When executing a query, the SQL Server optimizer tries to find the best query plan based on existing indexes and available latest statistics for a reasonable time, of course, if this plan is not already stored in the server cache. If no, the query is executed according to this plan, and the plan is stored in the server cache. If the plan has already been built for this query, the query is executed according to the existing plan.
We are interested in the following issue:
During compilation of a query plan, when sorting possible indexes, if the server does not find the best index, the missing index is marked in the query plan, and the server keeps statistics on such indexes: how many times the server would use this index and how much this query would cost.
In this article, we are going to analyze these missing indexes – how to deal with them.
Let’s consider this on a particular example. Create a couple of tables in our database on a local and test server:
[expand title =”Code”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go
[/expand]
The structure is simple and consists of two tables. The first table is called orders with such fields as an identifier, date of sale and seller. The second one is order details, where some goods are specified with price and quantity.
Look at a simple query and its plan:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
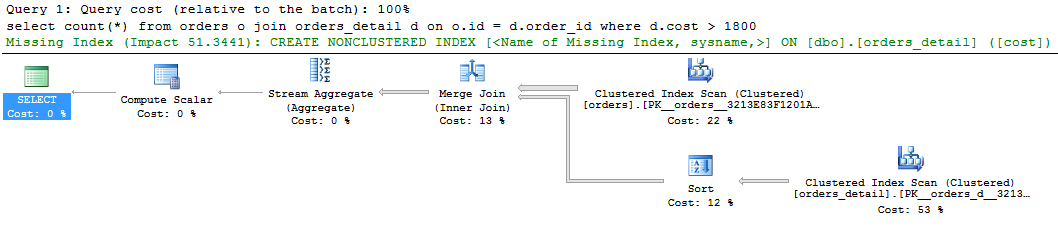
We can see a green hint about the missing index on the graphic display of the query plan. If you right-click it and select “Missing Index Details ..”, there will be the text of the suggested index. The only thing to do is to remove the comments in the text and give a name to the index. The script is ready to be executed.
We will not build the index we received from the hint provided by SSMS. Instead, we will see whether this index will be recommended by dynamic views linked to missing indexes. The views are as follows:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
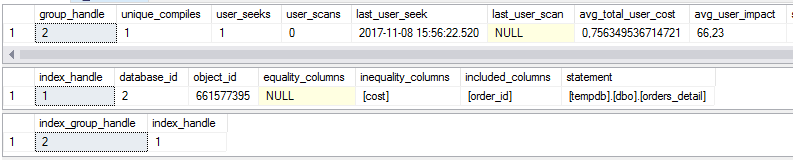
As we can see, there are some statistics on missing indexes in the first view:
- How many times would a search be performed if the suggested index existed?
- How many times would a scan be performed if the suggested index existed?
- Latest date and time we used the index
- The current real cost of the query plan without the suggested index.
The second view is the index body:
- Database
- Object/table
- Sorted columns
- Columns added to increase index coverage
The third view is the combination of the first and second views.
Accordingly, it is not difficult to get a script that would generate a script to create missing indexes from these dynamic views. The script is as follows:
[expand title=”Code”]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc
[/expand]
For index efficiency, the missing indexes are output. The perfect solution is when this result set returns nothing. In our example, the result set will return at least one index:

When there is no time and you do not feel like dealing with the client bugs, I executed the query, copied the first column and executed it on the server. After this, everything worked well.
I recommend treating the information on these indexes consciously. For example, if the system recommends the following indexes:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
And these indexes are used for the search, it is quite obvious that it is more logical to replace these indexes with one that will cover all three suggested:
create index ix_1 on tbl1 (a,b) include (c,d)
Thus, we make a review of the missing indexes before deploying them to the production server. Although…. Again, for example, I deployed the lost indexes to the TFS server, thus, increasing the overall performance. It took minimum time to perform this optimization. However, when changing from TFS 2015 to TFS 2017, I faced the issue that there was no update due to these new indexes. Nevertheless, they can easily be found by the mask
select * from sys.indexes where name like 'ix[_]2017%'
Useful tool:
dbForge Index Manager – handy SSMS add-in for analyzing the status of SQL indexes and fixing issues with index fragmentation.
Tags: execution plan, indexes, query performance, sql server Last modified: September 22, 2021






Thanks, really good things!