
A Database Management System is the information’s strongbox. We will attempt to design the Database Management System so that the database should remain well-managed and furnishing the purposes.
In this article, we are going to discuss designing and administering large-sized database systems. We’ll use multiple constitutions that will include Database technologies, storage, data distribution, server assets, architecture pattern, and some others.
Preferably, we should look for a large-sized database in the Telco domain, eCommerce platforms, Insurance domain, Banking system, Healthcare, Energy system, etc. We must keep a few parameters in mind ahead of choosing the right database technology. i.e., Traffic, TPS (Transactions Per Second), estimated storage per day, HA, and DR.
Designing a Large-Sized Database
While constructing our database, we must pay attention to several parameters because it is often very problematic to change the database with a substitute. Let’s consider them now.
Database Technology
Database technology is the primary factor. If you choose right database management system, it will help your business run efficiently and effortlessly and manages donor data.
There are various database technologies with many features. However, while working with open-source database technologies, you might not get access to some explicit features of predefined solutions. Enterprise database technologies like Microsoft SQL Server, Oracle, etc. would provide them.
Lots of enterprise database technologies implement HA (High Availability), DR (Disaster Recovery), Mirroring, Data Replication, Secondary Read Replica, and considerably more convenient and ready configurable business solutions. They may or may not be present in open-source databases.
There are lot many reasons. For instance, we sometimes find that the existing architecture is being disturbed because those factors mentioned above aren’t functional as we need them.
Storage
The storage impacts the performance of the business solution drastically. Business solutions require first-rated storage or SSD with a certain amount of IOPS. However, is it so? On-premises or Cloud, the Storage size and type determine the infrastructure costs.
While considering the storage performance we need to pay attention to the type of data and behavior of the data processing. We need to opt for storage selection according to the user’s data and processing of it. If the user is going to use multiple databases, we need to provide the storage choice over the SAN for different databases for the data types and the data processing behavior.
The Database engineer will provide a better retrospection on the various databases needed IOPS calculation if the users do not need premium storage at all.
Data Distribution
Most of the recent database technologies (SQL or NoSQL) offer partitioning or Sharding features.
- Partition redistributes data in the File system which is based on the partition key.
- Sharding distributes information across the database nodes and the data would be stored in the same or different machine.
Fundamentally, each database service or database table will not require the data Partitioning/Sharding features. They only require to be applied on databases holding larger-sized objects. That will enhance the performance.
Server Assets
Different machines require different types and sizes of Memory and CPU. You have to consider the hardware level assets, such as Memory, Processor, etc. For example, a machine that has to handle larger databases or multiple databases will need more memory and CPUs. Hence, the quality of Memory and Processor is significant. It is going to handle different types of processors available on the market with different CPU caches.
Many times, we come across issues we might not be aware of. We did not pay attention to the utilization and the role of the CPU cache of the hardware. But it is crucial for selecting and meeting the hardware requirements with larger database systems.
Architecture Pattern
In database designing, the Architecture pattern is always at an exemplary role. Earlier, database systems were designed in an extremely monolithic way. Now, we use Micro-Service based or Hybrid (Monolithic + Micro).
The performance, expandability, and zero downtime depend very much on the architecture pattern and the database design. Each application could have a separate database, and all databases could be loosely coupled with each other. In case of any application or database going down, another part of the product will not be disrupted. All micro-services would be independent and loosely coupling.
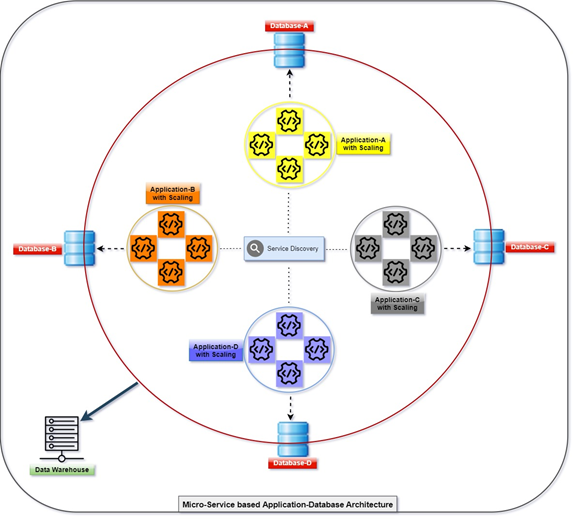
Micro Service
The diagram below explains how all applications are deploying and communicating with the help of their databases, which are loosely coupled at the same time. We can manipulate the data with T-SQL. The information will be gathered or accumulated by various applications, and the client will be able to access the data. Refer to the diagram with the number of scaled applications and its integrated database.
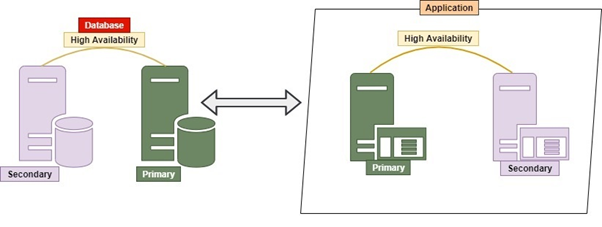
Monolithic
Which RDBMS should we use? It could be Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB, or any other database. The conventional way of dealing with all tables or objects managed in single or multiple databases in a single server is known as Monolithic.
Hybrid
Hybrid is a permutation of Monolithic and Micro Service. It is quite a common practice, as it allows numerous applications, numerous databases, and database servers. Numerous databases and database servers could be tightly coupled with one another.
For example, querying with JOINs between tables belonging to two or more databases in the same database server or different. Remote query used for data retrieve/manipulation with another database server.
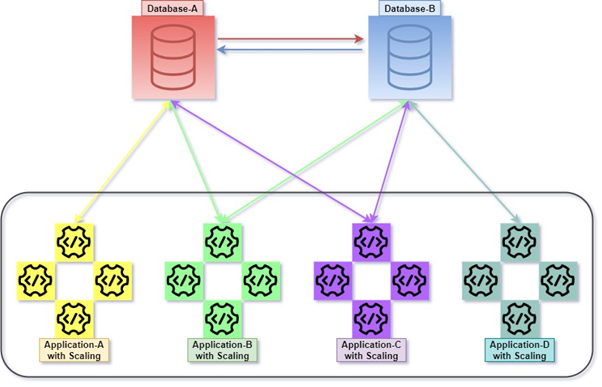
Everything is about SQL Server architecture. However, we are talking about the data manipulation among different tables within the same database or different databases that could reside on the same server or different servers.
Either in Hybrid or Monolithic architecture, we use JOINs between various tables within the same or different databases. It is quite complex when we follow the core Micro-Service standards because tables’ distribution can be between the database services (Dbas).
Under the Enterprise database technologies like Microsoft SQL Server, Oracle, etc., the user could query the distributed database’s tables with the help of Linked Server Joins. But it is not available in all open-source database technologies. It is known as the Tight-Coupled approach that might not work when the remote database service is not available.
Now, let us discuss making it loose-coupled. Why do we need data manipulation between remote databases?
Why do we Require Data Manipulation Between Remote Databases?
Users will require the data to be retrieved from more than one database service when the system is designed with help of Micro or Hybrid Services. The entire process is seen from the backend which can handle data amounts manipulated by the application.
When we look at the real-time cross-database querying, we always join the master entity tables, not the metadata tables. The master tables will not be larger than metadata tables. For reporting purposes, we always use the data warehouse to get all information together. But that’s not easy to manage and maintain for each product. If we design the enterprise solution, we can afford the warehouse. But we can’t afford it for small or medium-sized products.
For example, we need a report with the data from several tables residing in different databases. It is not an easy task to perform, as it collates the data using different microservices and merges it to produce the report. Hence, the necessary data needs to sync.
What can we Use as a Standard Solution to Make Loose-Coupled Table Data Synchronization Between two Databases?
Table Replication should be used for simple data synchronization among multiple databases. The example is the transaction replication for the Simplex data synchronization and the Merge Replication for the Duplex data synchronization provided by SQL Server.
There are a few paid third-party and open-source solutions that can synchronize the data between multiple databases. Even loose-coupled solutions with the help of message queues like SQL Server Transaction Replication can be developed by users on their own.
Conclusion
DBAs design databases in their way. While architecting the database and choosing the database management system, they have to keep many aspects in mind. We presented the most essential factors for the database design, especially for the larger-sized Databases. Stay tuned for the next materials!
Tags: database administration, database design, database management Last modified: April 21, 2023







