SQL CASE? Piece of cake!
Really?
Not until you bump into 3 troublesome issues that can cause runtime errors and slow performance.
If you are trying to scan the subheadings to see what the issues are, I can’t blame you. Readers, including me, are impatient.
I trust that you already know the basics of SQL CASE, so, I won’t bore you with long introductions. Let’s dig into a deeper understanding of what’s happening under the hood.
1. SQL CASE Does Not Always Evaluate Sequentially
Expressions in the Microsoft SQL CASE statement are mostly evaluated sequentially or from left to right. It’s a different story, though, when using it with aggregate functions. Let’s have an example:
-- aggregate function evaluated first and generated an error
DECLARE @value INT = 0;
SELECT CASE WHEN @value = 0 THEN 1 ELSE MAX(1/@value) END;
The above code looks normal. If I ask you what’s the result of those statements, you’ll probably say 1. Visual inspection tells us that because @value is set to 0. When the @value is 0, the result is 1.
But that is not the case here. Have a look at the real result from SQL Server Management Studio:
Msg 8134, Level 16, State 1, Line 4
Divide by zero error encountered.
But why?
When conditional expressions use aggregate functions like MAX() in SQL CASE, it is evaluated first. Thus, MAX(1/@value) will cause the division by zero error because @value is zero.
This situation is more troublesome when hidden. I’ll explain it later.
2. Simple SQL CASE Expression Evaluates Multiple Times
So what?
Good question. The truth is, there aren’t any problems at all if you use literals or simple expressions. But if you use subqueries as a conditional expression, you’ll get a big surprise.
Before you try the example below, you may want to restore a copy of the database from here. We will use it for the rest of the examples.
Now, consider this very simple query:
SELECT TOP 1 manufacturerID FROM SportsCars
It’s very simple, right? It returns 1 row with 1 column of data. The STATISTICS IO reveals minimal logical reads.
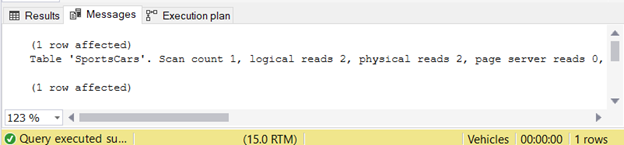
Quick note: For the uninitiated, having higher logical reads makes a query slow. Read this for more details.
The Execution Plan also reveals a simple process:
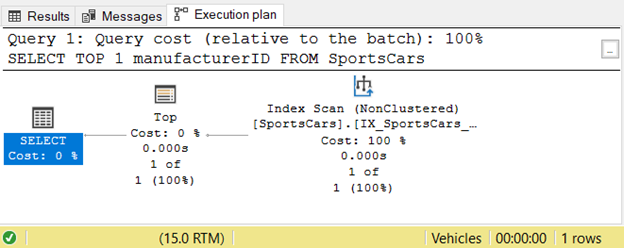
Now, let’s put that query into a CASE expression as a subquery:
-- Using a subquery in a SQL CASE
DECLARE @manufacturer NVARCHAR(50)
SET @manufacturer = (CASE (SELECT TOP 1 manufacturerID FROM SportsCars)
WHEN 6 THEN 'Alfa Romeo'
WHEN 21 THEN 'Aston Martin'
WHEN 64 THEN 'Ferrari'
WHEN 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Analysis
Cross your fingers because this is going to blow away logical reads 4 times over.
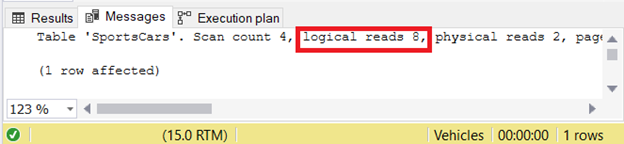
Surprise! Compared to Figure 1 with just 2 logical reads, this is 4 times higher. Thus, the query is 4 times slower. How could that happen? We only saw the subquery once.
But that’s not the end of the story. Check out the Execution Plan:
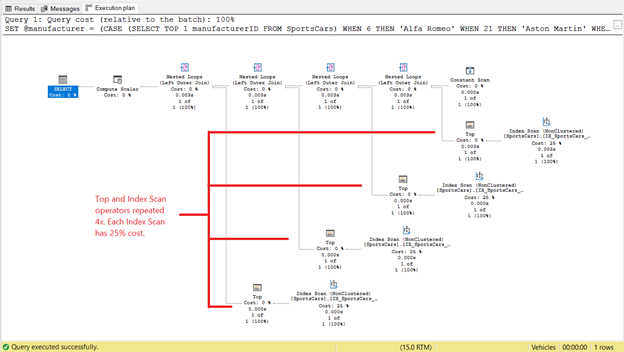
We see 4 instances of the Top and Index Scan operators in Figure 4. If each Top and Index Scan consume 2 logical reads, that explains why the logical reads became 8 in Figure 3. And since each Top and Index Scan have a 25% cost, it also tells us that they are the same.
But it doesn’t end there. The Properties of the Compute Scalar operator reveal how the entire statement is treated.
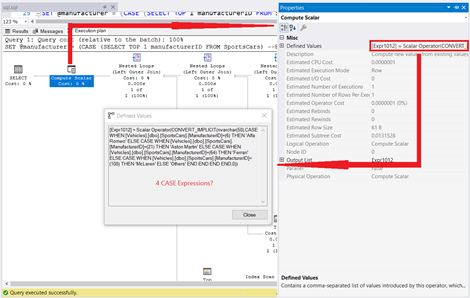
We see 4 CASE WHEN expressions coming from the Compute Scalar operator Defined Values. Looks like our simple CASE expression became a searched CASE expression like this:
DECLARE @manufacturer NVARCHAR(50)
SET @manufacturer = (CASE
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 6 THEN 'Alfa Romeo'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 21 THEN 'Aston Martin'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 64 THEN 'Ferrari'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Let’s recap. There were 2 logical reads for each Top and Index Scan operator. This multiplied by 4 makes 8 logical reads. We also saw 4 CASE WHEN expressions in the Compute Scalar operator.
In the end, the subquery in the simple CASE expression was evaluated 4 times. This will lag your query.
How to Avoid Multiple Evaluations of a Subquery in a Simple CASE Expression
To avoid such performance problem as multiple CASE statement in SQL, we need to rewrite the query.
First, put the result of the subquery in a variable. Then, use that variable in the condition of the simple SQL Server CASE expression, like this:
DECLARE @manufacturer NVARCHAR(50)
DECLARE @ManufacturerID INT -- create a new variable
-- store the result of the subquery in a variable
SET @ManufacturerID = (SELECT TOP 1 manufacturerID FROM SportsCars)
-- use the new variable in the simple CASE expression
SET @manufacturer = (CASE @ManufacturerID
WHEN 6 THEN 'Alfa Romeo'
WHEN 21 THEN 'Aston Martin'
WHEN 64 THEN 'Ferrari'
WHEN 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Is this a good fix? Let’s see the logical reads in STATISTICS IO:

We see lower logical reads from the modified query. Taking the subquery out and assigning the result to a variable is much better. How about the Execution Plan? See it below.
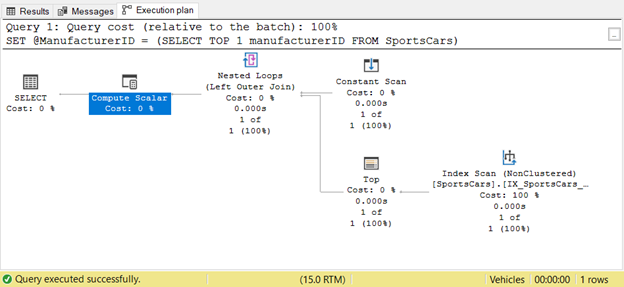
The Top and Index Scan operator appeared only once, not 4 times. Wonderful!
Takeaway: Do not use a subquery as a condition in the CASE expression. If you need to retrieve a value, put the result of the subquery in a variable first. Then, use that variable in the CASE expression.
3. These 3 Built-in Functions Secretly Transform to SQL CASE
There’s a secret, and the SQL Server CASE statement has something to do with it. If you don’t know how these 3 functions behave, you won’t know you’re committing a mistake that we tried to avoid in points #1 and #2 earlier. Here they are:
- IIF
- COALESCE
- CHOOSE
Let’s examine them one by one.
IIF
I used Immediate IF, or IIF, in Visual Basic and Visual Basic for Applications. This is also equivalent to C#’s ternary operator: <condition> ? <result_if_true> : <result_if_false>.
This function given a condition will return 1 of the 2 arguments based on the condition result. And this function is also available in T-SQL. CASE Statement in the WHERE clause can be used within the SELECT statement
But it’s just a sugarcoat of a longer CASE expression. How do we know? Let’s examine an example.
SELECT IIF((SELECT Model FROM SportsCars WHERE SportsCarID = 1276) = 'McLaren Senna', 'Yes', 'No');The result of this query is ‘No.’ However, check out the Execution Plan along with the properties of Compute Scalar.
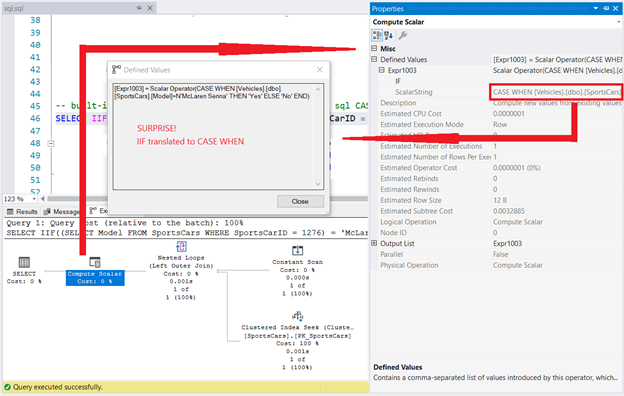
Since IIF is CASE WHEN what do you think will happen if you execute something like this?
DECLARE @averageCost MONEY = 1000000.00;
DECLARE @noOfPayments TINYINT = 0; -- intentional to force the error
SELECT IIF((SELECT Model FROM SportsCars WHERE SportsCarID = 1276) = 'SF90 Spider', 83333.33,MIN(@averageCost / @noOfPayments));
This will result in a Divide by Zero error if @noOfPayments is 0. The same happened at point #1 earlier.
You may wonder what causes this error because the above query will result in TRUE and should return 83333.33. Check point #1 again.
Thus, if you’re stuck with an error like this when using IIF, SQL CASE is the culprit.
COALESCE
COALESCE is also a shortcut of a SQL CASE expression. It evaluates the list of values and returns the first non-null value. In the previous article about COALESCE, I presented an example that evaluates a subquery twice. But I used another method to reveal the SQL CASE in the Execution Plan. Here’s another example that will use the same techniques.
SELECT
COALESCE(m.Manufacturer + ' ','') + sc.Model AS Car
FROM SportsCars sc
LEFT JOIN Manufacturers m ON sc.ManufacturerID = m.ManufacturerID
Let’s see the Execution Plan and the Compute Scalar Defined Values.
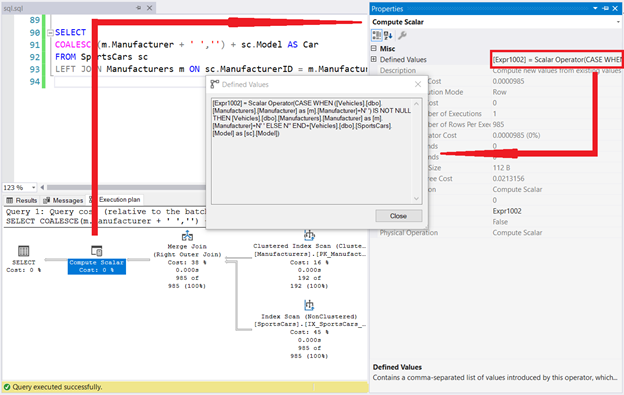
SQL CASE is alright. The COALESCE keyword is nowhere in the Defined Values window. This proves the secret behind this function.
But that’s not all. How many times did you see [Vehicles].[dbo].[Styles].[Style] in the Defined Values window? TWICE! This is consistent with the official Microsoft documentation. Imagine if one of the arguments in COALESCE is a subquery. Then, double the logical reads and get the slower execution too.
CHOOSE
Finally, CHOOSE. This is similar to the MS Access CHOOSE function. It returns 1 value from a list of values based on an index position. It also acts as an index into an array.
Let’s see if we can dig the transformation into a SQL CASE with an example. Check out the code below:
;WITH McLarenCars AS
(
SELECT
CASE
WHEN sc.Model IN ('Artura','Speedtail','P1/ P1 GTR','P1 LM') THEN '1'
ELSE '2'
END AS [type]
,sc.Model
,s.Style
FROM SportsCars sc
INNER JOIN Styles s ON sc.StyleID = s.StyleID
WHERE sc.ManufacturerID = 108
)
SELECT
Model
,Style
,CHOOSE([Type],'Hybrid','Gasoline') AS [type]
FROM McLarenCars
There’s our CHOOSE example. Now, let’s check the Execution Plan and the Compute Scalar Defined Values:
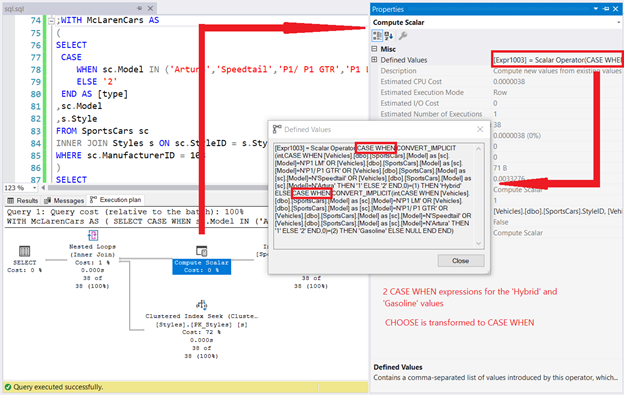
Do you see the keyword CHOOSE in the Defined Values window in Figure 10? How about CASE WHEN?
Like the previous examples, this CHOOSE function is just a sugarcoat to a longer CASE expression. And since the query has 2 items for CHOOSE, the CASE WHEN keywords appeared twice. See the Defined Values window enclosed in a red box.
However, we have multiple CASE WHEN in SQL here. That’s because of the CASE expression in the inner query of the CTE. If you look carefully, that part of the inner query appears twice too.
Takeaways
Now that the secrets are out, what have we learned?
- SQL CASE behaves differently when aggregate functions are used. Be careful when passing arguments to aggregate functions like MIN, MAX, or COUNT.
- A simple CASE expression will evaluate multiple times. Notice it and avoid passing a subquery. Though it’s syntactically correct, it will perform poorly.
- IIF, CHOOSE, and COALESCE have dirty secrets. Keep it in mind before passing values to those functions. It will transform into a SQL CASE. Depending on the values, you cause either an error or a performance penalty.
I hope this different take on SQL CASE has been useful to you. If so, your developer friends may like it too. Please share it on your favorite social media platforms. And let us know what you think about it in the Comments section.
Tags: sql case, sql server Last modified: September 16, 2022