This post has “strings attached: for a good reason. We are going to explore deep into SQL VARCHAR, the data type that deals with strings.
Also, this is “for your eyes only” because without strings, there will be no blog posts, web pages, game instructions, bookmarked recipes, and a lot more for our eyes to read and enjoy. We deal with a gazillion strings every day. So, as developers, you and I are responsible for making this sort of data efficient to store and access.
With this in mind, we will cover what matters best for storage and performance. Enter the do’s and don’ts for this data type.
But before that, VARCHAR is just one of the string types in SQL. What makes it different?
What is VARCHAR in SQL? (With Examples)
VARCHAR is a string or character data type of varying size. You can store letters, numbers, and symbols with it. Starting with SQL Server 2019, you can use the full range of Unicode characters when using a collation with UTF-8 support.
You can declare VARCHAR columns or variables using VARCHAR[(n)], where n stands for the string size in bytes. The range of values for n is 1 to 8000. That’s a lot of character data. But even more, you can declare it using VARCHAR(MAX) if you need a gigantic string of up to 2GB. That’s big enough for your list of secrets and private stuff in your diary! However, note that you can also declare it without the size and it defaults to 1 if you do that.
Let’s have an example.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
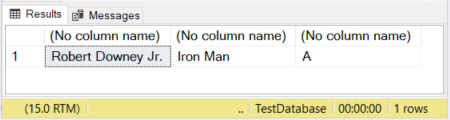
In Figure 1, the first 2 columns have their sizes defined. The third column is left without a size. So, the word “Avengers” is truncated because a VARCHAR without a size declared defaults to 1 character.
Now, let’s try something huge. But note that this query will take a while to run – 23 seconds on my laptop.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
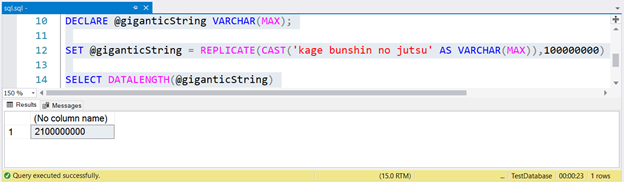
To generate a huge string, we replicated kage bunshin no jutsu 100 million times. Note the CAST within REPLICATE. If you don’t CAST the string expression to VARCHAR(MAX), the result will be truncated to up to 8000 characters only.
But how does SQL VARCHAR compare to other string data types?
Difference between CHAR and VARCHAR in SQL
Compared to VARCHAR, CHAR is a fixed-length character data type. No matter how small or big a value you put to a CHAR variable, the final size is the size of the variable. Check the comparisons below.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
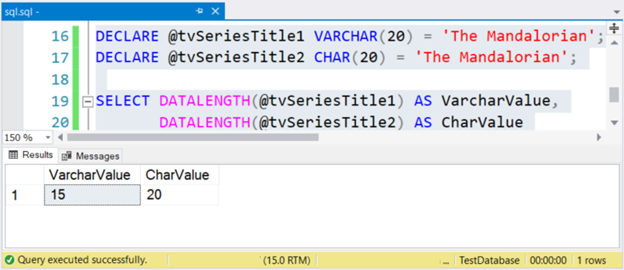
The size of the string “The Mandalorian” is 15 characters. So, the VarcharValue column correctly reflects it. However, CharValue retains the size of 20 – it is padded with 5 spaces to the right.
SQL VARCHAR vs NVARCHAR
Two basic things come to mind when comparing these data types.
First, it is the size in bytes. Each character in NVARCHAR has twice the size of VARCHAR. NVARCHAR(n) is from 1 to 4000 only.
Then, the characters it can store. NVARCHAR can store multilingual characters like Korean, Japanese, Arabic, etc. If you plan to store Korean K-Pop lyrics in your database, this data type is one of your options.
Let’s have an example. We’re going to use the K-pop group 세븐틴 or Seventeen in English.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
The above code will output the string value, its size in bytes, and the number of characters. If these are non-Unicode characters, the number of characters is equal to the size in bytes. But this is not the case. Check out Figure 4 below.
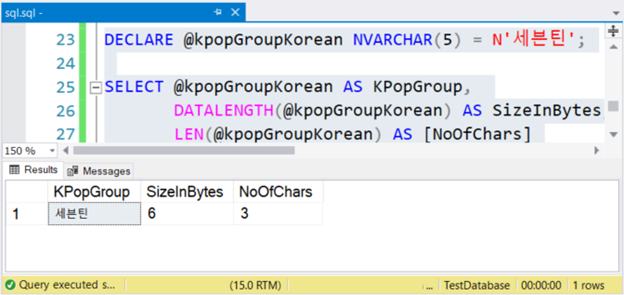
See? If NVARCHAR has 3 characters, the size in bytes is twice. But not with VARCHAR. The same is also true if you use English characters.
But how about NCHAR? NCHAR is the counterpart of CHAR for Unicode characters.
SQL Server VARCHAR with UTF-8 Support
VARCHAR with UTF-8 support is possible on a server level, database level, or table column level by changing the collation information. The collation to use should support UTF-8.
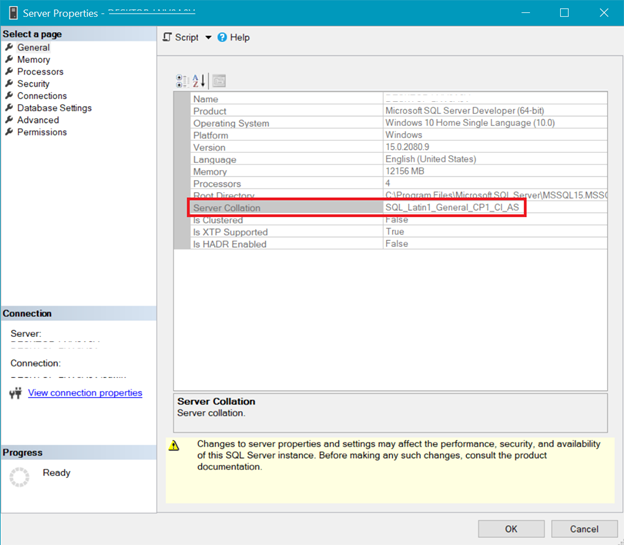
SQL SERVER COLLATION
Figure 5 presents the window in SQL Server Management Studio that shows server collation.
DATABASE COLLATION
Meanwhile, Figure 6 shows the collation of the AdventureWorks database.
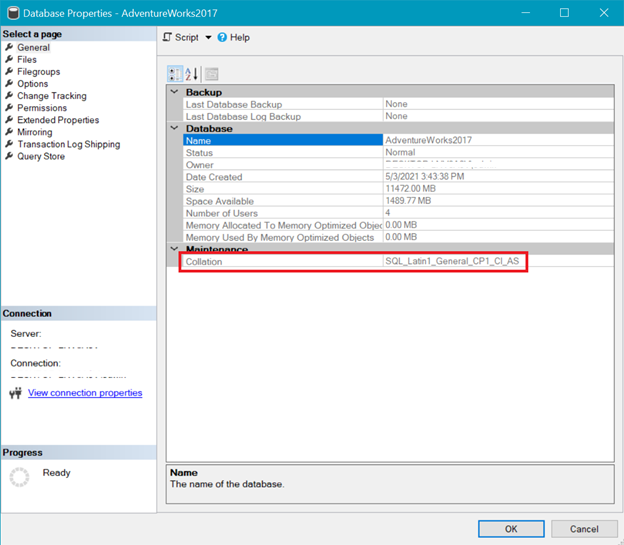
TABLE COLUMN COLLATION
Both the server and database collation above shows that UTF-8 is not supported. The collation string should have a _UTF8 in it for the UTF-8 support. But you can still use UTF-8 support at the column level of a table. See the example.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
The above code has Latin1_General_100_BIN2_UTF8 collation for the KoreanName column. Though VARCHAR and not NVARCHAR, this column will accept Korean language characters. Let’s insert some records and then view them.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
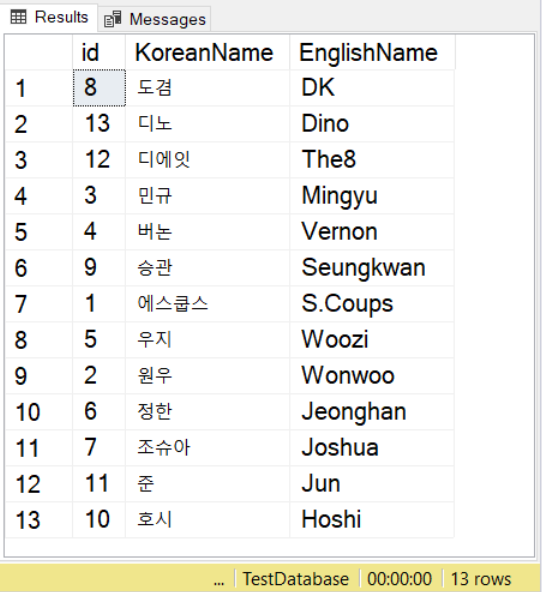
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
We’re using names from the Seventeen K-pop group using Korean and English counterparts. For Korean characters, notice that you still must prefix the value with N, just like what you do with NVARCHAR values.
Then, when using SELECT with ORDER BY, you can also use collation. You can observe this in the example above. This will follow sorting rules for the specified collation.
STORAGE OF VARCHAR WITH UTF-8 SUPPORT
But how’s the storage of these characters? If you expect 2 bytes per character then you’re in for a surprise. Check out Figure 8.
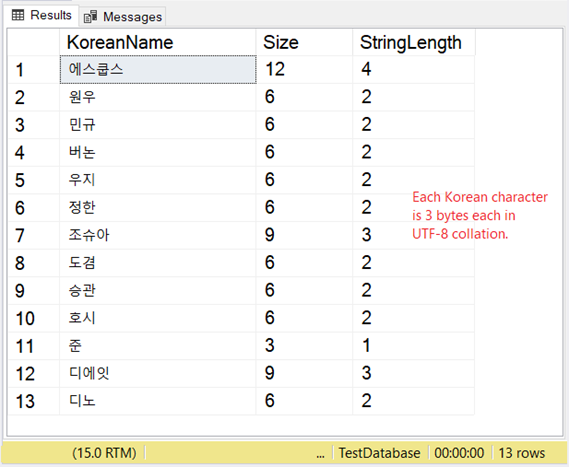
So, if storage matters a lot to you, consider the table below when using VARCHAR with the UTF-8 support.
| Characters | Size in Bytes |
| Ascii 0 – 127 | 1 |
| The Latin-based script, and Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac, Tāna, and N’Ko | 2 |
| East Asian script like Chinese, Korean, and Japanese | 3 |
| Characters in the range 010000–10FFFF | 4 |
Our Korean example is an East Asian script, so it’s 3 bytes per character.
Now that we’re done with describing and comparing VARCHAR to other string types, let’s now cover the Do’s and Don’ts
Do’s in Using VARCHAR in SQL Server
1. Specify the Size
What could go wrong without specifying the size?
STRING TRUNCATION
If you get lazy specifying the size, the string truncation will occur. You already saw an example of this earlier.
STORAGE AND PERFORMANCE IMPACT
Another consideration is storage and performance. You only need to set the right size for your data, not more. But how could you know? To avoid truncation in the future, you might just set it to the largest size. That is VARCHAR(8000) or even VARCHAR(MAX). And 2 bytes will be stored as-is. Same thing with 2GB. Does it matter?
Answering that will take us to the concept of how SQL Server stores data. I have another article explaining this in detail with examples and illustrations.
In short, data is stored in 8KB-pages. When a row of data exceeds this size, SQL Server moves it to another page allocation unit called ROW_OVERFLOW_DATA.
Suppose you have 2-byte VARCHAR data that may fit the original page allocation unit. When you store a string larger than 8000 bytes, the data will be moved to the row-overflow page. Then shrink it again to a lower size, and it will be moved back to the original page. The back-and-forth movement causes a lot of I/O and a performance bottleneck. Retrieving this from 2 pages instead of 1 needs extra I/O too.
Another reason is indexing. VARCHAR(MAX) is a big NO as an index key. Meanwhile, VARCHAR(8000) will exceed the maximum index key size. That is 1700 bytes for non-clustered indexes and 900 bytes for clustered indexes.
DATA CONVERSION IMPACT
Yet there’s another consideration: data conversion. Try it with a CAST without the size like the code below.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
This code will do a conversion of a date/time with time zone information to VARCHAR.
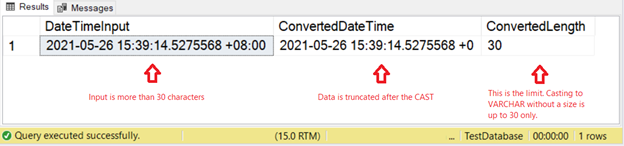
So, if we get lazy specifying the size during CAST or CONVERT, the result is limited to 30 characters only.
How about converting NVARCHAR to VARCHAR with UTF-8 support? There’s a detailed explanation of this later, so keep on reading.
2. Use VARCHAR If String Size Varies Considerably
Names from the AdventureWorks database vary in size. One of the shortest names is Min Su, while the longest name is Osarumwense Uwaifiokun Agbonile. That’s between 6 and 31 characters including the spaces. Let’s import these names into 2 tables and compare between VARCHAR and CHAR.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Which of the 2 are better? Let’s check the logical reads by using the code below and inspecting the output of STATISTICS IO.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
Logical reads:
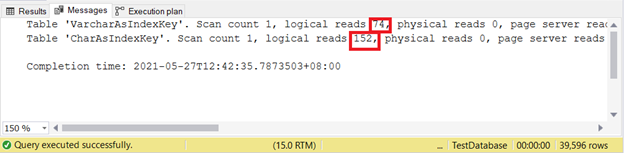
The less logical reads the better. Here, the CHAR column used more than double the VARCHAR counterpart. Thus, VARCHAR wins in this example.
3. Use VARCHAR as Index Key Instead of CHAR When Values Vary in Size
What happened when used as index keys? Will CHAR fare better than VARCHAR? Let’s use the same data from the previous section and answer this question.
We’ll query some data and check the logical reads. In this example, the filter uses the index key.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
Logical reads:
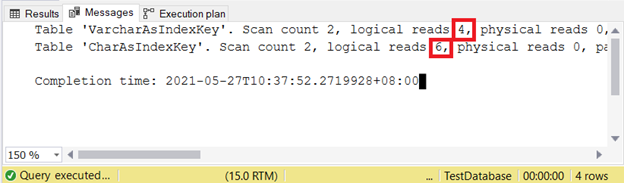
Therefore, VARCHAR index keys are better than CHAR index keys when the key has varying sizes. But how about INSERT and UPDATE that will alter the index entries?
WHEN USING INSERT AND UPDATE
Let’s test 2 cases and then check the logical reads like we usually do.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
Logical reads:
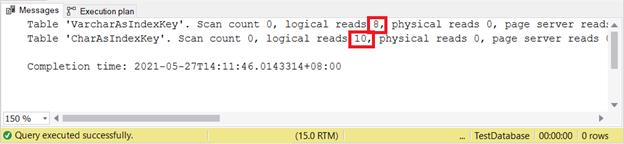
VARCHAR is still better when inserting records. How about UPDATE?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Logical reads:
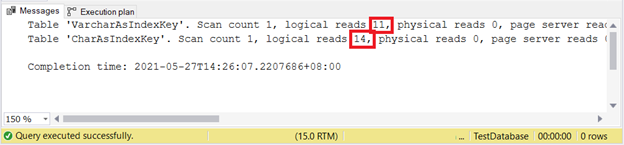
Looks like VARCHAR wins again.
Eventually, it wins our test, though it might be small. Do you have a bigger test case that proves the opposite?
4. Consider VARCHAR with UTF-8 Support for Multilingual Data (SQL Server 2019+)
If there’s a mix of Unicode and non-Unicode characters in your table, you can consider VARCHAR with UTF-8 support over NVARCHAR. If most of the characters are within the range of ASCII 0 to 127, it can offer space savings compared to NVARCHAR.
To see what I mean, let’s have a comparison.
NVARCHAR TO VARCHAR WITH UTF-8 SUPPORT
Did you already migrate your databases to SQL Server 2019? Are you planning to migrate your string data to UTF-8 collation? We’ll have an example of a mixed value of Japanese and non-Japanese characters to give you an idea.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
Now that the data is set, we’ll inspect the size in bytes of the 2 values:

Surprise! With NVARCHAR, the size is 30 bytes. That’s 15 times more than 2 characters. But when converted to VARCHAR with UTF-8 support, the size is only 27 bytes. Why 27? Check how this is computed.

Thus, 9 of the characters are 1 byte each. That’s interesting because, with NVARCHAR, English letters are also 2 bytes. The rest of the Japanese characters are 3 bytes each.
If this has been all Japanese characters, the 15-character string would be 45 bytes and also consume the maximum size of the VarcharUTF8 column. Notice that the size of the NVarcharValue column is less than VarcharUTF8.
The sizes can’t be equal when converting from NVARCHAR, or the data may not fit. You can refer to the previous Table 1.
Consider the impact on size when converting NVARCHAR to VARCHAR with UTF-8 support.
Don’ts in Using VARCHAR in SQL Server
1. When String Size is Fixed and Non-Nullable, Use CHAR Instead.
The general rule of thumb when a fixed-sized string is required is to use CHAR. I follow this when I have a data requirement that needs right-padded spaces. Otherwise, I’ll use VARCHAR. I had a few use cases when I needed to dump fixed-length strings without delimiters into a text file for a client.
Further, I use CHAR columns only if the columns will be non-nullable. Why? Because the size in bytes of CHAR columns when NULL is equal to the defined size of the column. Yet VARCHAR when NULL has a size of 1 no matter how much the defined size is. Run the code below and see it for yourself.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. Don’t Use VARCHAR(n) If n Will Exceed 8000 Bytes. Use VARCHAR(MAX) Instead.
Do you have a string that will exceed 8000 bytes? This is the time to use VARCHAR(MAX). But for the most common forms of data like names and addresses, VARCHAR(MAX) is overkill and will impact performance. In my personal experience, I do not remember a requirement that I used VARCHAR(MAX).
3. When Using Multilingual Characters with SQL Server 2017 and Below. Use NVARCHAR Instead.
This is an obvious choice if you still use SQL Server 2017 and below.
The Bottomline
The VARCHAR data type has served us well for so many aspects. It did for me since SQL Server 7. Yet sometimes, we still make poor choices. In this post, SQL VARCHAR is defined and compared to other string data types with examples. And again, here are the do’s and don’ts for a faster database:
Do’s:
- Specify the size n in VARCHAR[(n)] even if it’s optional.
- Use it when the string size varies considerably.
- Consider VARCHAR columns as index keys instead of CHAR.
- And if you’re now using SQL Server 2019, consider VARCHAR for multilingual strings with UTF-8 support.
Don’ts:
- Don’t use VARCHAR when string size is fixed and non-nullable.
- Don’t use VARCHAR(n) when string size will exceed 8000 bytes.
- And do not use VARCHAR for multilingual data when using SQL Server 2017 and earlier.
Do you have something else to add? Let us know in the Comments section. If you think this will help your developer friends, then please share this on your favorite social media platforms.
Tags: data types, varchar Last modified: February 21, 2022