Do your choices of SQL server data types and their sizes matter?
The answer lies in the result you got. Did your database balloon in a short time? Are your queries slow? Did you have the wrong results? How about runtime errors during inserts and updates?
It is not so much a daunting task if you know what you’re doing. Today, you will learn the 5 worst choices one can make with these data types. If they have become a habit of yours, this is the thing we should fix for your own sake and your users.
Lots of Data Types in SQL, Lots of Confusion
When I first learned about SQL Server data types, the choices were overwhelming. All the types are mixed up in my mind like this word cloud in Figure 1:

However, we can organize it into categories:
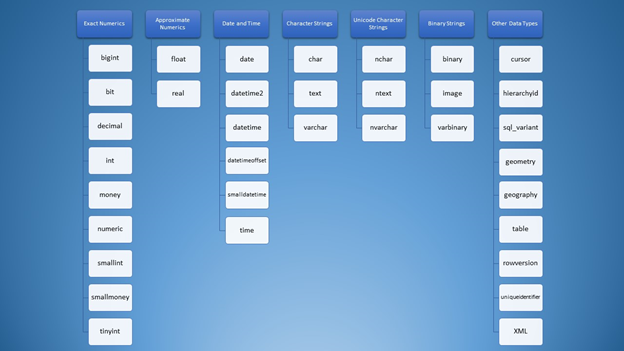
Still, for using strings, you have lots of options that can lead to the wrong usage. At first, I thought that varchar and nvarchar were just the same. Besides, they are both character string types. Using numbers is no different. As developers, we need to know which type to use in different situations.
But you may wonder, what’s the worst thing that can happen if I make the wrong choice? Let me tell you!
1. Choosing the Wrong SQL Data Types
This item will use strings and whole numbers to prove the point.
Using the Wrong Character String SQL Data Type
First, let’s go back to strings. There’s this thing called Unicode and non-Unicode strings. Both have different storage sizes. You often define this on columns and variable declarations.
The syntax is either varchar(n)/char(n) or nvarchar(n)/nchar(n) where n is the size.
Note that n is not the number of characters but the number of bytes. It’s a common misconception that happens because, in varchar, the number of characters is the same as the size in bytes. But not in nvarchar.
To prove this fact, let’s create 2 tables and put some data into them.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Now let’s check their row sizes using DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
Figure 3 shows that the difference is two-fold. Check it out below.
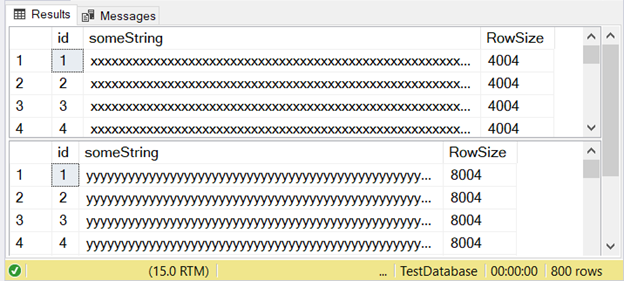
Notice the second result set with a row size of 8004. This uses the nvarchar data type. It’s also almost twice larger than the row size of the first result set. And this uses the varchar data type.
You see the implication on storage and I/O. Figure 4 shows the logical reads of the 2 queries.
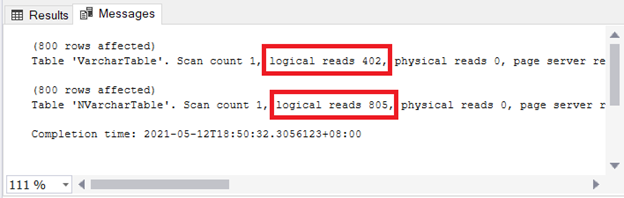
See? Logical reads are also two-fold when using nvarchar compared to varchar.
So, you cannot just interchangeably use each. If you need to store multilingual characters, use nvarchar. Otherwise, use varchar.
This means that if you use nvarchar for single-byte characters only (like English), the storage size is higher. Query performance is also slower with higher logical reads.
In SQL Server 2019 (and higher), you can store the full range of Unicode character data using varchar or char with any of the UTF-8 collation options.
Using the Wrong Numeric Data Type SQL
The same concept applies with bigint vs. int – their sizes can mean night and day. Like nvarchar and varchar, bigint is double the size of int (8 bytes for bigint and 4 bytes for int).
Still, another problem is possible. If you don’t mind their sizes, errors can happen. If you use an int column and store a number greater than 2,147,483,647, an arithmetic overflow will occur:
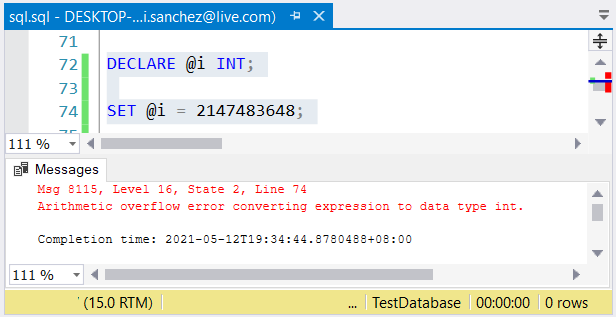
When choosing whole number types, make sure the data with the maximum value will fit. For example, you might be designing a table with historical data. You plan to use whole numbers as the primary key value. Do you think it won’t reach 2,147,483,647 rows? Then use int instead of bigint as the primary key column type.
The Worst Thing that Can Happen
Choosing the wrong data types can affect query performance or cause runtime errors. Thus, choose the data type that is right for the data.
2. Making Large Table Rows Using Big Data Types for SQL
Our next item is related to the first one, but it will expand the point even more with examples. Also, it has something to do with pages and big-sized varchar or nvarchar columns.
What’s with Pages and Row Sizes?
The concept of pages in SQL Server can be compared with the pages of a spiral notebook. Each page in a notebook has the same physical size. You write words and draw pictures on them. If a page is not enough for a set of paragraphs and pictures, you continue on the next page. Sometimes, you also tear a page and start over.
Likewise, table data, index entries, and pictures in SQL Server are stored in pages.
A page has the same size of 8 KB. If a row of data is very large, it will not fit the 8 KB page. One or more columns will be written on another page under the ROW_OVERFLOW_DATA allocation unit. It contains a pointer to the original row on the page under the IN_ROW_DATA allocation unit.
Based on this, you cannot just fit lots of columns in a table during the database design. There will be consequences on I/O. Also, if you query a lot on these row-overflow data, the execution time is slower. This can be a nightmare.
An issue arises when you max out all the varying-sized columns. Then, the data will spill to the next page under ROW_OVERFLOW_DATA. update the columns with smaller-sized data, and it needs to be removed on that page. The new smaller data row will be written on the page under IN_ROW_DATA together with the other columns. Imagine the I/O involved here.
Large Row Example
Let’s prepare our data first. We will use character string data types with big sizes.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Getting the Row Size
From the generated data, let’s inspect their row sizes based on DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
The first 300 records will fit the IN_ROW_DATA pages because each row has less than 8060 bytes or 8 KB. But the last 100 rows are too big. Check out the result set in Figure 6.
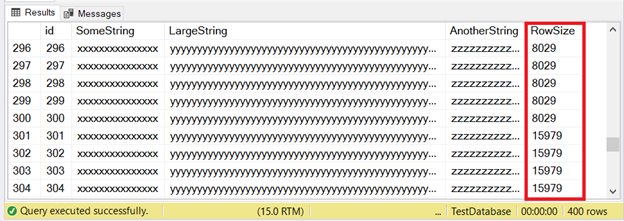
You see part of the first 300 rows. The next 100 exceed the page size limit. How do we know the last 100 rows are in the ROW_OVERFLOW_DATA allocation unit?
Inspecting the ROW_OVERFLOW_DATA
We’ll use sys.dm_db_index_physical_stats. It returns page information about table and index entries.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
The result set is in Figure 7.

There it is. Figure 7 shows 100 rows under ROW_OVERFLOW_DATA. This is consistent with Figure 6 when large rows exist starting with rows 301 to 400.
The next question is how many logical reads we get when we query these 100 rows. Let’s try.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

We see 102 logical reads and 100 lob logical reads of LargeTable. Leave these numbers for now – we’ll compare them later.
Now, let’s see what happens if we update the 100 rows with smaller data.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
This update statement used the same logical reads and lob logical reads as in Figure 8. From this, we know something bigger happened because of the lob logical reads of 100 pages.
But to be sure, let’s check it with sys.dm_db_index_physical_stats as we did earlier. Figure 9 shows the result:

Gone! Pages and rows from ROW_OVERFLOW_DATA became zero after updating 100 rows with smaller data. Now we know that the data movement from ROW_OVERFLOW_DATA to IN_ROW_DATA happens when large rows are shrunk. Imagine if this happens a lot for thousands or even millions of records. Crazy, isn’t it?
In Figure 8, we saw 100 lob logical reads. Now, see Figure 10 after re-running the query:

It became zero!
The Worst Thing that Can Happen
Slow query performance is the by-product of the row-overflow data. Consider moving the big-sized column(s) to another table to avoid it. Or, if applicable, reduce the size of the varchar or nvarchar column.
3. Blindly Using Implicit Conversion
SQL does not allow us to use data without specifying the type. But it’s forgiving if we make a wrong choice. It tries to convert the value to the type it expects, but with a penalty. This can happen in a WHERE clause or JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
The CardNumber column is not a numeric type. It’s nvarchar. So, the first SELECT will cause an implicit conversion. However, both will run just fine and produce the same result set.
Let’s check the execution plan in Figure 11.
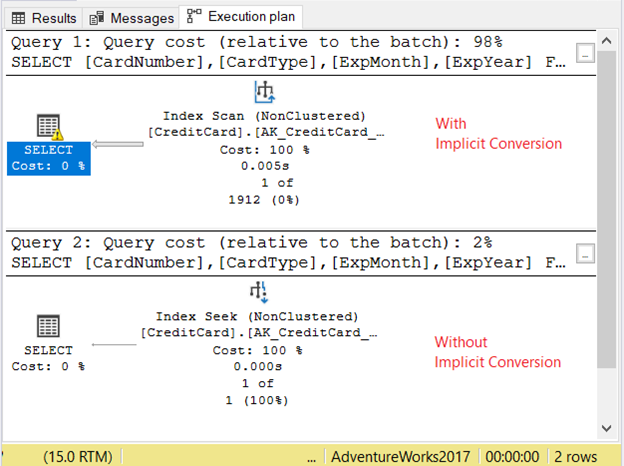
The 2 queries ran very quickly. In Figure 11, it’s zero seconds. But look at the 2 plans. The one with implicit conversion had an index scan. There’s also a warning icon and a fat arrow pointing to the SELECT operator. It tells us that it’s bad.
But it doesn’t end there. If you hover your mouse over the SELECT operator, you will see something else:
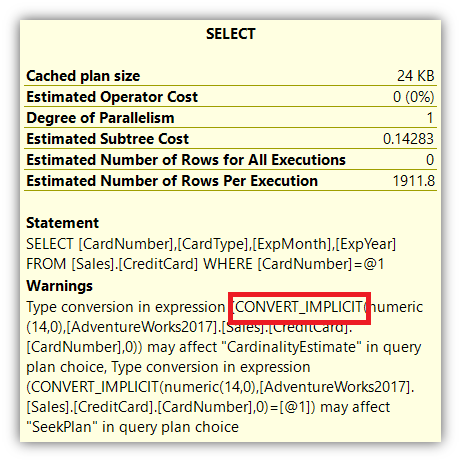
The warning icon in the SELECT operator is about the implicit conversion. But how big is the impact? Let’s check the logical reads.
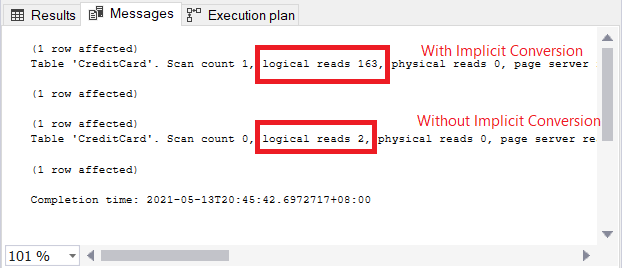
The comparison of logical reads in Figure 13 is like heaven and earth. In the query for credit card information, implicit conversion caused more than a hundred-fold of logical reads. Very bad!
The Worst Thing that Can Happen
If an implicit conversion caused high logical reads and a bad plan, expect slow query performance on large result sets. To avoid this, use the exact data type in the WHERE clause and JOINs in matching the columns you compare.
4. Using Approximate Numerics and Rounding It
Check out figure 2 again. SQL server data types belonging to approximate numerics are float and real. Columns and variables made of them store a close approximation of a numeric value. If you plan to round these numbers up or down, you might get a big surprise. I have an article that discussed this in detail here. See how 1 + 1 results in 3 and how you can deal with rounding numbers.
The Worst Thing that Can Happen
Rounding a float or real can have crazy results. If you want exact values after rounding off, use decimal or numeric instead.
5. Setting Fixed-Sized String Data Types to NULL
Let’s turn our attention to fixed-size data types like char and nchar. Aside from the padded spaces, setting them to NULL will still have a storage size equal to the size of the char column. So, setting a char(500) column to NULL will have a size of 500, not zero or 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
In the above code, data is maxed out based on the size of char and varchar columns. Checking their row size using DATALENGTH will also show the sum of the sizes of each column. Now let’s set the columns to NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Next, we query the rows using DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
What do you think will be the data sizes of each column? Check out Figure 14.
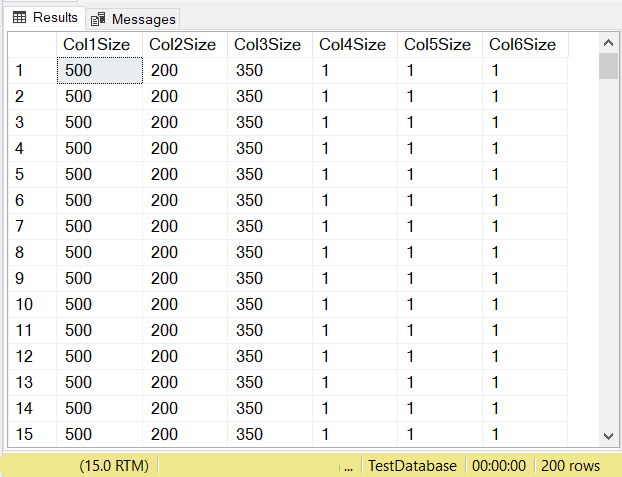
Look at the column sizes of the first 3 columns. Then compare them to the code above when the table was created. The data size of the NULL columns is equal to the size of the column. Meanwhile, the varchar columns when NULL have a data size of 1.
The Worst Thing that Can Happen
During the designing tables, nullable char columns, when set to NULL, will still have the same storage size. They will also consume the same pages and RAM. If you don’t fill the entire column with characters, consider using varchar instead.
What’s Next?
So, do your choices in SQL server data types and their sizes matter? The points presented here should be enough to make a point. So, what can you do now?
- Make time to review the database you support. Start with the easiest one if you have several on your plate. And yes, make time, not find the time. In our line of work, it’s almost impossible to find the time.
- Review the tables, stored procedures, and anything that deals with data types. Note the positive impact when identifying problems. You’re going to need it when your boss asks why you have to work on this.
- Plan to attack each of the problem areas. Follow whatever methodologies or policies your company has in dealing with the problems.
- Once the problems are gone, celebrate.
Sounds easy, but we all know it’s not. We also know that there’s a bright side at the end of the journey. That’s why they are called problems – because there’s a solution. So, cheer up.
Do you have something else to add about this topic? Let us know in the Comments section. And if this post gave you a bright idea, share it on your favorite social media platforms.
Tags: data types, sql numeric, sql strings Last modified: September 08, 2022