
Is SQL Server PARTITION BY clause giving you a brain freeze?
Beginners feel like entering a complex maze at first glance of code complexity. But you want to tackle this like a piece of cake, without the confusion. And without hair-pulling. So, this article is for you. We’ll make it plain and simple.
The complication starts with not being familiar with partitioning datasets. Adding more to the pain is the confusion between GROUP BY and PARTITION BY.
Well, prepare to have a eureka moment with this easy guide. Let’s start by getting familiar with partitioning. Then, we compare it to grouping. In no time, you will have a crystal-clear understanding. Because you will have easy-to-grasp examples to get you pump up and start using it.
This is how we will go over it:
- What is partitioning and how will this make you a SQL ninja?
- How is SQL Server GROUP BY different from SQL Server PARTITION BY?
- How to use SQL Server PARTITION BY With Examples
What’s ahead is not a complex maze. So, let’s begin.
What is Partitioning and How Will This Make You a SQL Ninja?
You love pizza, don’t you?
Imagine you have a large pizza. How would you share it with your friends? You don’t take a bite anywhere you like, do you? That would be messy. And your friends won’t like it. Instead, you cut it into smaller, manageable slices. And each of you will have a slice of it.
In like manner, data partitioning is like dividing a pizza into slices. Each partition is like a slice of pizza. It allows you to work on smaller chunks of data. And it’s also easier to handle that way. Certain criteria or conditions define your partitions like having meticulously-picked pizza toppings.
Now, consider the following result set:
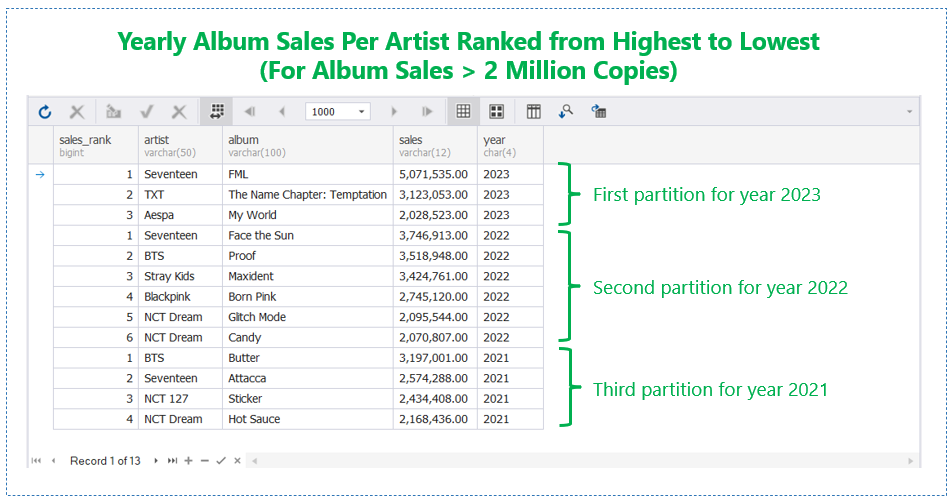
The data set above is a result of using PARTITION BY. As you can see, the data is not a summary. The first partition contains rows for 2023. Then, we ranked these rows according to the number of copies sold with the highest at the top. The same happens on every partition based on year.
So, this is data partitioning. And ranking rows based on criteria is just one of the possible use cases. Later, you will see what it looks like in code.
Here are some more real-world use cases for SQL Server PARTITION BY.
- Ranking and Top-N queries,
- Moving averages and running totals,
- Data comparison and gap analysis,
- and more…
So, knowing data partitioning can take you far in analyzing large datasets. In time, you can use this in analytical reports from simple to complex. Then, add query optimization techniques to your arsenal. And by then you can become the SQL ninja you aspire to be.
But before that, let’s compare it with another data processing technique – SQL Server GROUP BY.
How is SQL Server GROUP BY Different From SQL Server PARTITION BY?
Partitioning using PARTITION BY is like slicing a whole pizza. But, grouping using GROUP BY is like separating different pizza flavors in their own box. One box has meat. Another has veggies. And other boxes have other flavors also. Each pizza box contains many toppings.
The following is a table of differences between the two.
| GROUP BY | PARTITION BY | |
| Functionality | Aggregates data using aggregate functions like SUM, AVG, etc. | Partitions rows using window functions like RANK, FIRST_VALUE, etc. And aggregate functions can act like window functions when used with PARTITION BY. |
| Result set | Creates a new result set to summarize a set or rows based on your conditions. One row per group. | Works on the same set of rows without creating a new summarized result set. |
| Scope | Operates on the entire result set | Defines partitions based on a condition then operates on the rows on each partition. |
| Syntax | Specify the column(s) to base the grouping and perform aggregation(s) | Specify the column(s) to define partitions. Used together with window functions |
How to Use SQL Server PARTITION BY With Examples
You can use SQL Server PARTITION BY within an OVER clause. Here’s the syntax:
SELECT
[column-list]
<window-function-1> OVER (PARTITION BY expression1 [,expression2, expressionN] [ORDER BY clause] [ROW | RANGE clause)
<window-function-2> OVER (PARTITION BY expression1 [,expression2, expressionN]] [ORDER BY clause] [ROW | RANGE clause)
<window-function-N> OVER BY expression1 [,expression2, expressionN] [ORDER BY clause] [ROW | RANGE clause) In your SELECT statement, you can define more than 1 OVER clause with PARTITION BY. You can partition for one or more columns. Depending on the window function, SQL Server may need the ORDER BY clause. You can further limit the rows in a partition by using the ROW or RANGE clause.
Example 1: SQL Server PARTITION BY With RANK() – Ranking Album Sales Per Year
Here’s the code of the result set earlier.
SELECT
RANK() OVER(PARTITION BY year ORDER BY year DESC, sales DESC, album, artist) AS sales_rank
,artist
,album
,convert(varchar(12),sales,1) AS sales
,year
FROM kpop_album_sales
WHERE sales > 2000000
and year >= 2021
ORDER BY year DESC, sales DESC, album, artist; The partition uses the year as the criteria or condition. To RANK well, we added the ORDER BY clause. The result includes only the copies sold for more than 2 million. And the scope is from 2021 to 2023 only. You can find the entire dataset here.
Here’s the anatomy of the above SELECT statement with SQL Server PARTITION BY.

There’s no ROW or RANGE clause here. So, you’re telling SQL Server to use the first row as the one with top number of albums sold. The ORDER BY clause affects which goes to the top and bottom spots in the partition.
Now, instead of RANK, you can also use ROW_NUMBER OVER PARTITION BY in SQL Server with the same result. The following is the modified code:
SELECT
ROW_NUMBER() OVER(PARTITION BY year ORDER BY year DESC, sales DESC, album, artist) AS sales_rank
,artist
,album
,convert(varchar(12),sales,1) AS sales
,year
FROM kpop_album_sales
WHERE sales > 2000000
and year >= 2021
ORDER BY year DESC, sales DESC, album, artist; Example 2: SQL Server PARTITION BY With FIRST_VALUE() – Show the Leading Albums Sold and Artist Per Year
The following uses the FIRST_VALUE window function. This will get the leading artist and album per year.
SELECT DISTINCT
FIRST_VALUE(album) OVER(PARTITION BY year ORDER BY year DESC, sales DESC, album, artist) AS first_album
,FIRST_VALUE(artist) OVER(PARTITION BY year ORDER BY year DESC, sales DESC, album, artist) AS first_artist
,FIRST_VALUE(convert(varchar(12),sales,1)) OVER(PARTITION BY year ORDER BY year DESC, sales DESC, album, artist) AS first_sales
,year
FROM kpop_album_sales
WHERE sales > 2000000
and year >= 2021
ORDER BY year DESC This is like the previous query, but instead of RANK(), it uses FIRST_VALUE. FIRST_VALUE returns the first row in a partition. In this case, the highest-sold album per year. See the results below.
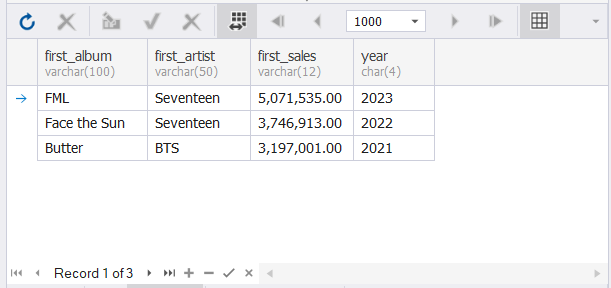
Another function that is the opposite of FIRST_VALUE is LAST_VALUE. If you want to get the row below the partition, this is the window function for that.
Example 3: SQL Server PARTITION BY With SUM() – Using SUM and PARTITION BY to Output a Running Total
Let’s prepare the sample data first. I prepared a small dataset by hand so you can use it too. But if you need a lot of meaningful data, there’s a handy tool for that. This handy tool that I use is the Data Generator from dbForge Studio for SQL Server.
Anyway, let’s create the table and add some data.
CREATE TABLE transactions
(
account_number varchar(12),
transaction_date date,
description varchar(50),
amount decimal(10,2)
);
INSERT INTO transactions
(account_number, transaction_date, description, amount)
VALUES
('987432010210','2022-12-01','Deposit',10000.00),
('987432010212','2022-12-01','Deposit',1000.00),
('987432010210','2022-12-03','Deposit',15200.00),
('987432010210','2022-12-04','Withdrawal',-1000.00),
('987432010212','2022-12-02','Credit Adjustment',3400.00),
('987432010210','2022-12-05','Debit Adjustment',-1000.00),
('987432010212','2022-12-10','Deposit',51000.00),
('987432010212','2022-12-20','Withdrawal',-2000.00),
('987432010210','2022-12-11','Deposit',1000.00),
('987432010210','2022-12-18','Withdrawal',-1000.00); Now, to display transactions together with a running total, here’s the code:
SELECT
account_number
,transaction_date
,description
,amount
,SUM(amount) OVER(PARTITION BY account_number
ORDER BY transaction_date
ROWS UNBOUNDED PRECEDING) AS running_total
FROM transactions; This is good for displaying bank transactions with running total per account number. The following is the result set:
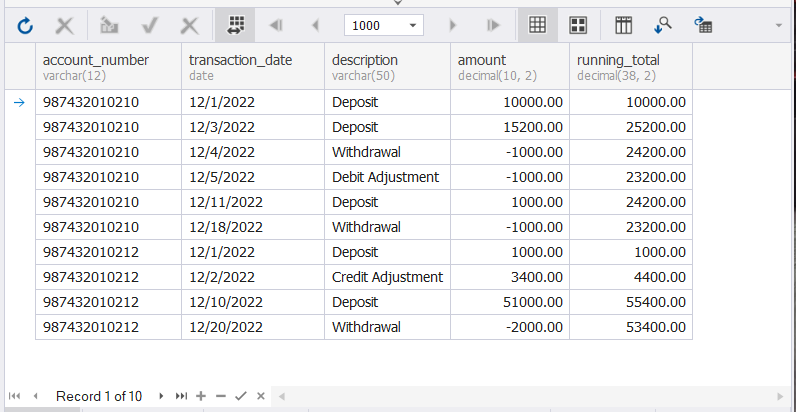
Note that there are 2 account numbers. Each of them has a series of deposits and withdrawals. The last row in each partition is the latest account balance.
The ROWS UNBOUNDED PRECEDING states the starting point of the window frame. It means that the window functions should start at the first row of the partition. In our example, the first row of the partition is the initial deposit.
Takeaways
That’s it.
Piece of cake, right? Using PARTITION BY in SQL Server divides a large data set in manageable chunks or partitions. From there, you can use window functions. So, pick the window function that best fits your purpose.
In this article, we used a SQL Server GUI tool called dbForge Studio for SQL Server. The screenshots where this appears are just the tip of the iceberg. More nice features like Query Profiler, Data Generator, and more will make you more productive. Why not try it out today?
Last modified: July 21, 2023



