Introduction
Amazon Web Service, aka AWS, is a leading cloud infrastructure provider for storing your servers, applications, databases, networking, domain controllers, and active directories in a widespread cloud architecture. AWS provides a Simple Storage Service (S3) for storing your objects or data with (119’s) of data durability. AWS S3 is compliant with PCI-DSS, HIPAA/HITECH, FedRAMP, EU Data Protection Directive, and FISMA that helps satisfy regulatory requirements.
When you log in to the AWS portal, navigate to the S3 bucket, choose your required bucket, and download or upload the files. Doing it manually on the portal is quite a time-consuming task. Instead, you can use the AWS Command Line Interface (CLI) that works best for bulk file operations with easy-to-use scripts. You can schedule the execution of these scripts for an unattended object download/upload.
Configure AWS CLI
Download the AWS CLI and install AWS Command Line Interface V2 on Windows, macOS, or Linux operating systems.

You can follow the installation wizard for a quick setup.
Create an IAM user
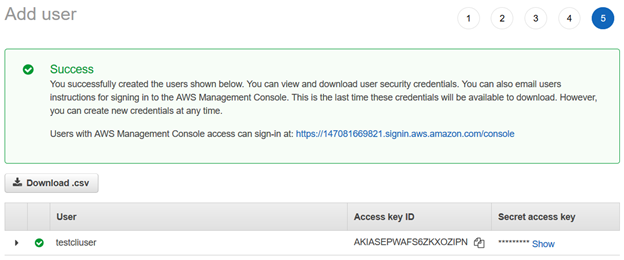
To access the AWS S3 bucket using the command line interface, we need to set up an IAM user. In the AWS portal, navigate to Identity and Access Management (IAM) and click Add User.

In the Add User page, enter the username and access type as Programmatic access.
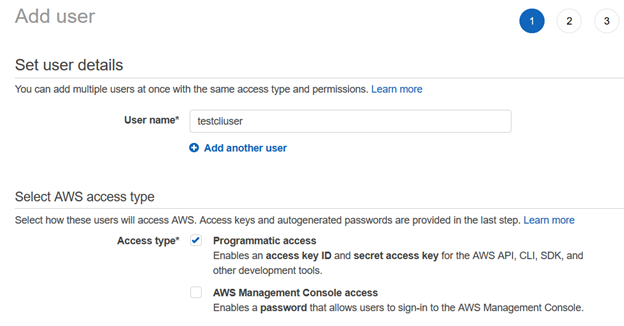
Next, we provide permissions to the IAM user using existing policies. For this article, we have chosen [AmazonS3FullAccess] from the AWS managed policies.
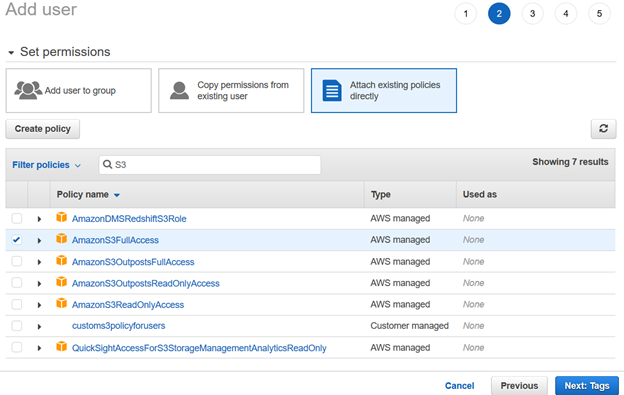
Review your IAM user configuration and click Create user.
Once the AWS IAM user is created, it gives the Access Key ID and Secret access key to connect using the AWS CLI.
Note: You should copy and save these credentials. AWS does not allow you to retrieve them at a later stage.
Configure AWS Profile On Your Computer
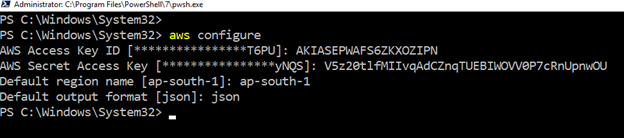
To work with AWS CLI on Amazon web service resources, launch the PowerShell and run the following command.
>aws configureIt requires the following user inputs:
- IAM user Access Key ID
- AWS Secret Access key
- Default AWS region-name
- Default output format
Create S3 Bucket Using AWS CLI
To store the files or objects, we need an S3 bucket. We can create it using both the AWS portal and AWS CLI.
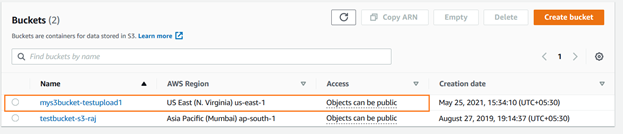
The following CLI command creates a bucket named [mys3bucket-testupload1] in the us-east-1 region. The query returns the bucket name in the output, as shown below.
>aws s3api create-bucket --bucket mys3bucket-testupload1 --region us-east-1
You can verify the newly-created s3 bucket using the AWS console. As shown below, the [mys3bucket-testupload1] is uploaded in the US East (N. Virginia).
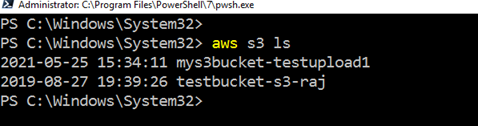
To list the existing S3 bucket using AWS CLI, run the command – aws s3 ls
Uploading Objects in the S3 Bucket Using AWS CLI
We can upload a single file or multiple files together in the AWS S3 bucket using the AWS CLI command. Suppose we have a single file to upload. The file is stored locally in the C:\S3Files with the name script1.txt.
To upload the single file, use the following CLI script.
>aws s3 cp C:\S3Files\Script1.txt s3://mys3bucket-testupload1/It uploads the file and returns the source-destination file paths in the output:

Note: The time to upload on the S3 bucket depends on the file size and the network bandwidth. For the demo purpose, I used a small file of a few KBs.
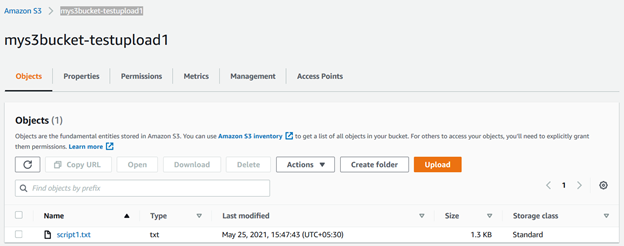
You can refresh the s3 bucket [mys3bucket-testupload1] and view the file stored in it.
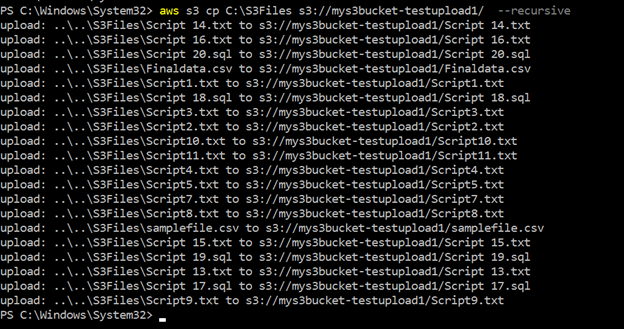
Similarly, we can use the same CLI script with a slight modification. It uploads all files from the source to the destination S3 bucket. Here, we use the parameter –recursive for uploading multiple files together:
>aws s3 cp c:\s3files s3://mys3bucket-testupload1/ --recursiveAs shown below, it uploads all files stored inside the local directory c:\S3Files to the S3 bucket. You get the progress of each upload in the console.
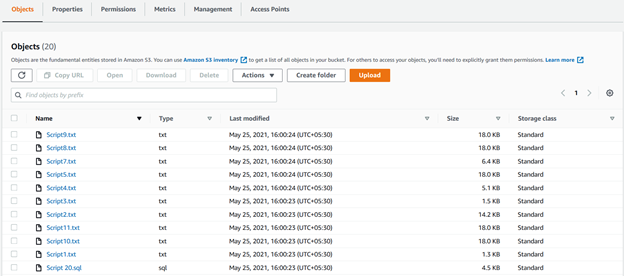
We can see all uploaded files using recursive parameters in the S3 bucket in the following figure:
If you do not want to go to the AWS portal to verify the uploaded list, run the CLI script, return all files, and upload timestamps.
>aws s3 ls s3://mys3bucket-testupload1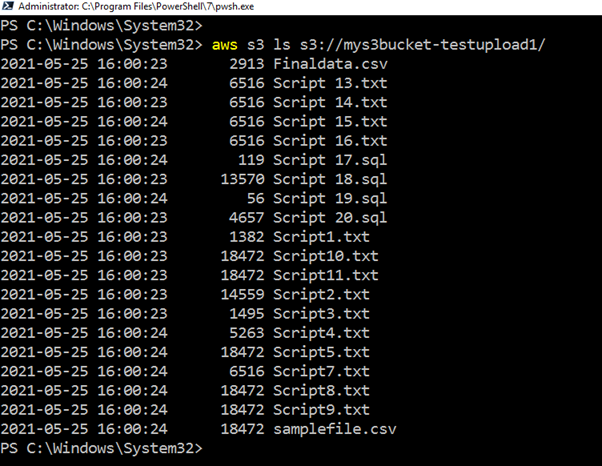
Suppose we want to upload only files with a specific extension into the separate folder of AWS S3. You can do the object filtering using the CLI script as well. For this purpose, the script uses include and exclude keywords.
For example, the query below checks files in the source directory (c:\s3bucket), filters files with .sql extension, and uploads them into SQL/ folder of the S3 bucket. Here, we specified the extension using the include keyword:
>aws s3 cp C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.sqlIn the script output, you can verify that files with the .sql extensions only were uploaded.

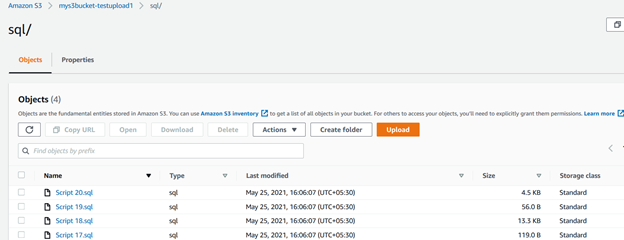
Similarly, the below script uploads files with the .csv extension into the S3 bucket.
>aws s3 cp C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.csv
Upload New or Modified Files from Source Folder to S3 Bucket
Suppose you use an S3 bucket to move your database transaction log backups.
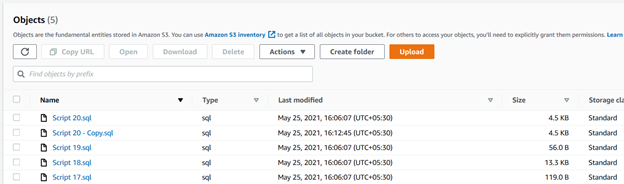
For this purpose, we use the sync keyword. It recursively copies new, modified files from the source directory to the destination s3 bucket.
>aws s3 sync C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.sqlAs shown below, it uploaded a file that was absent in the s3 bucket. Similarly, if you modify any existing file in the source folder, the CLI script will pick it and upload it to the S3 bucket.

Summary
The AWS CLI script can make your work easier for storing files in the S3 bucket. You can use it to upload or synchronize files between local folders and the S3 bucket. It is a quick way to deploy and work with objects in the AWS cloud.
Tags: AWS, aws cli, aws s3, cloud platform Last modified: October 27, 2022







