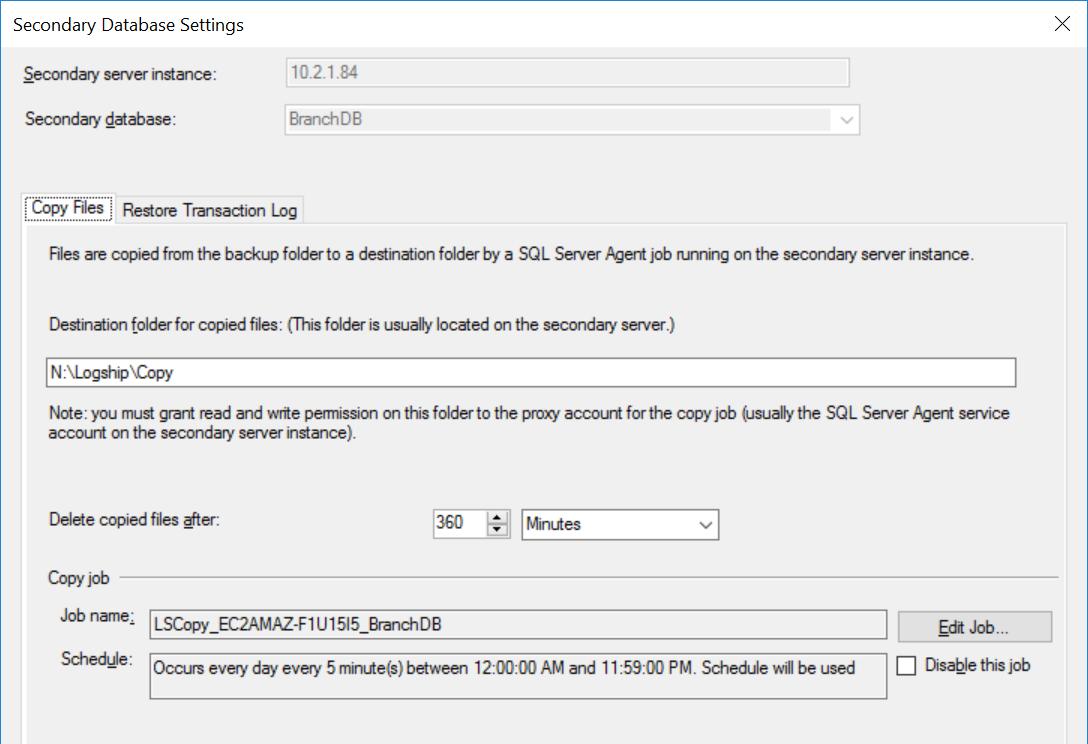
Fig. 4 Copy Settings for BranchDB
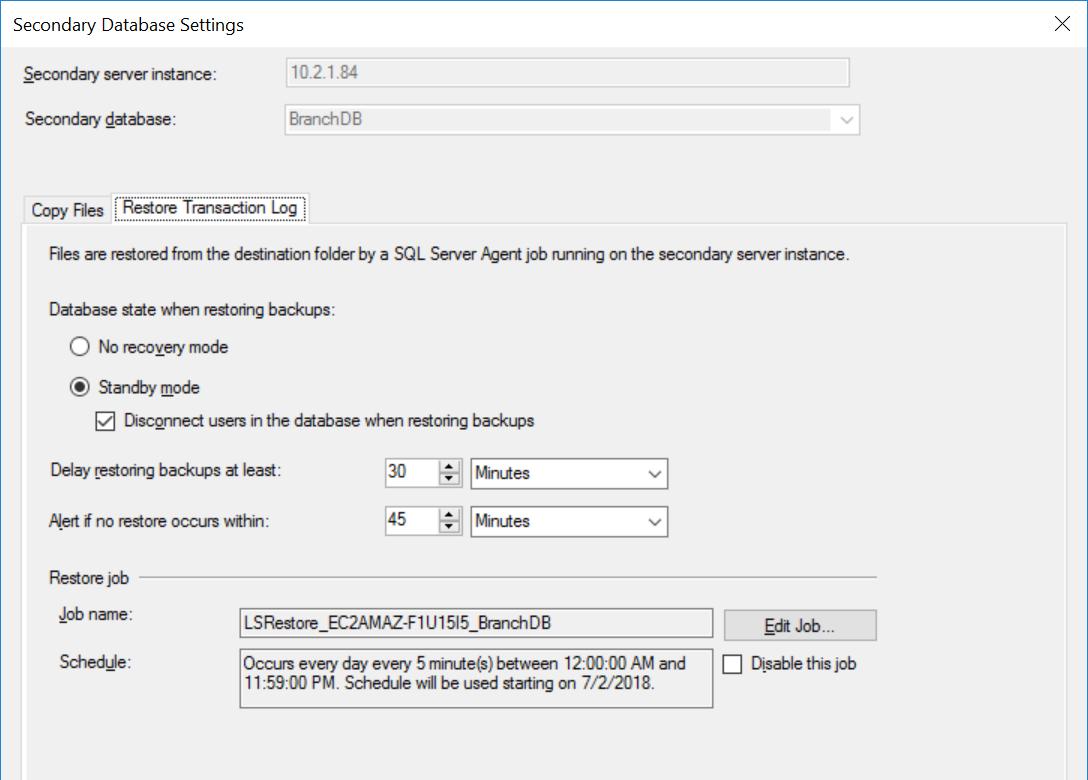
Fig. 5 Restore Settings for BranchDB
Each Log Shipping job is configured to run every five minutes. To process “Delay Restoring Backups”, we must use the Standby Recovery mode in the Log Shipping configuration. It is logical since it has the Secondary Database in standby mode and indicates that we can query the Secondary Database whenever a Transaction Log Restore is not ongoing. The value we specify in this option (30 minutes in this case) gives us a good window during which we can run reports off the Secondary Database apart from the core requirement of this article which is being able to recover from user error.
Also, we should mention that the restore of transaction log backups actually is being delayed. Its timestamp is later than the delay value. This means that all transaction log backups will be copied to the secondary server, which is based on the schedule and specified in the Copy Job. In fact, the Restore Job will still run on schedule but transaction log backups (that are not up to 30 minutes old) will not be restored. In essence, the BranchDB Standby database is 30 minutes behind the BranchDB primary database. To demonstrate this lag, in the next section, we shall create a table in both databases and create a job which inserts a record every minute. We will examine this table in the Secondary Databases.
The Settings for the CorporateDB Database are the same as in Figs. 3 to 5, except for the Restore Job which is NOT set to delay transaction log backups.
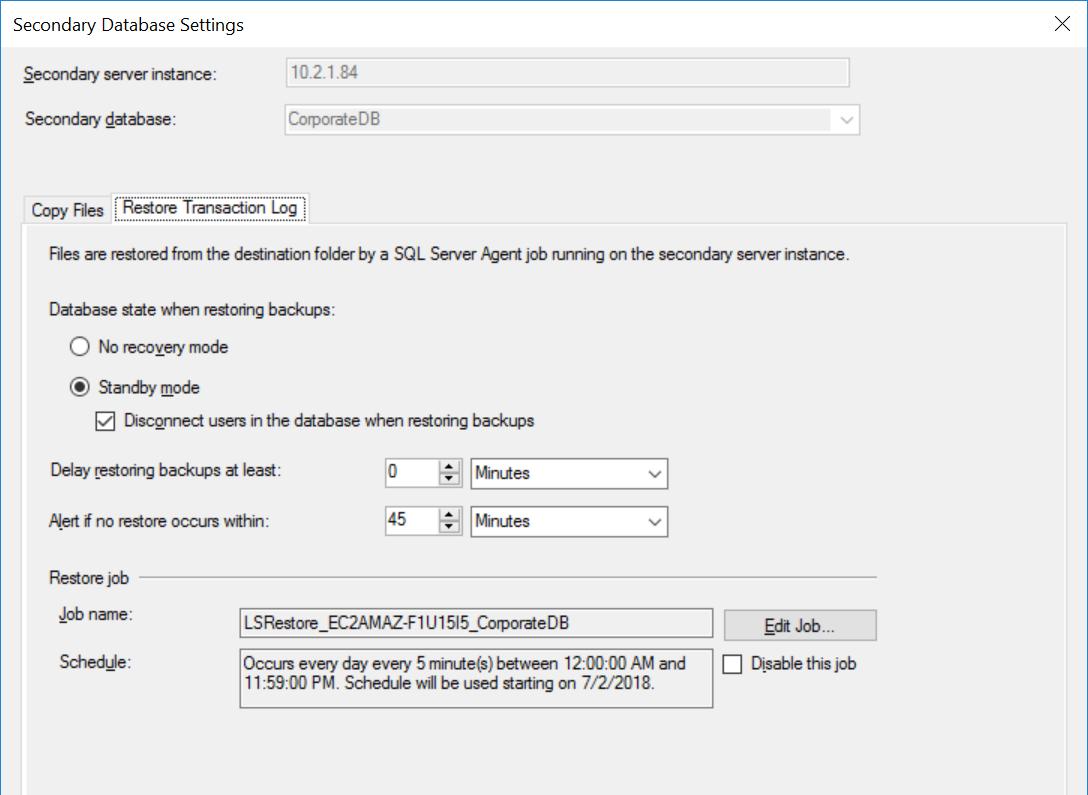
Fig. 6 Restore Settings for CorporateDB
Verifying the Configuration
Once the configuration is done, we can verify that the configuration is OK and start with observing of its work. The Transaction Log Shipping Report shows us that the Branch DB is indeed lagging the CorporateDB in terms of restores:
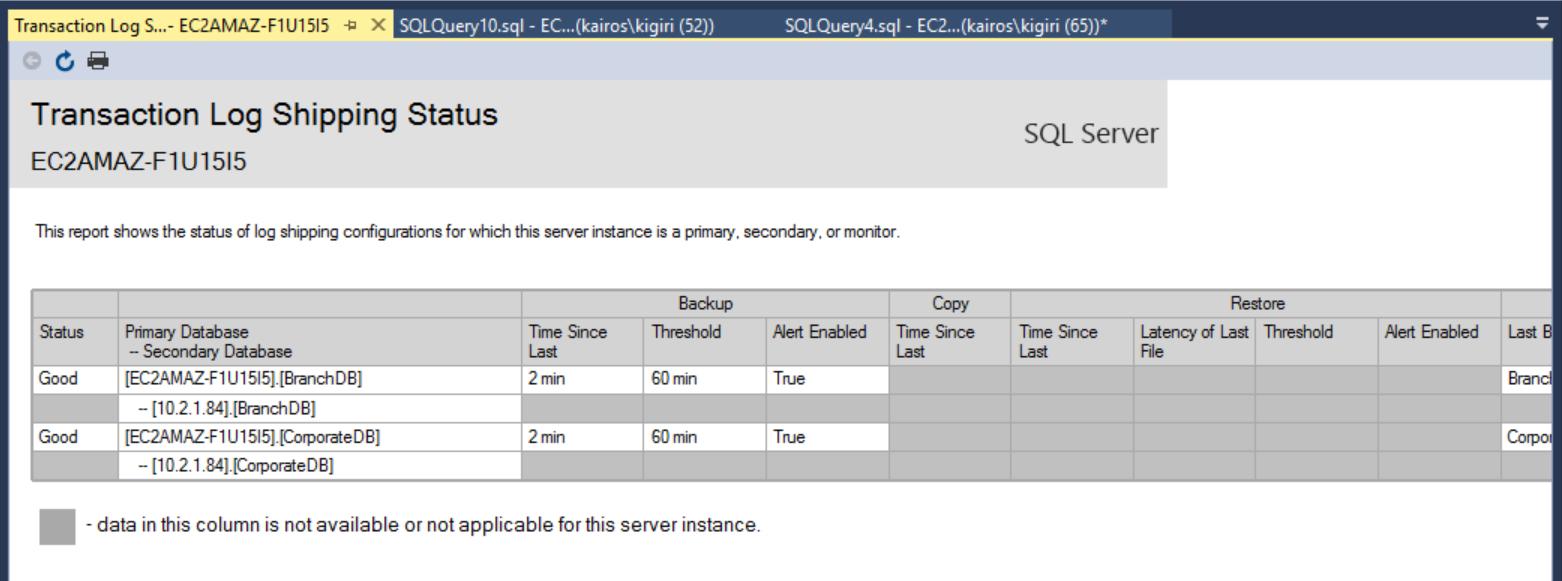
Fig. 7a Transaction Log Shipping Report on Primary Server
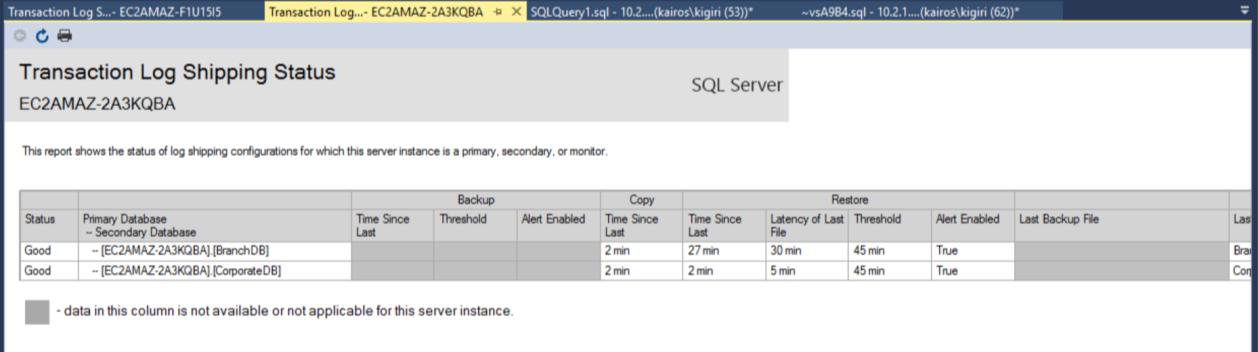
Fig. 7b Transaction Log Shipping Report on Secondary Server
In addition, you will notice the message below in the Restore Job history for the BranchDB:
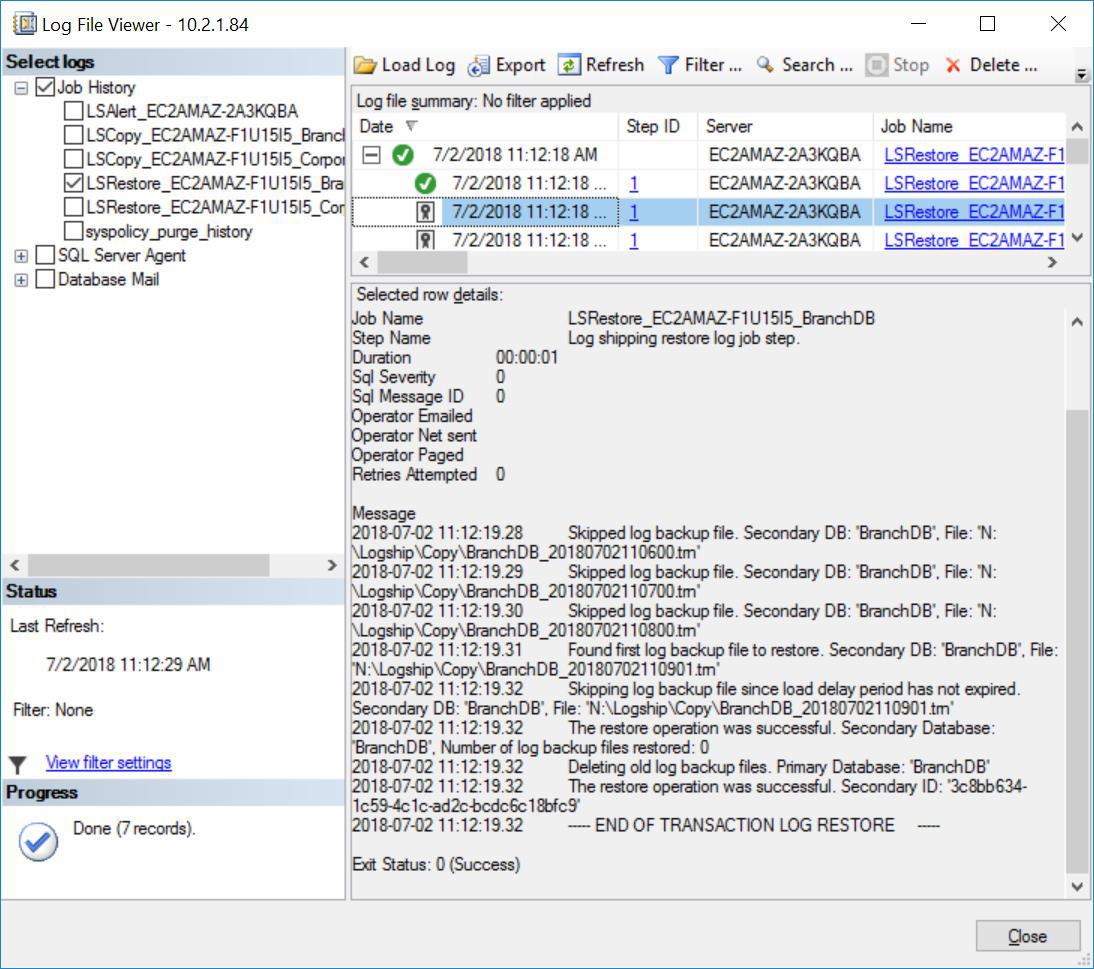
Fig. 8 Skipped Transaction Log Restores on Secondary Server
We can go further with this verification by creating a table and using a job to populate this table with rows every minute. The job is a simple way of simulating what an application might be doing to a user table. This can show us the that this lag is definitely shown in user data.
Listing 2 – Create Log Tracker Table
use BranchDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername) use CorporateDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername)
Listing 3 – Create Job to Populate Log Tracker Table
/* ==Scripting Parameters== Source Server Version : SQL Server 2017 (14.0.3023) Source Database Engine Edition : Microsoft SQL Server Standard Edition Source Database Engine Type : Standalone SQL Server Target Server Version : SQL Server 2017 Target Database Engine Edition : Microsoft SQL Server Standard Edition Target Database Engine Type : Standalone SQL Server */ USE [msdb] GO /****** Object: Job [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ BEGIN TRANSACTION DECLARE @ReturnCode INT SELECT @ReturnCode = 0 /****** Object: JobCategory [[Uncategorized (Local)]] Script Date: 7/2/2018 3:32:00 PM ******/ IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1) BEGIN EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback END DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'InsertRecords', @enabled=1, @notify_level_eventlog=0, @notify_level_email=0, @notify_level_netsend=0, @notify_level_page=0, @delete_level=0, @description=N'No description available.', @category_name=N'[Uncategorized (Local)]', @owner_login_name=N'kairos\kigiri', @job_id = @jobId OUTPUT IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback /****** Object: Step [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'InsertRecords', @step_id=1, @cmdexec_success_code=0, @on_success_action=1, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N'TSQL', @command=N'use BranchDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) use CorporateDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) GO', @database_name=N'master', @flags=0 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @job_id=@jobId, @name=N'Schedule', @enabled=1, @freq_type=4, @freq_interval=1, @freq_subday_type=4, @freq_subday_interval=1, @freq_relative_interval=0, @freq_recurrence_factor=0, @active_start_date=20180702, @active_end_date=99991231, @active_start_time=0, @active_end_time=235959, @schedule_uid=N'03e5f1b2-2e0b-4b30-8d60-3643c84aa08d' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback COMMIT TRANSACTION GOTO EndSave QuitWithRollback: IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION EndSave: GO
When we query the table on the Primary Databases respectively, we can confirm (by using the RecordTime column) that the rows match in BranchDB and CorporateDB. When we examine the table in the Secondary Databases, in the same way, we see clearly that we do have a 30-minute gap between BranchDB and CorporateDB.
Listing 4 – Querying the Log Tracker Table
select top 10 @@servername [Current_Server],* from BranchDB.dbo.log_ship_tracker order by RecordTime desc select top 10 @@servername [Current_Server], * from CorporateDB.dbo.log_ship_tracker order by RecordTime desc
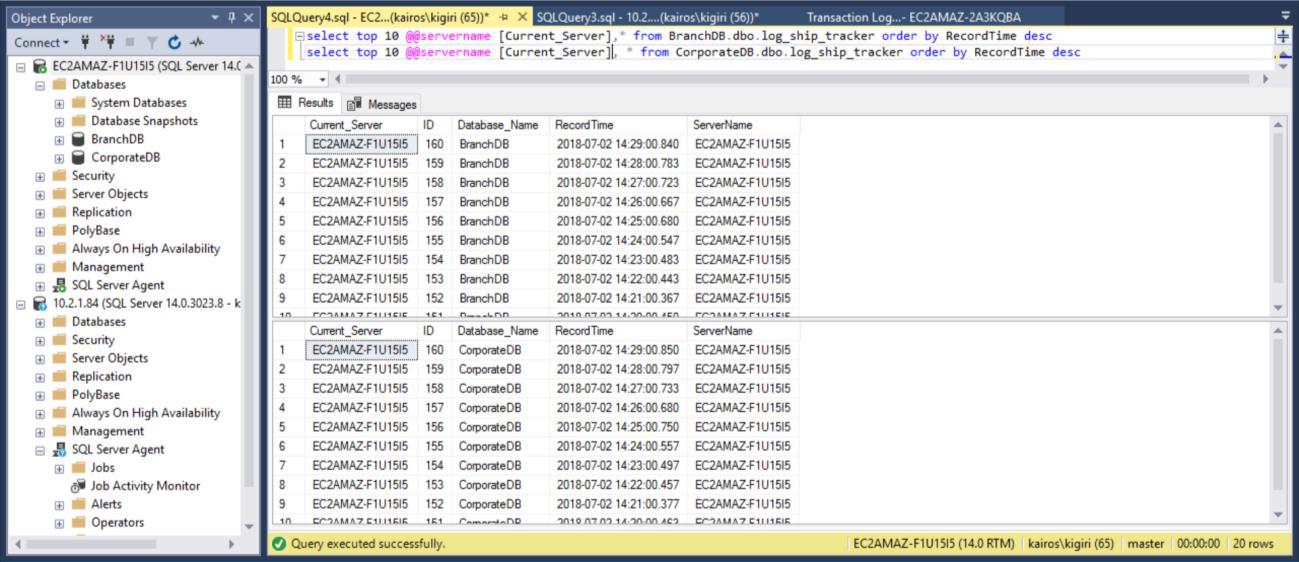
Fig. 9 Log Tracker Tables Match in Primary Databases
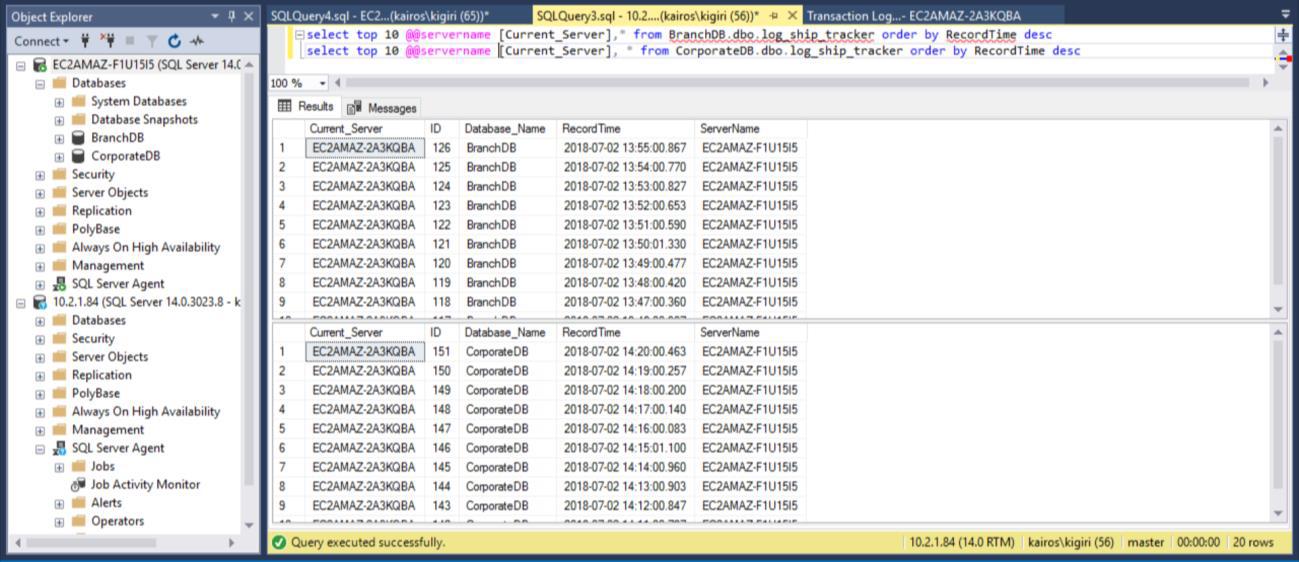
Fig. 10 Log Tracker Tables Have a ~30-Minutes Gap in Secondary Databases
Recovering from User Error
Now let’s talk about the key benefit of this delay. In the scenario, where a user inadvertently drops a table, we can recover the data quickly from the Secondary Database as long as the Delay period has not elapsed. In this example, we drop the table Sales.Orderlines on BOTH databases and verify that the table no longer exists in BOTH databases.
Listing 5 – Dropping Orderlines Table
drop table BranchDB.Sales.Orderlines drop table CorporateDB.Sales.Orderlines GO use BranchDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO use CorporateDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO
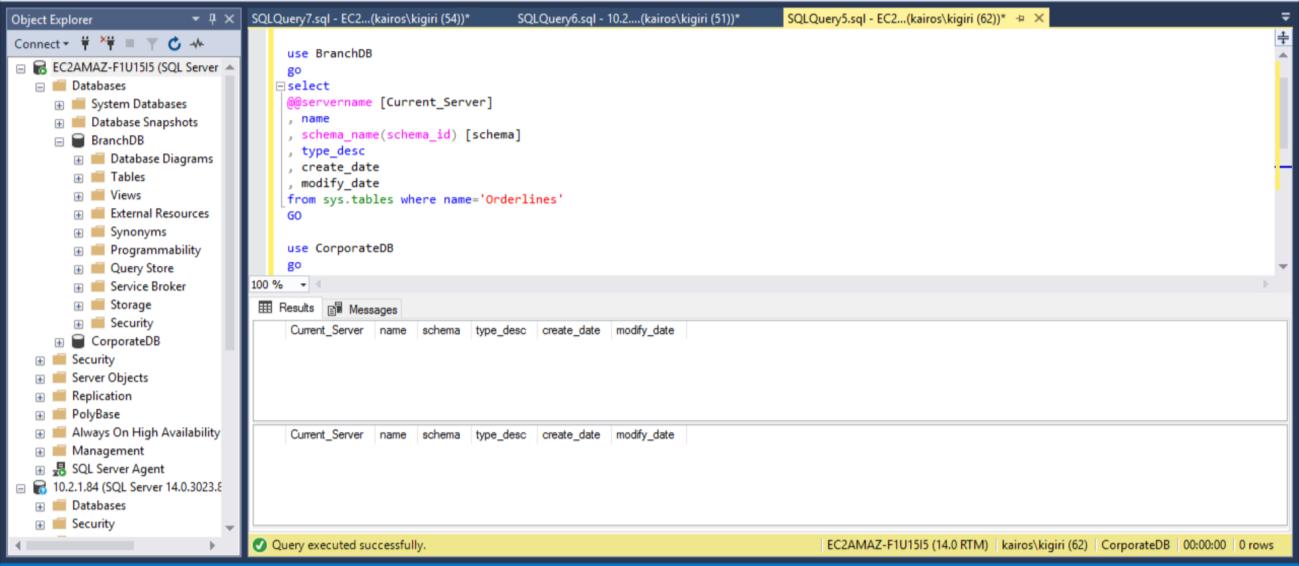
Fig. 11 Dropping Table Sales.Orderlines
When we look for the table on the Secondary Server, we find that the table is still available in BOTH databases. Thus, for CorporateDB we have less than five minutes to recover the data. (Fig. 12). But once the next restores Cycle executes, we lose the table in the Corporate DB database. To recover this table, we need to do point-in-time recover using a full backup in a separate environment and then extract this specific table. You will agree that it will take some time. For the BranchDB Orderlines table, we have a little more time and we can recover the table with a single SQL Statement over a Linked Server (see Listing 6).
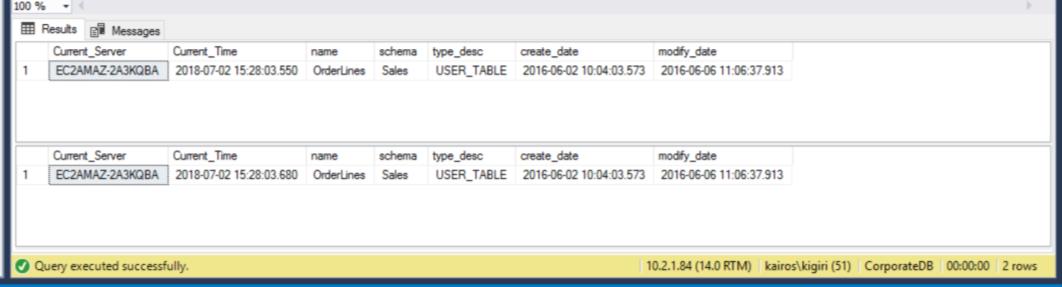
Fig. 12 Five Minutes Countdown: Table Exists in Both Secondary Databases
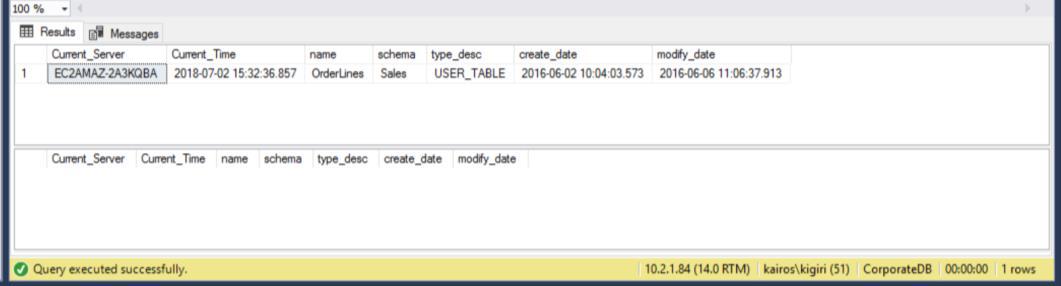
Fig. 13 Additional 25 Minutes to Recover the BranchDB Table
Listing 6 – Recover Orderlines Table
USE [master] GO /****** Object: LinkedServer [10.2.1.84] Script Date: 7/2/2018 4:14:59 PM ******/ EXEC master.dbo.sp_addlinkedserver @server = N'10.2.1.84', @srvproduct=N'SQL Server' /* For security reasons the linked server remote logins password is changed with ######## */ EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'10.2.1.84',@useself=N'True',@locallogin=NULL,@rmtuser=NULL,@rmtpasswo rd=NULL GO select * into BranchDB.Sales.Orderlines from [10.2.1.84].BranchDB.Sales.Orderlines
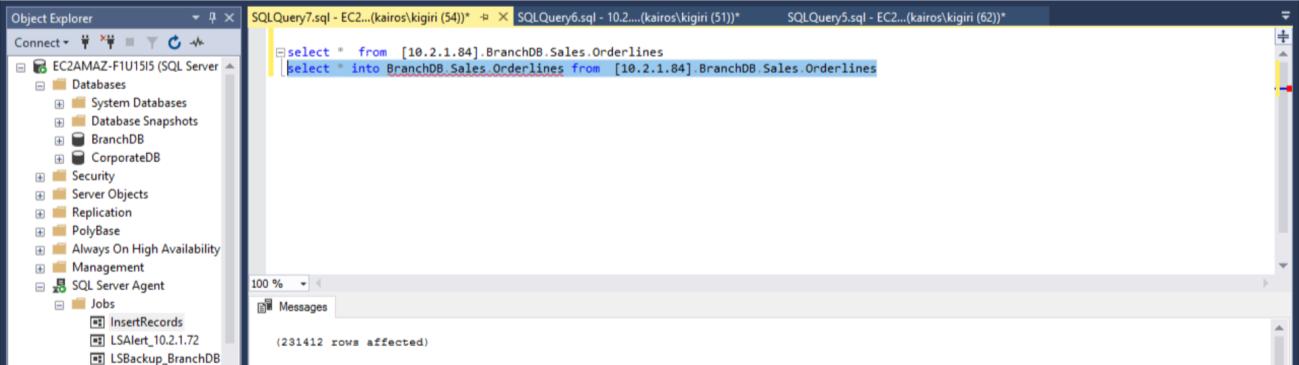
Fig. 14 Recover the BranchDB Sales.Orderlines Table
Then we verify the Primary Server (BranchDB Database) that the table is restored.
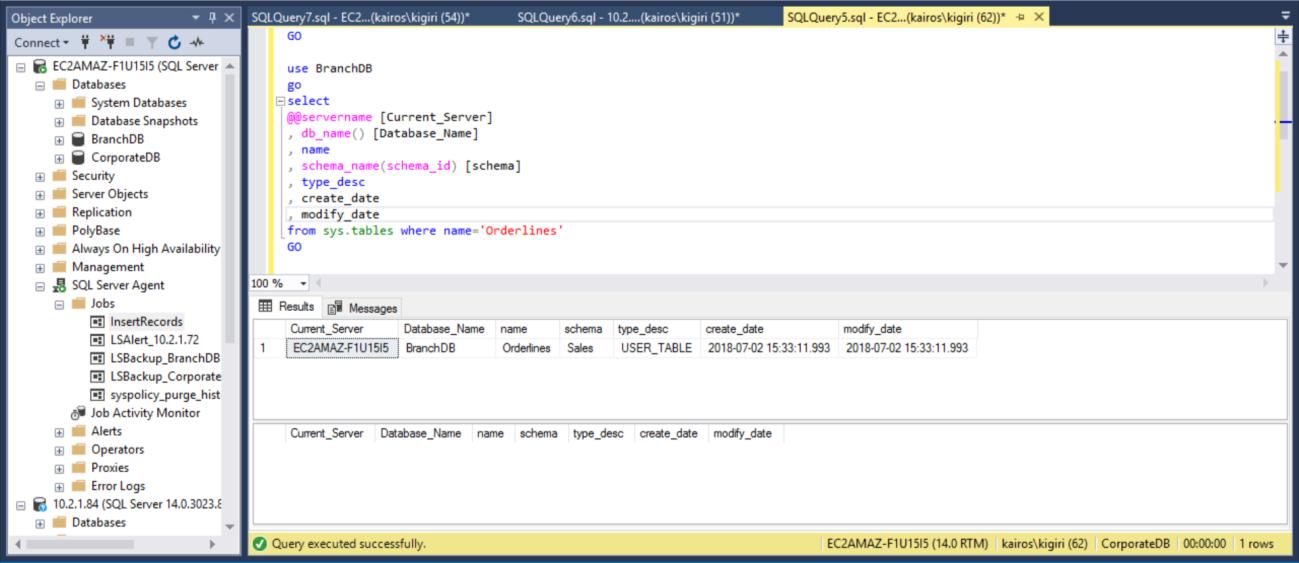
Fig. 15 Recover the BranchDB Sales.Orderlines Table
Conclusion
SQL Server provides a number of way of recovering from data loss from a variety of root causes – disk failure, corruption, user error etc. Point-in-time recovery from backups is probably the most well-known of these methods. For certain simple cases of user error or the similar case, where one or two objects are lost, usage of Transaction Log Shipping with Delayed Recovery is a good approach to consider. However, it should be noted that a secondary database, which is configured strictly for DR needs, has to be selected for lower RPOs.
Tags: database administration, database backup, sql server, transaction log Last modified: September 22, 2021





