In the last few years, JSON has positioned itself as a standard data exchange format between services, although XML is still widely used. In the SQL Server 2016, Microsoft implemented JSON support directly in the database engine, and the capabilities of data manipulation are increasing in each following version.
The word comes as an abbreviation from JavaScript Object Notation, and it represents an open-standard format in a form of human-readable key-value pairs; it is language-independent. It is often used in application configurations, RESTful web services, and NoSQL databases like CouchDB and MongoDB.
Popular development languages, including JavaScript, natively support generation and consumption of JSON without serialization, which gives it flexibility while keeping self-description without the need for schema, which is a requirement in XML.
Table of Contents
- Decoding JSON: What It Is and Why You Need It
- How to Retrieve SQL Server Data in JSON Format
- How to Convert Tabular Data to JSON in SQL Server
- JSON Data Validation: Best Practices and Methods for SQL Server
- How to Update JSON Data in SQL Server
- Example 1: update the JSON property value
- Example 2: Check values before and after the update
- Example 3: Add a new property to the JSON string
- Example 4: Remove the existing JSON property
- Example 5: Rename a key
- Optimizing JSON Storage in SQL Server: Challenges and Workarounds
- Conclusion
Decoding JSON: What It Is and Why You Need It
JSON text content is a sequence of tokens containing code points that conform to the JSON value grammar. Values can be either primitive (strings, numbers, booleans, or nulls) or complex (objects or arrays).
A JSON object is defined as a collection of “zero or more” key-value pairs named object members that are written in paired braces. Keys and values are separated with a single colon, and objects are separated by a comma. The key is a string, and the value can be any primitive or complex data type. A JSON array is an ordered list of zero or more values separated by commas and surrounded by square brackets.
Since JSON is designed to be as lightweight as possible, it supports only four primitive data types – numbers (double-precision float), string (Unicode text surrounded by double-quotes), true/false (boolean values that must be written in lowercase), and nulls. There is no dedicated “date” type – they are represented as strings. In JSON, strings are sequences wrapped with quotation marks, and all characters must be placed within them, except for escaped characters.

How to Retrieve SQL Server Data in JSON Format
When we start working with JSON in SQL Server, we usually first have to retrieve tabular data in this format. Microsoft first implemented a FOR JSON clause in SQL Server 2017 – this clause can be natively used with the SELECT statement, similarly to FOR XML that we use for retrieving data in XML format.
FOR JSON allows for two methods to select from:
- FOR JSON AUTO – output will be formatted according to the SELECT statement structure
- FOR JSON PATH – output will be formatted according to the user-defined structure, allowing you to use nested objects and properties
Whichever model you choose, SQL Server will extract relational data in SELECT statements. It will automatically convert the database data types to JSON types and implement character escape rules. Finally, it will format the output according to explicitly or implicitly defined formatting rules.
With FOR JSON AUTO, the output format is controlled by the design of the SELECT statement. Thus, using this mode requires a database table or view.
USE AdventureWorks2019
GO
SELECT GETDATE() FOR JSON AUTO
We get the following error message:
Msg 13600, Level 16, State 1, Line 4
FOR JSON AUTO requires at least one table for generating JSON objects. Use FOR JSON PATH or add a FROM clause with a table name.
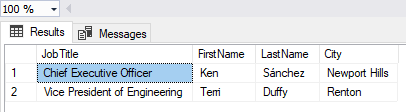
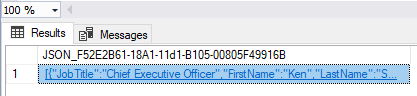
Now we show how SQL Server automatically generates JSON data. First, it is as output in Management Studio, and then formatted in a text editor:
USE AdventureWorks2019
GO
SELECT TOP(2) JobTitle, FirstName, LastName, City
FROM HumanResources.vEmployee
FOR JSON AUTO
[
{
"JobTitle": "Chief Executive Officer",
"FirstName": "Ken",
"LastName": "Sánchez",
"City": "Newport Hills"
},
{
"JobTitle": "Vice President of Engineering",
"FirstName": "Terri",
"LastName": "Duffy",
"City": "Renton"
}
]
Each row in the original result set is created as a flat property structure. If you compare this to standard XML, you will see much less text. It is because the table names do not appear in the JSON output.
The difference in size becomes important when you start to use the ELEMENTS option in XML instead of the default RAW value. To demonstrate this, we use the SELECT statement that compares the data length in bytes of XML and JSON output:
USE AdventureWorks2019
GO
SELECT DATALENGTH( CAST
(( SELECT *
FROM HumanResources.vEmployee FOR XML AUTO
) AS NVARCHAR(MAX))) AS XML_SIZE_RAW
, DATALENGTH( CAST
(( SELECT *
FROM HumanResources.vEmployee FOR XML AUTO, ELEMENTS
) AS NVARCHAR(MAX))) AS XML_SIZE_ELEMENTS
, DATALENGTH( CAST (( SELECT *
FROM HumanResources.vEmployee FOR JSON AUTO
) AS NVARCHAR(MAX))) AS JSON_SIZE
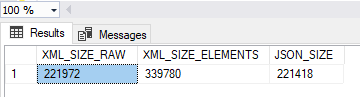
As we can see from the query results, XML element size is around 65% bigger than JSON size. On the other hand, when expressed as XML attributes, JSON and XML are about the same.
The output of using FOR JSON AUTO is a flat structure with single-level properties. If this is not sufficient for your needs, you need to use the FOR JSON PATH extension.
FOR JSON PATH allows you to keep complete control of the JSON output by creating wrapper objects and using complex properties. The final result is presented as a JSON objects array. This extension will use the alias/column name to define the key name in the output. If an alias contains dots, it will create a nested object.
Extending the previous example, we want to present FirstName and LastName columns as nested properties of the new PersonName column. We do it by adding an alias to do the columns that we nest and use dot syntax to get the proper output:
USE AdventureWorks2019
GO
SELECT TOP(2) JobTitle, City,
FirstName AS 'PersonName.FirstName', LastName AS 'PersonName.LastName'
FROM HumanResources.vEmployee
FOR JSON PATH
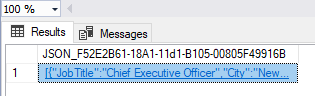
[
{
"JobTitle": "Chief Executive Officer",
"City": "Newport Hills",
"PersonName": {
"FirstName": "Ken",
"LastName": "Sánchez"
}
},
{
"JobTitle": "Vice President of Engineering",
"City": "Renton",
"PersonName": {
"FirstName": "Terri",
"LastName": "Duffy"
}
}
]
If we do not change default settings, the NULL values won’t be included in the results. If your statement joins multiple tables in one query, the output will be a flat list where FOR JSON PATH nests each column according to the defined column alias.
FOR JSON PATH extensions don’t need databases table, as we can in the following example:
SELECT GETDATE() AS TadayDate FOR JSON PATH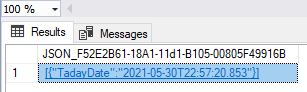
How to Convert Tabular Data to JSON in SQL Server
To use JSON with relational data or work with tables, you need to map this data with JSON and import it into the database tables.
If you are using SQL Server 2016 or later, you can use the OPENJSON function. This is a new rowset table-valued function added to the database engine. It returns an object that can be used as a view or table.
It converts JSON objects/properties pairs to rows/columns combinations, accepting two input parameters: Expression (UNICODE-based JSON text) and Path (JSON path expression, optional argument, used to specify a fragment of input expression).
If your database is not at a compatibility level of 130 or more, you will get the following exception when trying to use the OPENJSON function:
Msg 208, Level 16, State 1, Line 78
Invalid object name ‘OPENJSON’.
If you do not specify the schema for returned results, it will create a table containing three columns:
- Key (name of property or index of element, column type is NOT NULL VARCHAR(4000));
- Value (value of property or index of element, column type is NOT NULL NVARCHAR(MAX));
- Type (JSON data type of value, column type is TINYINT).
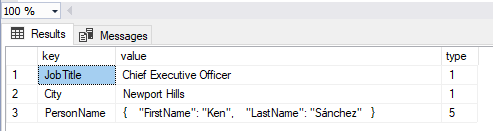
OPENJSON will return one table, where first-level properties will be rows, and each row will be one JSON property or array element. To demonstrate this, we will use sample JSON data and provide it as a string to see the output:
DECLARE @JSON NVARCHAR(MAX) = N'
{
"JobTitle": "Chief Executive Officer",
"City": "Newport Hills",
"PersonName": {
"FirstName": "Ken",
"LastName": "Sánchez"
}
}';
SELECT * FROM OPENJSON(@JSON)
If the input data is in the incorrect format, the following error will be displayed:
DECLARE @JSON NVARCHAR(MAX) = N'
{
"JobTitle": "Chief Executive Officer",
"City": "Newport Hills",
“SOMETHING_WRONG”,
"PersonName": {
"FirstName": "Ken",
"LastName": "Sánchez"
}
}';
SELECT * FROM OPENJSON(@JSON)

In this example, we returned only first-level properties. If we wish to return complex values of JSON documents (objects and arrays), we need to specify a path argument. See the next example with returning the PersonName element:
DECLARE @JSON NVARCHAR(MAX) = N'
{
"JobTitle": "Chief Executive Officer",
"City": "Newport Hills",
"PersonName": {
"FirstName": "Ken",
"LastName": "Sánchez"
}
}';
SELECT * FROM OPENJSON(@JSON, '$.PersonName')
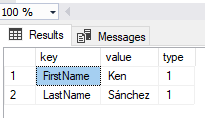
Again, if JSON is not properly formatted, the SQL Server engine will throw an exception. Let’s make an intended mistake in the same JSON text – we’ll omit one quotation sign next to FirstName:
DECLARE @JSON NVARCHAR(MAX) = N'
{
"JobTitle": "Chief Executive Officer",
"City": "Newport Hills",
"PersonName": {
FirstName: "Ken",
"LastName": "Sánchez"
}
}';
SELECT * FROM OPENJSON(@JSON, '$.PersonName')

A frequent problem is loading data in a comma-separated-value format, and we can use OPENJSON to help us with this:
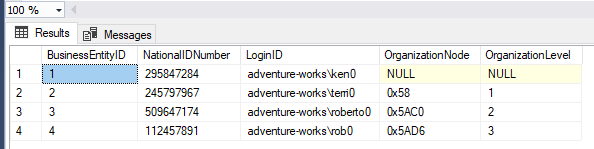
USE AdventureWorks2019
DECLARE @NationalIDNumberIDs AS VARCHAR(100) = '295847284,245797967';
SELECT [BusinessEntityID]
,[NationalIDNumber]
,[LoginID]
,[OrganizationNode]
,[OrganizationLevel]
FROM [HumanResources].[Employee] Emp
INNER JOIN ( SELECT value FROM OPENJSON('[' + @NationalIDNumberIDs + ']') )
AS JSONTbl ON Emp.NationalIDNumber = JSONTbl.value;
There is an easier way to work with the JSON code – modern technologies brought us numerous tools. For instance, the dbForge SQL Complete allows you to add this plugin to SSMS and then view the JSON code directly in a dedicated Data Viewer window.
JSON Data Validation: Best Practices and Methods for SQL Server
If you wish to validate a JSON string, you can use a built-in function ISJSON, which takes one string parameter, any type except TEXT or NTEXT, and returns 0 or 1, depending on the input parameter validity. The example is below:
SELECT
ISJSON ('JSON_test'),
ISJSON ('{}'), -- Correct
ISJSON (''),
ISJSON ('{JSON_test}'),
ISJSON ('{"item"}'),
ISJSON ('{"item":"10}'),
ISJSON ('{"item":10}'); -- Correct
It is important to note that this function does not check whether the keys of the same level are unique, you have to check this in your code:
SELECT ISJSON ('{"item":"10", "item":"test"}') AS JSON_TEXT
As we are using text columns to store data types, one way to test the validity of JSON data is to create a table with a CHECK constraint that would use the ISJSON function to validate the input before data is saved to the table.
How to Update JSON Data in SQL Server
You might want to update a part of the JSON data stored in the SQL Server column. SQL Server 2016 brings a JSON_MODIFY function that can be used to update the value of a single property, add an element to an array, insert a new property/value pair or delete property based on the given values. The function has three mandatory inputs – expression (column containing JSON text), path (JSON path expression), and new_value (new value for element specified in “path” parameter). The function returns updated JSON text. Using multiple examples, we demonstrate how to use this function.
Example 1: update the JSON property value
We update the JSON property value – update the product value in the existing JSON file. The first argument contains the original text, the second property path we are updating and the third is a new value:
SELECT JSON_MODIFY('{"Class":"","Method":"TEST_METHD"}', '$.Method', 'TEST_METHOD') AS 'JSON';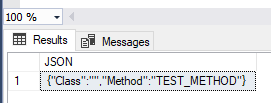
Example 2: Check values before and after the update
We want to see values before and after the update, for logging or comparison reasons. We use the following query, declaring a variable and storing JSON text in it, while later we use JSON_MODIFY() function to get updated JSON:
DECLARE @OriginalJSON NVARCHAR(4000), @newvalue varchar(30),@path varchar(20)
Set @OriginalJSON='{"Class":"C#","Method":"TEST_METHD"}'
Set @newvalue='TEST_METHOD'
set @path='$.Method'
Select
@OriginalJSON as 'Before Update',
JSON_MODIFY(@OriginalJSON,@path, @newvalue) AS 'Updated JSON';
Example 3: Add a new property to the JSON string
To do this, we specify a new property and its value. JSON_MODIFY() function, in its default behavior, inserts this property since it doesn’t exist in the original JSON text:
DECLARE @OriginalJSON NVARCHAR(4000)
Set @OriginalJSON='{"Class":"C#","Method":"TEST_METHD"}'
Select
@OriginalJSON as 'Before Update',
JSON_MODIFY(@OriginalJSON,'$.ScreenSize',17) AS 'Updated JSON';
If we do not wish to use default behavior, we can use strict mode. In this case, JSON_MODIFY() will throw an exception if the property doesn’t exist in JSON text:
DECLARE @OriginalJSON NVARCHAR(4000)
Set @OriginalJSON='{"Class":"C#","Method":"TEST_METHD"}'
Select
@OriginalJSON as 'Before Update',
JSON_MODIFY(@OriginalJSON,'strict$.ScreenSize',17) AS 'Updated JSON';
Example 4: Remove the existing JSON property
To remove nodes or properties, we need to pass the NULL value as the third argument:
DECLARE @OriginalJSON NVARCHAR(4000), @newjson VARCHAR(100);
SET @OriginalJSON = '{"Class":"C#","Class":"MTHD","Properties":["Inp","Out","Oth"]}';
SELECT @OriginalJSON AS 'Before Update',
JSON_MODIFY(@OriginalJSON, '$.Properties[0]', NULL) AS 'Updated JSON';
When we execute the above code, it replaces the array element with NULL. This is probably not what we wanted. One way to do it is to replace array values with new values, so we eliminate NULL values from the output.
DECLARE @OriginalJSON NVARCHAR(4000), @newjson VARCHAR(100);
SET @OriginalJSON = '{"Class":"C#","Class":"MTHD","Properties":["Inp","Out","Oth"]}';
set @newjson='["Inp2","Out2"]'
SELECT @OriginalJSON AS 'Before Update',
JSON_MODIFY(@OriginalJSON, '$.Properties', JSON_Query(@newjson)) AS 'Updated JSON';
Example 5: Rename a key
We do it in the same way as renaming existing columns in the database. We use nested JSON_MODIFY() functions combined with the JSON_VALUE function, creating a new key and dropping the existing key after copying its value to the new key.
DECLARE @OriginalJSON NVARCHAR(4000)
SET @OriginalJSON = '{"Class":"C#","Class":"Method"}';
SELECT @OriginalJSON AS 'Before Update',
JSON_MODIFY(
JSON_MODIFY(@OriginalJSON, '$.OptionalClass', JSON_VALUE(@OriginalJSON,'$.Class')),
'$.Class',NULL);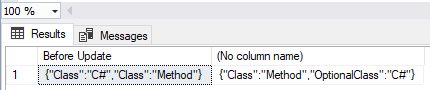
These examples show basic JSON data manipulation options.
Optimizing JSON Storage in SQL Server: Challenges and Workarounds
Unlike XML, JSON is stored in text columns. While we can store XML as BLOB objects and use customized indexes on those columns, JSON data is stored as a simple UNICODE text and needs interpretation to be processed. It could impact performance in reading and writing large JSON documents. One option to mitigate this problem, on JSON columns that are smaller than 1700 bytes, is to create a non-clustered index on them or use them as included columns (in that case, the limit does not apply). Until SQL Server delivers a dedicated data format, performance improvements are limited. You could create computed columns and index them, or use full-text indexes, but with an increase in JSON document size, performance will degrade.
Let’s start with an example of the index on computed columns. First, we create a sample table and populate it with some data and then analyze performance using execution plans.
Initial table creation and data load (using AdventureWorks2019 database):
DROP TABLE IF EXISTS dbo.JSON_PERF;
CREATE TABLE dbo.JSON_PERF
(
PK_ID NVARCHAR(1000) PRIMARY KEY,
JSON_DATA NVARCHAR(4000) NOT NULL
);
INSERT INTO dbo.JSON_PERF( PK_ID, JSON_DATA )
SELECT LoginID,
( SELECT EInner.LoginID, EInner.HireDate
FROM HumanResources.Employee EInner
WHERE EInner.LoginID = EOuter.LoginID FOR JSON AUTO
)
FROM HumanResources.Employee EOuter;
DROP TABLE IF EXISTS dbo.JSON_PERF;Now we try a simple SELECT statement:
SELECT * FROM dbo.JSON_PERF
WHERE JSON_VALUE(JSON_DATA, '$.HireDate') = '2009-02-08'
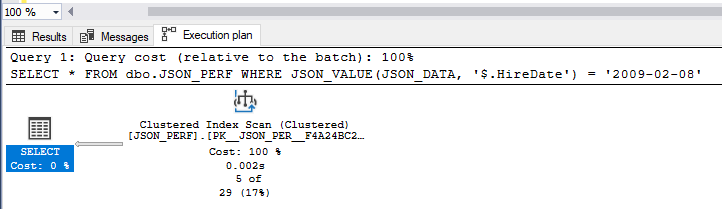
The above plan shows that a clustered index was performed since SQL Server was unable to lookup full strings in the JSON column efficiently. To improve this, we will use a computed column with the same expression and then use a dedicated non-clustered index on this column:
ALTER TABLE dbo.JSON_PERF
ADD COMPUT_COL AS JSON_VALUE(JSON_DATA, '$.HireDate');
CREATE INDEX IDX_1 ON dbo.JSON_PERF(COMPUT_COL);
SELECT * FROM dbo.JSON_PERF
WHERE JSON_VALUE(JSON_DATA, '$.HireDate') = '2009-02-08';This approach will work only for this attribute (in this case, “HireDate”), for others you need to create additional computed columns and indexes. An important thing to note with JSON indexes is that they are collation-aware, meaning that the result of the value function is a text value that inherits collation from the input variable. This also implies that values in the index will be sorted using collation rules as defined in source columns.
Conclusion
In this comprehensive guide, we’ve journeyed through the landscape of JSON, from its basic building blocks to its advanced integration with SQL Server. We’ve demonstrated key concepts with practical examples, showing you how to execute common operations like parsing, validating, and modifying data. While JSON support in SQL Server may not be as robust as that for XML, it has seen significant improvements with each new version and is highly capable for most real-world applications. However, there’s room for growth; the introduction of a JSON native data type in future SQL Server versions could offer performance optimization through indexing on JSON columns. As we’ve discussed best practices for performance, we’ve also acknowledged the limitations of the current implementation. Armed with this knowledge, we hope you’re excited to leverage JSON in your upcoming projects.
Tags: data formatting, json Last modified: September 04, 2023