
Is it a big deal to choose between CHAR and VARCHAR? What if your choice between CHAR vs. VARCHAR results in a nightmare of query lags?
When I was a newbie in SQL Server, it was not a big deal to me. Both store strings of characters so I thought it was just the same.
Until….
- I find myself using RTRIM more often in CHAR types,
- I found out CHAR uses more storage space than VARCHAR,
- And, that choosing the wrong one will make my query even slower.
If you find yourself in the same boat, you are not alone. You don’t have to experience it more like what I did long ago.
So, knowing this today as a newbie will up your game in database design and query optimization. The difference is easy to grasp, I assure you. And after you learn this, you’ll be more confident in choosing these text data types.
Here’s how we are going to proceed in this article:
- How to Store CHAR Data Type?
- How to Store VARCHAR Data Type?
- CHAR vs. VARCHAR Showdown: Know the Similarities
- CHAR vs. VARCHAR: Know the Differences
- CHAR vs. VARCHAR: How to Slash Query Time by Choosing the Right Type
- Wrongly Choosing Other Data Types Also Poses a Query Performance Threat
How to Store CHAR Data Type?
CHAR data type is for storing fixed-length character strings. It can store both single and multibyte character sets. The easy syntax for defining columns and variables with CHAR data type is this:
| CHAR(n) |
Where n is the number of bytes and valid values are from 1 to 8000. Note that storing characters less than n will cause padded blank spaces. So, let’s say you have a column of CHAR(10) and you store the word ‘pizza’ in it. The actual storage for that is ‘pizza’ + 5 more blank spaces. There will always be trailing spaces if you don’t fill up the whole range.
In other words, the data will always have the same size. So, when you use DATALENGTH for a column, you will always get the size defined in the column.
The CHAR data type is best for character data with fixed length. For example, you need to store a 5-digit official receipt number. And you want to pad zeroes in the beginning so that OR # 1 will be 00001. Then, you need a column with CHAR(5) data type. But if you don’t need to pad zeroes then CHAR(5) is not a good choice. Because OR # 1 will not be ‘1’ but ‘1’ + 4 blank spaces.
Examples of Using CHAR Data Type
1. Using CHAR Data Type in Column Definitions
Check out the syntax for new columns:
column_name CHAR(n) [NOT NULL] [DEFAULT 'default value'] Simply name the column and define the CHAR size in bytes. Then, tell SQL Server if it’s not nullable or has a default value. Here’s an example using this syntax:
CREATE TABLE payment_details
(
payment_id INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
or_number CHAR(5) NOT NULL,
or_payment_date DATE NOT NULL DEFAULT GETDATE(),
or_amount MONEY NOT NULL DEFAULT 0.00,
or_particulars VARCHAR(100) DEFAULT '',
modified DATETIME NOT NULL DEFAULT GETDATE()
); 2. Using CHAR Data Type in Variable Declaration
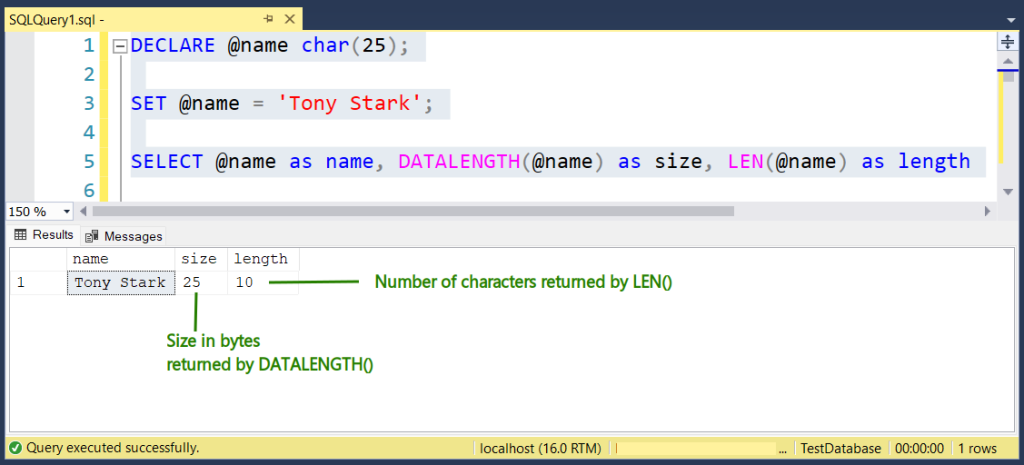
The following defines the variable @name as CHAR(25). Then, we set the value to it and determine its length in bytes and the number of characters.
DECLARE @name CHAR(25);
SET @name = 'Tony Stark';
SELECT @name AS name, DATALENGTH(@name) AS size, LEN(@name) AS length; See the result below. The size in bytes is the same as the size of the variable.
How to Store VARCHAR Data Type?
VARCHAR data type is for storing variable-length strings. Like CHAR, it can store single and multibyte characters. The syntax is easy and follows the same rules as CHAR:
| VARCHAR(n | max) |
Like CHAR, n is the number of bytes and possible values are 1 to 8000. But unlike CHAR, there are no trailing spaces when you don’t consume the entire range. Another option is to specify max instead of a number. This will let you store a large string of characters up to 2GB. Microsoft recommends using VARCHAR(max) instead of the TEXT data type in new tables.
If the data you’re going to store varies in size, use VARCHAR instead of CHAR. And if you think it will exceed 8000 bytes, use VARCHAR(max).
Examples of Using VARCHAR Data Type
1. Defining Columns as VARCHAR
The syntax is not so different from CHAR. Here it is:
column_name VARCHAR(n|max) [NOT NULL] [DEFAULT 'default value'] Here’s the same code that also shows a VARCHAR column example:
CREATE TABLE payment_details
(
payment_id INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
or_number CHAR(5) NOT NULL,
or_payment_date DATE NOT NULL DEFAULT GETDATE(),
or_amount MONEY NOT NULL DEFAULT 0.00,
or_particulars VARCHAR(100) DEFAULT '',
modified DATETIME NOT NULL DEFAULT GETDATE()
); 2. Using VARCHAR Data Type in Variable Declarations
It’s the same as how you declare a CHAR variable. So, here’s an example using VARCHAR(max):
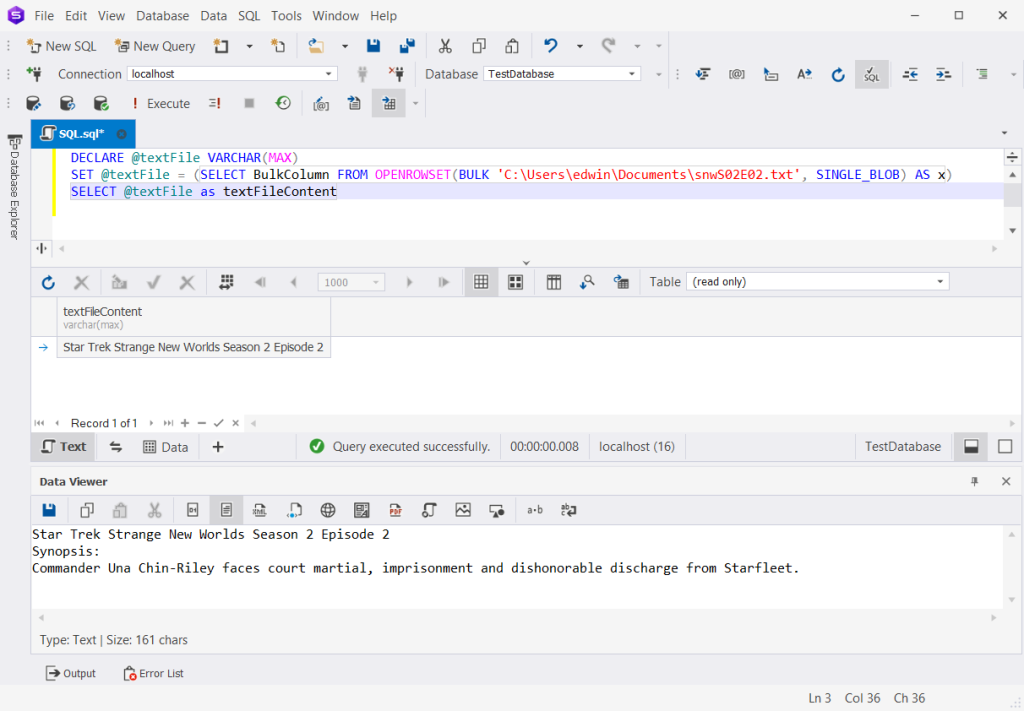
DECLARE @textFile VARCHAR(MAX)
SET @textFile = (SELECT BulkColumn FROM OPENROWSET(BULK 'C:\Users\edwin\Documents\snwS02E02.txt', SINGLE_BLOB) AS x)
SELECT @textFile as textFileContent The following shows the output using dbForge Studio for SQL Server. It also shows the Data Viewer window to view large text.
CHAR vs. VARCHAR Showdown: Know the Similarities
We’re not going to talk about obvious similarities here. But the things you need to know when coding T-SQL code that deals with them.
Let’s begin.
CHAR vs. VARCHAR: Default Value of n
Do you know that you don’t need to define the size in bytes explicitly? You can just leave it without them. Try this out and find out the default value.
CREATE TABLE testCharTypes
(
testColumn1 VARCHAR,
testColumn2 CHAR
); So, what’s the default value of n? Check it out below.
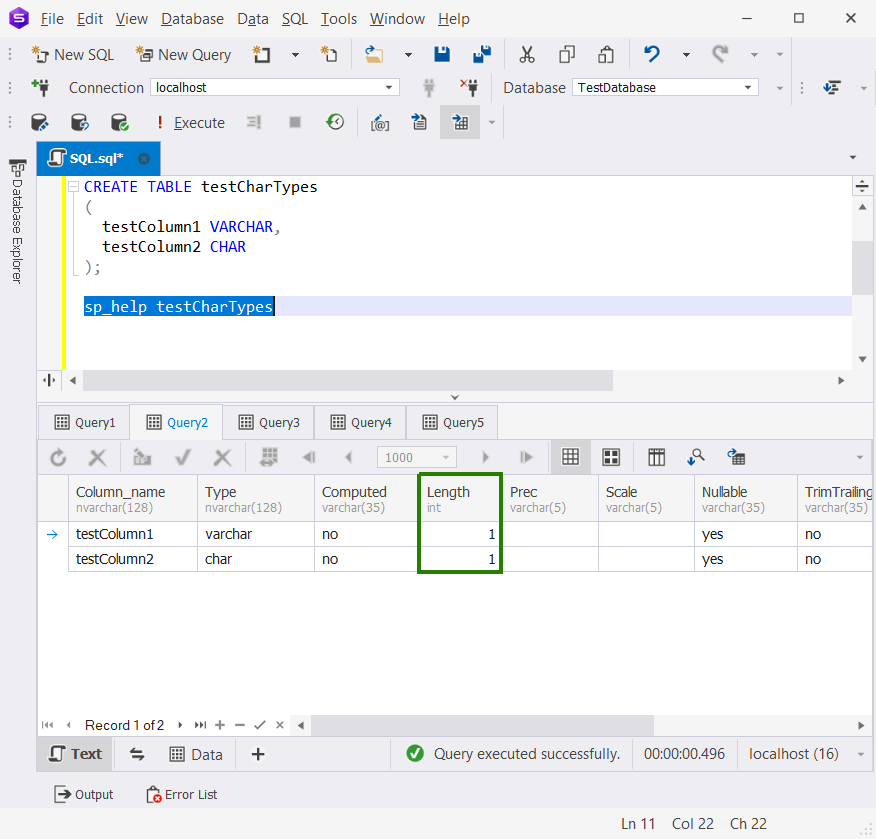
So, the default size in bytes is 1. You can use sp_help or your GUI tool’s database object viewer to see it for yourself.
The behavior is the same when declaring variables. You can try this out:
DECLARE @secretIdentity AS VARCHAR = 'Bruce Wayne';
DECLARE @heroName AS CHAR = 'Batman';
--The following returns 1 for both VARCHAR and CHAR
SELECT DATALENGTH(@secretIdentity), DATALENGTH(@heroName);
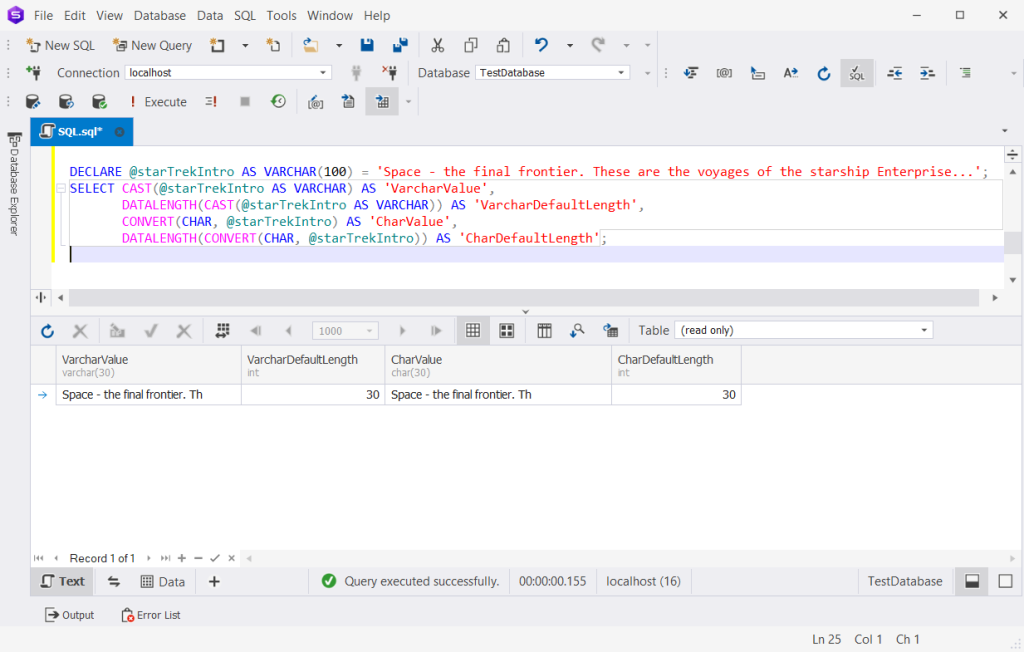
GO But it’s different when converting using CAST and CONVERT. The default value is 30 bytes. So, check this one out:
DECLARE @starTrekIntro AS VARCHAR(100) = 'Space - the final frontier. These are the voyages of the starship Enterprise...';
SELECT CAST(@starTrekIntro AS VARCHAR) AS 'VarcharValue',
DATALENGTH(CAST(@starTrekIntro AS VARCHAR)) AS 'VarcharDefaultLength',
CONVERT(CHAR, @starTrekIntro) AS 'CharValue',
DATALENGTH(CONVERT(CHAR, @starTrekIntro)) AS 'CharDefaultLength'; And here’s the result:
Although SQL Server allows leaving out the size, it’s better to specify it to avoid truncation.
CHAR vs. VARCHAR: Same Truncation Rules
When you specify the size in bytes, you’re telling SQL Server the column or variable’s limit. It won’t go beyond the limit you set.
Check out the last example from the previous section again. Since the default value of n is 30, SQL Server truncates the value to 30. So, the second sentence is incomplete. That example also uses single-byte characters. So, the number of characters is the same as the number of bytes.
Here’s another one, and it relates to VARCHAR(max):
-- This will take a while
DECLARE @humongousString VARCHAR(MAX);
SET @humongousString = REPLICATE(CAST('I love you 3000' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@humongousString) This will generate a 1.5GB-sized string. This will run way longer than what you expect from a 3-line code. Note the conversion using CAST. Without that, SQL Server will truncate the result to 8000 bytes only.
Yet, here’s another example that involves the UNIQUEIDENTIFIER type. This type is 36 characters long. And if you convert a CHAR(40) or VARCHAR(40) to this, truncation will occur.
Here’s an example:
DECLARE @sampleID VARCHAR(45) = 'f38fcf72-ae36-455d-958d-3736fd13a539-5555'
SELECT @sampleID, CAST(@sampleID as UNIQUEIDENTIFIER) as converted Expect the extra characters (‘-5555’) in the @sampleID to disappear after the CAST.
In the end, size matters to avoid truncation for both CHAR and VARCHAR.
CHAR vs. VARCHAR: Numeric and Date Conversions to Text with Style
You can use either CHAR or VARCHAR to convert numbers and dates to text with a style format. Compare the results of using CHAR and VARCHAR as target types for conversion.
-- Using CHAR
SELECT TOP 100
SalesOrderID
,OrderDate
,CONVERT(CHAR(12), OrderDate, 3) as OrderDateStyle3
,TotalDue
,CONVERT(CHAR(12), TotalDue,1) as TotalDueStyle1
FROM Sales.SalesOrderHeader
-- Using VARCHAR
SELECT TOP 100
SalesOrderID
,OrderDate
,CONVERT(VARCHAR(12), OrderDate, 3) as OrderDateStyle3
,TotalDue
,CONVERT(VARCHAR(12), TotalDue,1) as TotalDueStyle1
FROM Sales.SalesOrderHeader And here’s the result for VARCHAR.
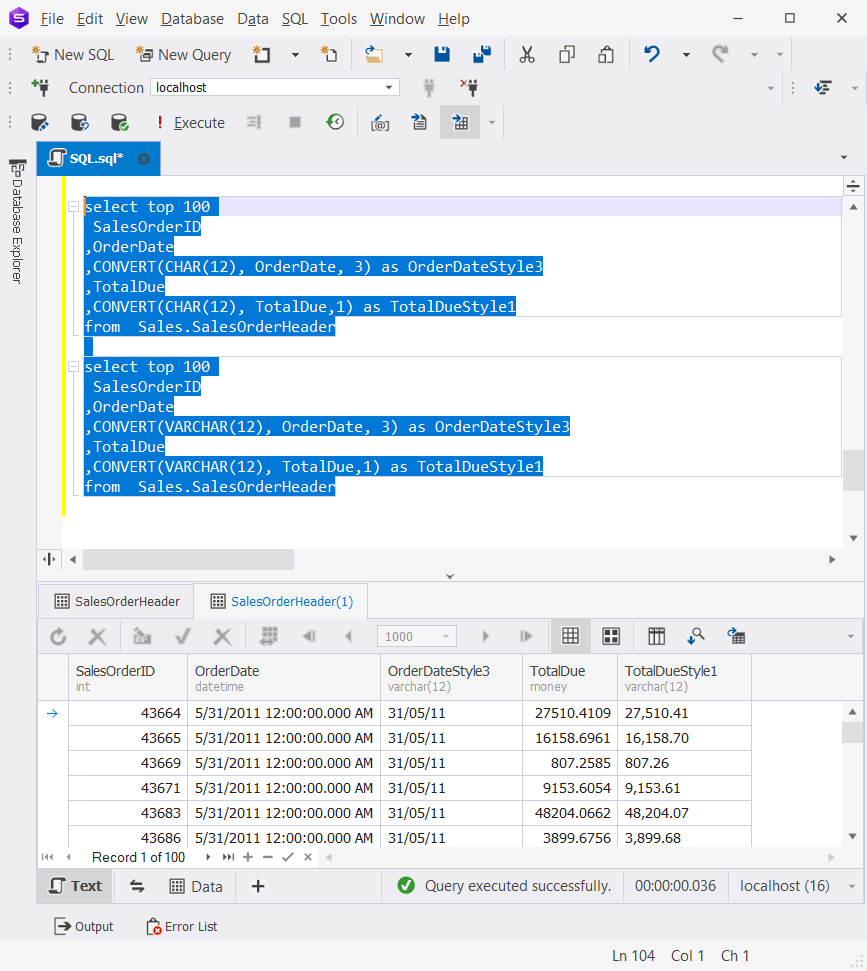
CHAR vs. VARCHAR: Both Stores Unicode Characters
If you’re designing a database that the world will use, you need multi-byte or Unicode support. This can handle all the characters for known languages.
And starting in SQL Server 2019, CHAR and VARCHAR support UTF8 character encoding. You can set it in the server, database, or table column level. For more details, check out my previous article about VARCHAR Do’s and Don’ts.
Here’s an example of how to support UTF8 in the table column level with a VARCHAR data type:
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
) See the KoreanName column? That can store Korean characters. But the EnglishName column can only store single-byte characters. The type is VARCHAR, but you can also use CHAR if applicable.
You need to prefix the value with N to specify a Unicode value, like this:
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino') Take note that using Unicode support has different storage requirements. Consider this when doing capacity planning. Check out the table below:
| Characters | Storage in Bytes |
| Ascii characters 0 to 127 | 1 |
| The Latin-based script, and Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac, Tāna, and N’Ko | 2 |
| East Asian script like Japanese, Chinese, or Korean | 3 |
| Characters in the range 010000–10FFFF | 4 |
In our example, we used Korean characters. So, each character is 3 bytes.
Since we declared enough size for the KoreanName column, truncation will not occur.
CHAR vs. VARCHAR Showdown: Know the Differences
What is the difference between CHAR and VARCHAR in SQL? Check out the table below. This applies to SQL Server 2022.
| CHAR | VARCHAR | |
| Sizing | Fixed | Variable |
| Column or variable declaration | CHAR(n) | VARCHAR(n | max) |
| Maximum data storage | 8000 bytes | 2GB using VARCHAR(max) |
| Character storage | Size in n bytes | Size in n bytes + 2 bytes |
| Behavior | Pads trailing spaces when entire size is not used | No trailing spaces when entire size is not used |
| Use Case | When size in bytes is known and consistent | When size in bytes vary |
CHAR vs. VARCHAR: How to Slash Query Time by Choosing the Right Type
The difference between CHAR and VARCHAR is a big deal. Choose the wrong type, and your query will run at a snail’s pace. This section will discuss the performance implication.
But before we proceed, please note that we will use STATISTICS IO. I have an article that explains what this is all about. You may refer to that if you are new to this. But for now, we will focus on the value of logical reads in our test queries. Note that the lower the logical reads, the better. “Better” means less storage and memory consumed and faster performance.
But why not measure the execution time? The linked article above also explains that part. And it’s not a reliable way to measure performance. Do you wonder why it’s faster on your PC and slow on the production server? This is one of the reasons why we can’t rely on time measurements.
Anyway, let’s begin.
Generate the Sample Data
The AdventureWorks sample database has a table of names. The length of their names varies in size. So, this is a good candidate for the CHAR vs. VARCHAR showdown. But let’s dump that data into 2 different tables. One having CHAR names and the other having VARCHAR names.
Here’s how to generate the data:
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO After running this, you will get 2 tables: the VarcharAsIndexKey and the CharAsIndexKey. Both have the same data but use different types.
Perform the Tests
First, let’s try a simple SELECT and compare their logical reads.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
SET NOCOUNT OFF So, which of the tables will have lower logical reads? Check out below.
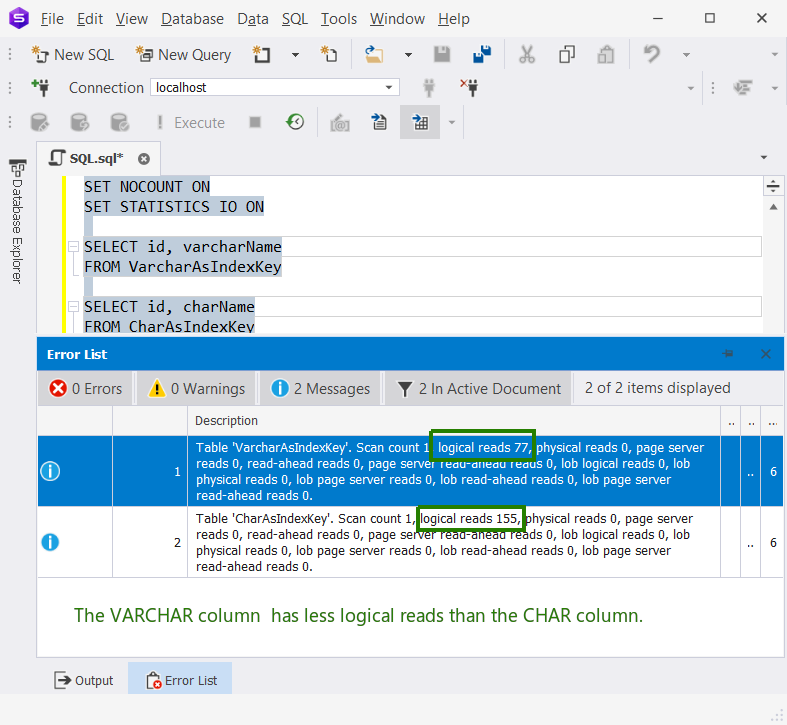
Both the CHAR and VARCHAR name columns have the same size of 50 bytes. But the CHAR column occupies more data and index pages with 155 logical reads.
The reason? The padded trailing spaces of the CHAR column. That column always has a size of 50 bytes, no matter how many characters the name has.
How about inserting 2 rows? Here’s the code:
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Skywalker, Luke'), ('Organa, Leia')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Skywalker, Luke'), ('Organa, Leia')
SET STATISTICS IO OFF And here’s the logical reads:
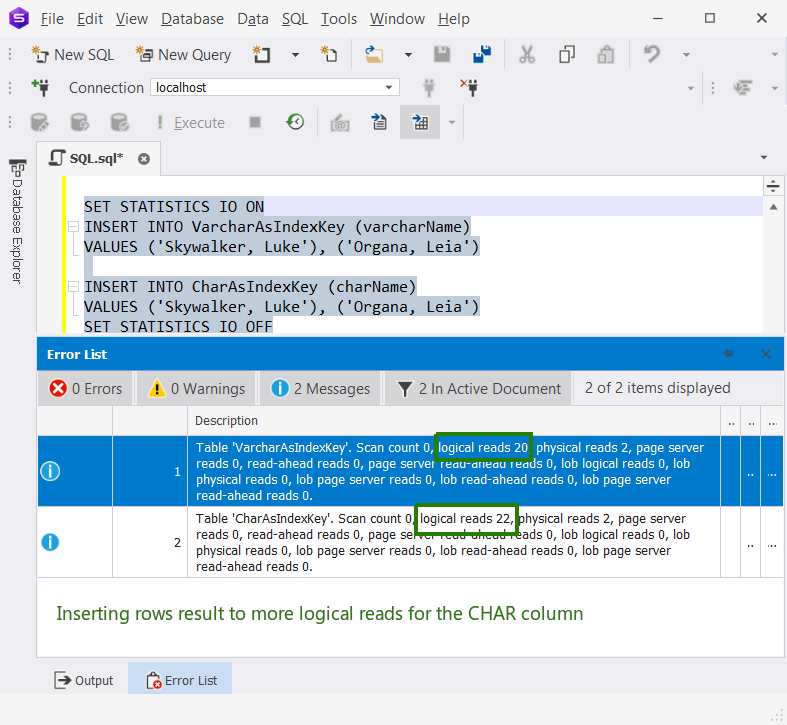
How about an UPDATE?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Skywalker, Anakin'
WHERE varcharName = 'Skywalker, Luke'
UPDATE CharAsIndexKey
SET charName = 'Skywalker, Anakin'
WHERE charName = 'Skywalker, Luke'
SET STATISTICS IO OFF The VARCHAR column will always win since it consumes fewer logical reads.
The Major Takeaway from the Tests
When the data you need to store has varying sizes, VARCHAR is your best option. Because VARCHAR columns will outperform CHAR columns because of less logical reads. This is just one scenario in choosing between CHAR and VARCHAR.
When choosing between CHAR and VARCHAR, perform a test like the one we did. Or you can also use other performance optimization techniques.
Then, adjust your data types accordingly.
Wrongly Choosing Other Data Types Also Pose a Query Performance Threat
We only covered CHAR and VARCHAR. Other data types for consideration for character strings are NCHAR and NVARCHAR. And the binary types too. This is so if your SQL Server version is 2017 or lower. Choosing one or the other can affect performance in any way.
Then, there are date data types for chronological events. There are conversion considerations for these too.
Whatever type it is, there are use cases and performance impacts for each.
Conclusion
CHAR and VARCHAR data types are for storing fixed or variable-sized strings. You cannot just pick one at random for any column or variable. There’s a performance impact if you don’t know their secrets or proper usage.
But we exposed these today. So, you now have the knowledge that will up your game in database design and query optimization.
The tool we used here is dbForge Studio for SQL Server. There are many more features you can get than what you saw here. Give it a try today and improve your SQL Server development productivity.
Last modified: July 07, 2023



