
Hi there, newbie. Are you still using multiple INSERT statements to insert multiple rows in SQL Server?
Let me tell you today that it’s a terrible idea. It gives you an agonizing feeling when your database inserts become like a slow-motion scene in The Matrix. You love the movie scene. But you don’t want it happening in your database.
But let me tell you too that there’s a way to get over this. It’s not a band-aid solution. It’s what DBA heroes do. They save the day by freeing the database to a crawling state. And it’s not even hard to do.
In this article, let’s dive into inserting multiple rows in SQL Server correctly. Here’s how the discussion will go:
- Using Separate INSERT Statements – How Bad Is It?
- Insert Multiple Rows in SQL Server Using VALUES
- INSERT Multiple Rows in SQL Server From Another Table
So, put on your shiny DBA cape, and let’s begin.
Using Separate INSERT Statements – How Bad Is It?
Before I give you the hero power-ups for multiple INSERTs, let me convince you first how bad it is.
But if you haven’t done inserting multiple rows in SQL Server, soon you will. Because you might process a big chunk of data and insert its final values into a table. Or you simply need a script to prepare new rows to a brand-new table for the first time. Or maybe send new rows from an app into the database.
It’s good to learn this now. But if you’re doing it the wrong way for quite some time, it’s time to put this aside.
Here’s why using multiple INSERT statements is a terrible idea:
Errors May Result in Half-Baked, Inconsistent Data
Suppose you have 3 INSERT statements like the one below.
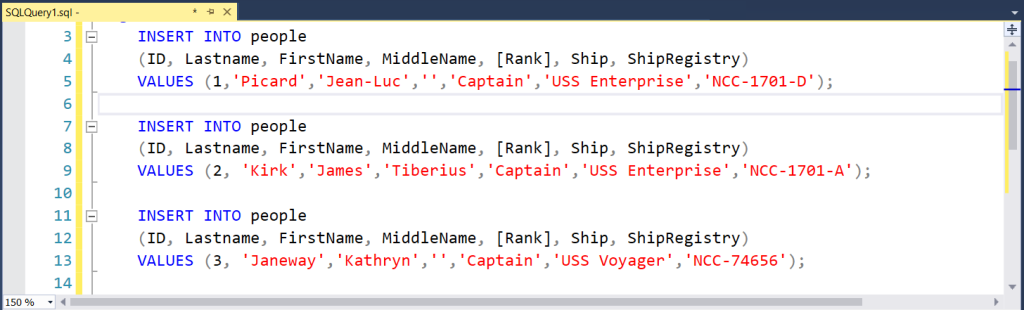
Looks simple enough. What can go wrong?
Suppose an error occurs running the third INSERT statement in line 11. The first 2 INSERTs are a success. So, rows with ID numbers 1 and 2 exist. But ID number 3 does not. If these statements belong to one transaction unit, it is now inconsistent. Even worse, what if there’s a follow-up INSERT in a child table? If that depends on ID #3, it will also fail.
This is a lack of atomicity in a database management system. If one statement fails, it should be like nothing happened. It’s all or nothing.
To explain this further, let’s say you want to transfer money from your bank account to your friend’s bank account. The transaction involves 2 steps. First, deduct the money from your account. Then, add the money to your friend’s account. If the first step is good and the second went bad and failed, you ended up losing money. And your friend didn’t get any. It should roll back like nothing happened. That’s atomicity.
But you may say: “If that’s the case, start with BEGIN TRANSACTION and ROLLBACK when an error occurs.” You could be right, but…
An Increase in Transaction Overhead May Occur
Adding transactions to cover multiple INSERT statements could be a good idea. But let’s say the INSERT fails at line 11 from the previous example. SQL Server will have to roll back the previous 2 INSERT statements.
So, how is it bad?
Because using just 1 INSERT statement for all 3 rows may be easier for SQL Server to rollback. Did you get it? Rollback just 1 INSERT instead of 2. Now, this can’t be a big deal. Of course, what are 3 rows in SQL Server? But what if this is 3,000 rows? Or maybe 30,000? Don’t fix your mind to just 3 rows.
Not to mention that this is happening in a multi-user environment of thousands of users. Others can perform other INSERTs. And others are updating. Or maybe deleting. In this scenario, a rollback or commit of a thousand rows may result in another problem.
Performance Impact – Your Database is Now Crawling
There can be other factors that can make a database crawl. But your many INSERT statements may run longer. And it can happen along with other DML commands. Then it may cause locking and blocking issues. This means that when your transaction holds a lock on a resource, others will have to wait. And when this happens, your system will have more waiting. And this is bad for users (and you!). You can’t make them wait. They don’t want to.
And yet, multiple INSERT statements affect you too in the long run.
Code is Harder to Maintain
Seeing a lot of INSERT statements compared to better approaches is bad for you if you maintain the code. Or if anyone is maintaining the code. You’ll see repeated INSERT INTO tables using the same columns. The approaches you’ll see later are more friendly to your eyes.
Note that the problems presented here may or may not appear in your specific use case. Maybe not now. It depends on your use case, the number of rows, and the requirements. Use tools like extended events. Or examine the execution plans to see how they will impact your system.
Now when you know how bad it can be, let’s proceed to the first tip.
Insert Multiple Rows in SQL Server Using VALUES
But isn’t that what we’ve been doing?
For the uninitiated, you can use several row values with the VALUES clause. Here’s the syntax:
INSERT INTO table (column1, column2, column3, columnN)
VALUES (value1a, value2a, value3a, valueNa),
(value1b, value2b, value3b, valueNb),
(value1c, value2c, value3c, valueNc),
...
(value1N, value2N, value3N, valueNN); Enclosed in parenthesis comprises one row. And a comma separates each row. Note that you can only add value clauses for up to 1000 rows in SQL Server 2022.
Examples of Using Many VALUES Clause
Let’s start by converting the example earlier into 1 INSERT statement. Let’s have the CREATE TABLE first.
CREATE TABLE [dbo].[people](
[ID] [int] NOT NULL,
[Lastname] [varchar](50) NOT NULL,
[FirstName] [varchar](50) NOT NULL,
[MiddleName] [varchar](50) NULL,
[Rank] [varchar](20) NOT NULL,
[Ship] [varchar](50) NOT NULL,
[ShipRegistry] [varchar](20) NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[people] ADD DEFAULT ('') FOR [MiddleName]
GO
ALTER TABLE [dbo].[people] ADD DEFAULT (getdate()) FOR [ModifiedDate]
GO Now, here’s the INSERT statement:
INSERT INTO people
(ID, Lastname, FirstName, MiddleName, [Rank], Ship, ShipRegistry)
VALUES (1,'Picard','Jean-Luc','','Captain','USS Enterprise','NCC-1701-D'),
(2, 'Kirk','James','Tiberius','Captain','USS Enterprise','NCC-1701-A'),
(3, 'Janeway','Kathryn','','Captain','USS Voyager','NCC-74656'); Isn’t it much better?
Here’s another example using the AdventureWorks sample database. If you don’t have it, you can download it from here. Pick the one for the SQL Server version you have.
USE AdventureWorks
GO
INSERT INTO Person.BusinessEntity
(rowguid,ModifiedDate)
VALUES (default,default),
(default,default);Notice that we used default as the values for 2 columns. Since they have default values in their table definition, these won’t give you errors. And the statement above results in 2 rows added to the BusinessEntity table. You can do the same for any table column with default values.
Aside from typing everything in the code window, you can use a GUI tool like the example here. It uses dbForge Studio for SQL Server and it’s Query Builder for creating INSERT statements. Another example is using the generated INSERT script using the same tool.
Insert Multiple Rows in SQL Server From Another Table
You can use the result of a SELECT statement to insert multiple rows in SQL Server. This can happen when you need to copy data from the production server to the development server. Or, you may process some data from several tables in the same server. And then, insert the final result into another table.
Examples Using SQL INSERT From Another Table
Example 1: Insert Rows from a Linked Server
The example below assumes 2 linked SQL Servers. It will insert movie titles from the production server to the development server.
INSERT INTO development.dbo.Titles
(Title, ReleaseDate, OverallUserRating)
SELECT
Title, ReleaseDate, OverallUserRating
FROM production.movies.dbo.Titles; If both tables are the same, this can also work:
INSERT INTO development.dbo.Titles
SELECT
Title, ReleaseDate, OverallUserRating
FROM production.movies.dbo.Titles; Or, even this:
INSERT INTO development.dbo.Titles
SELECT *
FROM production.movies.dbo.Titles; But use caution when using SELECT *. If your key column is an IDENTITY column, you may encounter an error. The same may happen when the number of columns from the source is different from the target. Or, the column arrangement is different.
Simple SELECT statements are not the only option. You can use a SELECT with a CASE statement, a join, and more complex SELECT queries.
Example 2: Summarize Sales with Query Performance Optimization in Mind
Another way to make your database crawl is by crafting queries that don’t perform well. In this example, let’s use the AdventureWorks database sample again. And let’s summarize the sales per product category. Let’s limit the sales period to the year 2014. Then, we insert the results into a new table called Sales.ProductCategorySalesPerMonth.
Let’s define the table first.
USE AdventureWorks
GO
CREATE TABLE Sales.ProductCategorySalesPerMonth (
OrderYear int NOT NULL,
OrderMonth int NOT NULL,
CategoryName dbo.Name NOT NULL,
TotalSales money NOT NULL DEFAULT 0.00
)
ON [PRIMARY]
GO Now here’s the INSERT statement:
INSERT INTO Sales.ProductCategorySalesPerMonth
(OrderYear, OrderMonth, CategoryName, TotalSales)
SELECT
YEAR(OrderDate) AS OrderYear
,MONTH(OrderDate) AS OrderMonth
,ProductCategory.Name AS CategoryName
,SUM(OrderQty * UnitPrice) AS TotalSales
FROM Sales.SalesOrderHeader
INNER JOIN Sales.SalesOrderDetail
ON SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID
INNER JOIN Production.Product
ON SalesOrderDetail.ProductID = Product.ProductID
INNER JOIN Production.ProductSubcategory
ON Product.ProductSubcategoryID = ProductSubcategory.ProductSubcategoryID
INNER JOIN Production.ProductCategory
ON ProductSubcategory.ProductCategoryID = ProductCategory.ProductCategoryID
WHERE OrderDate BETWEEN '01/01/2014' AND '12/12/2014'
GROUP BY YEAR(Sales.SalesOrderHeader.OrderDate)
,MONTH(Sales.SalesOrderHeader.OrderDate)
,ProductCategory.Name
ORDER BY OrderYear, OrderMonth, CategoryName; You can find the result after INSERT below:
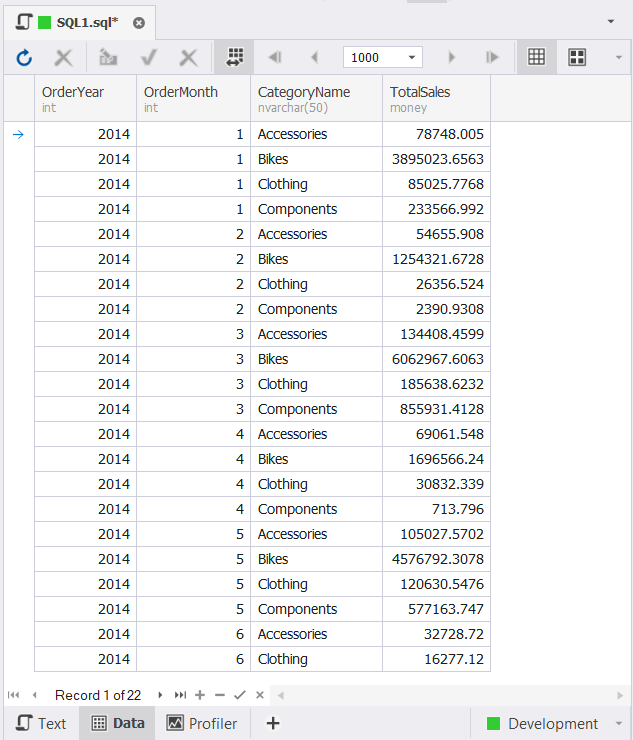
The output is simple but the query looks complex with several joined tables.
Let’s assume that there’s no index for the ProductID column in SalesOrderDetail. Then, let’s use dbForge Studio’s Query Profile to examine the query earlier. To begin, click the Query Profiling Mode from the toolbar. Then, run the INSERT.
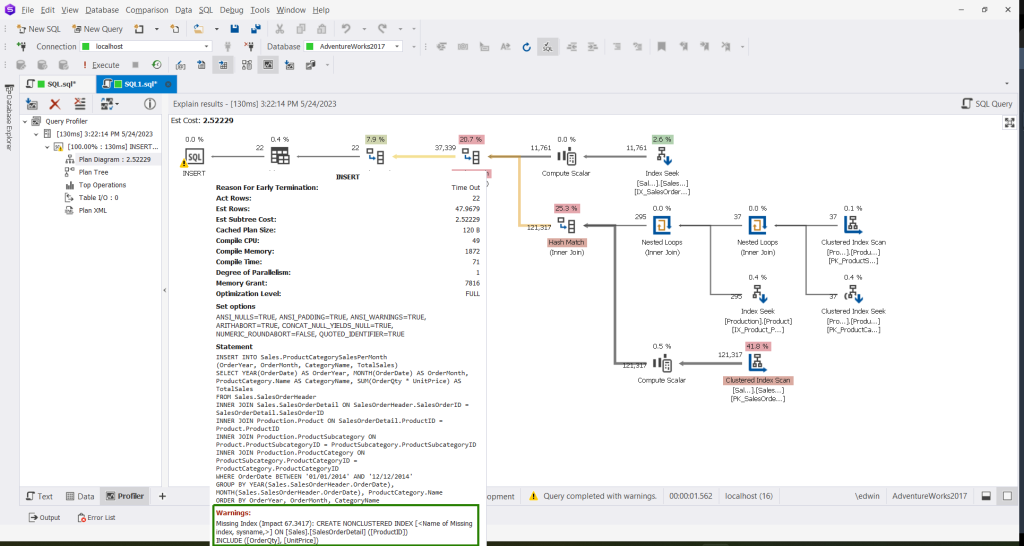
The first thing you’ll notice is the warning icon on the INSERT node. Hovering your mouse over it shows a missing index warning. SQL Server recommends that you create an index on the SalesOrderDetail table. And use the ProductID as the key. And include the columns OrderQty and UnitPrice. So, the wise thing to do is to create the index in another SQL window.
CREATE INDEX IX_SalesOrderDetail_ProductID
ON Sales.SalesOrderDetail (ProductID)
INCLUDE (OrderQty, UnitPrice) Then, re-run the query with Query Profiling Mode ON again. You will notice that the warning disappeared. And SQL Server used the new index.
A missing index is only one of the problems you may encounter. Check my article on SQL Server query optimization for more information.
Conclusion
Hero DBAs use better alternatives to many INSERT statements:
- Using many VALUES clauses,
- or using SELECT statements.
It avoids repeated code and makes it maintainable. And avoids the problems that multiple INSERT statements may incur.
Learning these tips is not the only way to make your SQL Server database fly. But your database will run much better than using multiple INSERTs. And it’s not even rocket science.
What do you think? Let us know in the Comments section below.
Last modified: May 31, 2023



