Table indexing strategy is one of the most important performance tuning and optimization keys. In SQL Server, the indexes (both, clustered and nonclustered) are created using a B-tree structure, in which each page acts as a doubly linked list node, having an information about the previous and the next pages. This B-tree structure, called Forward Scan, makes it easier to read the rows from the index by scanning or seeking its pages from the beginning to the end. Although the forward scan is the default and heavily known index scanning method, SQL Server provides us with the ability to scan the index rows within the B-tree structure from the end to the beginning. This ability is called the Backward Scan. In this article, we will see how this happens and what are the pros and cons of the Backward scanning method.
SQL Server provides us with the ability to read data from the table index by scanning the index B-tree structure nodes from the beginning to the end using the Forward Scan method, or reading the B tree structure nodes from the end to the beginning using the Backward Scan method. As the name indicates, the Backward scan is performed while reading opposite to the order of the column included in the index, which is performed with the DESC option in the ORDER BY T-SQL sorting statement, that specifies the direction of the scan operation.
In specific situations, SQL Server Engine finds that reading of the index data from the end to the beginning with the Backward scan method is faster than reading it in its normal order with the Forward scan method, that may require an expensive sorting process by the SQL Engine. Such cases include the usage of the MAX() aggregate function and situations when sorting of the query result is opposite of the index order. The main drawback of the Backward scan method is that the SQL Server Query Optimizer will always choose to execute it using serial plan execution, without being able to take benefits from the parallel execution plans.
Assume we have the following table that will contain information about the company employees. The table can be created using the CREATE TABLE T-SQL statement below:
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
After creating the table, we will fill it with 10K dummy records, using the INSERT statement below:
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000
If we execute the below SELECT statement to retrieve data from the previously created table, the rows will be sorted according to the ID column values in ascending order, that is the same as the clustered index order:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
Then checking the execution plan for that query, a scan will be performed on the clustered index to get the sorted data from the index as shown in the execution plan below:

To get the direction of the scan that is performed on the clustered index, right-click the index scan node to browse the node properties. From the Clustered Index Scan node properties, the Scan Direction property will display the direction of the scan that is performed on the index within that query, which is Forward Scan as shown in the snapshot below:
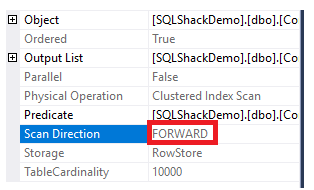
The index scanning direction can be also retrieved from the XML execution plan from the ScanDirection property under the IndexScan node, as shown below:

Assume that we need to retrieve the maximum ID value from the CompanyEmployees table created previously, using the T-SQL query below:
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
Then review the execution plan that is generated from executing that query. You will see that a scan will be performed on the clustered index as shown in the execution plan below:

To check the direction of the index scan, we will browse the properties of the Clustered Index Scan node. The result will show us that, the SQL Server Engine prefers to scan the clustered index from the end to the beginning, which will be faster in this case, in order to get the maximum value of the ID column, due to the fact that the index is already sorted according to the ID column, as shown below:
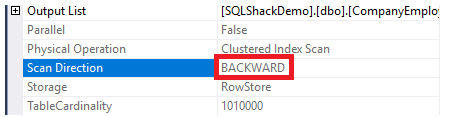
Also, if we try to retrieve the previously created table data using the following SELECT statement, the records will be sorted according to the ID column values, but this time, opposite to the clustered index order, by specifying the DESC sorting option in the ORDER BY clause shown below:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
If you check the execution plan generated after execution the previous SELECT query, you will see that a scan will be performed on the clustered index in order to get the requested records of the table, as shown below:
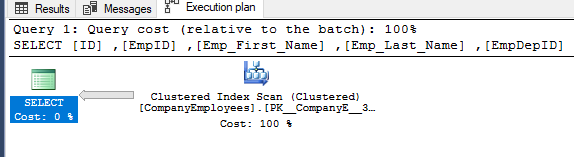
The Clustered Index Scan node properties will show that the direction of the scan that the SQL Server Engine prefers to take is the Backward Scan direction, which is faster in this case, due to sorting the data opposite to the real sorting of the clustered index, taking into consideration that the index is already sorted in ascending order according to the ID column, as shown below:
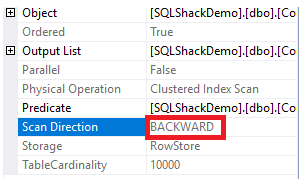
Performance Comparison
Assume that we have the below SELECT statements that retrieve information about all employees that have been hired starting from 2010, two times; the first time the returned result set will be sorted in ascending order according to the ID column values, and the second time the returned result set will be sorted in descending order according to the ID column values using the T-SQL statements below:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
Checking the execution plans that are generated by executing the two SELECT queries, the result will show that a scan will be performed on the clustered index in the two queries to retrieve the data, but the direction of the scan in the first query will be Forward Scan due to the ASC data sorting, and Backward Scan in the second query due to using the DESC data sorting, to replace the need to reorder the data again, as shown below:
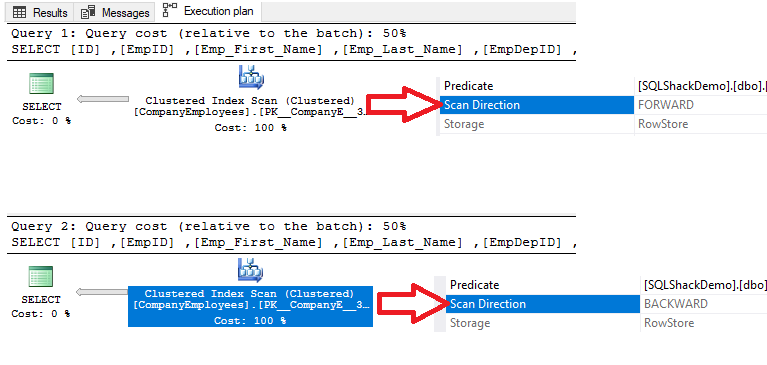
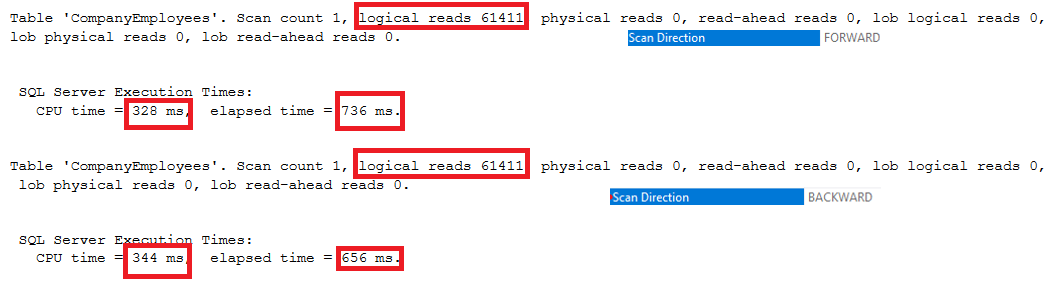
Also, if we check the IO and TIME execution statistics of the two queries, we will see that both queries perform the same IO operations and consume near values of the execution and CPU time.
These values show us how smart the SQL Server Engine is when choosing the most suitable and fastest index scanning direction to retrieve data for the user, which is Forward Scan in the first case and Backward Scan in the second case, as clear from the statistics below:
Let us visit the previous MAX example again. Assume that we need to retrieve the maximum ID of the employees that have been hired in 2010 and later. For this, we will use the following SELECT statements that will sort the read data according to the ID column value with the ASC sorting in the first query and with the DESC sorting in the second query:
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
You will see from the execution plans generated from execution of the two SELECT statements, that both queries will perform a scan operation on the clustered index to retrieve the maximum ID value, but in different scanning directions; Forward Scan in the first query and Backward Scan in the second query, due to the ASC and DESC sorting options, as shown below:
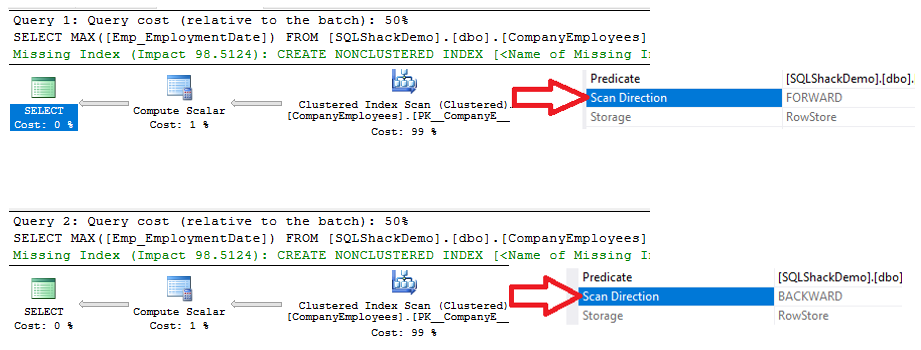
The IO statistics generated by the two queries will show no difference between the two scanning directions. But the TIME statistics show a big difference between calculating the maximum ID of the rows when these rows are scanned from the beginning to the end using the Forward Scan method and scanning it from the end to the beginning using the Backward Scan method. It is clear from the below result that the Backward Scan method is the optimal scanning method to get the maximum ID value:

Performance Optimization
As I mentioned at the beginning of this article, query indexing is the most important key in the performance tuning and optimization process. In the previous query, if we arrange to add a non-clustered index on the EmploymentDate column of the CompanyEmployees table, using the CREATE INDEX T-SQL statement below:
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Checking the execution plans generated after execution of the two queries, you will see that a seek will be performed on the newly created nonclustered index, and both queries will scan the index from the beginning to the end using the Forward Scan method, without the need to perform a Backward Scan to speed up the data retrieval, although we used the DESC sorting option in the second query. This occurred due to seeking the index directly without the need to perform a full index scan, as shown in the execution plans comparison below:

The same result can be derived from the IO and TIME statistics generated from the previous two queries, where the two queries will consume the same amount of execution time, CPU and IO operations, with a very small difference, as shown in the statistics snapshot below:

Useful Links:
- Clustered and Nonclustered Indexes Described
- Create Nonclustered Indexes
- SQL Server Performance Tuning: Backward Scanning of an Index
Useful tool:
dbForge Index Manager – handy SSMS add-in for analyzing the status of SQL indexes and fixing issues with index fragmentation.
Tags: execution plan, indexes, performance, sql server Last modified: September 22, 2021





