In this article, we will discover some best practices of T-SQL queries. Badly written queries can cause performance and I/O problems. For this reason, we should pay attention to keep some rules in our mind when writing T-SQL queries.
Don’t use “SELECT * “ in queries
When we write a query, we need to select only required columns. Because this approach reduces the I/O and network roundtrip. Assume that, in case you need one or two column but you select all columns of a table. It will damage the SQL Server performance.
Try to avoid “TABLE OR INDEX SCAN” in queries
Performance is the most critical issue for SQL Server. For this reason, we should pay attention to performance criteria of queries. Well written queries will consume minimum resources and will be effective in terms of performance. Indexes provide query performance, so we need use indexes effectively.
Tip: When we see index scan in the execution plan, it means SQL Server reads all index pages and then find relevant records. But an index seek reads only required pages and is much selective than index scan.
In this sample, we will look at the two queries and will compare the execution plans of queries.
USE AdventureWorks2014
GO
SELECT Name
FROM [Production].[Product]
WHERE SUBSTRING(name,1,1) ='P'
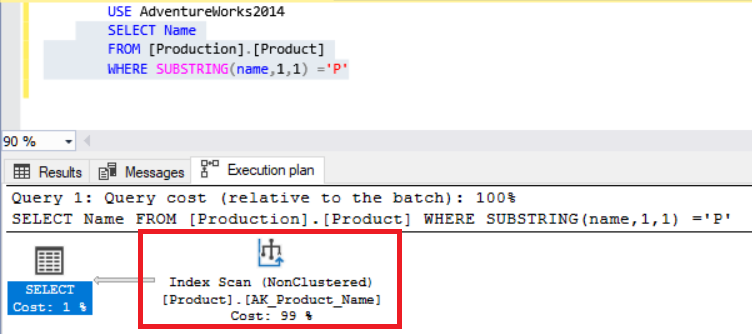
When we looked at the query execution plan, we saw cluster index scan. But when we convert the same query like this.
USE AdventureWorks2014 SELECT Name FROM [Production].[Product] WHERE name LIKE 'P%'
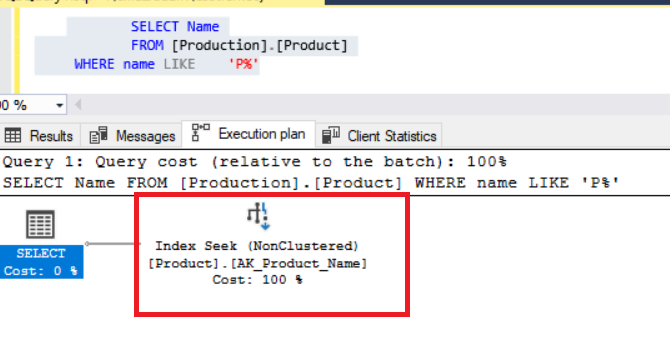
It uses cluster index seek and provides better performance than the first query.
Tip: When the index covers all columns from referenced query it is called “cover index”.
The basic purpose of this type of index is to generate less I/O. To achieve this idea, queries have to use the index seek.
Now, we will look at the query below and activate “Include Actual Execution Plan” in SQL Server Management Studio.
USE [AdventureWorks2014] GO SELECT [CarrierTrackingNumber] ,[UnitPrice] ,[ModifiedDate] FROM [Sales].[SalesOrderDetail] WHERE [ModifiedDate] BETWEEN '20050101' AND '20151231'
When we execute the query, we see index scan and index recommendation.
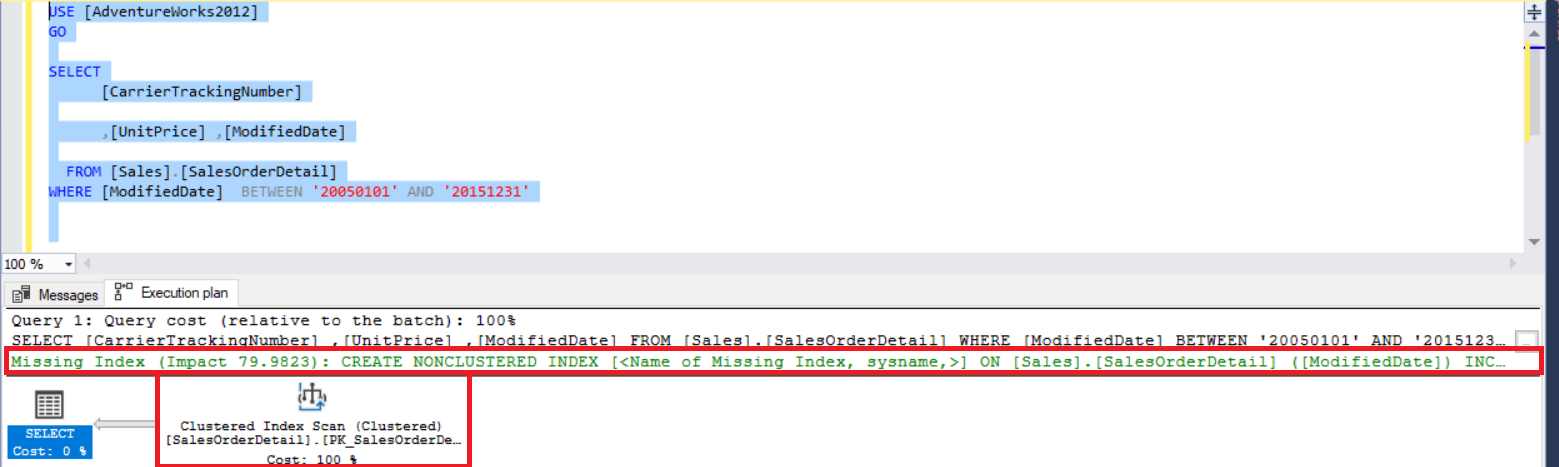
In this step, we will apply index recommendation because we want to change the “index scan” operation to “index seek”.
USE [AdventureWorks2014] GO CREATE NONCLUSTERED INDEX [Index_New] ON [Sales].[SalesOrderDetail] ([ModifiedDate]) INCLUDE ([CarrierTrackingNumber],[UnitPrice])
When we look at the index “CREATE” statement, it covers all columns. When we execute the same query, the execution plan will change.
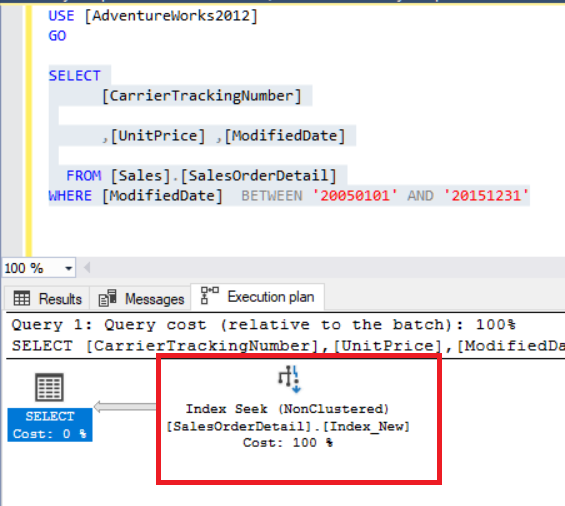
Tip: Don’t use functions on the left side of “where” clause because it reduces query performance. Like this:
SELECT .... FROM .... WHERE dateadd(d,30,ColumName) > getdate() SELECT .... FROM .... where LEFT(ColumName,1)='X'
Use TRY-CATCH block for error handling
Sometimes our queries can return errors. We need to handle these errors. Especially when we get an error in transaction blocks, we have to rollback this transaction. Because open transactions may cause serious problems. Therefore, we need to use TRY-CATCH blocks. This sample is the main usage of the TRY-CATCH blocks.
DROP TABLE IF EXISTS TestTable GO CREATE TABLE TestTable (ID INT PRIMARY KEY ,Val VARCHAR(100)) INSERT INTO TestTable VALUES(1,'Value1') BEGIN TRY BEGIN TRANSACTION INSERT INTO TestTable VALUES(1,'Value1') COMMIT TRANSACTION END TRY BEGIN CATCH PRINT 'Error ' + CONVERT(varchar(50), ERROR_NUMBER()) + ', Severity ' + CONVERT(varchar(5), ERROR_SEVERITY()) + ', State ' + CONVERT(varchar(5), ERROR_STATE()) + ', Line ' + CONVERT(varchar(5), ERROR_LINE()) PRINT ERROR_MESSAGE(); IF XACT_STATE() <> 0 BEGIN PRINT 'Transaction RollBack' ROLLBACK TRANSACTION END END CATCH;
But in some cases, the “TRY-CATCH” block cannot catch errors. For this case, we need to use “SET XACT_ABORT ON”. Now let’s take look at the below script. When we execute this query, we will get an error.
BEGIN TRY BEGIN TRANSACTION SELECT * FROM NonTable INSERT INTO TestTable VALUES(1,'Value1') COMMIT TRANSACTION END TRY BEGIN CATCH PRINT 'Error ' + CONVERT(varchar(50), ERROR_NUMBER()) + ', Severity ' + CONVERT(varchar(5), ERROR_SEVERITY()) + ', State ' + CONVERT(varchar(5), ERROR_STATE()) + ', Line ' + CONVERT(varchar(5), ERROR_LINE()) PRINT ERROR_MESSAGE(); IF XACT_STATE() <> 0 BEGIN PRINT 'Transaction RollBack' ROLLBACK TRANSACTION END END CATCH;
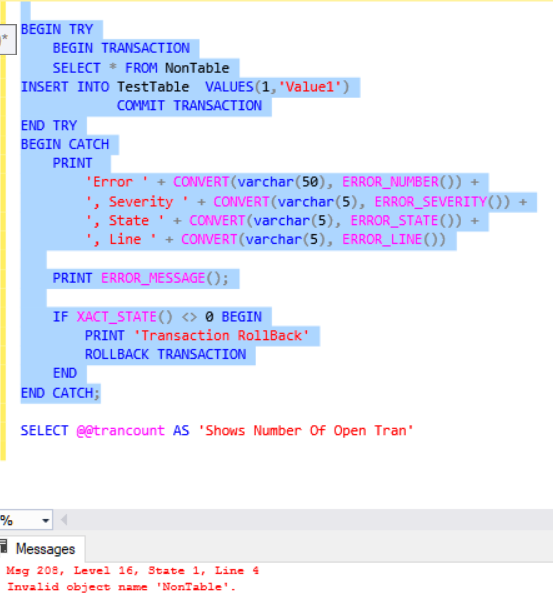
We will check the number of open transactions.
![]()
To avoid this case, we will add the “SET XACT_ABORT ON” statement at the beginning of the query and then re-execute the query. We will get the same error, but the open transaction will rollback automatically when the error occurs.
SET XACT_ABORT ON BEGIN TRY BEGIN TRANSACTION SELECT * FROM NonTable INSERT INTO TestTable VALUES(1,'Value1') COMMIT TRANSACTION END TRY BEGIN CATCH PRINT 'Error ' + CONVERT(varchar(50), ERROR_NUMBER()) + ', Severity ' + CONVERT(varchar(5), ERROR_SEVERITY()) + ', State ' + CONVERT(varchar(5), ERROR_STATE()) + ', Line ' + CONVERT(varchar(5), ERROR_LINE()) PRINT ERROR_MESSAGE(); IF XACT_STATE() <> 0 BEGIN PRINT 'Transaction RollBack' ROLLBACK TRANSACTION END END CATCH; SELECT @@trancount AS 'Shows Number Of Open Tran'
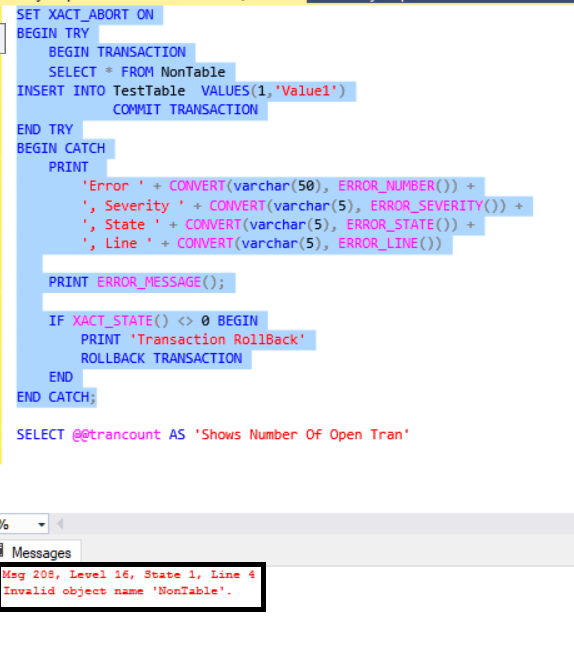
![]()
Use SCHEMABINDING to create view or function
Sometimes, we want to keep objects from changing that we used in views or functions. Assume that we created a view and then some developer or dba drops a table that is used in this view. To prevent this case, we have to use SCHEMABINDING.
We will create a simple example in which SQL Server will not be allowed to drop table or change columns because we will use SCHEMABINDING.
CREATE VIEW TestView WITH SCHEMABINDING AS SELECT Val FROM dbo.TestTable DROP TABLE TestTable
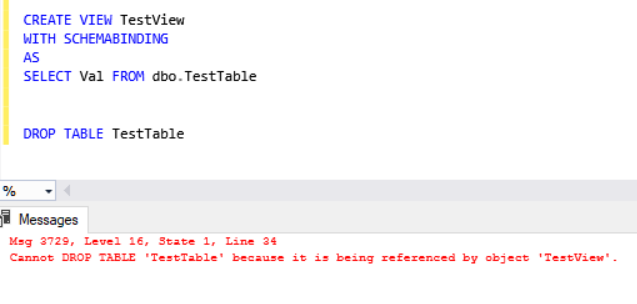
Avoid index hints
Some SQL queries include index hint. When you use index hint in queries, it deactivates the query optimizer because this hint forces query optimizer to use a constant index.
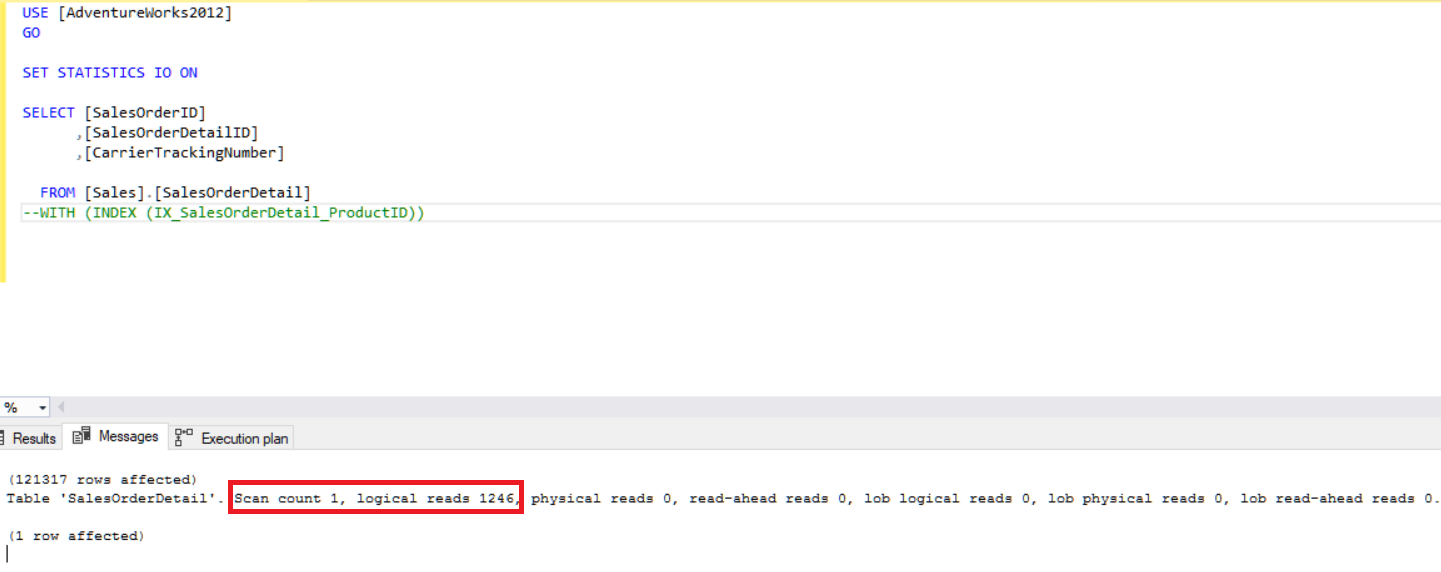
USE [AdventureWorks2012] GO SET STATISTICS IO ON SELECT [SalesOrderID] ,[SalesOrderDetailID] ,[CarrierTrackingNumber] FROM [Sales].[SalesOrderDetail] WITH (INDEX (IX_SalesOrderDetail_ProductID))
This query makes 371818 logical reads.
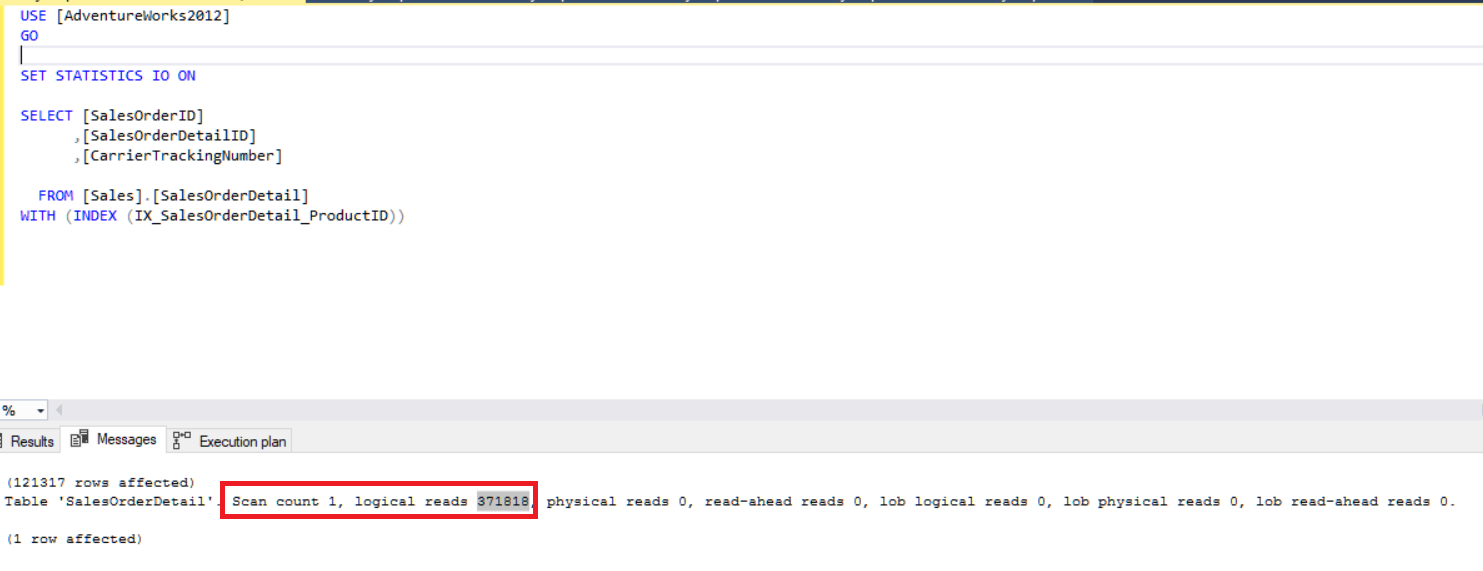
But, when we remove index hint, this query works and offers much less logical reads
Avoid subqueries
Badly written queries always damage SQL Server performance. When you write a subquery, this subquery query will run a number of rows.
Now we will look at this example.
SELECT p.Name,(SELECT pm.Name FROM Production.ProductCategory pm WHERE pm.ProductCategoryID=p.ProductSubcategoryID) AS modelname FROM production.Product p
We can re-write above query like this.
SELECT P.NAME ,PM.NAME FROM production.Product p LEFT JOIN Production.ProductCategory pm ON pm.ProductCategoryID=p.ProductSubcategoryID
Use EXISTS operator instead of IN
In T-SQL BEST Practices, notes use the EXISTS operator instead of IN. Because in the huge tables, it will make sense.
We can re-write this query like:
SELECT p.name FROM production.Product p WHERE p.ProductModelID IN (SELECT pm.ProductModelID FROM Production.ProductModel pm)
This query will offer effective performance than the previous query.
SELECT p.name FROM production.Product p WHERE EXISTS (SELECT pm.ProductModelID FROM Production.ProductModel pm WHERE pm.ProductModelID = p.ProductModelID )
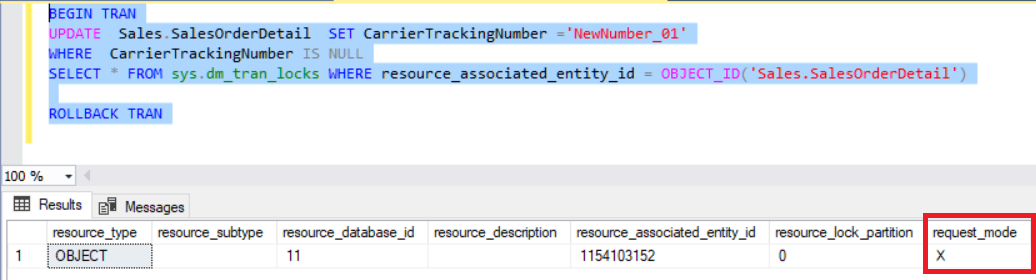
Use small batches in delete and update statements
Big update or delete statement sometimes can be very dangerous. Because transaction log can grow, it can consume a lot of resources or can create exclusive locks and this case affects concurrent users. For this reason, we need to change update or delete methodology. This update query will take a long time and create an exclusive lock on SalesOrderDetail.
SELECT p.name FROM production.Product p WHERE EXISTS (SELECT pm.ProductModelID FROM Production.ProductModel pm WHERE pm.ProductModelID = p.ProductModelID )
We can change the previous query as the following.
BEGIN TRAN UPDATE TOP(1000) Sales.SalesOrderDetail SET CarrierTrackingNumber ='NewNumber_01' WHERE CarrierTrackingNumber IS NULL COMMIT TRAN GO 40
References
Useful tool:
SQL Complete – write, beautify, refactor your code easily and boost your productivity.
Tags: execution plan, indexes, query performance, t-sql queries, tips and tricks Last modified: October 07, 2022







Nice tips. Just a suggestion, though. If all someone is going to do is regurgitate the same error that SQL Server generates, then forget the Try-Catch and let SQL Server do it’s job.
[…] T-SQL Best Practices […]
Your tips are good. There are couple of issues with two of them, however, that should be addressed.
Avoid correlated subqueries.
This query:
SELECT
p.Name AS ProductName
, (SELECT pc.Name
FROM Production.ProdutCategory AS pc
WHERE pc.ProductCategoryID = p.ProductSubcategoryID
) AS ModelName
FROM
Prodution.Product AS p;
May not be equvilent to this query:
SELECT
p.Name AS ProducctName
, pc.Name AS ModelName
FROM
Prodution.Product AS p
LEFT JOIN Prodution.ProductCategory AS pc — Left inner join from Product to ProductCategory
ON pc.ProductCategoryID = p.ProductSubcategoryID;
The first query could have NULL values returned by the subquery. This would not be
the case it there was a foreign key relationship between Product and ProductCategory
where the values in ProductSubcategoryID must exist in ProductCategoryID.
If NULL values are possible, then the new query would need to look like this:
SELECT
p.Name AS ProducctName
, pc.Name AS ModelName
FROM
Prodution.Product AS p
LEFT OUTER JOIN Prodution.ProductCategory AS pc
ON pc.ProductCategoryID = p.ProductSubcategoryID;
Use small batcches in delete an upddate statements.
The original script in the article will work when being run manually in SSMS.
However, if you are writing a procedure, the code provided won’t work.
You will need something like this:
DECLARE @BatchSize int
, @LoopSize int
, @LoopCnt int;
SET @BatchSize = 1000;
SET @LoopSize = CEILING((1.0 * (SELECT COUNT(*)
FROM Sales.SalesOrderDetail AS sod
WHERE sod.CarrierTrackingNumber IS NULL
)
) / @BatchSize
);
SET @LoopCnt = 0;
WHILE @LoopCnt < @LoopSize
BEGIN
BEGIN TRAN
UPDATE TOP(@BatchSize) Sales.SalesOrderDetail SET
CarrierTrackingNumber = 'NewNumber_01'
WHERE CarrierTrackingNumber IS NULL;
COMMIT TRAN;
SET @LoopCnt += 1;
END;