Introduction
It is common knowledge in database circles that indexes improve query performance either by satisfying the required result set entirely (Covering Indexes) or acting as lookups which easily direct the Query Engine to the exact location of the required data set. However, as experienced DBAs know, one should not be too enthusiastic about creating indexes in OLTP environments without understanding the nature of the workload. Using Query Store in SQL Server 2019 instance (Query Store was introduced in SQL Server 2016), it is quite easy to show the effect of an index on inserts.
Insert Without Index
We start by restoring the WideWorldImporters Sample database and then creating a copy of the Sales. Invoices table using the script in Listing 1. Note that the sample database has Query Store enabled in read-write mode already.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Notice that there are no indexes at all in the table we’ve just created. All we have is the table structure. Once done, we perform inserts in the new table using the data from its parent as shown in Listing 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
During this operation, Query Store captures the execution plan of the query. Figure 1 shows briefly what is happening under the hood. Reading from left to right, we see that SQL Server executes the inserts using Plan ID 563 – an Index Scan on the source table’s Primary Key to fetch the data and then a Table Insert on the destination table. (Reading from left to right). Observe that in this case, the bulk of the cost is on the Table Insert – 99% of the query cost.
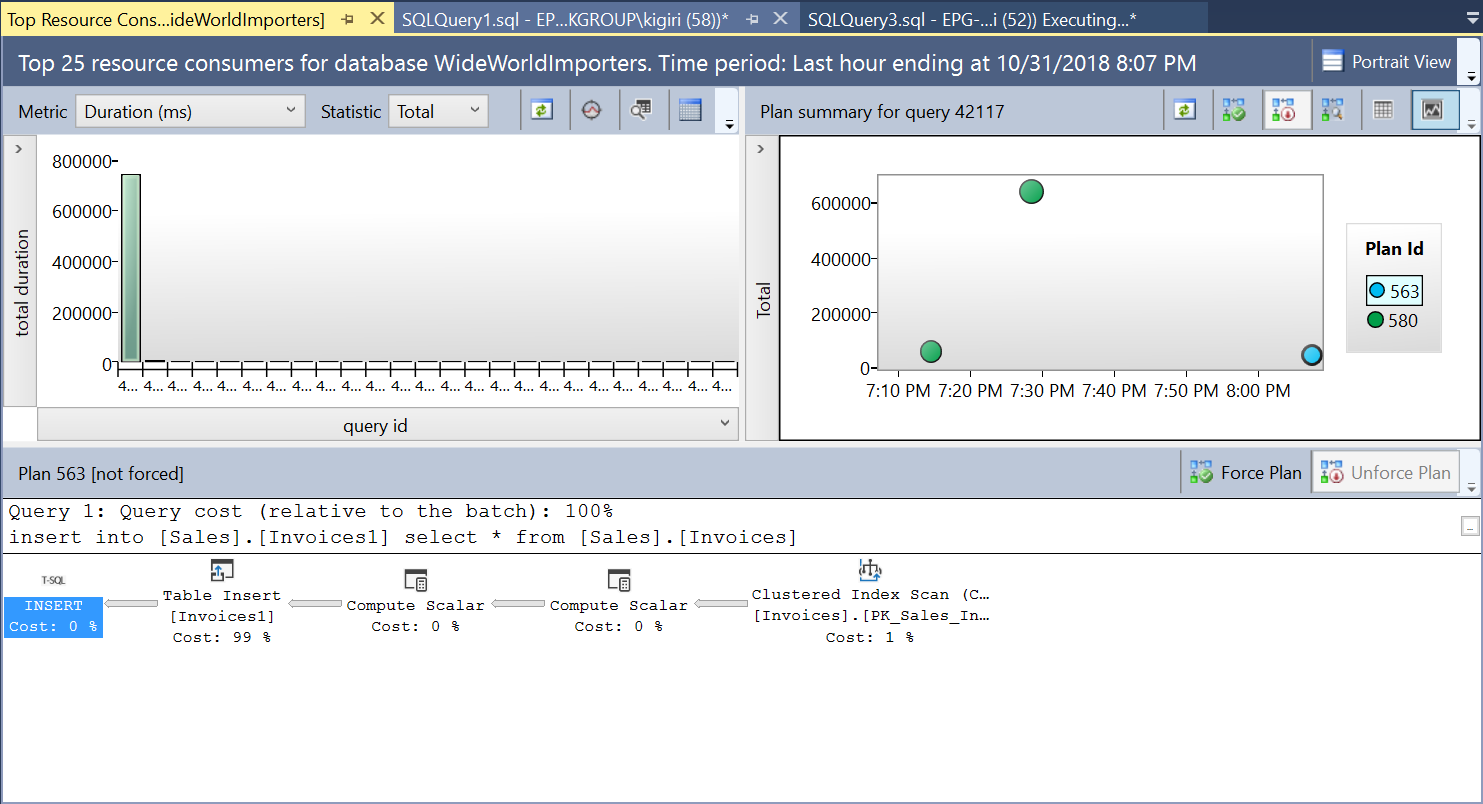
Fig. 1 Execution Plan 563
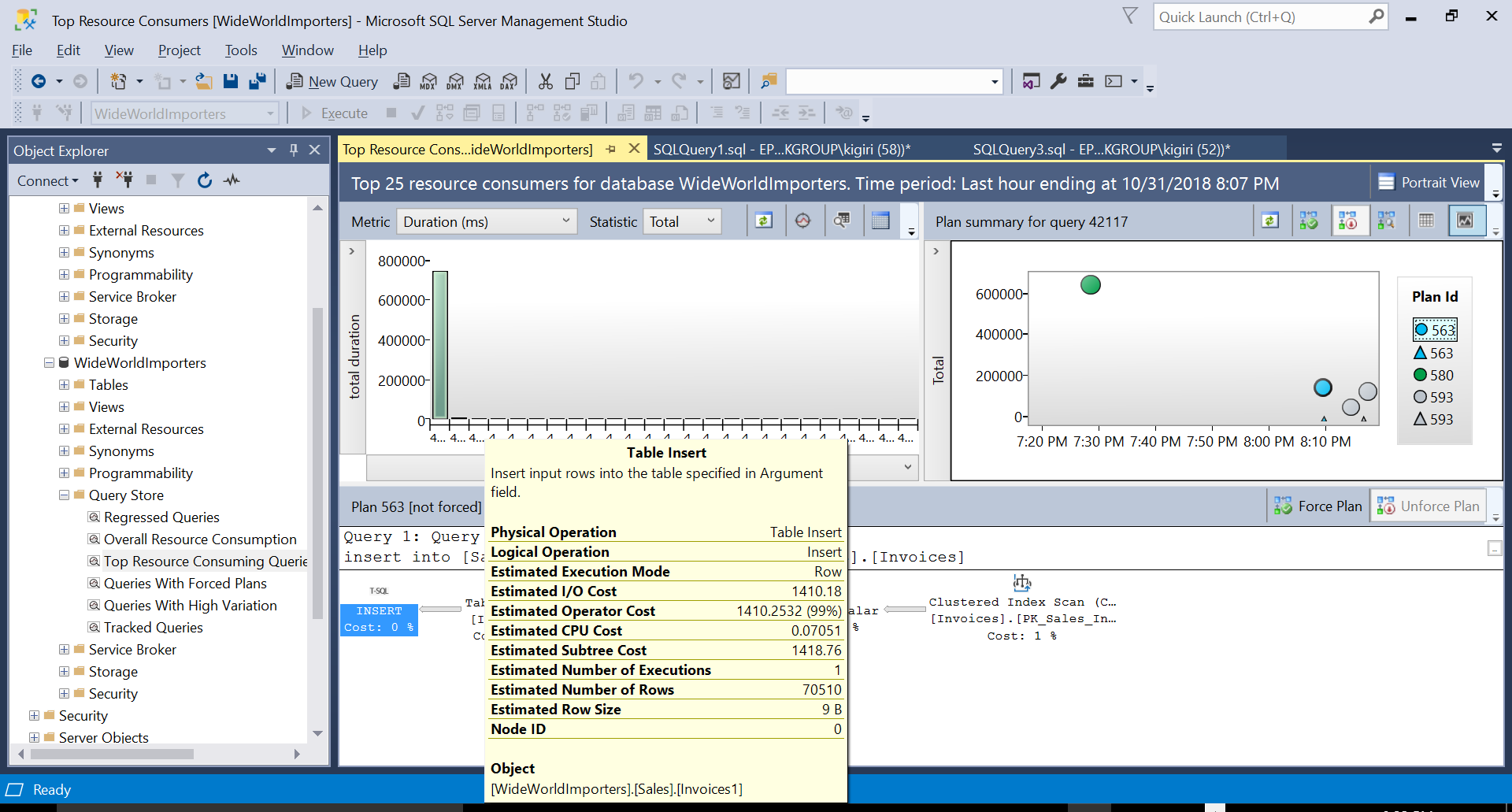
Fig. 2 Table Insert on Destination
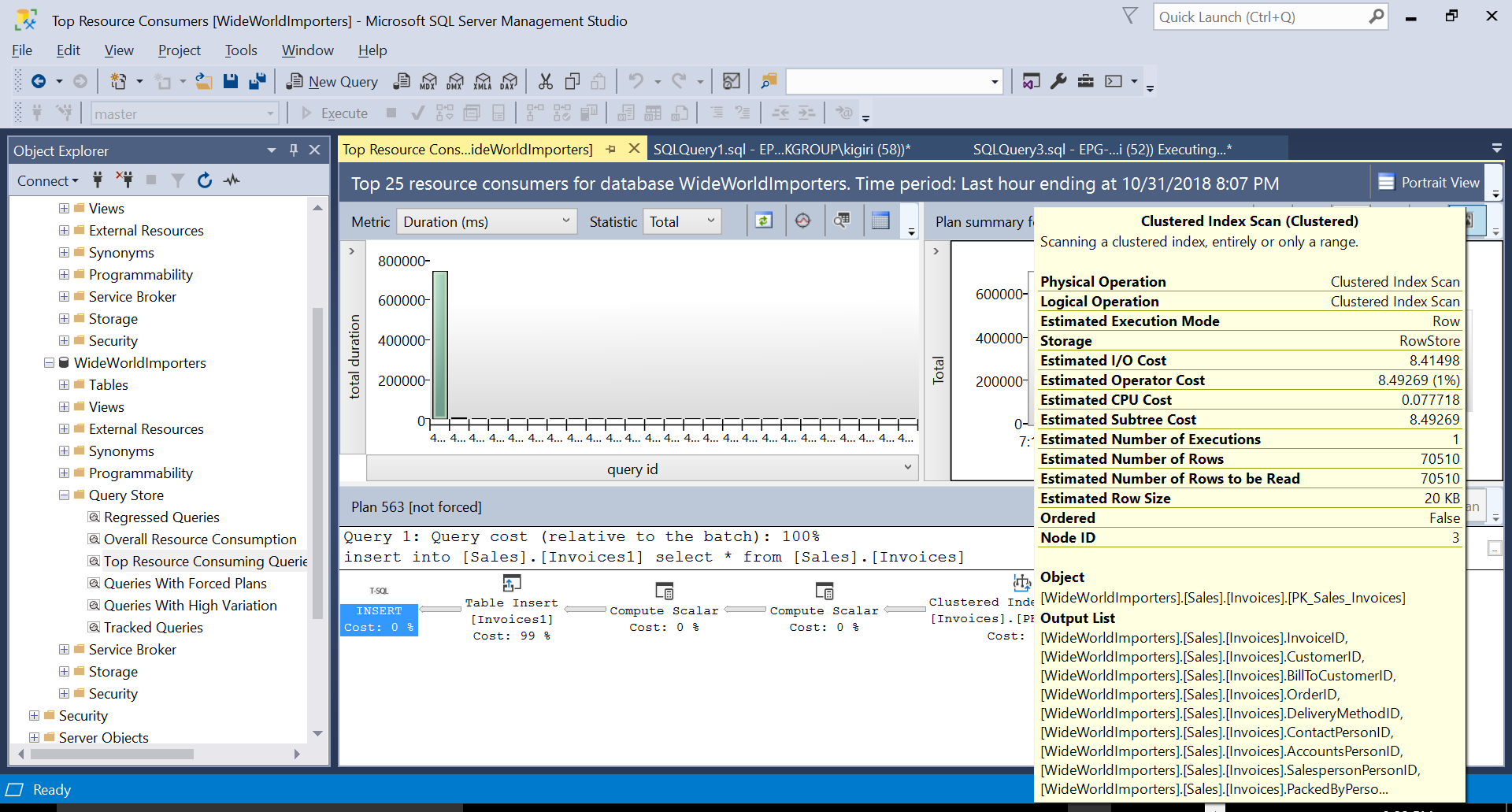
Fig. 3 Clustered Index Scan on Source Table
Insert With Index
We then create an index on the destination table using the DDL in Listing 3. When we repeat the statement in Listing 2 after truncating the destination table, we see a slightly different execution plan (Plan ID 593 shown in Fig 4). We still see the Table Insert but it contributes only 58% to the cost of the query. The execution dynamics are skewed a little with the introduction of a sort and an Index Insert. Essentially what is happening is that SQL Server must introduce corresponding rows on the index as new records are introduced in the table.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
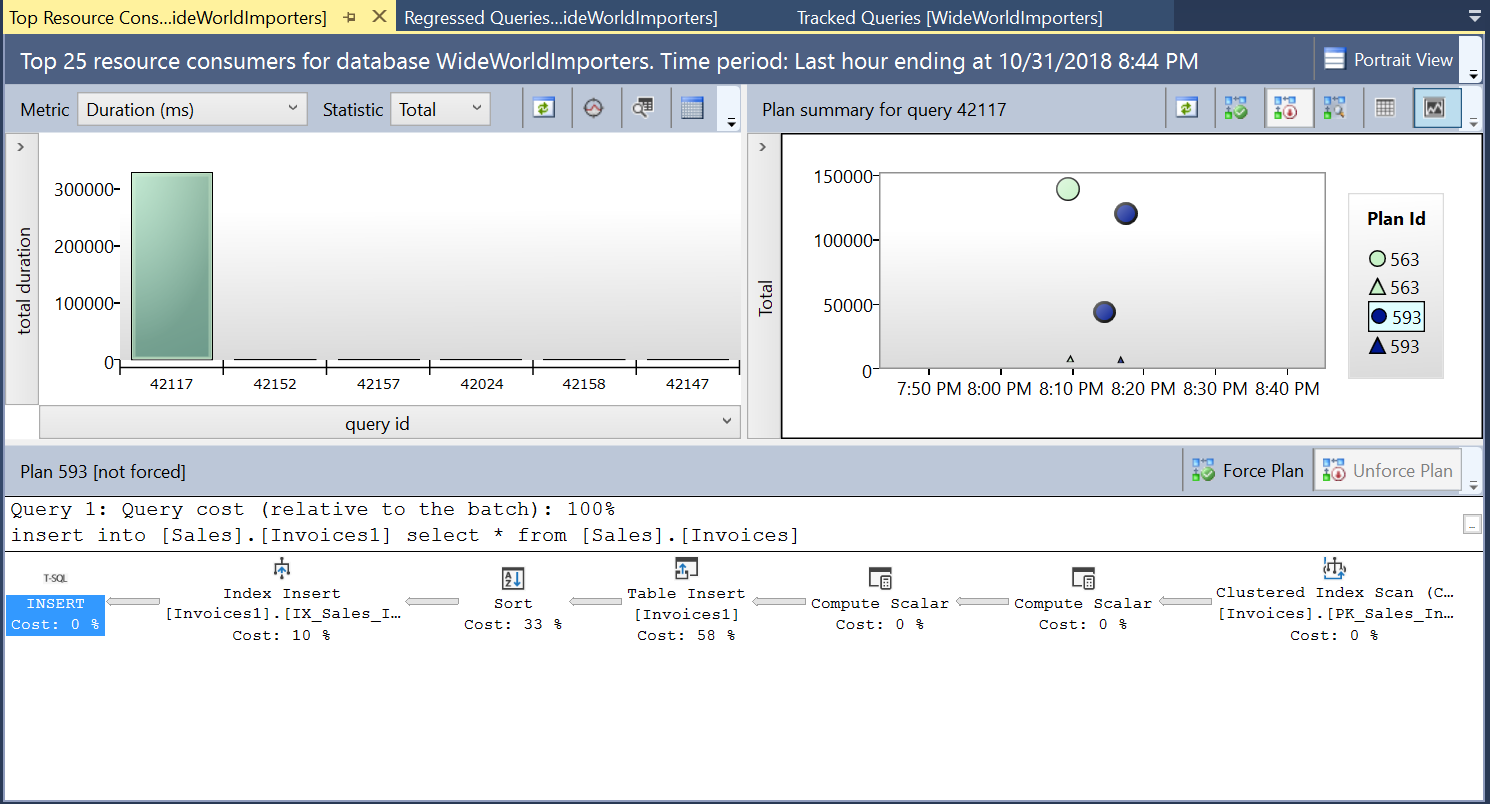
Fig. 4 Execution Plan 593
Looking Deeper
We can examine the details of both plans and see how these new factors escalate the execution time of the statement. Plan 593 adds an additional 300ms or so to the Average Duration of the statement. Under heavy workload in a production environment, this difference could be significant.
Turning STATISTICS IO on when executing the insert statement just once in both cases – with Index on destination table and without an index on Destination table – also shows that more working is done in terms of logical IO when inserting rows in a table with indexes.
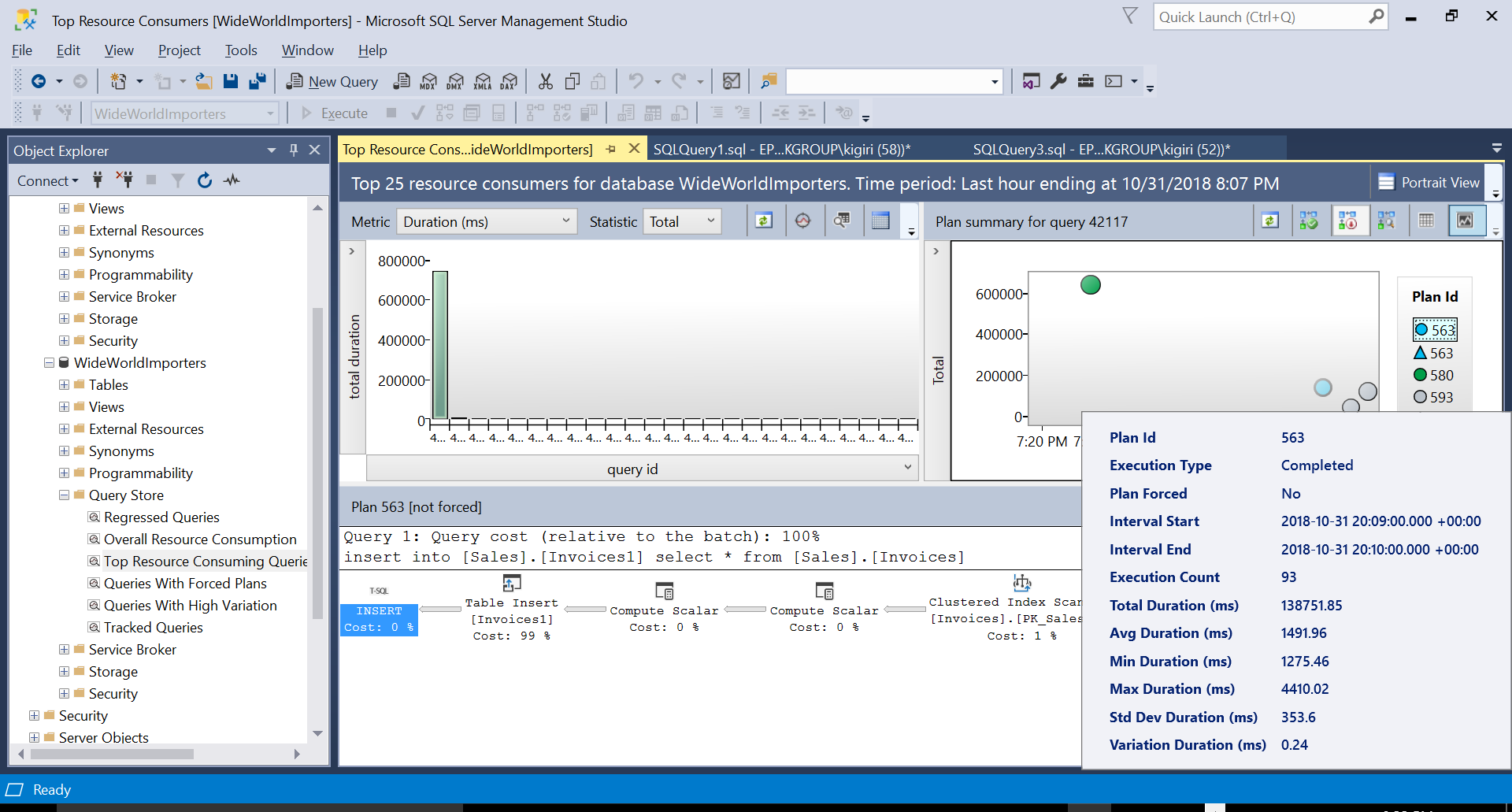
Fig. 5 Details of Execution Plan 563
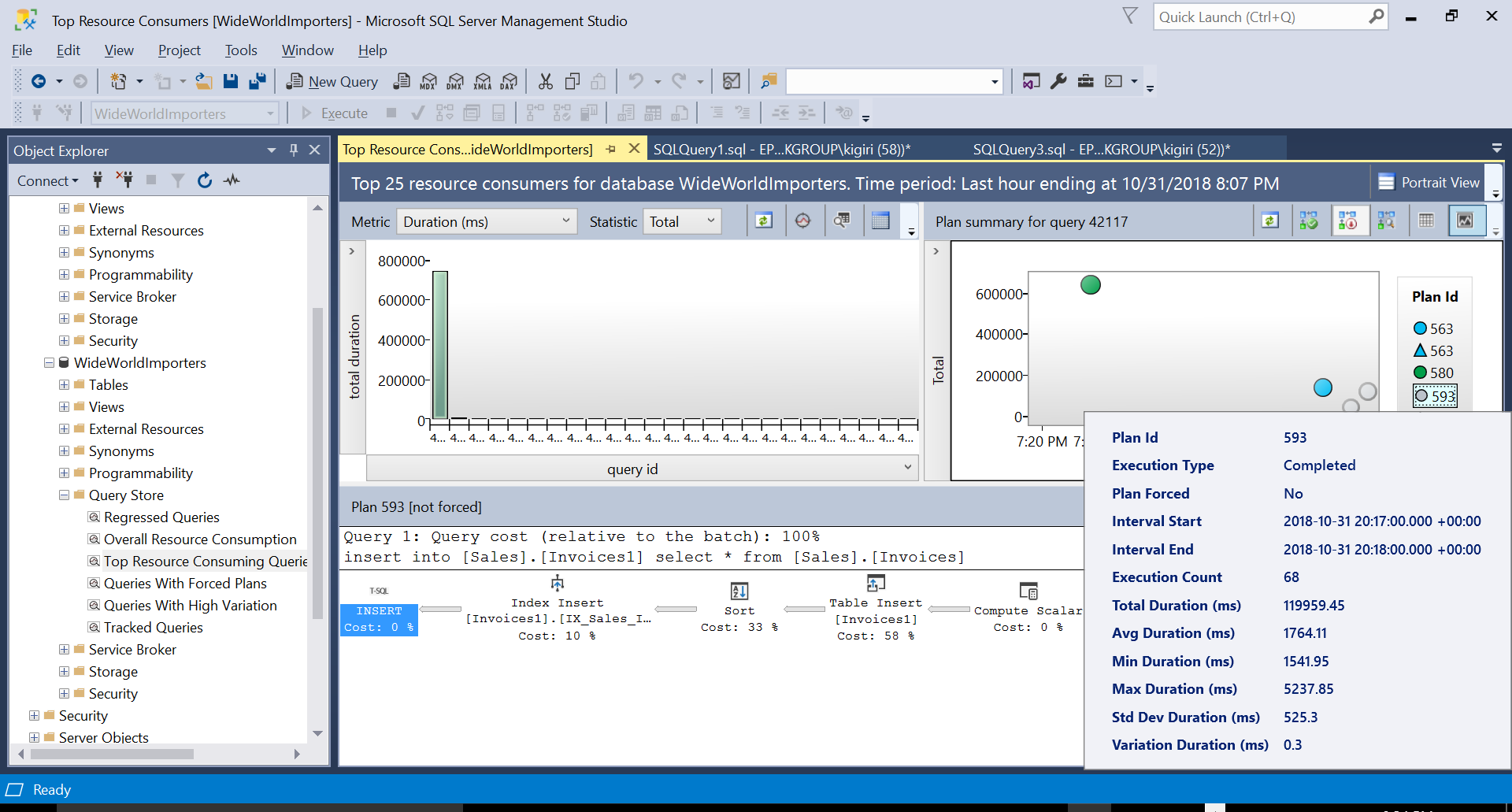
Fig. 4 Details of Execution Plan 593
No Index: Output with STATISTICS IO Turned on:
Table ‘Invoices1’. Scan count 0, logical reads 78372, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Invoices’. Scan count 1, logical reads 11400, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(70510 rows affected)
Index: Output with STATISTICS IO Turned on:
Table ‘Invoices1’. Scan count 0, logical reads 81119, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Invoices’. Scan count 1, logical reads 11400, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(70510 rows affected)
Additional Information
Microsoft and other sources provide scripts to examine indexes production environment and identify such situations as:
- Redundant Indexes – Indexes that are duplicated
- Missing Indexes – Indexes that could improve performance based on workload
- Heaps – Tables without Clustered Indexes
- Over-indexed Tables – Tables with more indexes than columns
- Index Usage – Count of seeks, scans and lookups on indexes
Items 2, 3, and 5 are more related to performance impact with respect to reads, while items 1 and 4 are related to performance impact with respect to writes. Listings 4 and 5 are two examples of these publicly available queries.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Conclusion
We have shown, using Query Store, that additional workload with an index can introduce in the execution plan of a sample insert statement. In production, excessive and redundant indexes can have a negative impact on performance, particularly in databases meant for OLTP workloads. It is important to use available scripts and tools to examine indexes and determine whether they are actually helping or hurting performance.
Useful tool:
dbForge Index Manager – handy SSMS add-in for analyzing the status of SQL indexes and fixing issues with index fragmentation.
Tags: indexes, query performance, sql server Last modified: September 22, 2021





