According to Wikipedia, ”A Bulk insert is a process or method provided by a database management system to load multiple rows of data into a database table.” If we adjust this explanation in accordance with the BULK INSERT statement, bulk insert allows importing external data files into SQL Server. Assume that our organization has a CSV file of 1.500.000 rows and we want to import this file to a particular table in SQL Server, so we can easily use the BULK INSERT statement in SQL Server. Certainly, we can find several import methodologies to handle this CSV file import process, e.g. we can use bcp (bulk copy program), SQL Server Import and Export Wizard or SQL Server Integration Service package. However, the BULK INSERT statement is much faster and robust than using other methodologies. Another advantage of the bulk insert statement is that it offers several parameters which help to determine settings of the bulk insert process.

At first, we will start a very basic sample and then we will go through various sophisticated scenarios.
Preparation
Before starting the samples, we need a sample CSV file. Therefore, we will download a sample CSV file from E for Excel website, where you can find various sampled CSV files with a different row number. You can find the link at the end of the article. In our scenarios, we will use 1.500.000 Sales Records. Download a zip file then unzip the CSV file, and place it in your local drive.
Import CSV File into SQL Server table
Scenario-1: Destination and CSV file have an equal number of columns
In this first scenario, we will import the CSV file into the destination table in the simplest form. I placed my sample CSV file on the C: drive and now we will create a table which we will import data from the CSV file.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
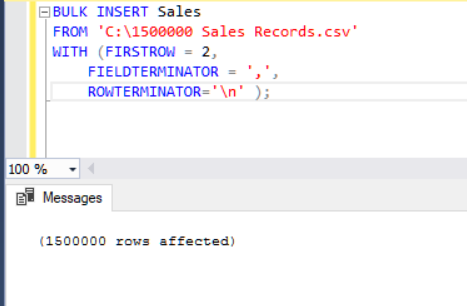
The following BULK INSERT statement imports the CSV file to the Sales table.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
Now, we will explain the parameters of the above bulk insert statement.
The FIRSTROW parameter specifies the starting point of the insert statement. In the below example, we want to skip column headers so we set this parameter to 2.

FIELDTERMINATOR defines the character which separates fields from each other. SQL Server detects each field in such a way. ROWTERMINATOR does not much differ from FIELDTERMINATOR. It defines the separation character of rows. In the sample CSV file, fieldterminator is very clear and it is a comma (,). But how can we detect a fieldterminator? Open the CSV file in Notepad++ and then navigate to View->Show Symbol->Show All Charters, and then find out the CRLF characters at the end of each field.
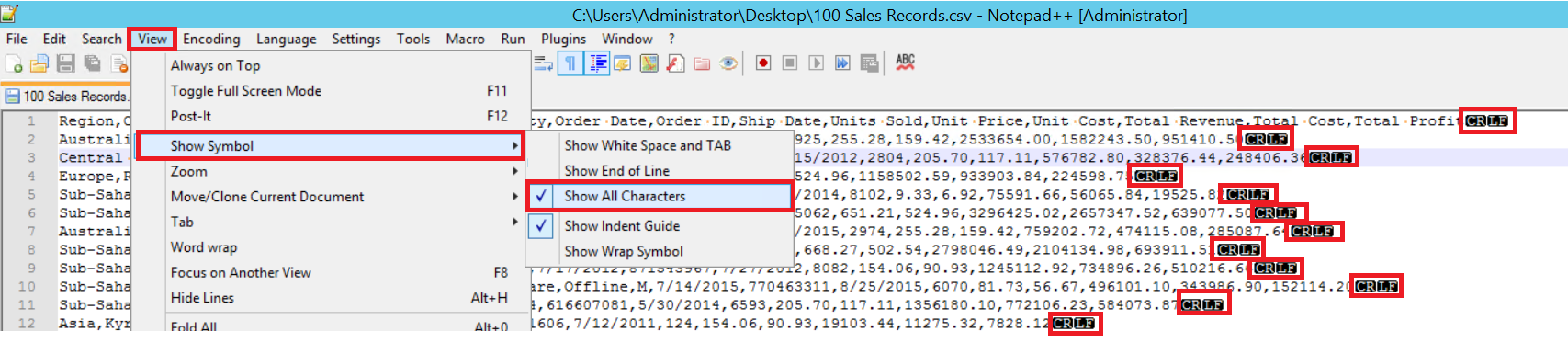
CR = Carriage Return and LF = Line Feed. They are used to mark a line break in a text file and it is indicated by the “\n” character in the bulk insert statement.
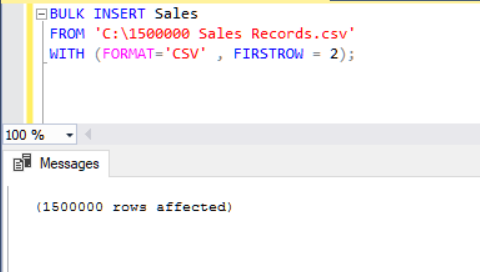
Another method of importing a CSV file to a table with help of bulk insert is using the FORMAT parameter. Please note that the FORMAT parameter is available only in SQL Server 2017 and later versions.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Now we will analyze another scenario.
Scenario-2: Destination table has more columns then CSV file
In this scenario, we will add a primary key to the Sales table and this case breaks the equality column mappings. Now, we will create the Sales table with a primary key, try to import the CSV file through the bulk insert command, and then we will get an error.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
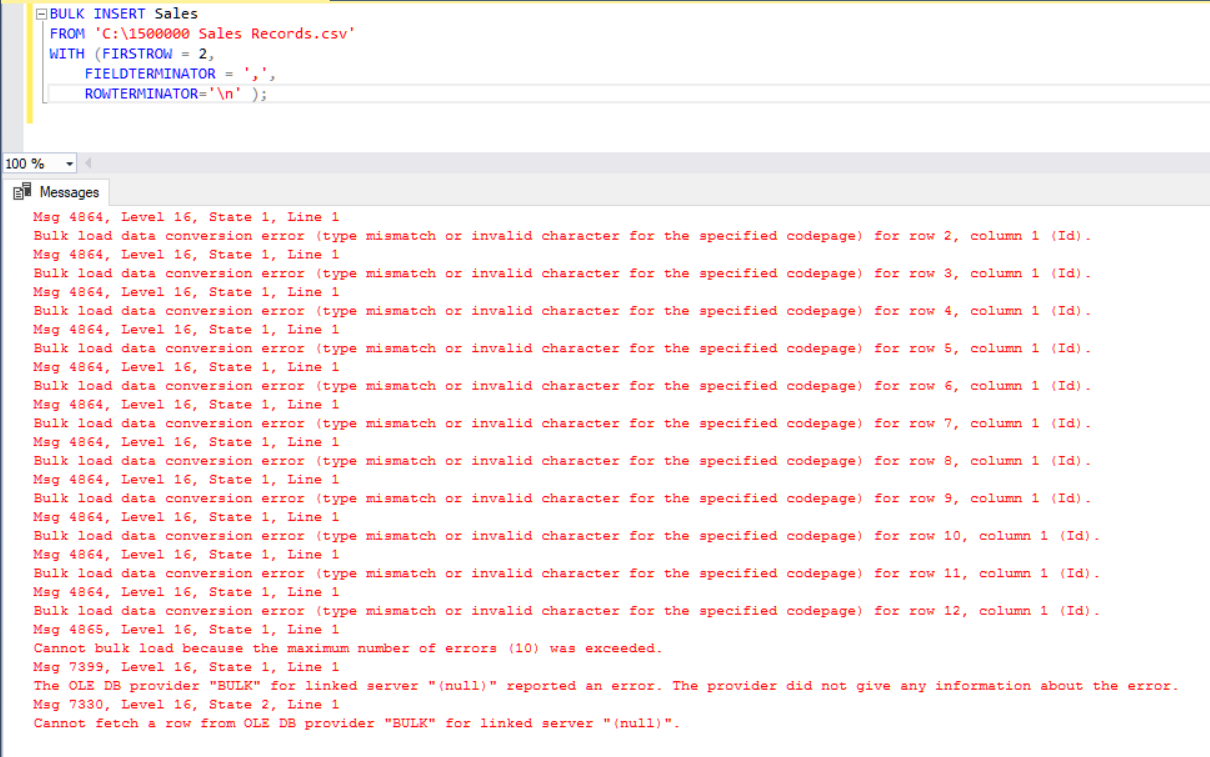
In order to overcome this error, we will create a view of the Sales table with mapping columns to the CSV file and import the CSV data over this view to the Sales table.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
Scenario-3: How to separate and load CSV file into small batch size?
SQL Server acquires a lock to destination table during the bulk insert operation. By default, if you do not set the BATCHSIZE parameter, SQL Server opens a transaction and inserts the whole CSV data into this transaction. However, if you set the BATCHSIZE parameter, SQL Server divides the CSV data according to this parameter value. In the following sample, we will divide the whole CSV data into several sets of 300.000 rows each. Thus the data will be imported at 5 times.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
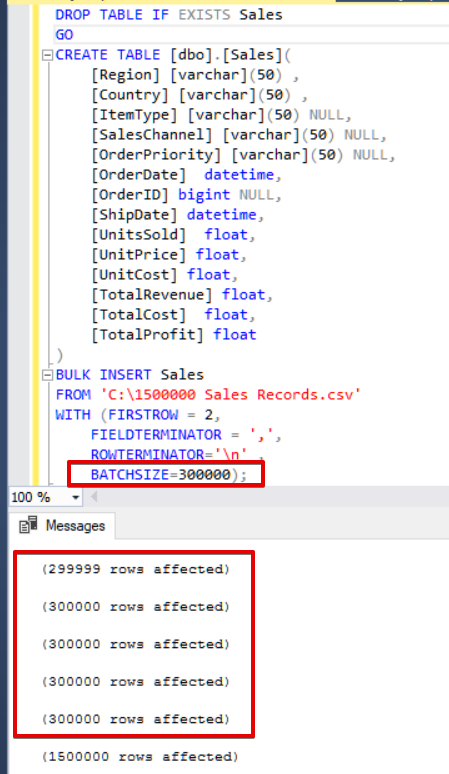
If your bulk insert statement does not include the batch size (BATCHSIZE) parameter, an error will occur, and SQL Server will rollback the whole bulk insert process. On the other hand, if you set the batch size parameter to bulk insert statement, SQL Server will rollback only this divided part where the error occurred. There is no optimum or best value for this parameter because this parameter value can be changed according to your database system requirements.
Scenario-4: How to cancel the import process when getting an error?
In some bulk copy scenarios, if an error occurs, we may want either cancel the bulk copy process or keep the process going. The MAXERRORS parameter allows us to specify the maximum number of errors. If the bulk insert process reaches this max error value, the bulk import operation will be canceled and rollbacked. The default value for this parameter is 10.
In the following example, we will intentionally corrupt data type in 3 rows of the CSV file and set the MAXERRORS parameter to 2. As a result, the whole bulk insert operation will be canceled because the error number exceeds the max error parameter.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
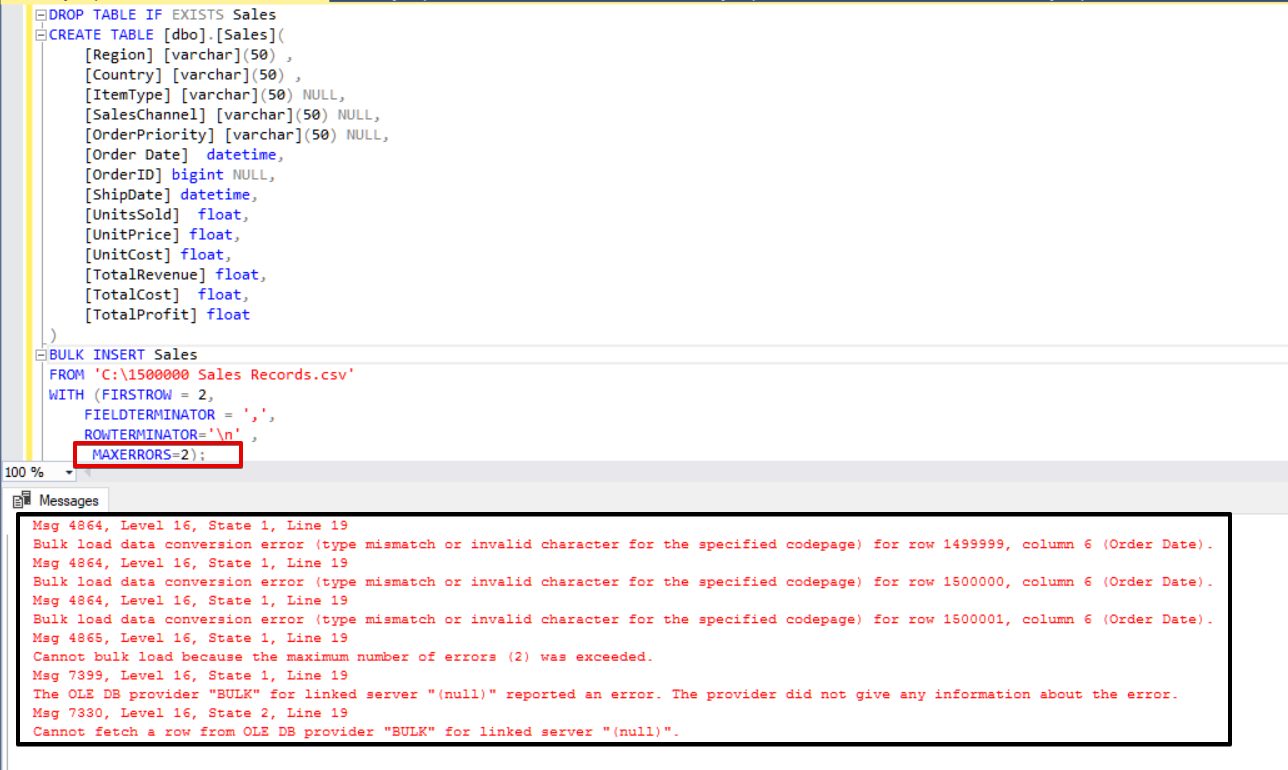
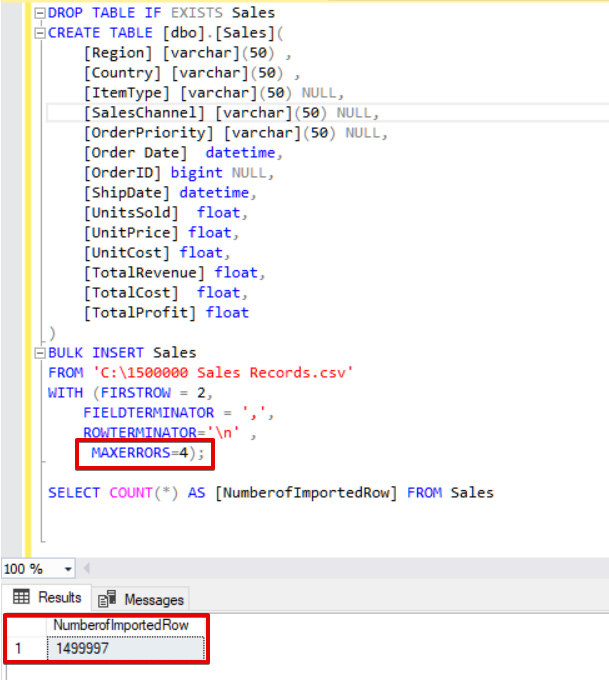
Now we will change the max error parameter to 4. As a result, the bulk insert statement will skip these rows and insert proper data structured rows, and complete the bulk insert process.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
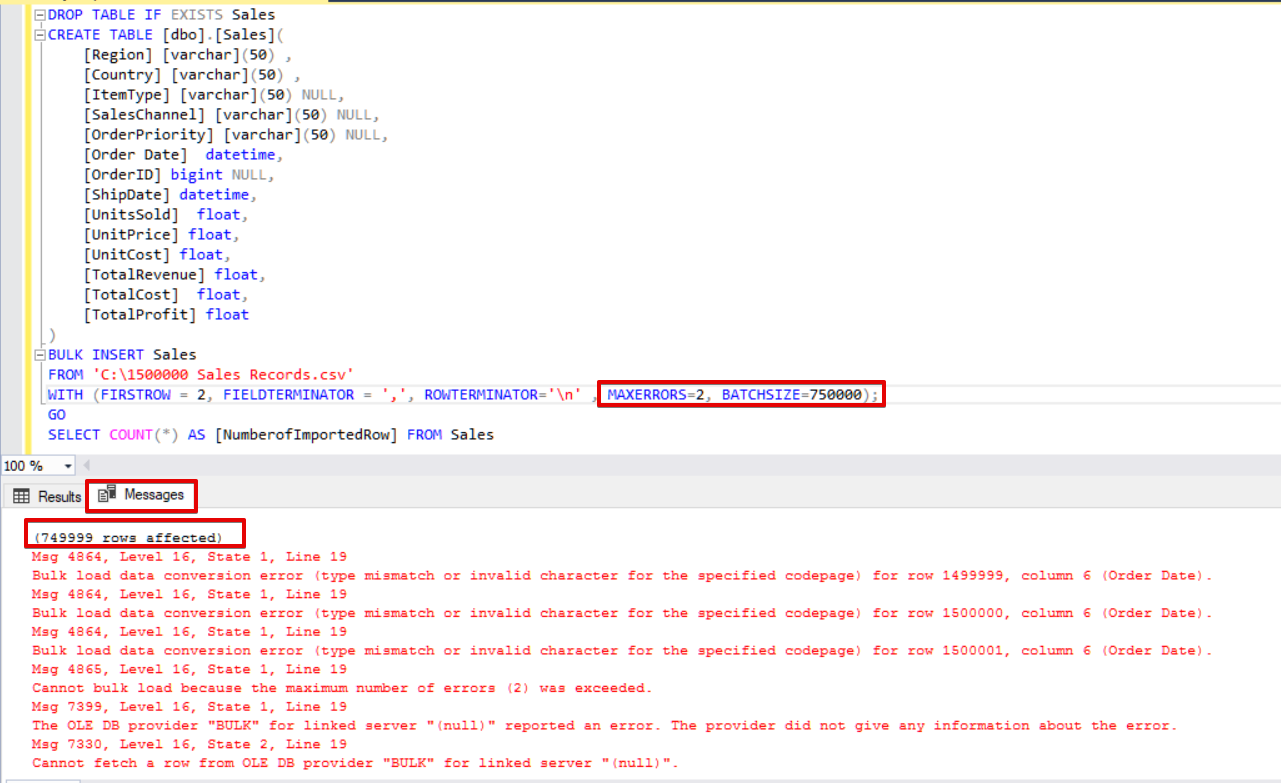
In addition, if we use both, the batch size and maximum error parameters at the same time, the bulk copy process will not cancel the whole insert operation, it will only cancel the divided part.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
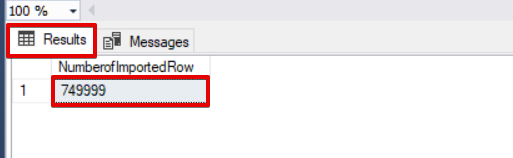
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
In this first part of this article series, we discussed the basics of using the bulk insert operation in SQL Server and analyzed several scenarios which are close to the real-life issues.

Useful links:
Bulk insert
QL Server Bulk Insert – Part 2
E for Excel – Sample CSV Files / Data Sets for Testing (till 1.5 Million Records)
Useful tool:
dbForge Data Pump – an SSMS add-in for filling SQL databases with external source data and migrating data between systems.
Tags: sql, sql server, t-sql, t-sql statements Last modified: August 08, 2022




