- Briefly about Pivot tables
- Pivoting data by means of tools (dbForge Studio for MySQL)
- Pivoting data by means of SQL
- Automating data pivoting, creating query dynamically
Briefly about Pivot tables
This article deals with the transformation of table data from rows to columns. Such transformation is called pivoting tables. Often, the result of the pivot is a summary table in which statistical data are presented in the form suitable or required for a report.
Besides, such data transformation can be useful if a database is not normalized and the information is stored therein in a non-optimal form. So, when reorganizing the database and transferring data to new tables or generating a required data representation, data pivot can be helpful, i.e. moving values from rows to resulting columns.
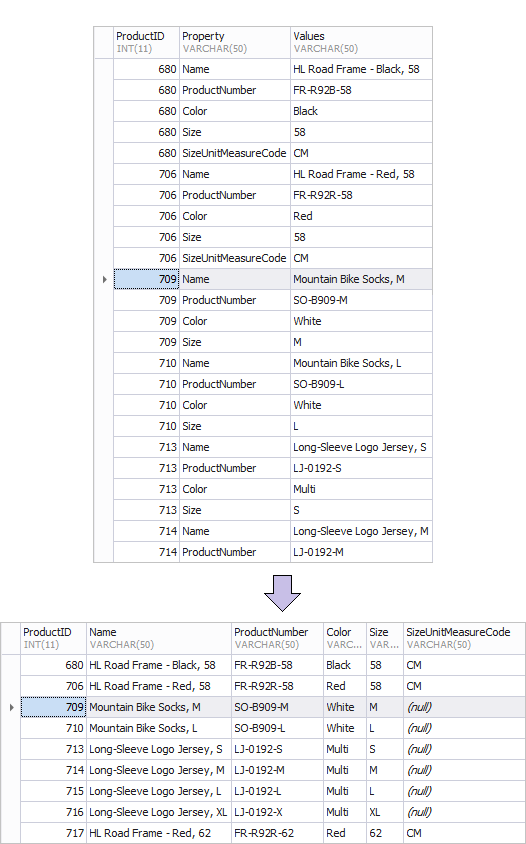
Below is an example of the old table of products – ProductsOld and the new one — ProductsNew. It is through the transformation from rows to columns that such a result can be easily achieved.
Here is a pivot table example.
Pivoting data by means of tools (dbForge Studio for MySQL)
There are applications that have tools allowing to implement data pivot in a convenient graphical environment. For example, dbForge Studio for MySQL includes Pivot Tables functionality that provides the desired result in just a few steps.

Let’s look at the example with a simplified table of orders – PurchaseOrderHeader.
CREATE TABLE PurchaseOrderHeader ( PurchaseOrderID INT(11) NOT NULL, EmployeeID INT(11) NOT NULL, VendorID INT(11) NOT NULL, PRIMARY KEY (PurchaseOrderID) ); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (1, 258, 1580); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (2, 254, 1496); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (3, 257, 1494); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (4, 261, 1650); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (5, 251, 1654); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (6, 253, 1664); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (7, 255, 1678); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (8, 256, 1616); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (9, 259, 1492); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (10, 250, 1602); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (11, 258, 1540); ...
Assume that we need to make a selection from the table and determine the number of orders made by certain employees from specific suppliers. The list of employees, for which information is needed – 250, 251, 252, 253, 254.
A preferred view for the report is as follows.
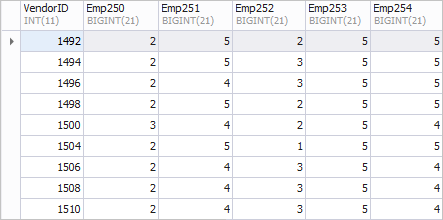
The left column VendorID shows the IDs of vendors; columns Emp250, Emp251, Emp252, Emp253, and Emp254 display the number of orders.
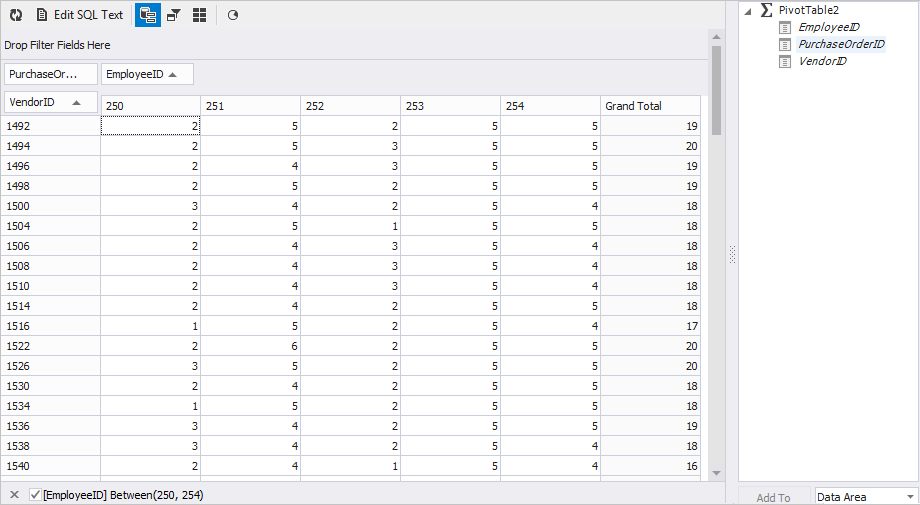
To achieve this in dbForge Studio for MySQL, you need to:
- Add the table as a data source for the ‘Pivot Table’ representation of the document. In Database Explorer, right-click the PurchaseOrderHeader table and select Send to and then Pivot Table in the popup menu.
- Specify a column the values of which will be rows. Drag the VendorID column to the ‘Drop Rows Fields Here’ box.
- Specify a column the values of which will be columns. Drag the EmployeeID column to the ‘Drop Column Fields Here’ box. You can also set a filter for the required employees (250, 251, 252, 253, 254).
- Specify a column, the values of which will be the data. Drag the PurchaseOrderID column to the ‘Drop Data Items Here’ box.
- In the properties of the PurchaseOrderID column, specify the type of aggregation – Count of values.
We quickly got the result in a report we need.
Pivoting data by means of SQL
Of course, data transformation can be performed by means of a database by writing a SQL query. But there is a slight hitch, MySQL does not have a specific statement allowing to do this.
T-SQL-based example for SQL Server
For example, SqlServer and Oracle have the PIVOT operator that allows making such data transformation. If we worked with SqlServer, our query would look like this.
SELECT
VendorID
,[250] AS Emp1
,[251] AS Emp2
,[252] AS Emp3
,[253] AS Emp4
,[254] AS Emp5
FROM (SELECT
PurchaseOrderID
,EmployeeID
,VendorID
FROM Purchasing.PurchaseOrderHeader) p
PIVOT
(
COUNT(PurchaseOrderID) FOR EmployeeID IN ([250], [251], [252], [253], [254])
) AS t
ORDER BY t.VendorID;
Example for MySQL
In MySQL, we will have to use the means of SQL. The data should be grouped by the vendor column – VendorID, and for each required employee (EmployeeID), you need to create a separate column with an aggregate function.
In our case, we need to calculate the number of orders, so we will use the aggregate function COUNT.
In the source table, the information on all employees is stored in one column EmployeeID, and we need to calculate the number of orders for a particular employee, so we need to teach our aggregate function to process only certain rows.
The aggregate function does not take into account NULL values, and we use this peculiarity for our purposes.
You can use the conditional operator IF or CASE which will return a specific value for the desired employee, otherwise will simply return NULL; as a result, the COUNT function will count only non-NULL values.
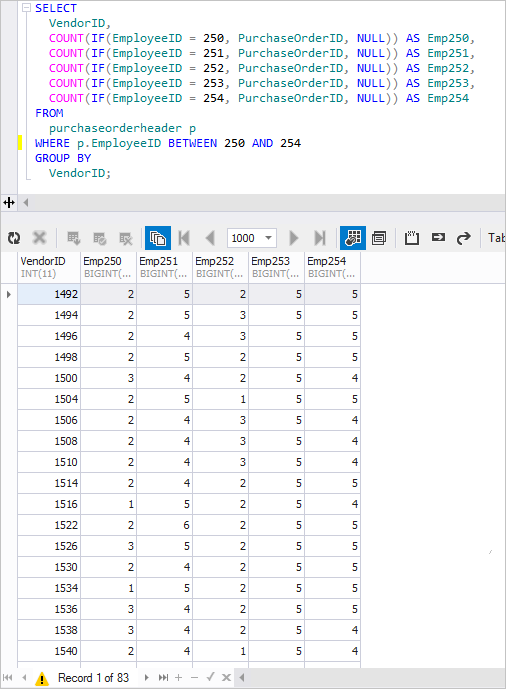
The resulting query is as follows:
SELECT VendorID, COUNT(IF(EmployeeID = 250, PurchaseOrderID, NULL)) AS Emp250, COUNT(IF(EmployeeID = 251, PurchaseOrderID, NULL)) AS Emp251, COUNT(IF(EmployeeID = 252, PurchaseOrderID, NULL)) AS Emp252, COUNT(IF(EmployeeID = 253, PurchaseOrderID, NULL)) AS Emp253, COUNT(IF(EmployeeID = 254, PurchaseOrderID, NULL)) AS Emp254 FROM PurchaseOrderHeader p WHERE p.EmployeeID BETWEEN 250 AND 254 GROUP BY VendorID;
Or even like this:
VendorID, COUNT(IF(EmployeeID = 250, 1, NULL)) AS Emp250, COUNT(IF(EmployeeID = 251, 1, NULL)) AS Emp251, COUNT(IF(EmployeeID = 252, 1, NULL)) AS Emp252, COUNT(IF(EmployeeID = 253, 1, NULL)) AS Emp253, COUNT(IF(EmployeeID = 254, 1, NULL)) AS Emp254 FROM PurchaseOrderHeader p WHERE p.EmployeeID BETWEEN 250 AND 254 GROUP BY VendorID;
When executed, a familiar result is obtained.
Automating data pivot, creating query dynamically
As can be seen, the query has a certain consistency, i.e. all the transformed columns are formed in a similar manner, and in order to write the query, you need to know the specific values from the table. To form a pivot query, you need to review all the possible values and only then you should write the query. Alternatively, you can pass this task to a server causing it to obtain these values and dynamically perform the routine task.
Let’s return to the first example, in which we formed the new table ProductsNew from the ProductsOld table. There, the values of properties are limited, and we can’t even know all the possible values; we only have the information on where the names of the properties and their value are stored. These are the Property and Value columns, respectively.
The whole algorithm of creating the SQL query comes down to obtaining the values, from which new columns and concatenations of unchangeable parts of the query will be formed.
SELECT
GROUP_CONCAT(
CONCAT(
' MAX(IF(Property = ''',
t.Property,
''', Value, NULL)) AS ',
t.Property
)
) INTO @PivotQuery
FROM
(SELECT
Property
FROM
ProductOld
GROUP BY
Property) t;
SET @PivotQuery = CONCAT('SELECT ProductID,', @PivotQuery, ' FROM ProductOld GROUP BY ProductID');
Variable @PivotQuery will store our query, the text has been formatted for clarity.
SELECT ProductID, MAX(IF(Property = 'Color', Value, NULL)) AS Color, MAX(IF(Property = 'Name', Value, NULL)) AS Name, MAX(IF(Property = 'ProductNumber', Value, NULL)) AS ProductNumber, MAX(IF(Property = 'Size', Value, NULL)) AS Size, MAX(IF(Property = 'SizeUnitMeasureCode', Value, NULL)) AS SizeUnitMeasureCode FROM ProductOld GROUP BY ProductID
After executing it, we will obtain the desired result corresponding to the scheme of the ProductsNew table.
What is more, the query from variable @PivotQuery can be executed in the script using MySQL statement EXECUTE.
PREPARE statement FROM @PivotQuery; EXECUTE statement; DEALLOCATE PREPARE statement;







Really good solution Alexey.
It would be perfect if mysql had the possibility of run a “SELECT * FROM Procedure “