
As SQL Server DBAs, we’ve heard that index structures can dramatically improve the performance of any given query (or set of queries). Still, there are certain details that many DBAs overlook, like the following:
- Index structures can become fragmented, potentially leading to performance degradation issues.
- Once an index structure has been deployed for a database table, SQL Server updates it whenever write operations take place for that table. This happens if the columns that conform to the index are affected.
- There’s metadata inside SQL Server that can be used to know when the statistics for a particular index structure were updated (if ever) for the last time. Insufficient or outdated statistics can impact the performance of certain queries.
- There’s metadata inside SQL Server that can be used to know how much an index structure has been either consumed by read operations, or updated by write operations by SQL Server itself. This information could be useful to know if there are indexes whose write volume vastly exceeds the read one. It can potentially be an index structure that is not that useful to keep around.*
It’s very important to keep in mind that the system view that holds this particular metadata gets wiped every time the SQL Server instance is restarted, so it won’t be information from its conception.
Due to the importance of these details, I have created a Stored Procedure to keep track of information regarding index structures in his/her environment, to act as proactively as possible.
Primary Considerations for Index Viewing in SQL Server
- Make sure that the account executing this Stored Procedure has enough privileges. You could probably start with the sysadmin ones and then go as granular as possible to make sure the user has the minimum of privileges required for the SP to work properly.
- The database objects (database table and stored procedure) will be created inside the database selected at the time that the script is executed, so choose carefully.
- The script is crafted in a way that it can be executed multiple times without getting an error thrown. For the Stored Procedure, I used the CREATE OR ALTER PROCEDURE statement, available since SQL Server 2016 SP1.
- Feel free to change the name of the created database objects if you’d like to use a different naming convention.
- When you choose to persist data returned by the Stored Procedure, the target table will be first truncated so only the most recent result set will be stored. You can make the necessary adjustments if you want this to behave differently, for whatever reason (to keep historical information perhaps?).
How to Use the Stored Procedure?
- Copy & paste the T-SQL Code (available within this article).
- The SP expects 2 parameters:
- @persistData: ‘Y’ if the DBA desires to save the output in a target table, and ‘N’ if the DBA only wants to see the output directly.
- @db: ‘all’ to get the information for all the databases (system & user), ‘user’ to target user databases, ‘system’ to target only system databases (excluding tempdb), and lastly the actual name of a particular database.
Fields Presented and Their Meaning
- dbName: the name of the database where the index object resides.
- schemaName: the name of the schema where the index object resides.
- tableName: the name of the table where the index object resides.
- indexName: the name of the index structure.
- type: the type of index (e.g. Clustered, Non-Clustered).
- allocation_unit_type: specifies the type of data referring to (e.g. in-row data, lob data).
- fragmentation: the amount of fragmentation (in %) that the index structure currently has.
- pages: the number of 8KB pages that form the index structure.
- writes: the number of writes that the index structure has experienced since the SQL Server instance was last restarted.
- reads: the number of reads that the index structure has experienced since the SQL Server instance was last restarted.
- disabled: 1 if the index structure is currently disabled or 0 if the structure is enabled.
- stats_timestamp: the timestamp value of when the statistics for the particular index structure were last updated (NULL if never).
- data_collection_timestamp: visible only if ‘Y’ is passed to the @persistData parameter, and it is used to know when the SP was executed and the information was successfully saved in the DBA_Indexes table.
How to Show List of Indexes in SQL Server
I will demonstrate a few executions of the Stored Procedure so that you can get an idea of what to expect from it. You can find the complete T-SQL code of the script in the tail of this article, so make sure to execute it before moving along with the following section.
The result set will be too wide to fit nicely in 1 screenshot, so I will share all the necessary screenshots to present the complete information.
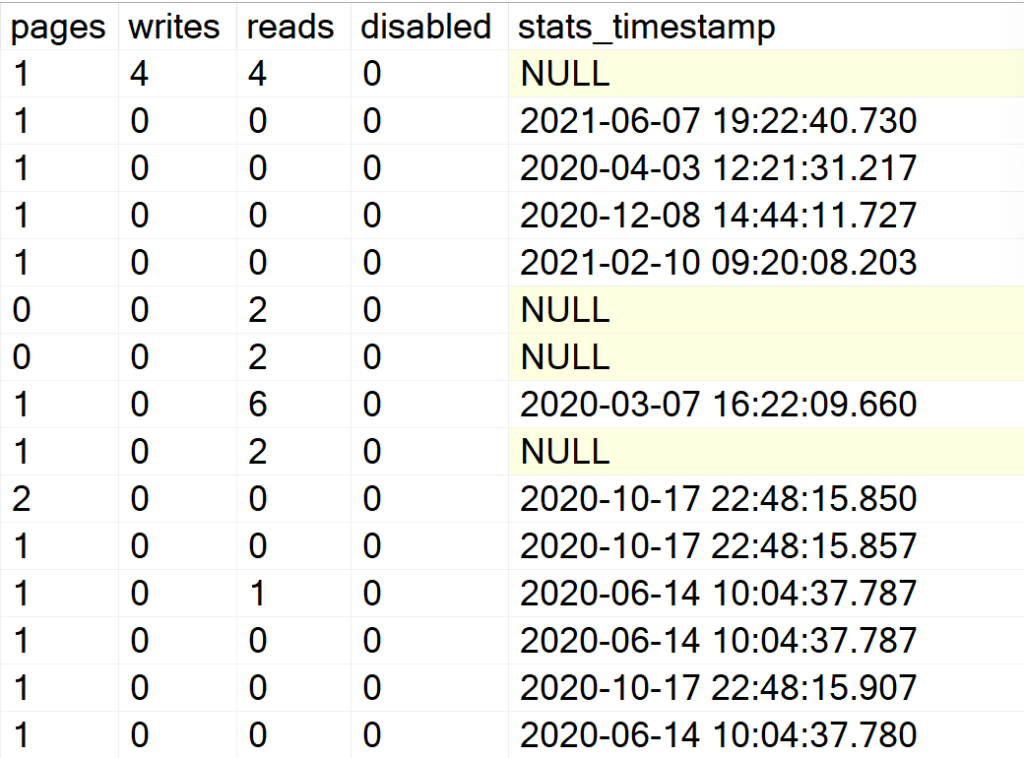
Display all the indexes information for all system & user databases
EXEC GetIndexData @persistData = 'N',@db = 'all'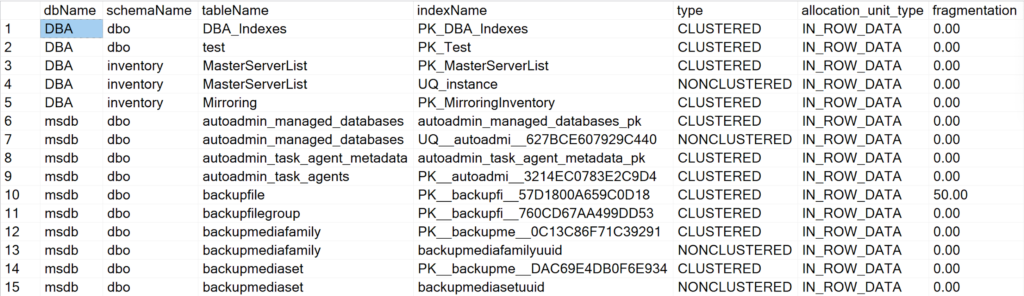
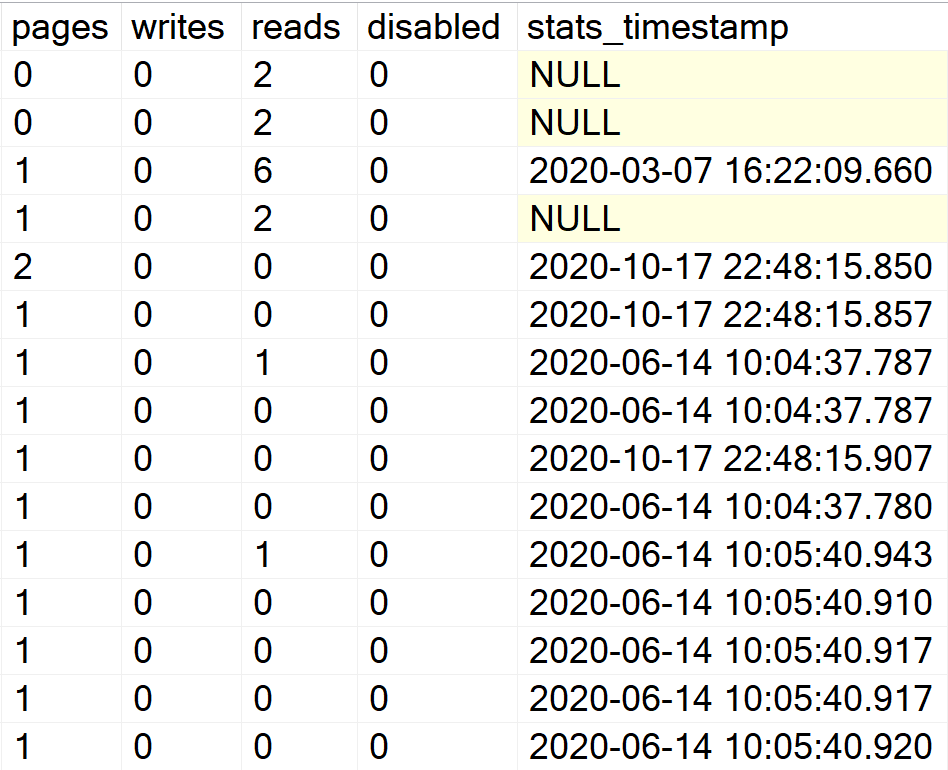
Display all the indexes information for all system databases
EXEC GetIndexData @persistData = 'N',@db = 'system'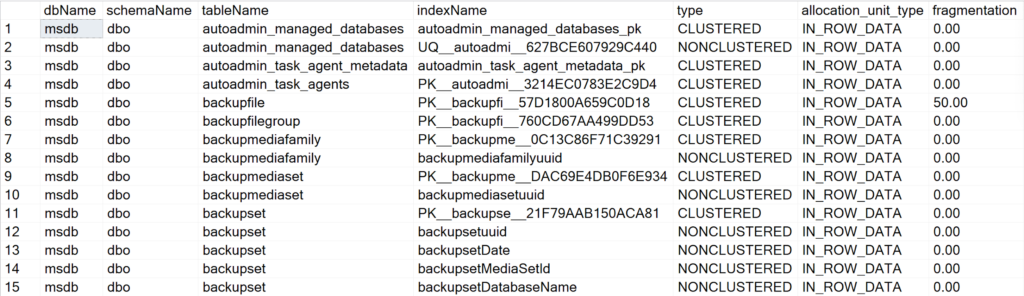
Display all the indexes information for all user databases
EXEC GetIndexData @persistData = 'N',@db = 'user'

Display all the indexes information for specific user databases
In my previous examples, only the database DBA showed up as my only user database with indexes in it. Therefore, let me create an index structure in another database I have laying around in the same instance so that you can see if the SP does its thing or not.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
All the examples showcased so far demonstrate the output that you get when you don’t want to persist data, for the different combinations of options for the @db parameter. The output is empty when you either specify an option that isn’t valid or the target database doesn’t exist. But what about when the DBA wants to persist data in a database table? Let’s find out.
*I’m going to run the SP for one case only because the rest of the options for the @db parameter have been pretty much showcased above and the result is the same but persisted to a database table.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
Now, after you execute the Stored Procedure you won’t get any output. To query the result set you have to issue a SELECT statement against the DBA_Indexes table. The main attraction here is that you can query the result set obtained, for post-analysis, and the addition of the data_collection_timestamp field that will let you know how recent/old the data you’re looking at is.
Side Queries for Listing Indexes in SQL Server
Now, to deliver more value to the DBA, I have prepared a few queries that can help you to obtain useful information from the data persisted in the table.
Query to find very fragmented indexes overall
Choose the number of % that you consider fitting. The 1500 pages are based on an article I read, based on Microsoft’s recommendation.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;Query to find disabled indexes within your environment
SELECT * FROM DBA_Indexes WHERE disabled = 1;Query to find indexes (mostly non-clustered) that are not that used that much by queries, at least not since the last time that the SQL Server instance was restarted
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';Query to find statistics that have either never been updated or are old
You determine what’s old within your environment, so make sure to adjust the number of days accordingly.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Stored Procedure Code to List All Databases Indexes in SQL Server
Here’s the complete code of the Stored Procedure:
At the very beginning of the script, you will see the default value that the Stored Procedure assumes if no value is passed for each parameter.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)+@db+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOConclusion
- You can deploy this SP in every SQL Server instance under your support and implement an alerting mechanism across your entire stack of supported instances.
- If you implement an agent job that is querying this information relatively frequently, you can stay on the top of the game to take care of the index structures within your supported environment(s).
- Make sure to test this mechanism properly in a sandbox environment and, when you are planning for a production deployment, make sure to choose low activity periods.
Index fragmentation issues can be tricky and stressful. To find and fix them, you can use different tools, like dbForge Index Manager that can be downloaded here.
Others Stored Procedures for SQL Server
Stored Procedure to Get Logins and Server Roles Inventory
Stored Procedure to Get Database Tables Information
How to Show List of Indexes in SQL Server using Stored Procedure
How to Use the sp_whoisactive PowerShell Script for Real-Time SQL Server Monitoring
How to Get SQL Server Statistics Information Using System Statistical Functions
SQL Server RAISERROR Statement with Simple Examples
Stored Procedure to Delete Duplicate Records in SQL Table
How to Get Backup Status in SQL Server using Stored Procedure







