In this article, I am going to explain how to move a table from the Primary filegroup to the Secondary filegroup. First, let’s understand what are datafile, filegroup, and type of filegroups.
Database Files and Filegroups
When SQL Server is installed on any server, it creates a Primary data file and Log file to store data. The Primary data file stores data and database objects like tables, index, stored procedures, etc. Log files store information required to recover transactions. Data files can be clubbed together in filegroups.
SQL Server has three types of files
- Primary file: It is created when SQL server is being installed, and it contains the database metadata and information. User data, objects can be stored on the Primary data files. The Primary file has the .mdf extension.
- Secondary File: Secondary files are user-defined. They store User data, Objects created by a user. They have the .ndf extension.
- Transaction Log Files: The T-Logs files log all the transaction performed to recover the database. The Log file extension in .ldf.
As I mentioned above, data files can be grouped in a filegroup. While SQL Server is being installed, it creates the Primary filegroup that has a primary data file. Secondary filegroups are user-defined. They have secondary data files. When we create a new database, we can create secondary datafiles and filegroups. Adding secondary data files helps to improve the performance. It can be created on different disk drives or separate disk partitions that reduces IO wait and read-write latency.
It is recommended to keep tables and indexes in separate filegroups. Also, keeping large tables in separate files improves performance.
There are three types of file groups:
- Row Filegroup: Row File group, also known as Primary filegroup, contains a primary data file. SQL object, data, system tables allocate to the primary filegroup.
- Memory-Optimized Filegroup: Memory-optimized filegroup contains Memory optimized tables and data. To enable in-memory OLTP, we need to create a memory-optimized filegroup.
- FileStream: File-stream filegroup contains file-stream data like Images, Documents, executable files etc. The Primary filegroup cannot contain file-stream data, we need to create a FileStream file group. It contains the FileStream data.
Demo Setup
In this demo, I created “DemoDatabase” on the SQL Server 2017 instance. The “Records” and “PatientData” tabes were created on the database. The “PK_CIDX_Records_ID” primary key was created on the “Records” table and the “CIDX_PatientData_ID” clustered index were created on the “PatientData” table. In this demo, I will move the “Records” and “PatientData” tables from the primary filegroup to the secondary filegroup.
For this, we need to to do the following:
- Create a secondary filegroup.
- Add data files to the secondary filegroup.
- Move the table to the secondary filegroup by moving the clustered index with the primary key constraint.
- Move the tables to the secondary filegroup by moving the clustered index without the primary key.
Create Secondary Filegroup
A secondary filegroup can be created using T-SQL OR using the Add file up wizard from SQL Server Management Studio. To add a filegroup using SSMS, open SSMS and select a database where a file group needs to be created. Right-click the database select “Properties” >> select “Filegroups” and click “Add Filegroup” as shown in the following image:
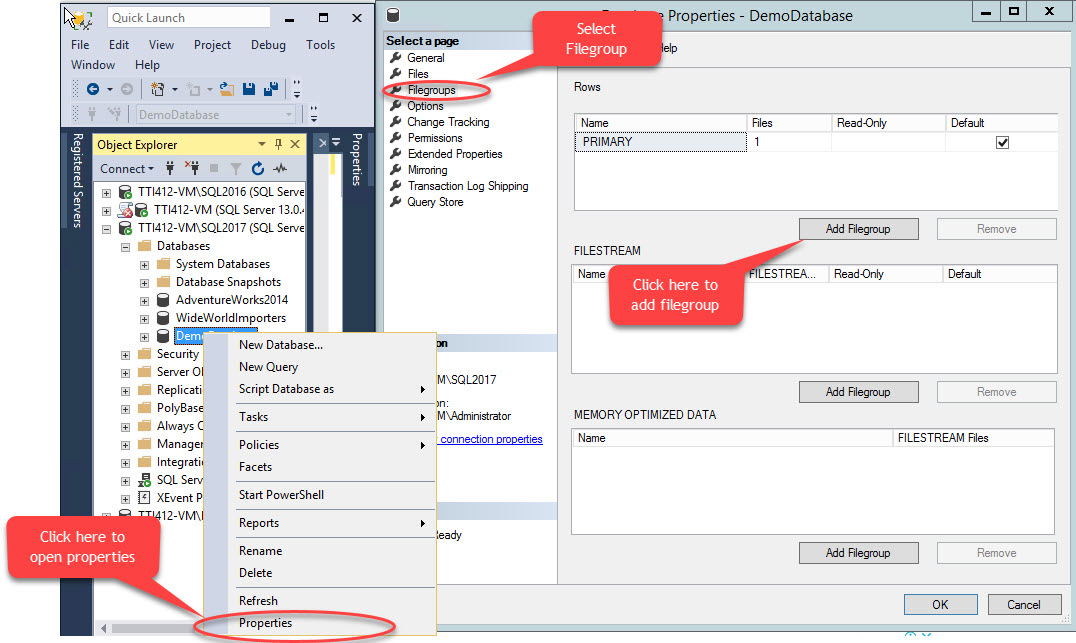
When we click the “Add Filegroup” button, a row will be added in the “Rows” grid. In the “Rows” grid, provide appropriate filegroup name in the “Name” column. Filegroup is neither read-only nor default; hence, keep the Read-only and Default checkboxes cleared for new filegroup. See the following image:
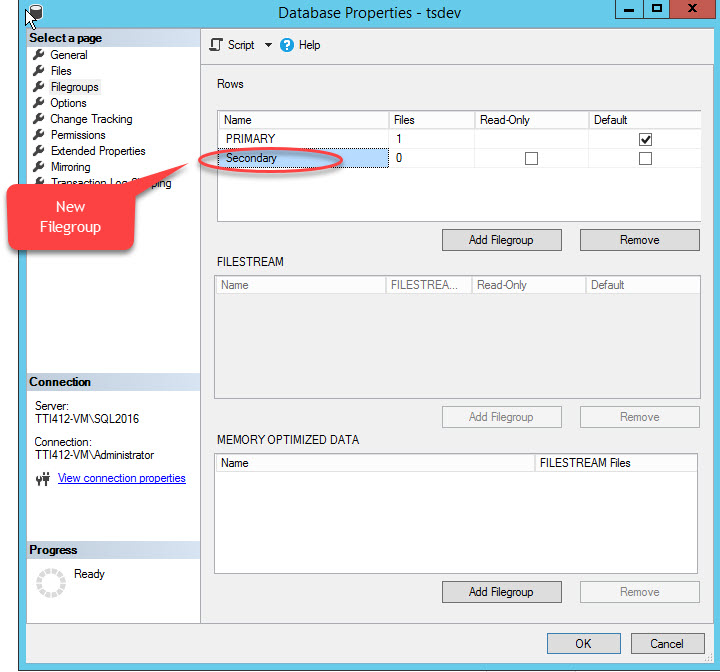
Click OK to close the dialog box.
To create a filegroup using T-SQL script, run the following script.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Adding Files to Filegroup
To add files in a filegroup, open database properties, select “files” and click on “Add.” As shown in the following image:
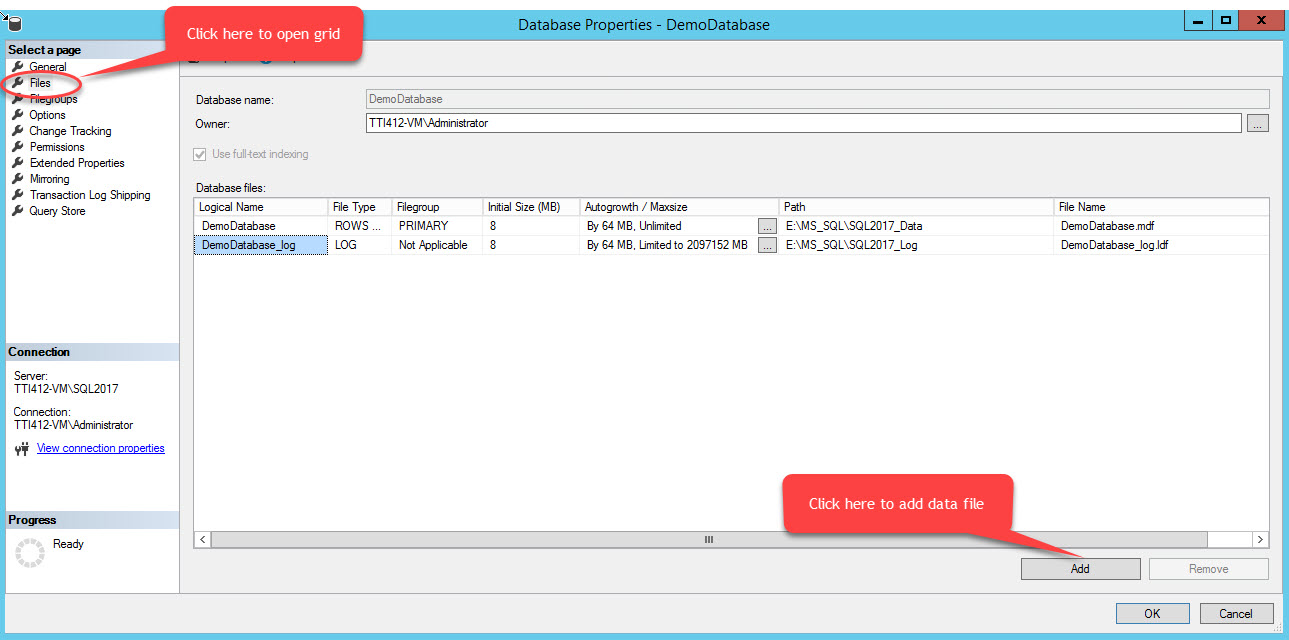
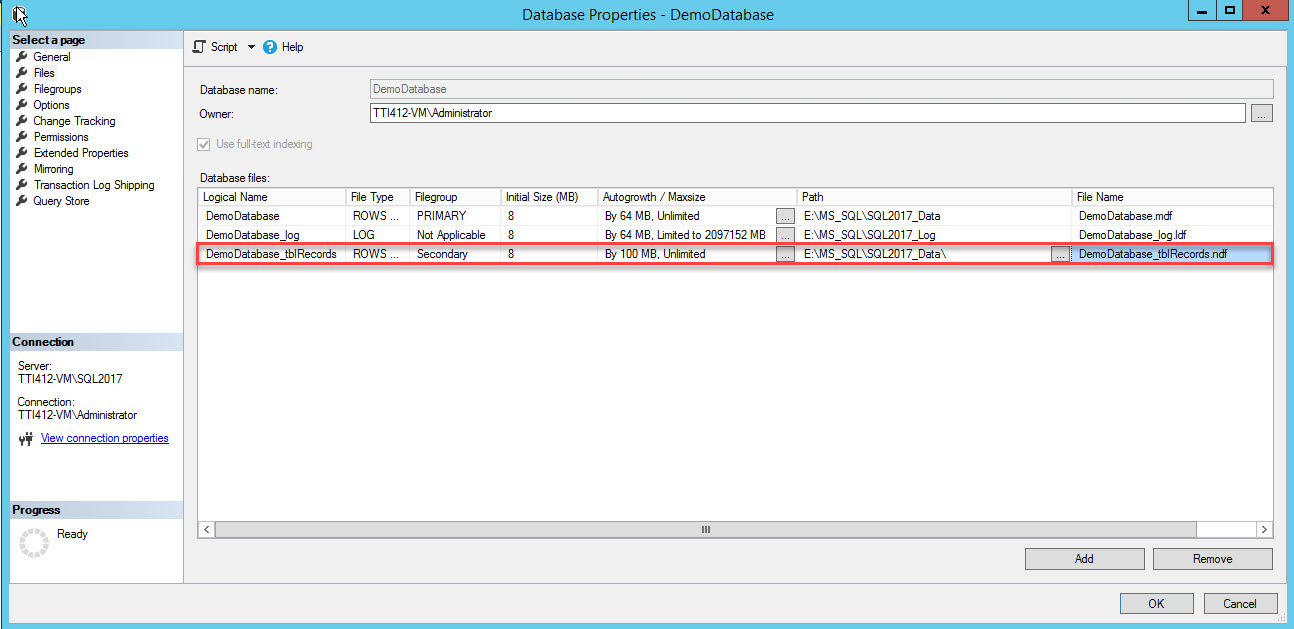
An empty row will be added in the Database Files grid view. In the Grid view, provide appropriate logical name in the Logical Name column, select Rows data from the File Type drop-down box, select secondary from the Filegroup drop-down box, set initial size of the file in the Initial Size columns, set auto-growth and max size parameter in the Autogrowth/Maxsize column, provide physical location of the secondary data file in the Path column and provide appropriate file name in the File Name column. See the following image:
Use the following T-SQL script to create a secondary data file.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
The secondary data file has been created. See the following image:
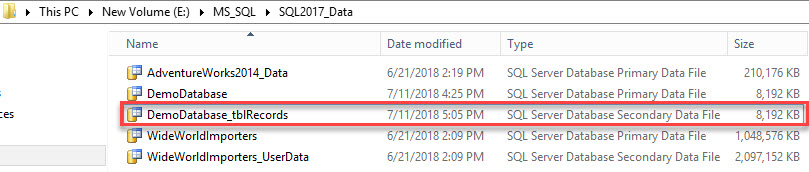
To view a list of file groups created on the database, execute the following query.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
Below is an output of the query.

Transfering Existing Table from Primary Filegroup to Secondary Filegroup
We can move an existing table to another filegroup by moving the clustered index to another filegroup. As we know, a leaf node of the clustered index has actual data; hence moving clustered index can move the entire table to another file group. Moving index has a limitation: if the index is a primary key or unique constraint, you cannot move index using SQL Server Management Studio. To move those indexes, we need to use the create index statement and with the DROP_Existing=ON option.
Moving Clustered Index with Primary Key Constraint.
Primary key enforces unique values, hence create the unique clustered index. The key column is PRN. To create it in the secondary filegroup, set the DROP_EXISTING=ON option and the filegroup should be secondary. Execute the following script.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
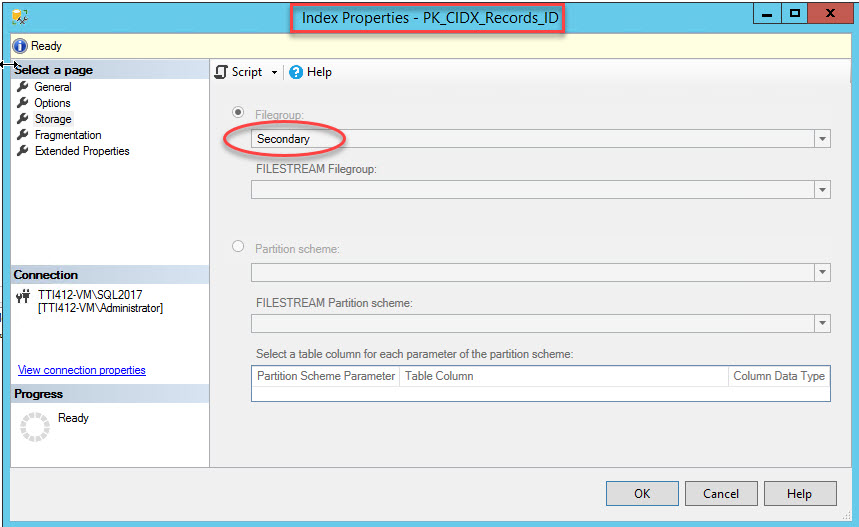
Once the command was executed successfully, verify that index has been created in the secondary filegroup. For this, right-click the Storage option in the Index Properties dialog box. To open index properties, expand the DemoDatabase database >> expand Tables >> expand Indexes. Right-click PK_CIDX_Records_ID, as shown in the following image:
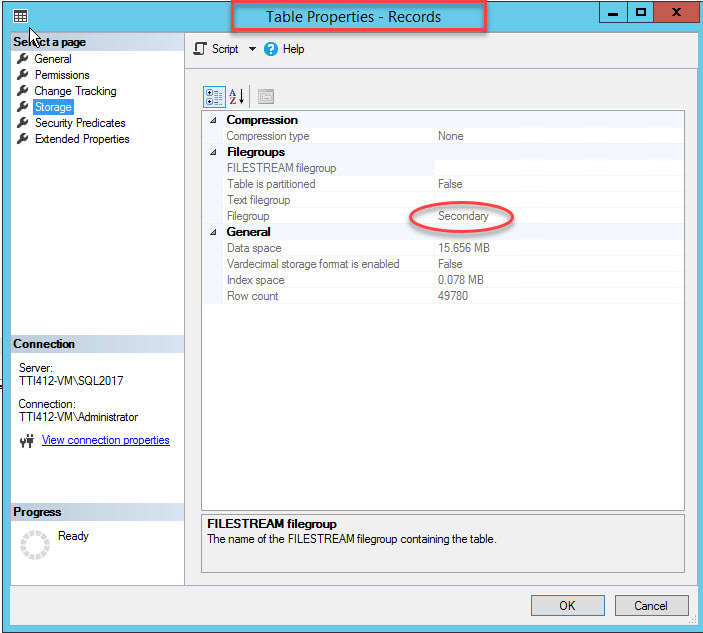
As I mentioned, once clustered index moves to a secondary filegroup, the table will be moved to the secondary filegroup. To verify it, right-click the Storage option in the Table Properties dialog box. To open index properties, expand the DemoDatabase database >> expand Tables >> right-click Records, and select storage, as shown in following image:
Moving Clustered Index Without Primary Key
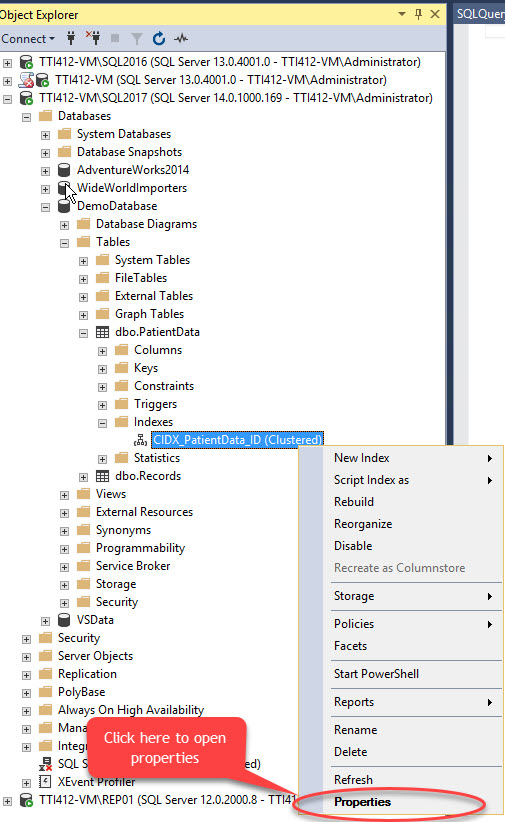
We can move clustered index without primary key using SQL Server Management Studio. To do that, expand the DemoDatabase database >> expand Tables >> expand Indexes >> right-click the CIDX_PatientData_ID index and select Properties, as shown in following image:
The Index Properties dialog box opens. In the dialog box, select Storage, and in the Storage window, click the Filegroup drop-down box, select the Secondary filegroup and click OK, as shown in the following image:
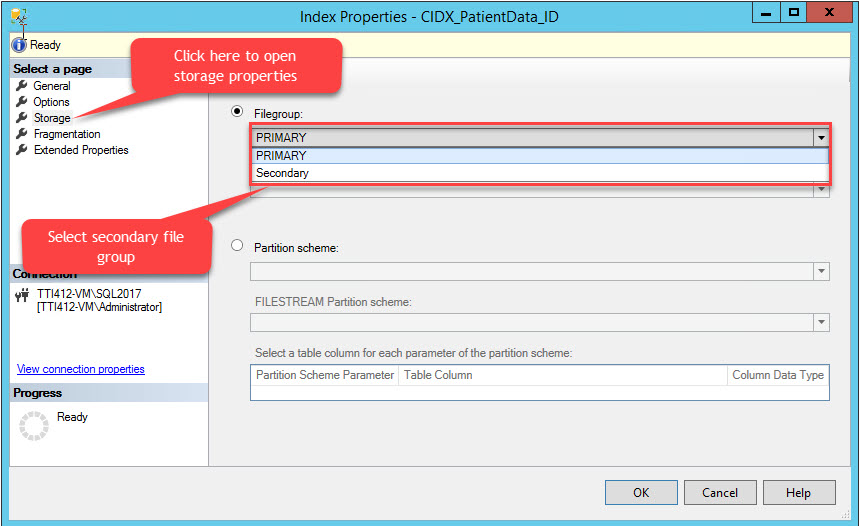
Changing of the index filegroup will re-create the entire index. Once the index is re-created, open Table Properties and select a storage.
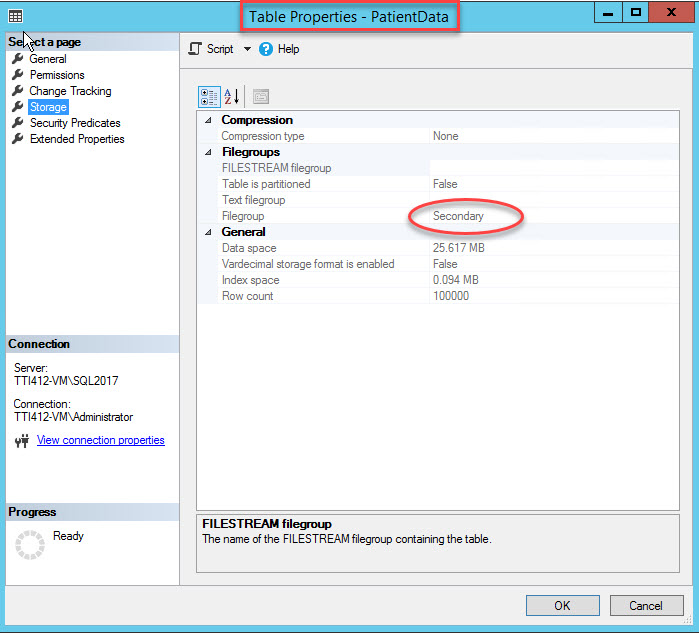
As you can see in the above image, along with moving the CIDX_PatientData_ID clustered index to the secondary filegroup, the PatientData table is also moved to the Secondary filegroup.
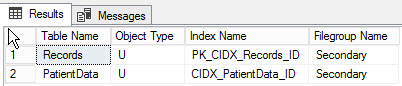
By executing the following query, you can find the list of objects created to different file group:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go
Below is the output of the query:
Summary
In this article, I have explained
-
- Basics of Datafiles and filegroups.
- How to create secondary filegroup and add secondary datafile in it.
- Move the table to secondary filegroup by moving:
- Primary key.
- Clustered index.






