In database programming, there are four fundamental operations: create, read, update, and delete – CRUD operations. They are the first step in database programming.
The term CRUD first appeared in James Martin’s book ‘Managing the Database Environment.’ Since then, this term has become popular. In this article, we’re going to explore the CRUD operation in terms of SQL Server because the operation syntax can differ from other relational and NoSQL databases.
Preparations
The main idea of relational databases is storing data in tables. The table data can be read, inserted, deleted. This way, CRUD operations manipulate the table data.
| C | CREATE | Insert row/rows into a table |
| R | READ | Read (select) row/rows from a table |
| U | UPDATE | Edit row/rows in the table |
| D | DELETE | Delete row/rows from the table |
To illustrate the CRUD operations, we need a data table. Let’s create one. It will contain only three columns. The first column will store country names, the second will store the continent of these countries and the last column will store the population of these countries. We can create this table with help of the T-SQL statement and entitle it as TblCountry.
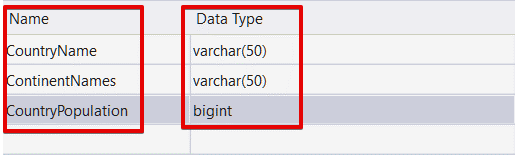
CREATE TABLE [dbo].[TblCountry]
(
[CountryName] VARCHAR(50),
[ContinentNames] VARCHAR(50) NULL,
[CountryPopulation] BIGINT NULL
)
Now, let us review the CRUD operations performed on the TblCountry table.
C – CREATE
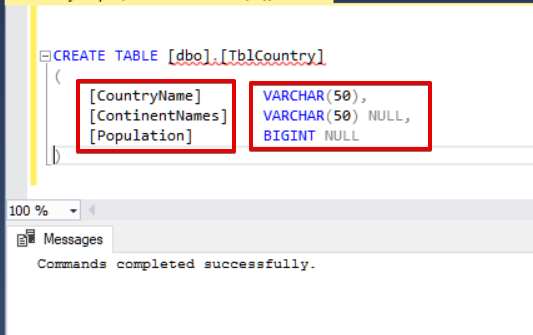
To add new rows to a table, we use the INSERT INTO command. In this command, we need to specify the name of the target table and will list the column names in brackets. The statement structure should end with VALUES:
INSERT INTO TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES ('Germany','Europe',8279000 )
To add multiple rows to the table, we can use the following type of the INSERT statement:
INSERT INTO TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES
('Germany','Europe',8279000 ),
('Japan','Asia',126800000 ),
('Moroco','Africa',35740000)
Note that the INTO keyword is optional, and you don’t need to use it in the insert statements.
INSERT TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES
('Germany','Europe',8279000 ),
('Japan','Asia',126800000 ),
('Moroco','Africa',35740000)
Also, you can use the following format to insert multiple rows to the table:
INSERT INTO TblCountry
SELECT 'Germany','Europe',8279000
UNION ALL
SELECT 'Japan','Asia',126800000
UNION ALL
SELECT 'Moroco','Africa',35740000
Now, we will copy data directly from the source table to the destination table. This method is known as the INSERT INTO … SELECT statement.
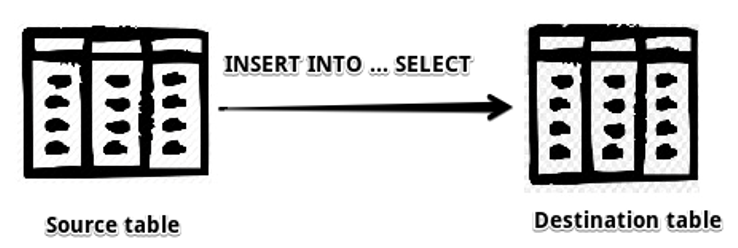
INSERT INTO … SELECT requires matching the data types of the source and destination tables. In the following INSERT INTO … SELECT statement, we will insert the data of the SourceCountryTbl table into the TblCountry table.
At first, we insert some synthetic data into the SourceCountryTbl table for this demonstration.
DROP TABLE IF EXISTS [SourceCountryTbl]
CREATE TABLE [dbo].[SourceCountryTbl]
(
[SourceCountryName] VARCHAR(50),
[SourceContinentNames] VARCHAR(50) NULL,
[SourceCountryPopulation] BIGINT NULL
)
INSERT INTO [SourceCountryTbl]
VALUES
('Ukraine','Europe',44009214 ) ,
('UK','Europe',66573504) ,
('France','Europe',65233271)
Now we will perform the INSERT INTO … SELECT statement.
INSERT INTO TblCountry
SELECT * FROM SourceCountryTbl
The above insert statement added all SourceCountryTbl data to the TblCountry table. We can also add the WHERE clause to filter the select statement.
INSERT INTO TblCountry
SELECT * FROM SourceCountryTbl WHERE TargetCountryName='UK'
SQL Server allows us to use table variables (objects which help to store temporary table data in the local scope) with the INSERT INTO … SELECT statements. In the following demonstration, we will use the table variable as a source table:
DECLARE @SourceVarTable AS TABLE
([TargetCountryName] VARCHAR(50),
[TargetContinentNames] VARCHAR(50) NULL,
[TargetCountryPopulation] BIGINT NULL
)
INSERT INTO @SourceVarTable
VALUES
('Ukraine','Europe',44009214 ) ,
('UK','Europe',66573504) ,
('France','Europe',65233271)
INSERT INTO TblCountry
SELECT * FROM @SourceVarTable
Tip: Microsoft announced a feature in SQL Server 2016 which is parallel insert. This feature allows us to perform INSERT operations in parallel threads.
If you add the TABLOCK hint at the end of your insert statement, SQL Server can choose a parallel with the processing execution plan according to your server’s max degree of parallelism or the cost threshold for parallelism parameters.
Parallel insert processing will also reduce the performing time of the insert statement. However, the TABLOCK hint will acquire the lock of the inserted table during the insert operation. For more information about the parallel insert, you can refer to the Real World Parallel INSERT…SELECT.
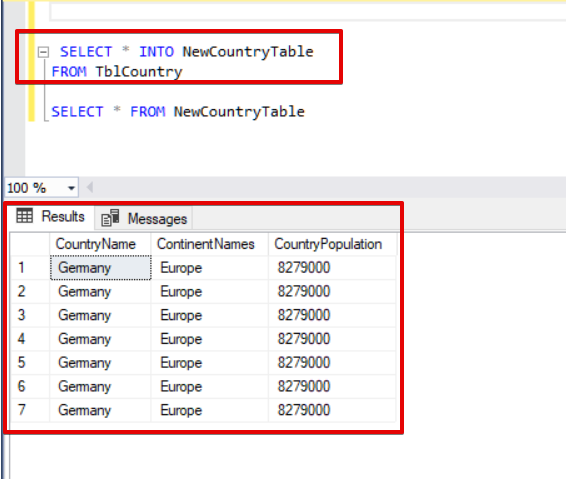
Another handy statement is SELECT INTO. This method allows us to copy data from one table into a newly-created table. In the following statement, NewCountryTable did not exist before the execution of the query. The query creates the table and inserts all data from the TblCountry table.
SELECT * INTO NewCountryTable
FROM TblCountry
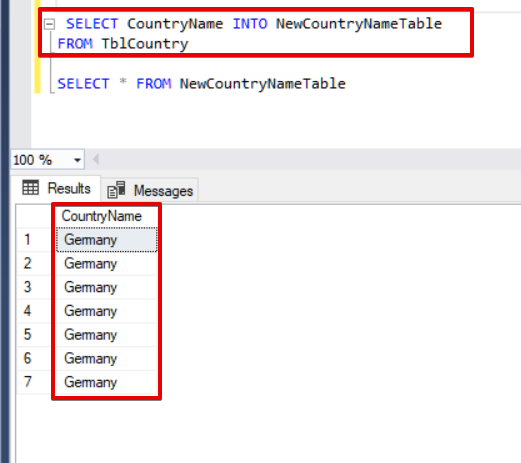
At the same time, we can create a new table for particular columns of the source table.
In some cases, we need to return and use inserted values from the INSERT statement. Since SQL Server 2005, the INSERT statement allows us to retrieve values in question from the INSERT statement.
Now, we will drop and create our test table and add a new identity column. Also, we will add a default constraint to this column. Thereby, if we don’t insert any explicit value to this column, it will automatically create a new value.
In the following sample, we will declare a table having one column and insert the output of the SeqID column value to this table with help of the OUTPUT column:
DROP TABLE IF EXISTS TblCountry
CREATE TABLE [dbo].[TblCountry]
(
[CountryName] VARCHAR(50),
[ContinentNames] VARCHAR(50) NULL,
[CountryPopulation] BIGINT NULL ,
SeqID uniqueidentifier default(newid())
)
DECLARE @OutputID AS TABLE(LogID uniqueidentifier)
INSERT TblCountry
(CountryName,ContinentNames,CountryPopulation)
OUTPUT INSERTED.SeqId INTO @OutputID
VALUES
('Germany','Europe',8279000 )
SELECT * FROM @OutPutId
R – Read
The Read operation retrieves data from a table and returns a result set with the records of the table. In case we want to retrieve data from more than one table, we can use the JOIN operator and create a logical relation between tables.
The SELECT statement plays a single primary role in the read operation. It is based on three components:
- Column – we define the columns from which we want to retrieve data
- Table – we specify the table from which we want to get data
- Filter – we can filter the data that we want to read. This part is optional.
The simplest form of the select statement is as follows:
SELECT column1, column2,...,columnN
FROM table_name
Now, we will go through the examples. At first, we need a sample table to read. Let us create it:
DROP TABLE IF EXISTS TblCountry
GO
CREATE TABLE [dbo].[TblCountry]
(
[CountryName] VARCHAR(50),
[ContinentNames] VARCHAR(50) NULL,
[CountryPopulation] BIGINT NULL
)
GO
INSERT INTO TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES
('Germany','Europe',8279000 ),
('Japan','Asia',126800000 ),
('Moroco','Africa',35740000)
Reading all columns in the table
The asterisk (*) operator is used in the SELECT statements because it returns all columns in the table:
SELECT * FROM TblCountry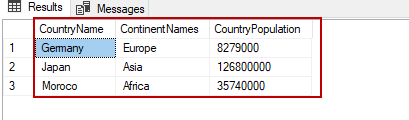
Tip: The asterisk (*) operator can influence the performance negatively because it causes more network traffic and consumes more resources. Thus, if you don’t need to get all the data from all columns returned, avoid using the asterisk (*) in the SELECT statement.
Reading particular columns of the table
We can read particular columns of the table too. Let’s review the example that will return only the CountryName and CountryPopulation columns:
SELECT CountryName,CountryPopulation FROM TblCountry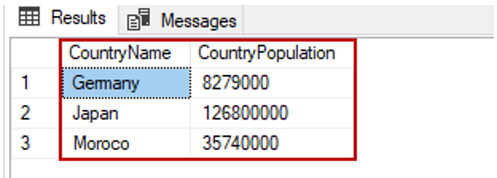
Using alias in the SELECT statements
In the SELECT statements, we can give temporary names to the table or columns. These temporary names are aliases. Let’s rewrite the previous two queries with table and column aliases.
In the following query, the TblC alias will specify the table name:
SELECT TblC.* FROM TblCountry TblC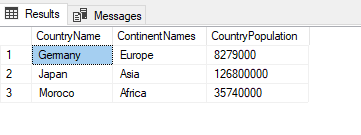
In the following example, we will provide aliases for the column names. We’ll change CountryName to CName, and CountryPopulation – to CPop.
SELECT TblC.CountryName AS [CName], CountryPopulation AS [CPop] FROM TblCountry TblC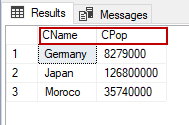
The purposes of the alias are:
- Make the query more readable if the table or column names are complex.
- Ensure using a query for the table more than one time.
- Simplify the query writing if the table or column name is long.
Filtering SELECT statements
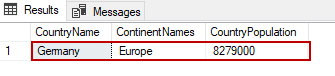
SELECT statements allow us to filter the result sets through the WHERE clause. For example, we want to filter the SELECT statement according to the CountryName column and only return the data of Germany into the resultset. The following query will perform the read operation with a filter:
SELECT TblC.* FROM TblCountry TblC
WHERE TblC.CountryName='Germany'
Sorting SELECT statements results
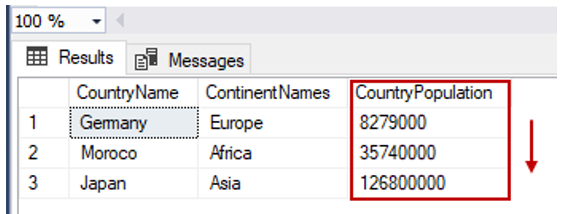
The ORDER BY clause helps us sort the result set of the SELECT statement by the specified column or columns. We can perform ascending or descending sorting with the help of the ORDER BY clause.
We’ll sort the TblCountry table according to the countries’ population in ascending order:
SELECT TblC.* FROM TblCountry TblC
ORDER BY TblC.CountryPopulation ASC
Tip: You can use the column index in the ORDER BY clause, and columns index numbers start by 1.
We can also write the previous query. The number three (3) indicates the CounrtyPopulation column:
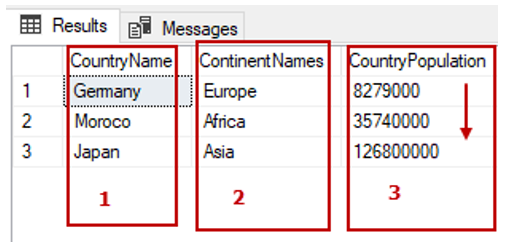
SELECT TblC.* FROM TblCountry TblC
ORDER BY 3 ASC
U – Update
The UPDATE statement modifies the existing data in the table. This statement must include the SET clause so that we can define the target column to modify the data.
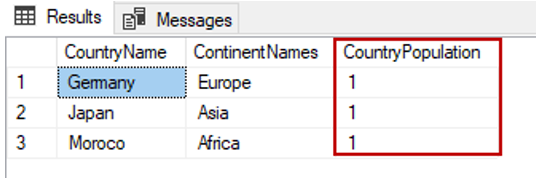
The following query will change all rows of the CounrtyPopulation column value to 1.
UPDATE TblCountry SET CountryPopulation=1
GO
SELECT TblC.* FROM TblCountry TblC
In the UPDATE statements, we can use the WHERE clause to modify a particular row or rows in the table.
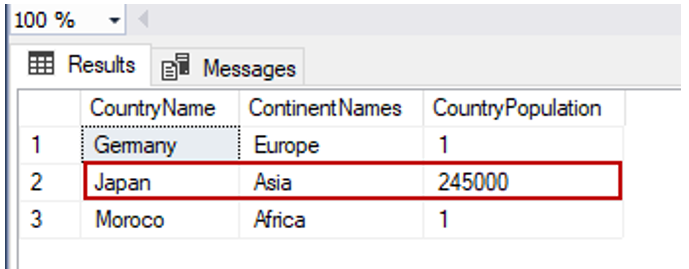
Let’s change the Japan row of CounrtyPopulation to 245000:
UPDATE TblCountry SET CountryPopulation=245000
WHERE CountryName = 'Japan'
GO
SELECT TblC.* FROM TblCountry TblC
The UPDATE statement is a union of the delete and insert statements. So, we can return the inserted and deleted values through the OUTPUT clause.
Let’s make an example:
UPDATE TblCountry SET CountryPopulation=22
OUTPUT inserted.CountryPopulation AS [Insertedvalue],
deleted.CountryPopulation AS [Deletedvalue]
WHERE CountryName = 'Germany'
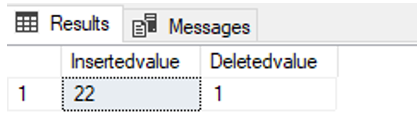
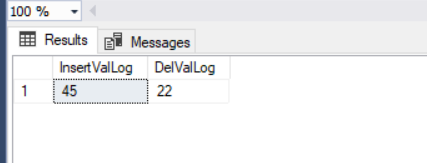
As you can see, we’ve modified the CountryPopulation value from 1 to 22. Then we can find out the inserted and deleted values. Additionally, we can insert these values into a table variable (a special variable type that can be used as a table).
We are going to insert the inserted and deleted values to the table variable:
DECLARE @LogTable TABLE(InsertValLog INT , DelValLog INT)
UPDATE TblCountry SET CountryPopulation=45
OUTPUT inserted.CountryPopulation ,
deleted.CountryPopulation INTO @LogTable
WHERE CountryName = 'Germany'
SELECT * FROM @LogTable
@@ROWCOUNT is a system variable that returns the number of rows affected in the last statement. Thus, we can use this variable to expose some modified rows in the update statement.
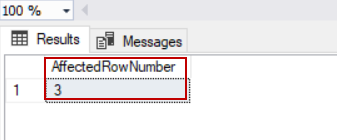
In the following example, the update query will change 3 rows, and the @@ROWCOUNT system variable will return 3.
UPDATE TblCountry SET CountryPopulation=1
SELECT @@ROWCOUNT AS [AffectedRowNumber]
D – Delete
The Delete statement removes existing row/rows from the table.
At first, let’s see how to use the WHERE clause in the DELETE statements. Most of the time we want to filter deleted rows.
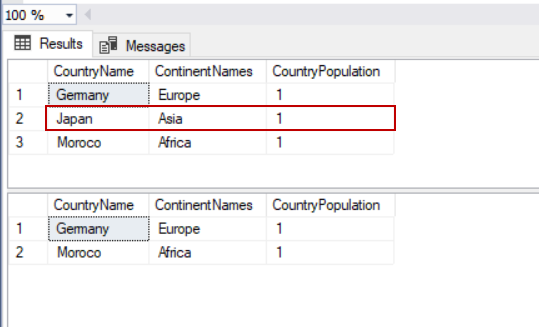
The below example illustrates how to remove a particular row:
SELECT TblC.* FROM TblCountry TblC
DELETE FROM TblCountry WHERE CountryName='Japan'
SELECT TblC.* FROM TblCountry TblC
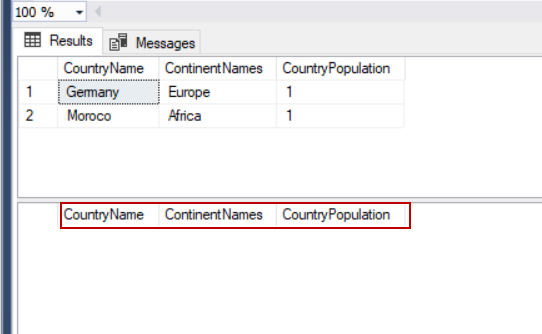
Though with the DELETE statement, we can remove all records from the table. However, the DELETE statement is very basic, and we don’t use the WHERE condition.
SELECT TblC.* FROM TblCountry TblC
DELETE FROM TblCountry
SELECT TblC.* FROM TblCountry TblC
Still, under some circumstances of the database designs, the DELETE statement does not delete the row/rows if it violates foreign keys or other constraints.
For example, in the AdventureWorks database, we cannot delete rows of the ProductCategory table because ProductCategoryID is specified as a foreign key in that table.
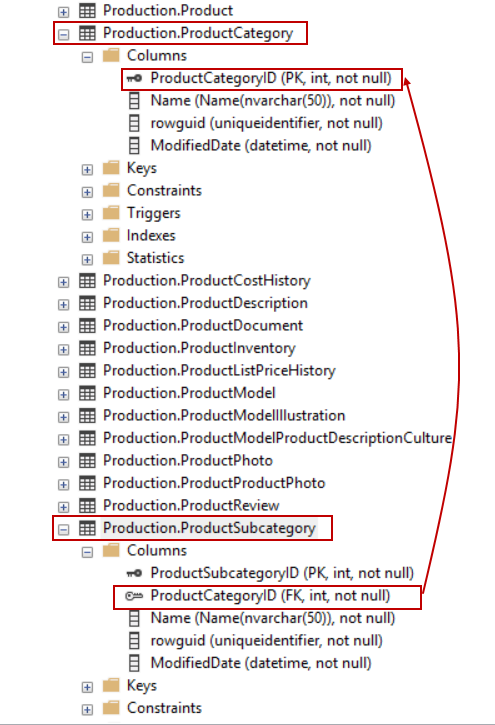
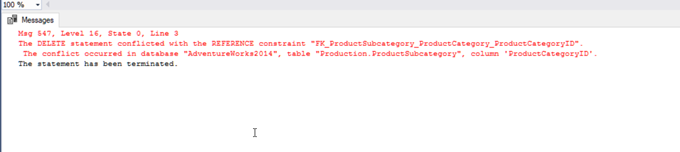
Let us try to delete a row from the ProductCategory table – in no doubt, we will face the following error:
DELETE FROM [Production].[ProductCategory]
WHERE ProductCategoryID=1
Conclusion
Thus, we have explored the CRUD operations in SQL. The INSERT, SELECT, UPDATE, and DELETE statements are the basic functions of the SQL database, and you have to master them if you want to learn SQL database programming. The CRUD theory could be a good starting point, and a lot of practice will help you become an expert.
Tags: sql, sql server, t-sql Last modified: October 13, 2021





