Overview
This article discusses two different approaches available to remove duplicate rows from SQL table(s) which often becomes difficult over time as data grows if this is not done on time.
The presence of duplicate rows is a common issue that SQL developers and testers face from time to time, however, these duplicate rows do fall into a number of different categories that we are going to discuss in this article.
This article focuses on a specific scenario, when data inserted into a database table, leads to the introduction of duplicate records and then we will take a closer look at methods for removing duplicates and finally remove the duplicates using these methods.
Preparing Sample Data
Before we start exploring the different options available to remove duplicates, it is worthwhile at this point to set up a sample database which will help us to understand the situations when duplicate data makes its way into the system and the approaches to be used to eradicate it.
Set up Sample Database (UniversityV2)
Start by creating a very simple database which consists of only a Student table at the beginning.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Populate Student Table
Let us only add two records to the Student table:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Data Check
View the table which contains two distinct records at the moment:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]

You have successfully prepared the sample data by setting up a database with one table and two distinct (different) records.
We are going to discuss now some potential scenarios in which duplicates were introduced and deleted starting from simple to slightly complex situations.
Case 01: Adding and Removing Duplicates
Now we are going to introduce duplicate row(s) in the Student table.
Preconditions
In this case, a table is said to have duplicate records if a student’s Name, Course, Marks, and ExamDate coincide in more than one records even if the Student’s ID is different.
So, we assume that no two students can have the same name, course, marks and exam date.
Adding Duplicate Data for Student Asif
Let us deliberately insert a duplicate record for Student: Asif to the Student table as follows:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
View Duplicate Student Data
View the Student table to see duplicate records:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]

Finding Duplicates by Self-referencing Method
What if there are thousands of records in this table, then viewing the table won’t be much help.
In the self-referencing method, we take two references to the same table and join them using column-by-column mapping with the exception of the ID which is made less than or greater than the other.
Let us look at the self-referencing method to find duplicates which looks like this:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
The output of the above script shows us only the duplicate records:

Finding Duplicates by Self-referencing Method-2
Another way to find duplicates using self-referencing is to use INNER JOIN as follows:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Removing Duplicates by Self-referencing Method
We can remove the duplicates using the same method we used to find duplicates with the exception of using DELETE in line with its syntax as follows:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
Data Check after Duplicates Removal
Let us quickly check the records after we have removed the duplicates:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
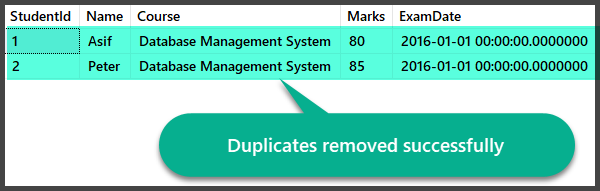
Creating Duplicates View and RemoveDuplicates Stored Procedure
Now that we know our scripts can successfully find and delete duplicate rows in SQL, it is better to turn them into view and stored procedure for ease of use:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
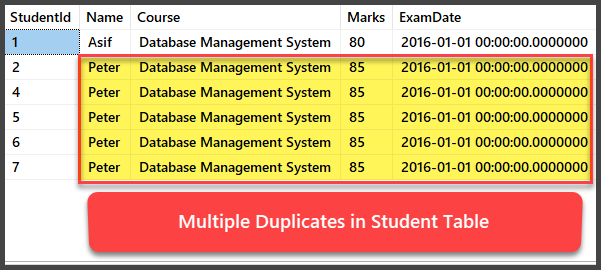
Adding and Viewing Multiple Duplicate Records
Let us now add four more records to the Student table and all the records are duplicates in such a way that they have the same name, course, marks and exam date:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Removing Duplicates by using UspRemoveDuplicates Procedure
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
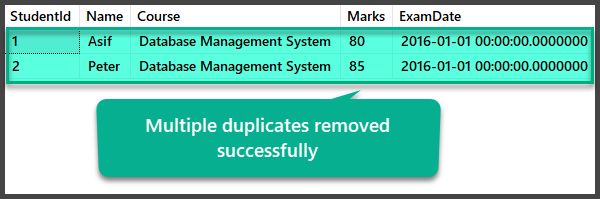
Data Check after Removal of Multiple Duplicates
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Case 02: Adding and Removing Duplicates with Same IDs
So far, we have identified duplicate records having distinct IDs but what if the IDs are the same.
For example, think of the scenario in which a table has been recently imported from a text or Excel file that has no primary key.
Preconditions
In this case, a table is said to have duplicate records if all the column values are exactly the same including some ID column and the primary key is missing which made it easier to enter the duplicate records.
Create Course Table without Primary Key
In order to reproduce the scenario in which duplicate records in the absence of a primary key fall into a table, let us first create a new Course table without any primary key in the University2 database as follows:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
Populate Course Table
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
Data Check
View the Course table:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

Adding Duplicate Data in Course Table
Now insert duplicates into the Course table:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
View Duplicate Course Data
Select all the columns to view the table:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

Finding Duplicates by Aggregate Method
We can find exact duplicates by using the aggregate method by grouping all the columns with a total of more than one after selecting all the columns along with counting all the rows using the aggregate count(*)function:
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
This can be applied as follows:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
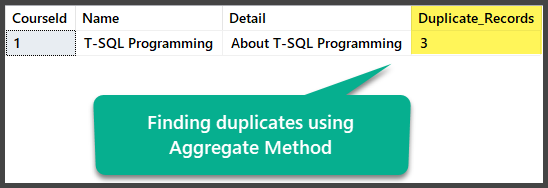
Removing Duplicates by Aggregate Method
Let us remove the duplicates using the Aggregate Method as follows:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Data Check
USE UniversityV2
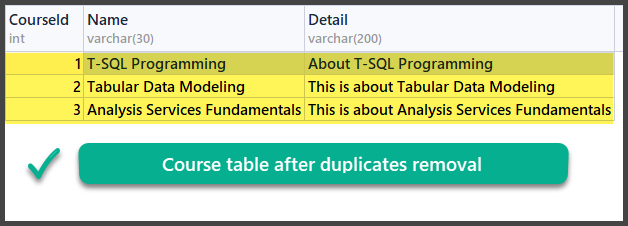
So, we have successfully learned how to remove duplicates from a database table using two different methods based on two different scenarios.
Things to Do
You can now easily identify and relieve a database table from duplicate value.
1. Try creating the UspRemoveDuplicatesByAggregate stored procedure based on the method mentioned above and remove duplicates by calling the stored procedure
2. Try modifying the stored procedure created above (UspRemoveDuplicatesByAggregates) and implement Clean up tips mentioned in this article.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Can you be sure that the UspRemoveDuplicatesByAggregate stored procedure can be executed as many times as possible, even after removing the duplicates, to show that the procedure remains consistent in the first place?
4. Please refer to my previous article Jump to Start Test-Driven Database Development (TDDD) – Part 1 and try inserting duplicates into the SQLDevBlog database tables, after that try removing the duplicates using both of the methods mentioned in this tip.
5. Please try to create another sample database EmployeesSample referring to my previous article Art of Isolating Dependencies and Data in Database Unit Testing and insert duplicates into the tables and try removing them using both of the methods you learned from this tip.
Useful tool:
dbForge Data Compare for SQL Server – powerful SQL comparison tool capable of working with big data.






