Introduction to SQL Server Indexes
Microsoft SQL Server is considered as one of the relational database management systems (RDBMS), in which the data is logically organized into rows and columns that are stored in data containers called tables. Physically, the tables are stored as 8 KB pages that can be organized into Heap or B-Tree Clustered tables. In the Heap table, there is no sorting order that controls the order of the data inside the data pages and the sequence of pages within that table, as there is no Clustered index defined on that table to enforce the sorting mechanism. If a Clustered index is defined on one column of the group of table columns, the data will be sorted inside the data pages based on the values of the Clustered index key columns, and the pages will be linked together based on these index key values. This sorted table is called a Clustered table.
In SQL Server, the index is considered as an important and effective key in the performance tuning process. The purpose of creating an index is to speed up access to the base table and retrieve the requested data without having to scan all the table rows to return the requested data. You can think of the database index as a book index that helps you quickly find the words in the book, without having to read the entire book to find that word. For example, suppose you need to retrieve information about a specific customer using a customer ID. If there is no index defined for the Customer ID column in this table, the SQL Server Engine checks all the table rows, one by one, in order to retrieve the customer with the provided ID. If an index is defined for the Customer ID column in this table, the SQL Server Engine will look for the requested Customer ID values in the sorted index, rather than in the base table, to retrieve information about the customer, reducing the number of scanned rows to retrieve the data.
In SQL Server, the index is structured logically as 8K pages, or index nodes, in the form of a B-tree. The B-Tree structure contains three levels: a Root Level that includes one index page at the top of the B-tree, a Leaf Level that is located at the bottom of the B-tree and contains data pages, and an Intermediate Level that includes all the nodes located between the root and the leaf levels, with index key values and pointers to the following pages. This B-tree shape provides a quick way to navigate the data pages from left to right and from the top to the bottom, based on the index key.
In SQL Server, there are two main types of indexes, a Clustered index, in which the actual data is stored at the leaf level pages of the index, with the ability to create only one clustered index for each table, as the data inside the data pages and the order of the pages will be sorted based on the clustered index key. If you define a primary key constraint in your table, a clustered index will be created automatically if no clustered index was previously defined for that table. The second type of indexes is a Non-clustered index that includes a sorted copy of the index key columns and a pointer to the rest of the columns in the base table or the clustered index, with the ability to create up to 999 non-clustered indexes for each table.
SQL Server provides us with other special types of indexes, such as a Unique index that is created automatically when a unique constraint is defined to enforce the uniqueness of specific column values, a Composite index in which more than one key column will participate in the index key, a Covering index in which all columns requested by a specific query will participate in the index key, a Filtered index that is an optimized non-clustered index with a filter predicate for indexing only a small portion of the table rows, a Spatial index that is created on the columns that store spatial data, an XML index that is created on XML binary large objects (BLOBs) in XML data type columns, a Columnstore index in which data is organized in columnar data format, a Full-text index that is created by the SQL Server Full-Text Engine, and a Hash index that is used in Memory-Optimized tables.
As I used to call the SQL Server index, this is a double-edged sword, where the SQL Server Query Optimizer can benefit from the index designed well to improve the performance of your applications by speeding up the data retrieval process. In contrast, an index that is designed in a bad way will not be chosen by the SQL Server Query Optimizer and it will degrade the performance of your applications by slowing down the data modification operations and consume you storage without taking advantage of it in the data retrieval processes. Therefore, it is better to first follow the index creation best practices and guidelines, check the effect if creating an on the development environment, and find a compromise between the speed of data retrieval operations and the overhead of adding that index on the data modification operations and the space requirements of that index, before applying it to the production environment.
Before creating an index, you need to study the different aspects that affect the creation and use of the index. This includes the type of the database workload, Online Transaction Processing (OLTP) or Online Analytical Processing (OLAP), the size of the table, the characteristics of the table columns, the sorting order of the columns in the query, the type of the index that corresponds to the query and the storage properties such as the FILLFACTOR and PAD_INDEX options that control the percentage of space on each leaf-level and the intermediate level pages to be filled with data.
SQL Server Index Fragmentation
Your work as a DBA is not limited to creating the right index. Once the index is created, you should monitor the index usage and statistics, for example, you need to know if this index is used poorly or not used at all. Thus, you can provide the correct solution to maintain these indexes or replace them with more efficient ones. In this way, you will maintain the highest applicable performance for your system. You may ask yourself: Why does the SQL Server Query Optimizer no longer use my index, although it did that before?
The answer is mainly related to the continuous data and schema changes that are performed on the base table that should be reflected in the indexes. Over time, and with all these changes, index pages become unsorted, causing the index to become fragmented. Another reason for the fragmentation is an attempt to insert a new value or update the current value, and the new value does not fit in the currently available free space. In this case, the page will be split into two pages, where the new page will be created physically after the last page. And you can imagine reading from a fragmented index and the number of pages that should be scanned, and, of course, the number of I/O operations performed to retrieve several records due to the distance between these pages. And because of this extra cost of using this fragmented index, the SQL Server Query Optimizer will ignore this index.
Different Ways to Get Index Fragmentation
SQL Server provides us with different ways to get the percentage of index fragmentation. The first way is to check the percentage of index fragmentation in the Index Properties window, under the Fragmentation tab, as shown below:
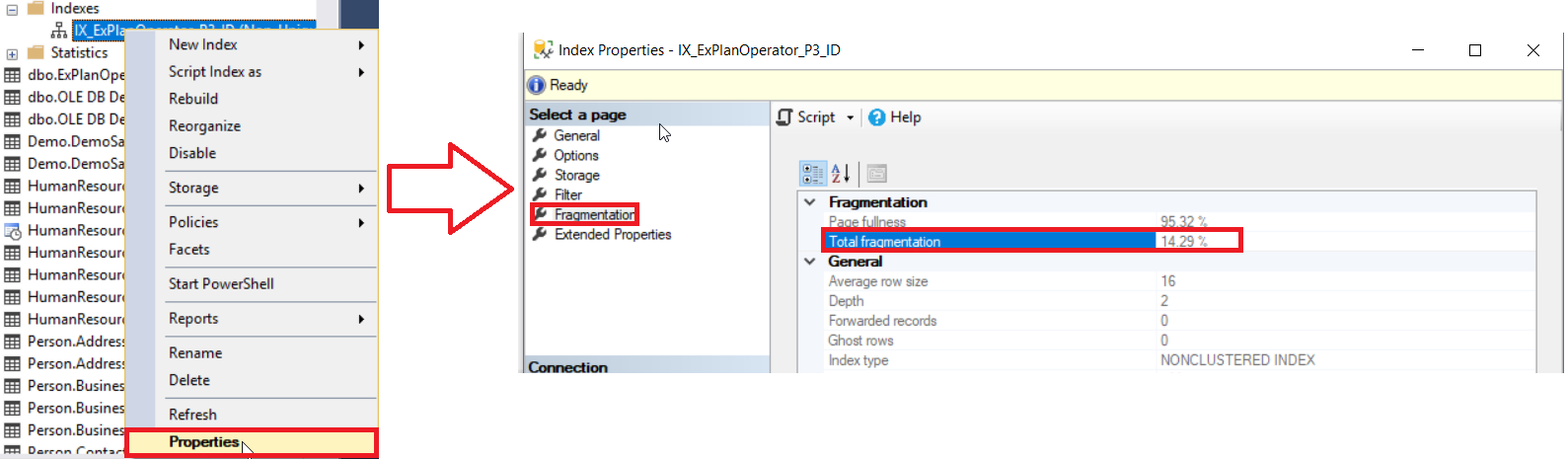
But in order to check the fragmentation level of multiple indexes, you need to first perform the UI method check for all the indexes, one by one, which is a time-wasting operation. The second available method to check the fragmentation level of all the database indexes is querying the sys.dm_db_index_physical_stats DMF and join it with the sys.indexes DMV to retrieve all the information about these indexes, taking into consideration that these statistics will be refreshed when the SQL Server service is restarted, using a query similar to the following:
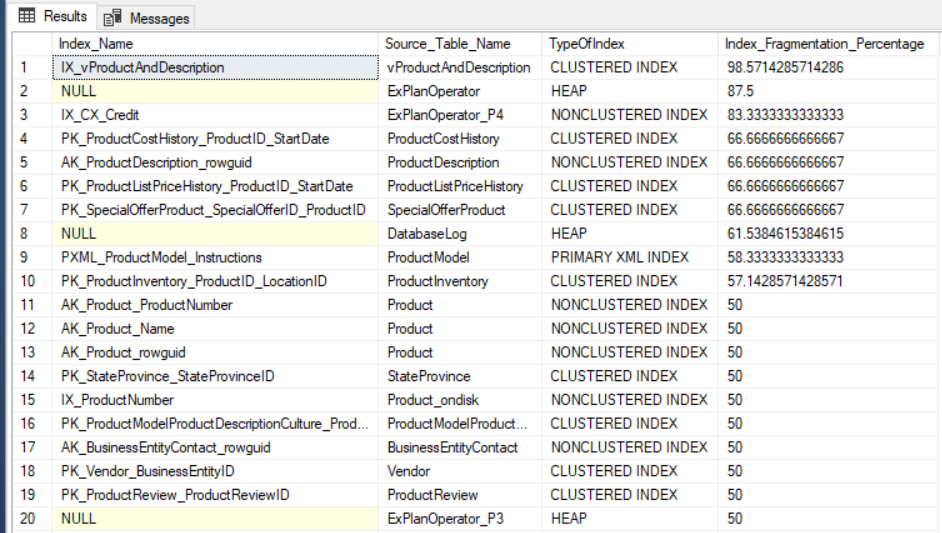
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
The output result of querying the AdventureWorks2016CTP3 testing database will be similar to the following:
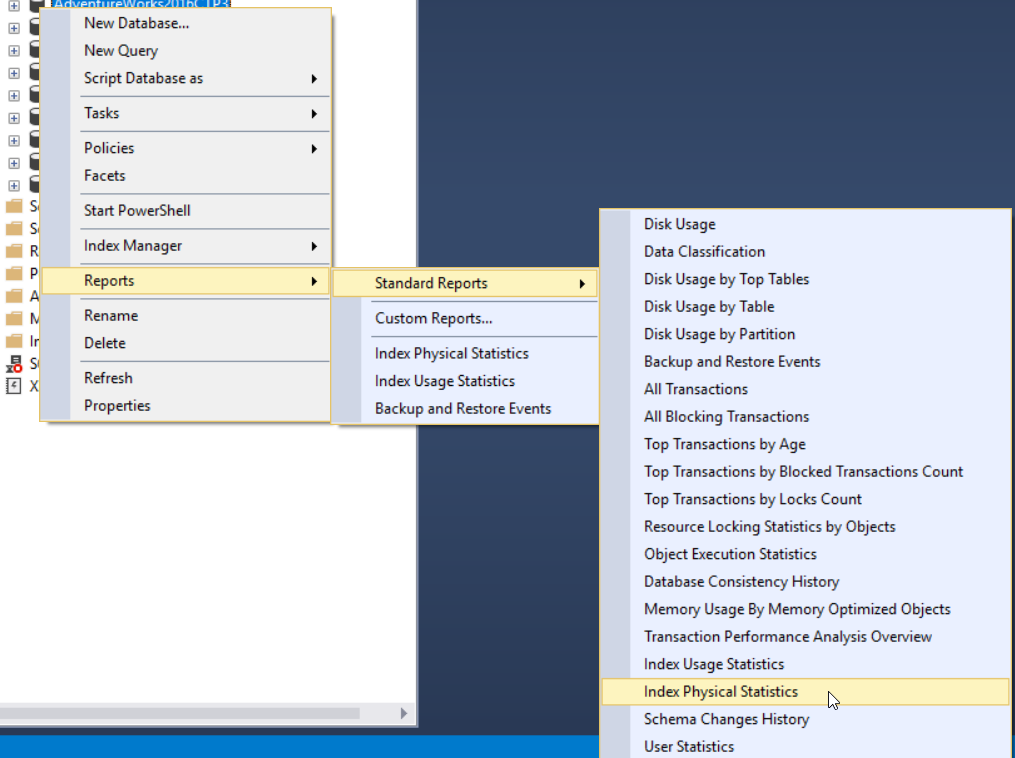
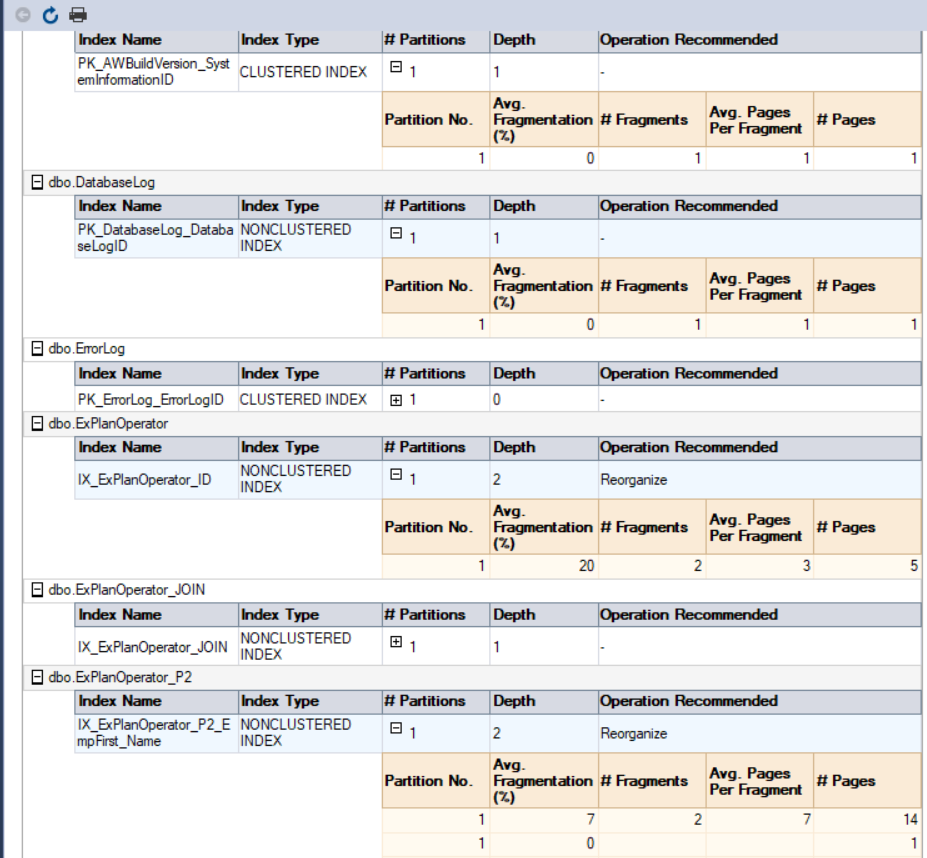
The third method of getting the fragmentation percentage is to use the SQL Server built-in standard report called Index Physical Statistics. This report returns useful information about the index partitions, fragmentation percentage, number of pages on each index partition, and recommendations on how to fix the index fragmentation issue by rebuilding or reorganizing the index. To view the report, right-click your database, select the Reports option, Standard Reports and select Index Physical Statistics as below:
In our case, the generated report will look like this:
The last and easiest way to retrieve the fragmentation percentage of all database indexes is the dbForge Index Manager tool. The dbForge Index Manager tool is an add-in that can be added to your SQL Server Management Studio to analyze the SQL Server databases indexes, providing you with a very useful report with the status of the selected database indexes and maintenance suggestions to fix these index fragmentation issues.
After installing the dbForge Index Manager add-in to your SSMS, you can run it by right-clicking the database to be scanned, select Index Manager, then Manage Index Fragmentation as shown below:
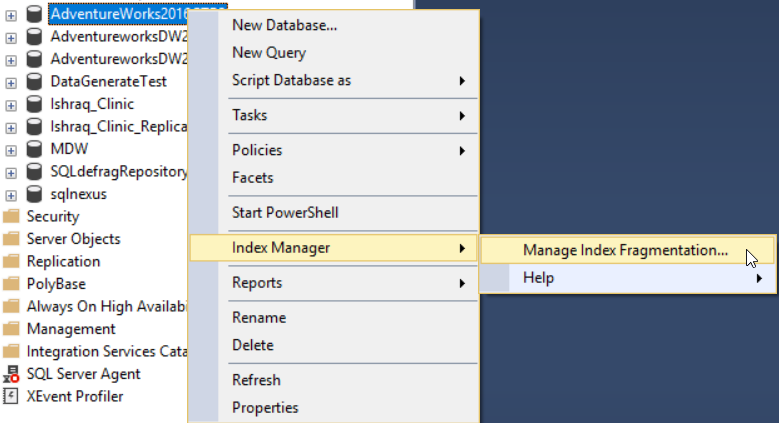
The dbForge Index Manager tool allows you to get an overall picture of the fragmentation of the selected database indexes, with recommendation for the proper actions to fix this issue, as shown below:

The dbForge Index Manager tool allows you also to switch between databases, providing you with a new report after scanning this database as shown below:
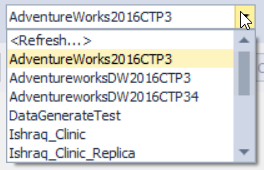
The index fragmentation report generated by the dbForge Index Manager tool can be exported to a CSV file in order to analyze the indexes fragmentation status, as shown below:
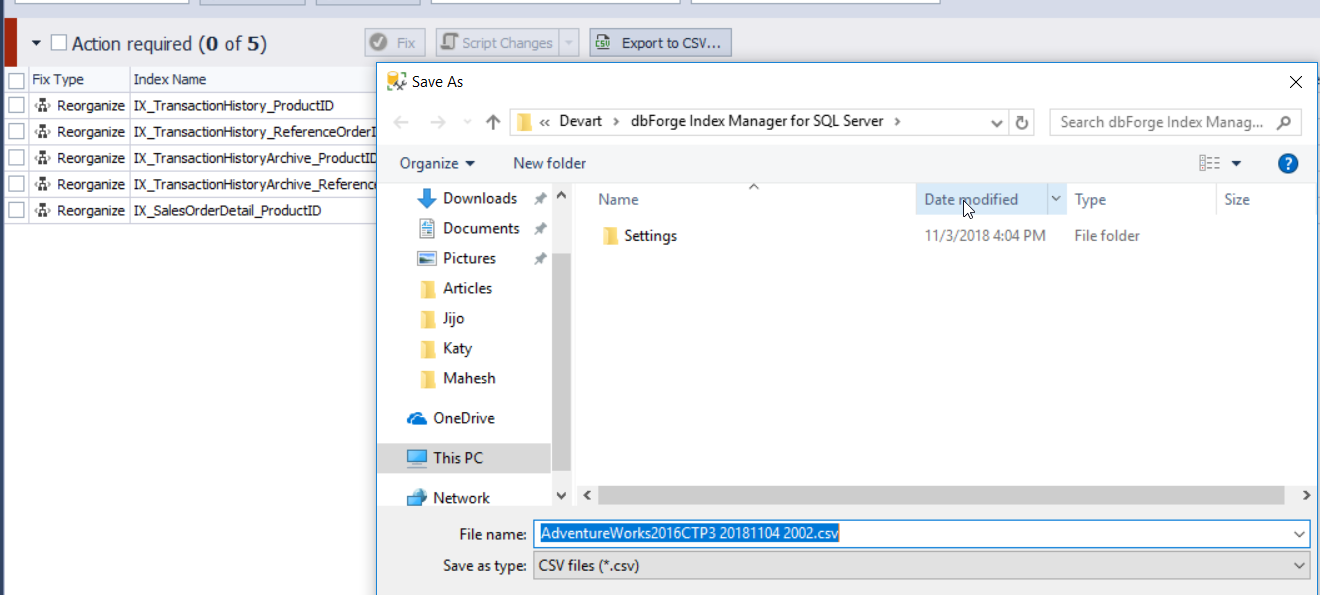
dbForge Index Manager allows you to generate T-SQL scripts to rebuild or reorganize the indexes as per the tool recommendation. Use the Script Changes option to show or save the script for the indexes that are fragmented, as shown below:
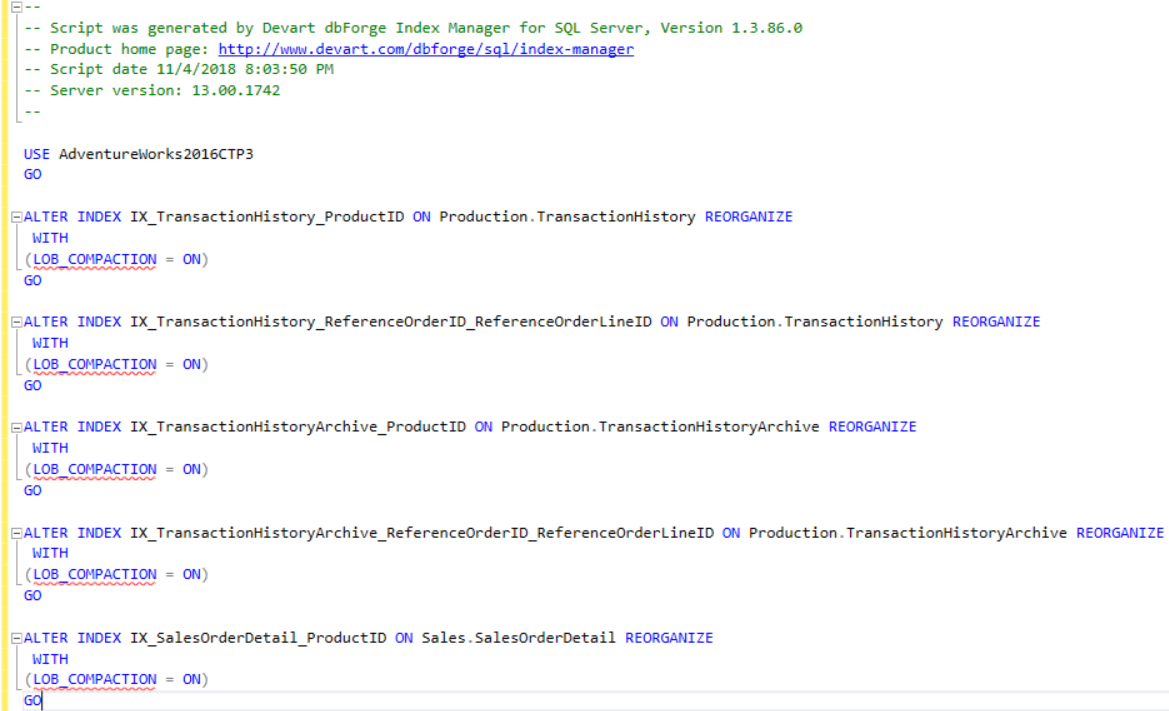
The dbForge Index Manager tool provides you with the ability to fix the index fragmentation issue directly by clicking the Fix button that will perform the recommended action directly on the selected indexes, showing the fixing status on the Result column as shown below:

If you click the Reanalyze button, it will scan the index fragmentation on the database again after performing the fix operation successfully. What is listed here in this article is just an introduction to how the dbForge Index Manager tool will help us in identifying and fixing index fragmentation issues. My recommendation for you is to download it and check what this tool can offer you.
Useful links:
- Index basics
- Types of indexes
- Clustered and Nonclustered indexes described
- Clustered index structures
Useful tool:
dbForge Index Manager – handy SSMS add-in for analyzing the status of SQL indexes and fixing issues with index fragmentation.
Tags: indexes, sql server Last modified: September 22, 2021





